Seguimos la serie de artículos de nuestro cluster de Hadoop. En este caso voy a integrar Apache Spark en el cluster y voy a incluir un script en Scala que usa el framewrok de Spark para realizar las mismas operaciones que realizamos con Hive en el artículo anterior.
Recapitulando los anteriores artículos habíamos creado un cluster Hadoop para procesar unos ficheros. Creamos un Dockerfile para generar una imagen base. Con esta imagen creamos nos nodos slave del cluster. También creamos otro Dockerfile que se basa en la imagen base y con el que creamos la imagen del nodo master del cluster. En un primer lugar creamos un cluster de Hadoop, después incluimos hive y ahora vamos a incluir Spark.
Como en artículo anterior nos modificamos los ficheros ya existentes y los cambios realizado los dejaré subidos en una rama del repositorio de Github de los artículos.
Empezamos modificando el Dockerfile de la imagen base. Se encuentra en la ruta docker/base/Dockerfile. Incluimos dos variables de entorno necesarias para que Spark encuentre las configuraciones de Hadoop y Yarn y pueda funcionar correctamente.
ENV HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
ENV YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop/Así quedaría el fichero Dockerfile completo.
FROM ubuntu:16.04
MAINTAINER irm
WORKDIR /root
# install openssh-server, openjdk and wget
RUN apt-get update && apt-get install -y openssh-server openjdk-8-jdk wget
# install hadoop 2.7.2
RUN wget http://apache.rediris.es/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz && \
tar -xzvf hadoop-2.7.7.tar.gz && \
mv hadoop-2.7.7 /usr/local/hadoop && \
rm hadoop-2.7.7.tar.gz
# set environment variable
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
ENV HADOOP_HOME=/usr/local/hadoop
ENV HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
ENV YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop/
ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
# ssh without key
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
RUN mkdir -p ~/hdfs/namenode && \
mkdir -p ~/hdfs/datanode && \
mkdir $HADOOP_HOME/logs
COPY config/* /tmp/
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh
RUN chmod +x ~/start-hadoop.sh && \
chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh
# format namenode
RUN /usr/local/hadoop/bin/hdfs namenode -format
CMD [ "sh", "-c", "service ssh start; bash"]
# Hdfs ports
EXPOSE 9000 50010 50020 50070 50075 50090
EXPOSE 9871 9870 9820 9869 9868 9867 9866 9865 9864
# Mapred ports
EXPOSE 19888
#Yarn ports
EXPOSE 8030 8031 8032 8033 8040 8042 8088 8188
#Other ports
EXPOSE 49707 2122Ahora vamos con los cambios del Dockerfile de la imagen master. Quitamos la instalación de Hive e incluimos la instalación de Spark. Podríamos tener ambos a la vez en el mismo cluster, pero en este caso prefiero eliminar Hive del cluster ya que no lo vamos a utilizar:
- Bajamos los binarios de Spark y lo descomprimimos.
- Configuramos las variables de entorno
- Añadimos el fichero de configuración de Spark
- Añadimos el jar que va a ejecutar Spark para procesar los ficheros. Mas adelante vemos que hace exactamente.
- Exponemos el puerto 18080 para poder acceder al Spark’s history server
El fichero se encuentra en docker/master/Dockerfile
RUN wget http://apache.rediris.es/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz && \
tar -xvf spark-2.4.0-bin-hadoop2.7.tgz && \
mv spark-2.4.0-bin-hadoop2.7 /usr/local/spark && \
rm spark-2.4.0-bin-hadoop2.7.tgz
ENV PATH=$PATH:/usr/local/spark/bin
ENV SPARK_HOME=/usr/local/spark
ENV LD_LIBRARY_PATH=/usr/local/hadoop/lib/native:$LD_LIBRARY_PATH
ADD config/spark-defaults.conf /usr/local/spark/conf
RUN chown root:root /usr/local/spark/conf/spark-defaults.conf
ADD bin/stackanswer_2.12-1.0.jar /usr/local/spark/jars
EXPOSE 18080Así quedaría el fichero Dockerfile completo.
FROM irm/hadoop-cluster-base
MAINTAINER irm
WORKDIR /root
# install Spark
RUN wget http://apache.rediris.es/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz && \
tar -xvf spark-2.4.4-bin-hadoop2.7.tgz && \
mv spark-2.4.4-bin-hadoop2.7 /usr/local/spark && \
rm spark-2.4.4-bin-hadoop2.7.tgz
ENV PATH=$PATH:/usr/local/spark/bin
ENV SPARK_HOME=/usr/local/spark
ENV LD_LIBRARY_PATH=/usr/local/hadoop/lib/native:$LD_LIBRARY_PATH
ADD config/spark-defaults.conf /usr/local/spark/conf
RUN chown root:root /usr/local/spark/conf/spark-defaults.conf
ADD bin/stackanswer_2.12-0.1.jar /usr/local/spark/jars
ADD config/bootstrap.sh /etc/bootstrap.sh
RUN chown root:root /etc/bootstrap.sh
RUN chmod 700 /etc/bootstrap.sh
ENV BOOTSTRAP /etc/bootstrap.sh
VOLUME /data
CMD ["/etc/bootstrap.sh", "-d"]
EXPOSE 18080Seguimos con el fichero boostrap.sh. Este fichero se ejecuta al arrancar el contenedor del nodo master. En la versión anterior, este fichero configuraba directorios en el HDFS para hive, se inicializa el metastorage de Hive y ejecutaba un job de wordcount en Hadoop y un job de Hive. Todo eso se elimina en esta versión.
Los cambios que incluimos son:
- Arrancar el proceso del Spark’s history server
- Crear el directorio de losg para Spark en el HDFS
- Lanzar el job de Spark que procesará los ficheros de entrada.
Este fichero se encuentra en la ruta docker/master/config/bootstrap.sh
#!/bin/bash
service ssh start
# start cluster
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
# create paths and give permissions
$HADOOP_HOME/bin/hdfs dfs -mkdir -p /user/root/input_answers
$HADOOP_HOME/bin/hdfs dfs -mkdir -p /user/root/input_names
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal /data/user_ids_answers input_answers
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal /data/user_ids_names input_names
$HADOOP_HOME/bin/hdfs dfs -mkdir /spark-logs
# start spark history server
$SPARK_HOME/sbin/start-history-server.sh
# run the spark job
spark-submit --deploy-mode cluster --master yarn \
--class StackAnswer \
$SPARK_HOME/jars/stackanswer_2.12-0.1.jar
# copy results from hdfs to local
$HADOOP_HOME/bin/hdfs dfs -copyToLocal /user/root/users_most_actives /data
$HADOOP_HOME/bin/hdfs dfs -copyToLocal /user/root/locations_most_actives /data
bashEs el turno del script que realiza toda la magia. En este caso, solo incluimos mapeo de puerto de history server cuando creamos el contenedor del nodo master. Este sería el fichero completo:
#!/bin/bash
# provisioning data
rm data/user_ids_names &> /dev/null
python src/provisioning_data.py
sudo rm -rf data/locations_most_actives data/users_most_actives
# create base hadoop cluster docker image
docker build -f docker/base/Dockerfile -t irm/hadoop-cluster-base:latest docker/base
# create master node hadoop cluster docker image
docker build -f docker/master/Dockerfile -t irm/hadoop-cluster-master:latest docker/master
echo "Starting cluster..."
# the default node number is 3
N=${1:-3}
docker network create --driver=bridge hadoop &> /dev/null
# start hadoop slave container
i=1
while [ $i -lt $N ]
do
docker rm -f hadoop-slave$i &> /dev/null
echo "start hadoop-slave$i container..."
docker run -itd \
--net=hadoop \
--name hadoop-slave$i \
--hostname hadoop-slave$i \
irm/hadoop-cluster-base
i=$(( $i + 1 ))
done
# start hadoop master container
docker rm -f hadoop-master &> /dev/null
echo "start hadoop-master container..."
docker run -itd \
--net=hadoop \
-p 50070:50070 \
-p 8088:8088 \
-p 18080:18080 \
--name hadoop-master \
--hostname hadoop-master \
-v $PWD/data:/data \
irm/hadoop-cluster-master
echo "Making jobs. Please wait"
while [ ! -d data/locations_most_actives ]
do
sleep 10
#echo "Waiting..."
done
echo "Stoping cluster..."
docker stop hadoop-master
i=1
while [ $i -lt $N ]
do
docker stop hadoop-slave$i
i=$(( $i + 1 ))
donePara que Spark funcione correctamente debemos incluir unos parámetros nuevos en el fichero de configuración de Yarn.
El fichero está en la ruta docker/base/config/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>A continuación el fichero de configuración de Spark. En el configuramos la memoria disponible para la ejecución de Spark. Recordar que Spark necesita mucha memoria. Bueno, dependiendo del volumen de los conjuntos de datos que se vayan a procesar. Spark usa memoria para trabajar más rápido, por lo que es necesario asignar la memoria suficiente para que pueda funcionar correctamente. También se configuran las rutas de logs en HDFS y el puerto del history server.
El fichero de logs se encuentra en la ruta docker/master/config/spark-defaults.conf
spark.master yarn
spark.driver.memory 512m
spark.yarn.am.memory 512m
spark.executor.memory 512m
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-master:9000/spark-logs
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
spark.history.fs.logDirectory hdfs://hadoop-master:9000/spark-logs
spark.history.fs.update.interval 10s
spark.history.ui.port 18080
Ahora es el turno del proceso de Scala que procesará los datos. Para trabajar con Scala he usado IntelliJ IDEA Community Edition con el plugin de Scala. En un futuro Post publicaré un tutorial para configurar el entorno de desarrollo con Scala, aunque haciendo un simple búsqueda hay mucho tutoriales. En src/StackAnswerScalaProject.zip he dejado el proyecto completo.
Este proceso realiza las mismas acciones que se realizaban en el post anterior con Hadoop y Hive, pero ahora unicamente con Scala sobre Spark.
import java.io.File
import org.apache.spark.sql.types.{IntegerType, StringType, StructType}
import org.apache.spark.sql.{SQLContext, SparkSession}
import org.apache.spark.sql.functions._
object StackAnswer {
def main(args: Array[String]): Unit = {
val namesFile = "hdfs:///user/root/input_names/user_ids_names"
val answersFile = "hdfs:///user/root/input_answers/user_ids_answers"
val pathWordCount = "hdfs:///user/root/user_ids_answers_wordcount"
val pathUsersMostActives = "hdfs:///user/root/users_most_actives"
val pathLocaltionsMostActives = "hdfs:///user/root/locations_most_actives"
val spark = SparkSession
.builder
.appName("StackAnswer")
.getOrCreate()
// configuramos los logs para que solo muestre errores
import org.apache.log4j.{Level, Logger}
val rootLogger = Logger.getRootLogger()
rootLogger.setLevel(Level.ERROR)
import spark.implicits._
// leemos el fichero con las respuestas y hacemos un count de los ids.
val readFileDF = spark.sparkContext.textFile(answersFile).toDF
val name_counts = readFileDF.groupBy("Value").count().orderBy($"count".desc)
val name_countsC = name_counts.coalesce(1)
name_countsC.write.csv(pathWordCount)
// leemos el fichero de con los nombres de los usuarios y sus localizaciones
val schemaNames = new StructType()
.add("user_id", IntegerType,true)
.add("name", StringType,true)
.add("reputation", IntegerType, true)
.add("location", StringType, true)
val userDataDF = spark.read
.option("sep", ",")
.option("header", false)
.schema(schemaNames)
.csv(namesFile)
// eliminamos las filas duplicadas
val userDataCleanedDF = userDataDF.dropDuplicates()
// hacemos un join de los datos
val dataUsersAnswersDF = userDataCleanedDF.join(name_counts, userDataCleanedDF("user_id") === name_counts("Value"), "inner").drop("Value")
val usersMostActivesDF = dataUsersAnswersDF.select($"user_id", $"name", $"count".as("n_answers")).coalesce(1)
usersMostActivesDF.write.csv(pathUsersMostActives)
val dataLocationsMostActivesDF = dataUsersAnswersDF
.groupBy("location")
.sum("count")
.select($"location", $"sum(count)".as("n_answres"))
.orderBy(desc("n_answres"))
.coalesce(1)
dataLocationsMostActivesDF.write.csv(pathLocaltionsMostActives)
}
}Dentro de IntelliJ generamos el fichero jar que usaremos para lanzar el trabajo de Spark. En el repositorio de GitHub el jar se encuentra en docker/master/bin/stackanswer_2.12-1.0.jar.
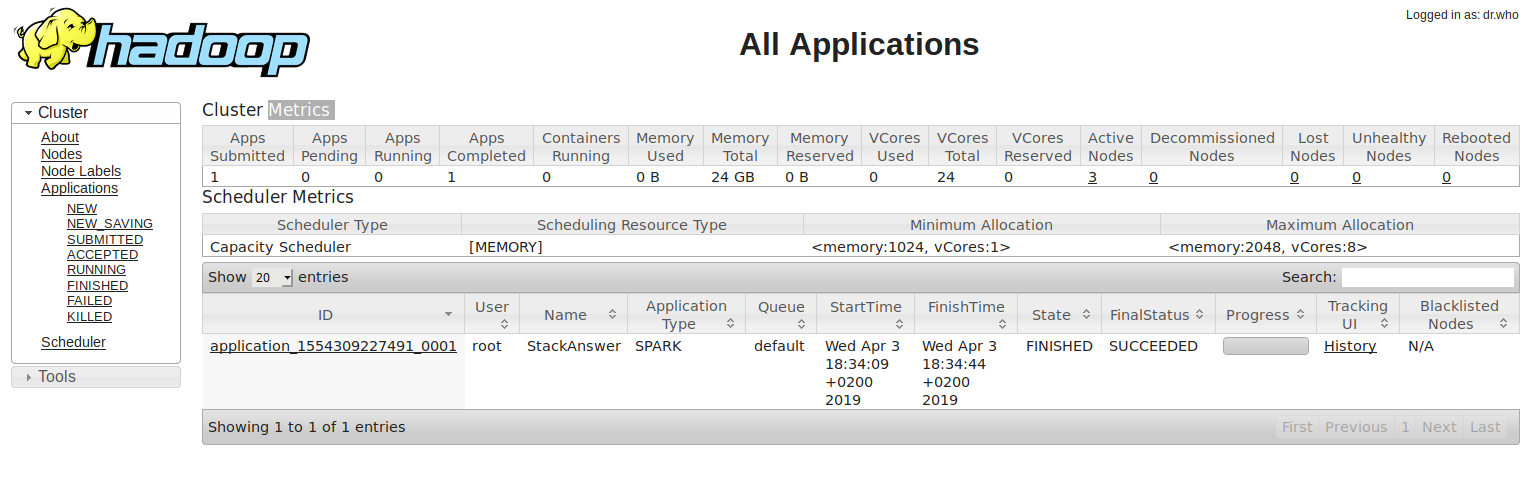
El proceso se lanzará automáticamente al ejecutar el cluster. En la siguiente imagen podemos la ejecución del trabajo de Spark en el Yarn de nuestro cluster hadoop
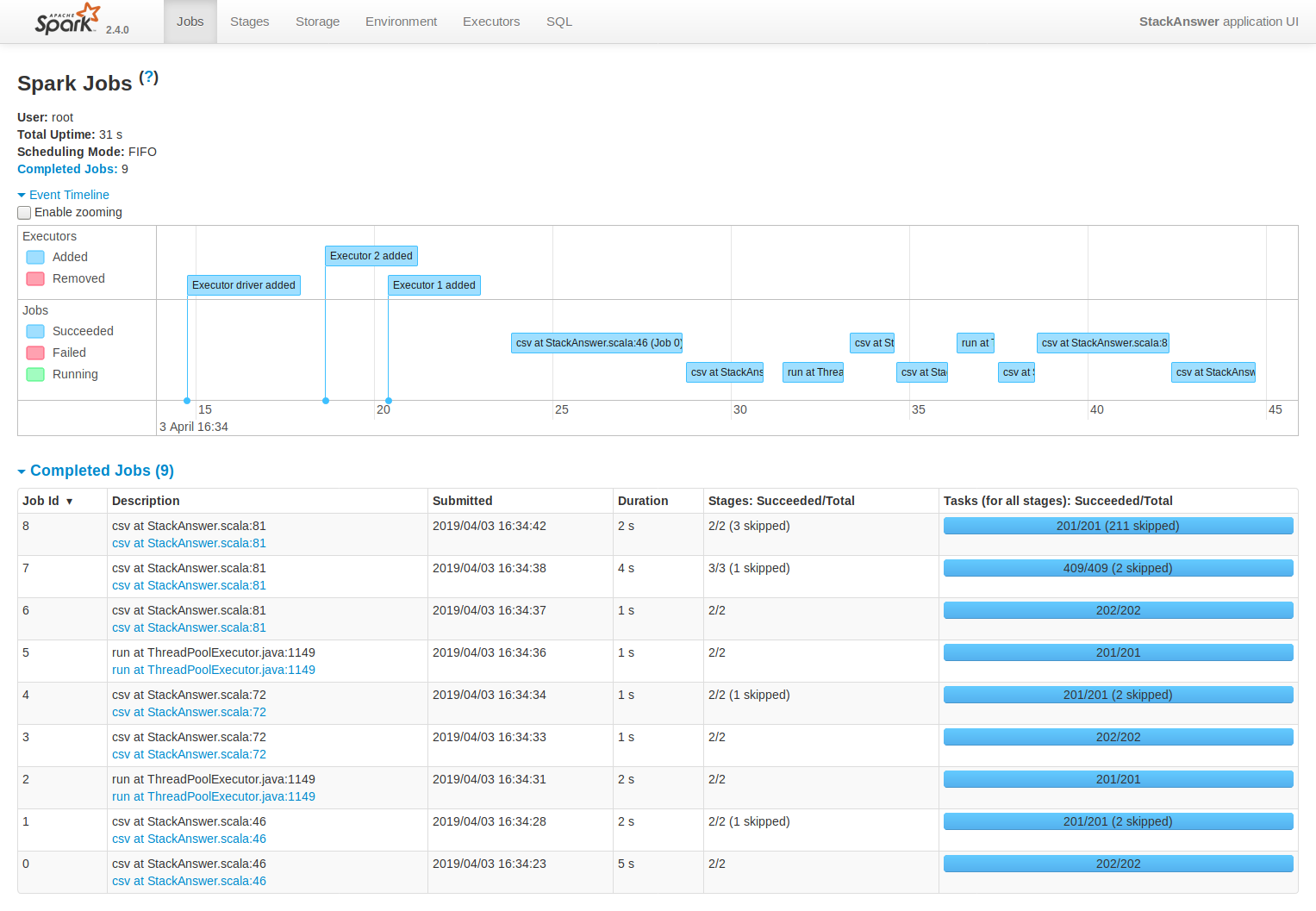
En esta imagen se puede ver timeline de la ejecución en el History server de Spark
Con esto estaría todo. Como hemos podido ver, teniendo un cluster Hadoop, incluir Spark para que ejecute trabajos dentro del cluster es bastante sencillo. Spark nos ofrece una velocidad de procesamiento muy superior a las operaciones de MapReduce de hadoop.