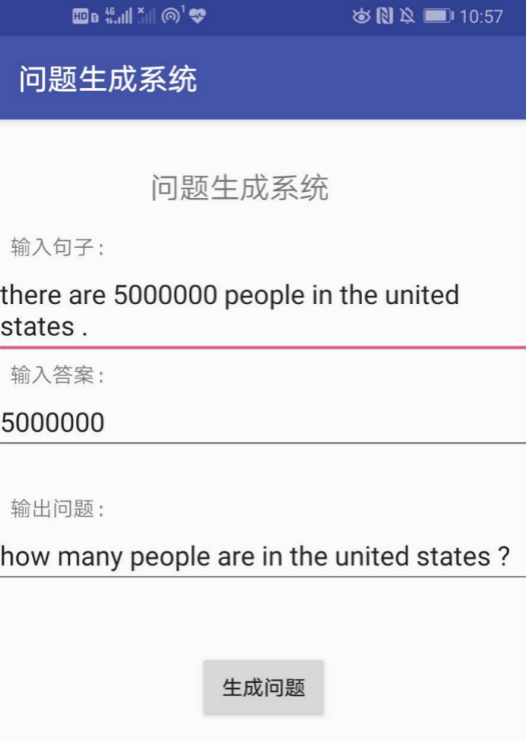
当前实验结果不理想,但确实是按照标准transformer实现的,有兴趣的大佬拿来做baseline的话提升空间应该会很大(手动滑稽)
作者目前在做别的QG研究,暂时无暇继续完善该项目,有兴趣的大佬可以直接fork,也欢迎在issue区留言或者直接找到作者的联系方式
使用Python版本 : Python3.6(其中模型评估部分脚本基于Python2.7)
使用深度学习框架 : Pytorch0.4.1
使用模型结构 : Transformer(详情参考论文《Attention Is All You Need》)
使用数据集 : SQuAD(可扩展到其它QG数据集)
./pipeline.sh [指定运行模式] [指定GPU]
0: 安装依赖包
1: 加载数据集
2: 数据预处理
3: 模型训练
4: 模型测试
5: 模型评估
6: 测试demo
可以同时指定多个运行模式,例如希望顺序执行 "3: 模型训练" 和 "4: 模型测试" 阶段,则命令为:
./pipeline.sh 23 [指定GPU]
其中 "2: 数据预处理" 会得到一个pt文件,其中包含了所有参数集合,
之后的 "3: 模型训练" / "4: 模型测试" / "6: 测试demo" 均是从该pt文件中读取参数集合
使用第几块GPU,若当前无可用GPU会自动转换为CPU模式
链接: https://pan.baidu.com/s/1JKaHR5mde8GGxYRXk33rSw
提取码: b95w
其中包含了所有原始数据和经过步骤1/2后得到的处理过后的数据,将数据放在新建的data文件夹中,即data/squad/
(其中原始数据由Song et al., 2018提供,相关论文为《Leveraging Context Information for Natural Question Generation》)
/src : 存储源代码
/data : 存储原始数据
/checkpoint : 存储训练好的模型参数(需要时会自动创建)
/output : 存储预测文件(需要时会自动创建)
/evaluate : 评价结果的脚本,包含BLEU/METEOR/ROUGH-L(由Du et al., 2017提供)
/image : 存储README.md中所用到的图片
load_dataset.py : 读取原始数据构造成文本形式(只针对SQuAD数据集)
preprocess.py : 数据预处理
train.py : 模型训练+验证
test.py : 模型测试
demo.py : demo测试
app.py : 开启后端服务器(flask框架)
vocab.py : Vocab类(构造任务所使用词表)
dataset.py : Dataset类(将数据构造成batch形式)
transformer.py : Model类(Transformer模型)
rnnsearch.py : Model类(RNNSearch模型)
optimizer.py : Optimizer类(训练模型所使用优化器)
beam.py : Beam类(模型测试时所使用beam search)
logger.py : logger方法(项目所使用的日志输出器)
params.py : params方法(项目所使用的参数集合)
pipeline.sh 运行脚本
requirements.txt : 需要安装的依赖包及对应版本
BLEU-1: 32.49
BLEU-2: 15.72
BLEU-3: 9.08
BLEU-4: 5.54
METEOR: 11.91
ROUGH-L: 32.67