A maze solver simulation using Q Learning algorithm.
Codes
Demo
Report Bug
·
Request Feature

This project made as a class assignment. Its purpose is basically make the computer learn how to solve the maze with Q-Learning algorithm. It coded on unity with c#.
Features:
- You can run the simulation with and see what happens
- You can generate random mazes with prim algorithm for more info -> https://en.wikipedia.org/wiki/Maze_generation_algorithm#Randomized_Prim%27s_algorithm
- You can slow it down, make the maze bigger , play with some metrics
- You can print the Q Table when the desired epoch reached
Q-learning is a model-free reinforcement learning algorithm. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. It does not require a model (hence the connotation "model-free") of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations.
For any finite Markov decision process (FMDP), Q-learning finds a policy that is optimal in the sense that it maximizes the expected value of the total reward over any and all successive steps, starting from the current state. Q-learning can identify an optimal action-selection policy for any given FMDP, given infinite exploration time and a partly-random policy. "Q" names the function that returns the reward used to provide the reinforcement and can be said to stand for the "quality" of an action taken in a given state.
To get a local copy up and running follow these simple steps.
- Clone the repo
git clone https://github.com/izzettunc/Q-Learning-Maze-Solver.git-
Open the project with Unity
-
Make changes, run it, use it whatever you like 😄
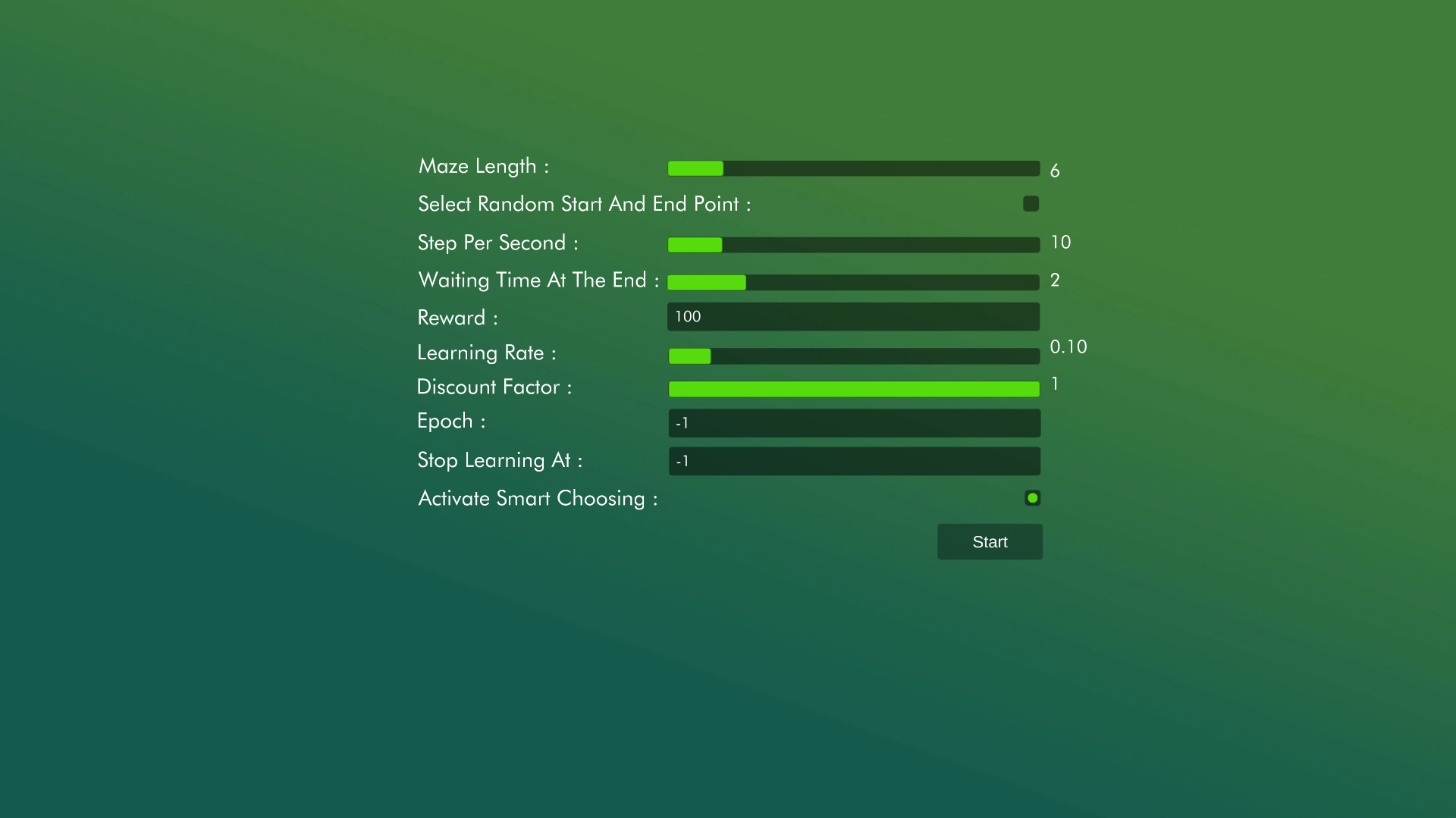
- Select your settings and play start.
- If you bored or want to change the settings then press back button on bottom left.


Unnecessary information for settings
- Maze Length : Changes size of the maze its range changes between 3 to 25 for best view experience.
- Select Random Start And End Point : Randomize start and end point.
- Step Per Second : Changes how much step will be processed for second you can speed it up by increasing or slow it down by keeping it in 0 - 1 range.
- Waiting Time At The End : Changes how much time the simulation is going to wait when character reaches the end.
- Reward : Reward value in the reward table for Q Learning algorithm.
- Learning Rate : https://en.wikipedia.org/wiki/Learning_rate ( Changes between 0 and 1 )
- Discount Rate : https://en.wikipedia.org/wiki/Q-learning#Discount_factor ( Changes between 0 and 1 )
- Epoch : Determines how many times character have to reach end. ( -1 for limitless epoch )
- Stop Learning At: Determines when the character stops learning. This setting has no relevance with the algorithm. I added it just for fun. (-1 for limitless)
- Activate Smart Choosing : Activates smart choosing. This setting has no relevance with the algorithm. I misunderstood the algorithm and look for one step further while selecting the best Q value and in the end I couldn't delete it and add it as a feature.
See the open issues for a list of proposed features (and known issues).
Distributed under the MIT License. See LICENSE for more information.
İzzet Tunç - izzet.tunc1997@gmail.com