A news classfication application that uses three different NLP classfication algorithm.
Report Bug
·
Request Feature
- About the Project
- Getting Started
- Usage
- Input structure
- Comparison Of Methods
- Roadmap
- License
- Contact

This project made as a class assignment.Its purpose is basically classifying given test data by learned information from train data using classification algorithms.I use three different method for compare them between each other.These three algortihms are K-NN -that using four different distance method which them are Pearson Corelation Coefficient,Cosine Similarity,Euler Distance,Manhattan Distance- , Multinomial Naive Bayes and Rocchio -that using same distance methods as K-NN -
Features:
- You can classify any given text
- You can visualize train and test process with confusion matrix,performance matrix,accuracy and time metrics
- You can see which document assigned which class by algorithm
- You can print results in a txt file
In machine learning, naïve Bayes classifiers are a family of simple "probabilistic classifiers" based on applying Bayes' theorem with strong (naïve) independence assumptions between the features. They are among the simplest Bayesian network models. Naïve Bayes has been studied extensively since the 1960s. It was introduced (though not under that name) into the text retrieval community in the early 1960s, and remains a popular (baseline) method for text categorization, the problem of judging documents as belonging to one category or the other (such as spam or legitimate, sports or politics, etc.) with word frequencies as the features. With appropriate pre-processing, it is competitive in this domain with more advanced methods including support vector machines.
Multinomial Naive Bayes is a specialized version of Naive Bayes that is designed more for text documents. Whereas simple naive Bayes would model a document as the presence and absence of particular words, multinomial naive bayes explicitly models the word counts and adjusts the underlying calculations to deal with in.
In machine learning, a nearest centroid classifier or nearest prototype classifier is a classification model that assigns to observations the label of the class of training samples whose mean (centroid) is closest to the observation. When applied to text classification using tf*idf vectors to represent documents, the nearest centroid classifier is known as the Rocchio classifier because of its similarity to the Rocchio algorithm for relevance feedback. An extended version of the nearest centroid classifier has found applications in the medical domain, specifically classification of tumors.
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression:
In k-NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
In k-NN regression, the output is the property value for the object. This value is the average of the values of k nearest neighbors.
k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification.
Both for classification and regression, a useful technique can be to assign weights to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of 1/d, where d is the distance to the neighbor.
The neighbors are taken from a set of objects for which the class (for k-NN classification) or the object property value (for k-NN regression) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.
To get a local copy up and running follow these simple steps.
- Clone the repo
git clone https://github.com/izzettunc/newsClassification.git-
Open newsClassification.sln with Visual Studio
-
Restore nuget packages How to restore nuget packages ?
-
Make changes, run it, use it whatever you like 😄
I use 2 different github project while devoloping this app.If you want ta scrap this project and use classes independetly make sure to add BigFloat for Multinomial Naive Bayes and Nuve for tokenizer.
-
I use BigFloat because while calculating ratios and probabilities of documents in MN Bayes result become so small that doesn't fit in double, real or float variable type
-
I use Nuve in Tokenizer for stemming Turkish words
Make sure to add System.Numerics assembly reference to your project if you wanna use BigFloat. Because BigInteger used while developing BigFloat.
Make sure to install Nuve to your project if you wanna use Nuve in your project
Here is some unneeded screenshots for how to use it
- Select training files root folder Don't forget! Input should look like Input structure
- Select test files root folder Don't forget! Input should look like Input structure
- If it's real data check unlabeled checkbox
- Select stop words file Don't forget! Input should look like Input structure
- Check at least one classification method checkbox If you select K-NN you must also select distance function and K value, If you select rocchio selecting distance function will be enough.In case of both K-NN and Rocchio selection both method will use same distance function
- Press start
- Also you can open up visual if you close it accidently by clicking visualize
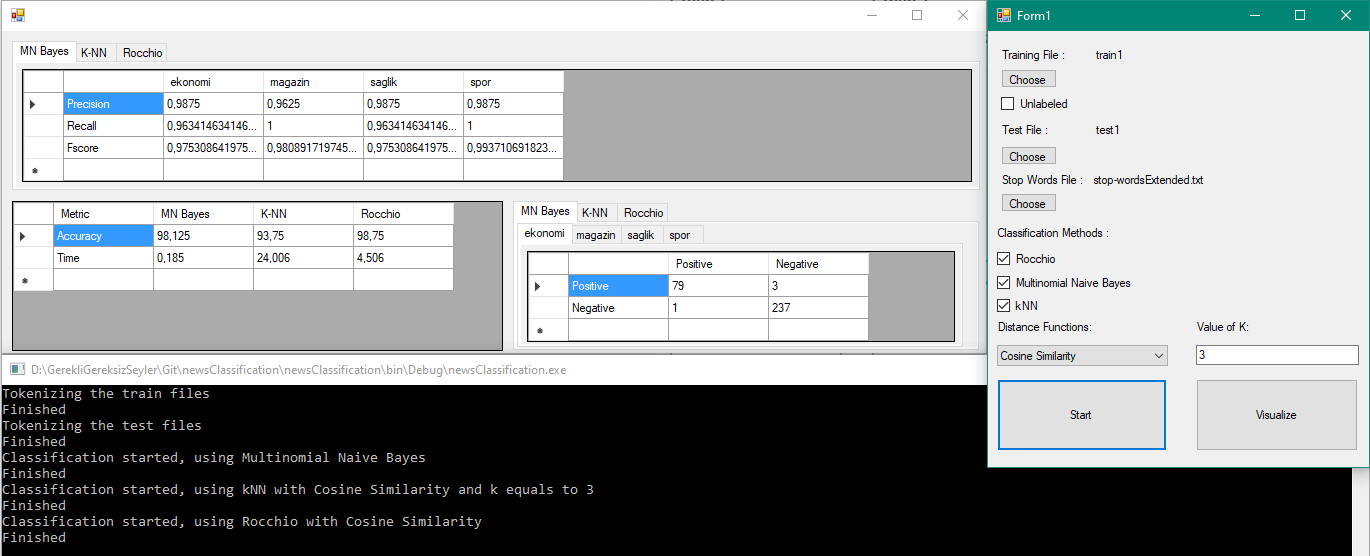

For every method you select app will be ask to you where it should save results. If you don't want to save result simply close to pop-up and app will continue.

If you save the result. Result will be in csv format and contains documents and assigned classes of them. Also last row will be name of the method and execution time

While reading input files(train and test) I basically use DFS like algorithm to get each and every input file in every folder. So if you change input app won't going to work.
Input Structure:
rootFolder (Name is not important)
|
|- className1
| |
| |-Text files(Name is not important)
|
|- className2
| |
| |-Text files(Name is not important)
|
|- className3
| |
| |-Text files(Name is not important)
For stop words there isn't any real structure but I split words by lines so structure is look like this :
word1
word2
word3
..
..
..
wordN
Lastly if you don't want to use stop word an empty text file will be solution for you.
The data is different news which is retrieved from several news website. There is 4 class Economy(Ekonomi),Magazine(Magazine),Health(Sağlık),Sport(Spor).Train data consists of 600 documents and Test data consists of 320 documents. All the documents are in Turkish. Documents are not in a format and there is misspellings, foreign words, brand names etc.





See the open issues for a list of proposed features (and known issues).
Distributed under the MIT License. See LICENSE for more information.
İzzet Tunç - izzet.tunc1997@gmail.com