
In this code pattern, we will use a Jupyter notebook with Watson Studio to glean insights from a vast body of unstructured data. We'll start with data exported from Facebook Analytics. We'll use Watson’s Natural Language Understanding and Visual Recognition to enrich the data.
We'll use the enriched data to answer questions like:
What emotion is most prevalent in the posts with the highest engagement?
What sentiment has the higher engagement score on average?
What are the top keywords, entities or images measured by total reach?
These types of insights are especially beneficial for marketing analysts who are interested in understanding and improving brand perception, product performance, customer satisfaction, and ways to engage their audiences.
It is important to note that this code pattern is meant to be used as a guided experiment, rather than an application with one set output. The standard Facebook Analytics export features text from posts, articles, and thumbnails, along with standard Facebook performance metrics such as likes, shares, and impressions. This unstructured content was then enriched with Watson APIs to extract keywords, entities, sentiment, and emotion.
After the data is enriched with Watson APIs, we'll use the Cognos Dashboard Embedded service to add a dashboard to the project. Using the dashboard you can explore our results and build your own sophisticated visualizations to communicate the insights you've discovered.
This code pattern provides mock Facebook data, a notebook, and comes with several pre-built visualizations to jump start you with uncovering hidden insights.
When the reader has completed this code pattern, they will understand how to:
- Read external data in to a Jupyter Notebook via Object Storage and pandas DataFrames.
- Use a Jupyter notebook and Watson APIs to enrich unstructured data.
- Write data from a pandas DataFrame in a Jupyter Notebook out to a file in Object Storage.
- Visualize and explore the enriched data.

- A CSV file exported from Facebook Analytics is added to Object Storage.
- Generated code makes the file accessible as a pandas DataFrame.
- The data is enriched with Watson Natural Language Understanding.
- The data is enriched with Watson Visual Recognition.
- Use a dashboard to visualize the enriched data and uncover hidden insights.
- IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
- IBM Watson Natural Language Understanding: Natural language processing for advanced text analysis.
- IBM Watson Visual Recognition: Understand image content.
- IBM Cognos Dashboard Embedded: The IBM Cognos Dashboard Embedded lets you, the developer, painlessly add end-to-end data visualization capabilities to your application.
- IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market.
- Jupyter Notebooks: An open-source web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text.
- pandas: A Python library providing high-performance, easy-to-use data structures.
- Beautiful Soup: Beautiful Soup is a Python library for pulling data out of HTML and XML files.
Follow these steps to setup and run this code pattern. The steps are described in detail below.
- Clone the repo
- Create a new Watson Studio project
- Add services to the project
- Create the notebook in Watson Studio
- Add credentials
- Add the CSV file
- Run the notebook
- Add a dashboard to the project
- Analyze the results
Clone the pixiedust-facebook-analysis repo locally. In a terminal, run the following command:
git clone https://github.com/IBM/pixiedust-facebook-analysis.git-
Log into IBM's Watson Studio. Once in, you'll land on the dashboard.
-
Create a new project by clicking
New project +and then click onCreate an empty project. -
Enter a project name.
-
Choose an existing Object Storage instance or create a new one.
-
Click
Create. -
Upon a successful project creation, you are taken to the project
Overviewtab. Take note of theAssetsandSettingstabs, we'll be using them to associate our project with any external assets (datasets and notebooks) and any IBM cloud services.

-
Associate the project with Watson services. To create an instance of each service, go to the
Settingstab in the new project and scroll down toAssociated Services. ClickAdd serviceand selectWatsonfrom the drop-down menu. Add the service using the freeLiteplan. Repeat for each of the services used in this pattern:- Natural Language Understanding
- Visual Recognition (optional)
-
Once your services are created, copy the credentials and save them for later. You will use them in your Jupyter notebook.
- Use the upper-left
☰menu, and selectServices > My Services. - Use the 3-dot actions menu to select
Manage in IBM Cloudfor each service. - Copy each
API keyandURLto use in the notebook.
- Use the upper-left
-
Go back to your Watson Studio project by using your browser's back button or use the upper-left
☰menu, and selectProjectsand open your project. -
Select the
Overviewtab, clickAdd to project +on the top right and choose theNotebookasset type.
-
Fill in the following information:
- Select the
From URLtab. [1] - Enter a
Namefor the notebook and optionally a description. [2] - For
Select runtimeselect theDefault Python 3.6 Freeoption. [3] - Under
Notebook URLprovide the following url [4]:
https://raw.githubusercontent.com/IBM/pixiedust-facebook-analysis/master/notebooks/pixiedust_facebook_analysis.ipynb
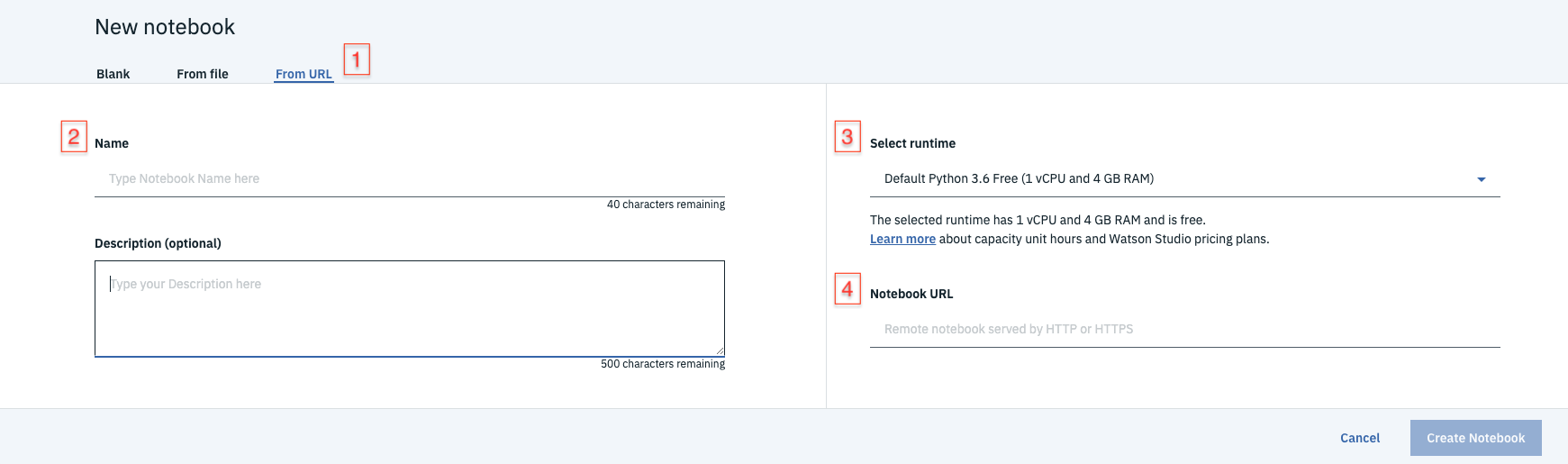
- Select the
-
Click the
Create notebookbutton.TIP: Your notebook will appear in the
Notebookssection of theAssetstab.


Find the notebook cell after 1.5. Add Service Credentials From IBM Cloud for Watson Services.
Set the API key and URL for each service.

Note: This cell is marked as a
hidden_cellbecause it will contain sensitive credentials.
Use Find and Add Data (look for the 01/00 icon) and its Files tab. From there you can click browse and add a .csv file from your computer.

Note: If you don't have your own data, you can use our example by cloning this git repo. Look in the
datadirectory.
Find the notebook cell after 2.1 Load data from Object Storage. Place your cursor after # **Insert to code > Insert pandas DataFrame**. Make sure this cell is selected before inserting code.
Using the file that you added above (under the 01/00 Files tab), use the Insert to code drop-down menu. Select pandas DataFrame from the drop-down menu.

Note: This cell is marked as a
hidden_cellbecause it contains sensitive credentials.

The inserted code includes a generated method with credentials and then calls the generated method to set a variable with a name like df_data_1. If you do additional inserts, the method can be re-used and the variable will change (e.g. df_data_2).
Later in the notebook, we set df = df_data_1. So you might need to fix the variable name df_data_1 to match your inserted code or vice versa.
We want to write the enriched file to the same container that we used above. So now we'll use the same file drop-down to insert credentials. We'll use them later when we write out the enriched CSV file.
After the df setup, there is a cell to enter the file credentials. Place your cursor after the # insert credentials for file - Change to credentials_1 line. Make sure this cell is selected before inserting credentials.
Use the CSV file's drop-down menu again. This time select Insert Credentials.

Note: This cell is marked as a
hidden_cellbecause it contains sensitive credentials.
The inserted code includes a dictionary with credentials assigned to a variable with a name like credentials_1. It may have a different name (e.g. credentials_2). Rename it or reassign it if needed. The notebook code assumes it will be credentials_1.
When a notebook is executed, what is actually happening is that each code cell in the notebook is executed, in order, from top to bottom.
Each code cell is selectable and is preceded by a tag in the left margin. The tag format is In [x]:. Depending on the state of the notebook, the x can be:
- A blank, this indicates that the cell has never been executed.
- A number, this number represents the relative order this code step was executed.
- A
*, this indicates that the cell is currently executing.
There are several ways to execute the code cells in your notebook:
- One cell at a time.
- Select the cell, and then press the
Playbutton in the toolbar.
- Select the cell, and then press the
- Batch mode, in sequential order.
- From the
Cellmenu bar, there are several options available. For example, you canRun Allcells in your notebook, or you canRun All Below, that will start executing from the first cell under the currently selected cell, and then continue executing all cells that follow.
- From the
- At a scheduled time.
- Press the
Schedulebutton located in the top right section of your notebook panel. Here you can schedule your notebook to be executed once at some future time, or repeatedly at your specified interval.
- Press the
- Go to the
Assetstab in the your Watson Studio project click on the01/00(Find and add data) icon. - Select the
enriched_example_facebook_data.csvfile and use the 3-dot pull-down to selectAdd as data asset.
- Go to the
Settingstab in the new project and scroll down toAssociated Services. - Click
Add serviceand selectDashboardfrom the drop-down menu. - Create the service using the free
Liteplan.
- Click the
Add to project +button and selectDashboard. - Select the
From filetab and use theSelect filebutton to open the filedashboards/dashboard.jsonfrom your local repo. - Select your Cognos Dashboard Embedded service from the list.
- Hit
Create. - If you are asked to re-link the data set, select your
enriched_example_facebook_data.csvasset.
If you walk through the cells, you will see that we demonstrated how to do the following:
- Install external libraries from PyPI
- Create clients to connect to Watson cognitive services
- Load data from a local CSV file to a pandas DataFrame (via Object Storage)
- Do some data manipulation with pandas
- Use BeautifulSoup
- Use Natural Language Understanding
- Use Visual Recognition
- Save the enriched data in a CSV file in Object Storage
When you try the dashboard, you will see:
- How to add a dashboard to a Watson Studio project
- How to import a dashboard JSON file
- Linking a dashboard to data saved in Cloud Object Storage
- An example with tabs and a variety of charts
- A dashboard tool that you can use to explore your data and create new visualizations to share
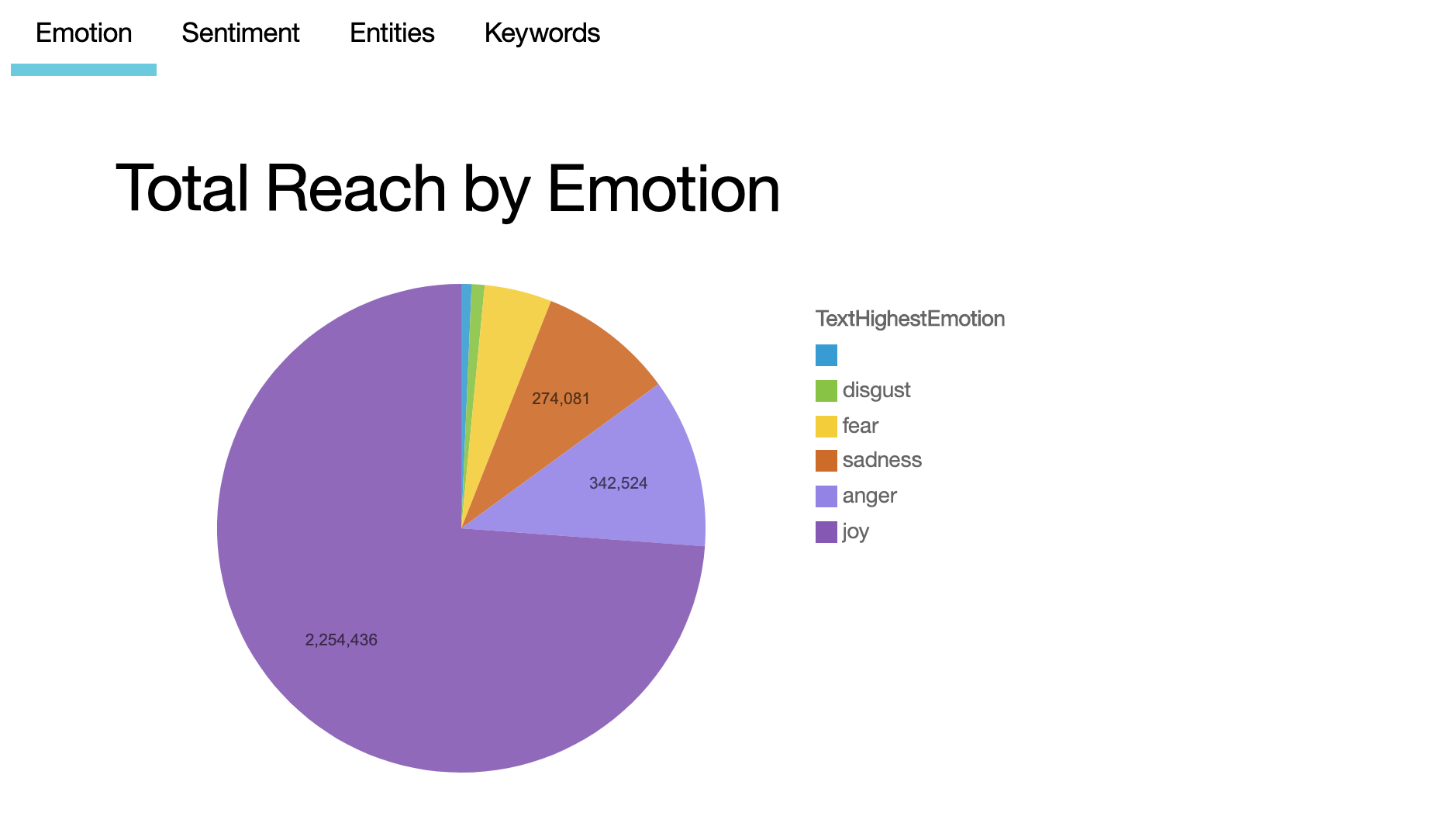
The provided dashboard uses four tabs to show four simple charts:
- Emotion
- Sentiment
- Entities
- Keywords
The enriched data contains emotions, sentiment, entities, and keywords that were added using Natural Language Understanding to process the posts, links, and thumbnails. Combining the enrichment with the metrics from Facebook gives us a huge number of options for what we could show on the dashboard. The dashboard editor also allows you great flexibility on how you arrange your dashboard and visualize your data. The example demonstrates the following:
-
A word-cloud showing the keywords sized by total impressions and using color to show the sentiment

-
A pie chart showing total reach by emotion
-
A stacked bar chart showing likes, shares, and comments by post sentiment
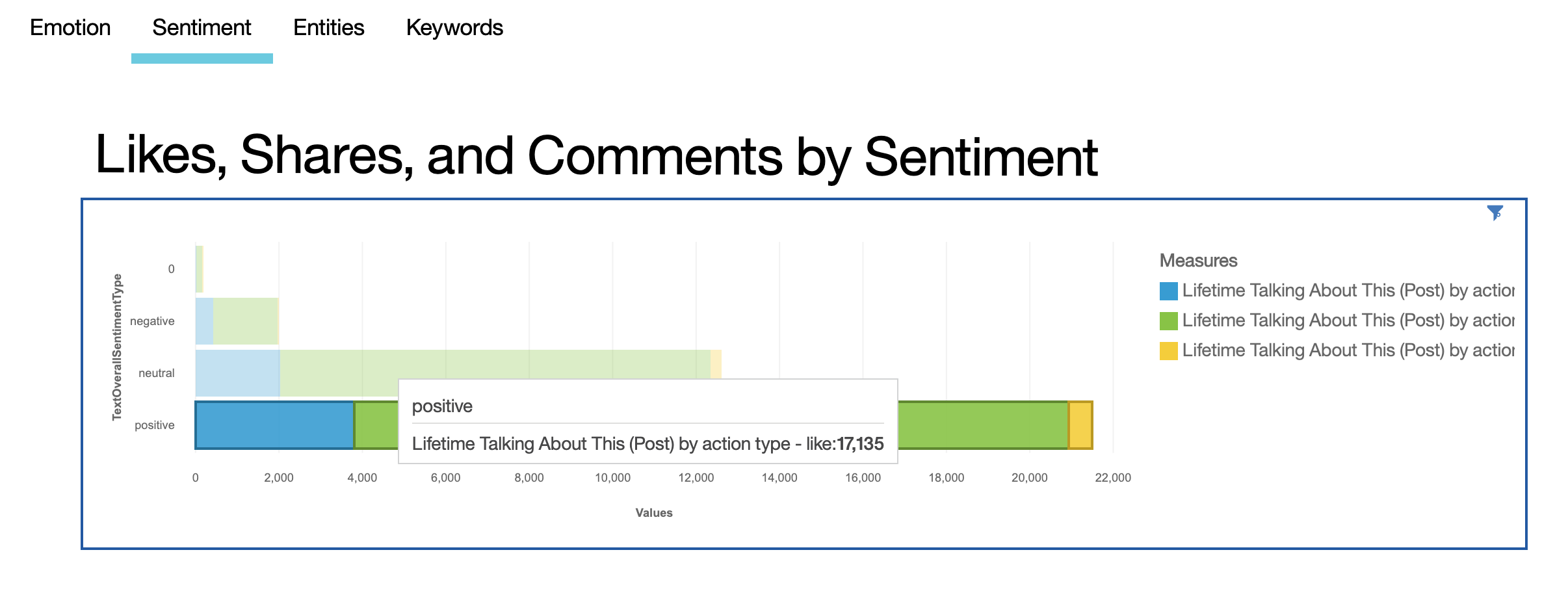
-
A bar chart with a line overlay, showing total impressions and paid impressions by mentioned entity
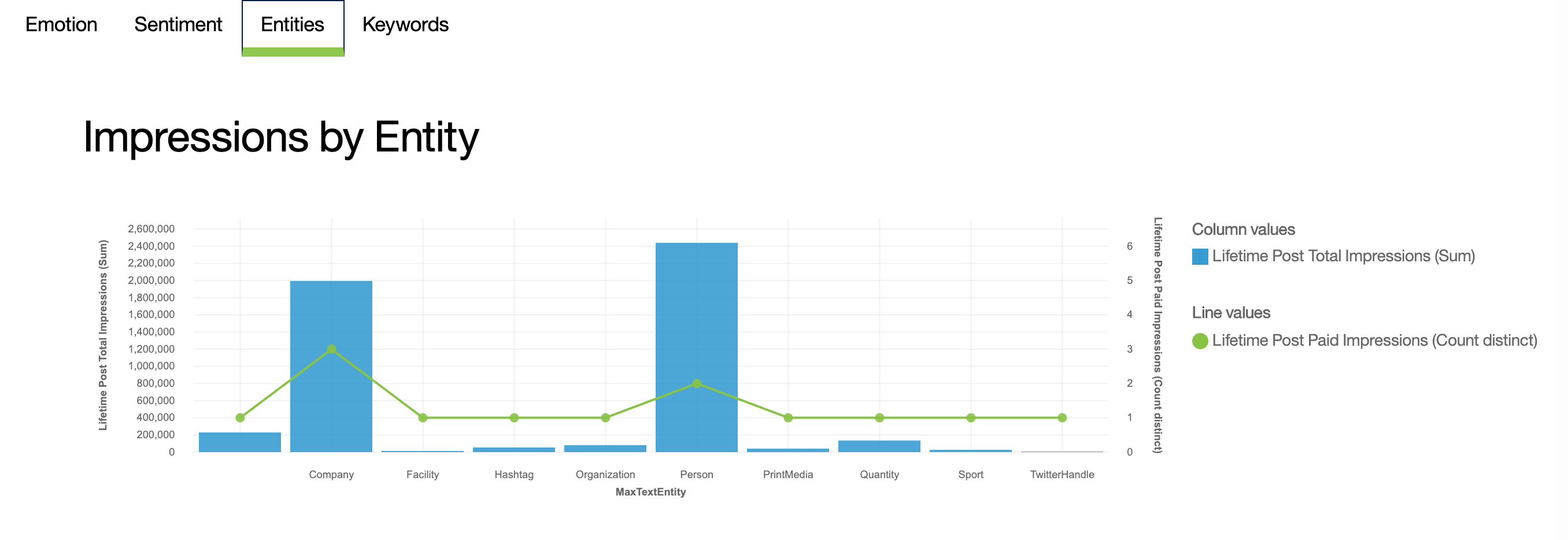




This code pattern is licensed under the Apache License, Version 2. Separate third-party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 and the Apache License, Version 2.