======================
This program allows fast and automatic detection of the genre of audio/music files.
This project is NOT under active development.
======================
This document gives a quick overview on how to use this library in your projects.
For more technical details on what underlying technologies have been used in building this library, and how does this library work, read this post on my blog: genreXpose - Quick music audio genre recognition.
Download the whole project source from GitHub. Do this by clicking here. Once downloaded, extract the source to a directory of your choice.
The project has the following directory structure:
your-working-dir/
|
|-docs/
| |-README.md
|
|-genreXpose/
| |-graphs/
| |-test/
| |-ceps.py
| |-classifier.py
| |-config.cfg
| |-tester.py
| |-utils.py
|
|-LICENSE
|
|-requirements.txt
The genreXpose/ directory contains the main code-base. This directory also contains the config.cfg file which is used for the configuraton of the software.
graphs/will contain all the generated graphs. The graphs are an excellent indicator of the performance of the algorithm.test/houses all the tests.- The function of the other files will be explained in subsequent sections.
The docs/ directory contains all the relevant documentation of the software.
The LICENSE contains important copyright references and redistribution terms.
The requirements.txt file lists all the requirements that need to be satisfied in order to run this software.
To install the required packages use the following command:
$ pip install -r /path/to/requirements.txt
In particular, this software requires you to have the following:
- NumPy
- PyDub (+ffmpeg)
- SciPy
- scikit-learn
- scikits.statsmodels
- scikits.talkbox
All the configuraton can be done using the config.cfg file. This file follows a particular syntax for storing the configurations. Please respect the syntax if you want to avoid bugs.
This file contains three variables that the user can modify as per his need. Comments begin with a # symbol and run till the end of a line. Rest everything is supposed to be valid configuration data.
The variables are:
GENRE_DIR- This is directory where the music dataset is located (GTZAN dataset)TEST_DIR- This is the directory where the test music is locatedGENRE_LIST- This is a list of the available genre types that you can use. Modify this list if you want to work with a subset of the available genres.
Set these three variables according to your system before proceeding to the next steps.
The dataset used for training the model is the GTZAN dataset. A brief of the data set:
- This dataset was used for the well known paper in genre classification " Musical genre classification of audio signals " by G. Tzanetakis and P. Cook in IEEE Transactions on Audio and Speech Processing 2002.
- The files were collected in 2000-2001 from a variety of sources including personal CDs, radio, microphone recordings, in order to represent a variety of recording conditions.
- The dataset consists of 1000 audio tracks each 30 seconds long. It contains 10 genres, each represented by 100 tracks. The tracks are all 22050Hz Mono 16-bit audio files in .wav format.
- Official web-page: marsyas.info
- Download size: Approximately 1.2GB
- Download link: Download the GTZAN genre collection
Since the files in the dataset are in the au format, which is lossy because of compression, they need to be converted in the wav format (which is lossless) before we proceed further.
NOTE: be sure to fully complete step 2 before moving further.
Now, the script ceps.py has to be run. This script analyzes and converts each file in the GTZAN dataset in a representation that can be used by the classifier and can be easily cached onto the disk. This little step prevents the classifier to convert the dataset each time the system is run.
The GTZAN dataset is used for training the classifier, which generates an in-memory regression model. This process is done by the LogisticRegression module of the scikit-learn library. The classifier.py script has been provided for this purpose. Once the model has been generated, we can use it to predict genres of other audio files. For effecient further use of the generated model, it is permanently serialized to the disk, and is deserialized when it needs to be used again. This simple process improves performance greatly. For serialization, the joblib module in the sklearn.externals package is used.
As of now, the classifier.py script must be run before any testing with unknown music can be done. Once the script is run, it will save the generated model at this path: ./saved_model/model_ceps.pkl. Once the model has been sucessfully saved, the classification script need not be run again until some newly labelled training data is available.
NOTE: be sure to fully complete step 2 and step 4 before moving further.
The tester.py script is used for the classification of new and unlabelled audio files. This script deserializes the previously cached model (stored at the path: ./saved_model/model_ceps.pkl) and uses it for classifying new audio files.
IMPORTANT NOTE: As of now, the classifier script must be run at least once before you run the testing script.
This is needed because the classifier script builds and saves the trained model to the disk.
When the classifier.py script is run, it generates and saves the trained model to the disk. This process also results in the creation of some graphs which are stored in the /graphs directory. The genereated graphs tell the performance of the classification process.
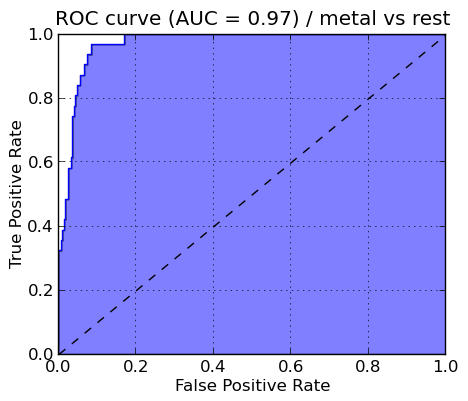
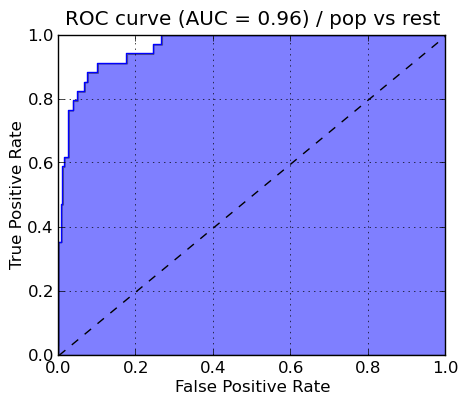
For each selected genre type, a ROC (Receiver Operating Characteristic) curve is generated and stored as a png file in the /graphs directory. The ROC curve is created by plotting the fraction of true positives out of the total actual positives (True positive rate) vs. the fraction of false positives out of the total actual negatives (False positive rate), at various threshold settings.
Some of the sample graphs are shown below alongwith their proper interpretation.
ROC curve of METAL genre
ROC curve of POP genre
To judge the overall performance, a confusion matrix is produced. A confusion matrix is a specific table layout that allows visualization of the performance of an algorithm. Each column of the matrix represents the instances in a predicted class, while each row represents the instances in an actual class.
The confusion matrix with all the genres selected is shown below.
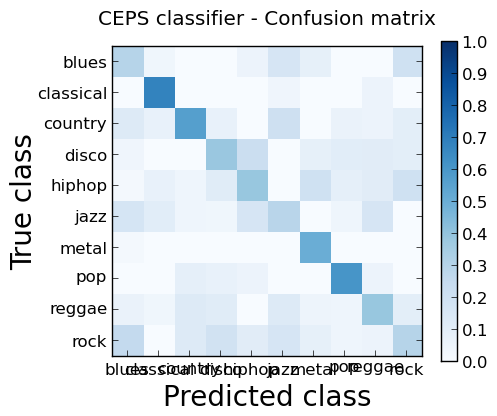
A spectrogram is a visual representation of the frequency content in a song. It shows the intensity of the frequencies on the y axis in the specified time intervals on the x axis; that is, the darker the color, the stronger the frequency is in the particular time window of the song.
Sample spectrograms of a few songs from the GTZAN dataset.
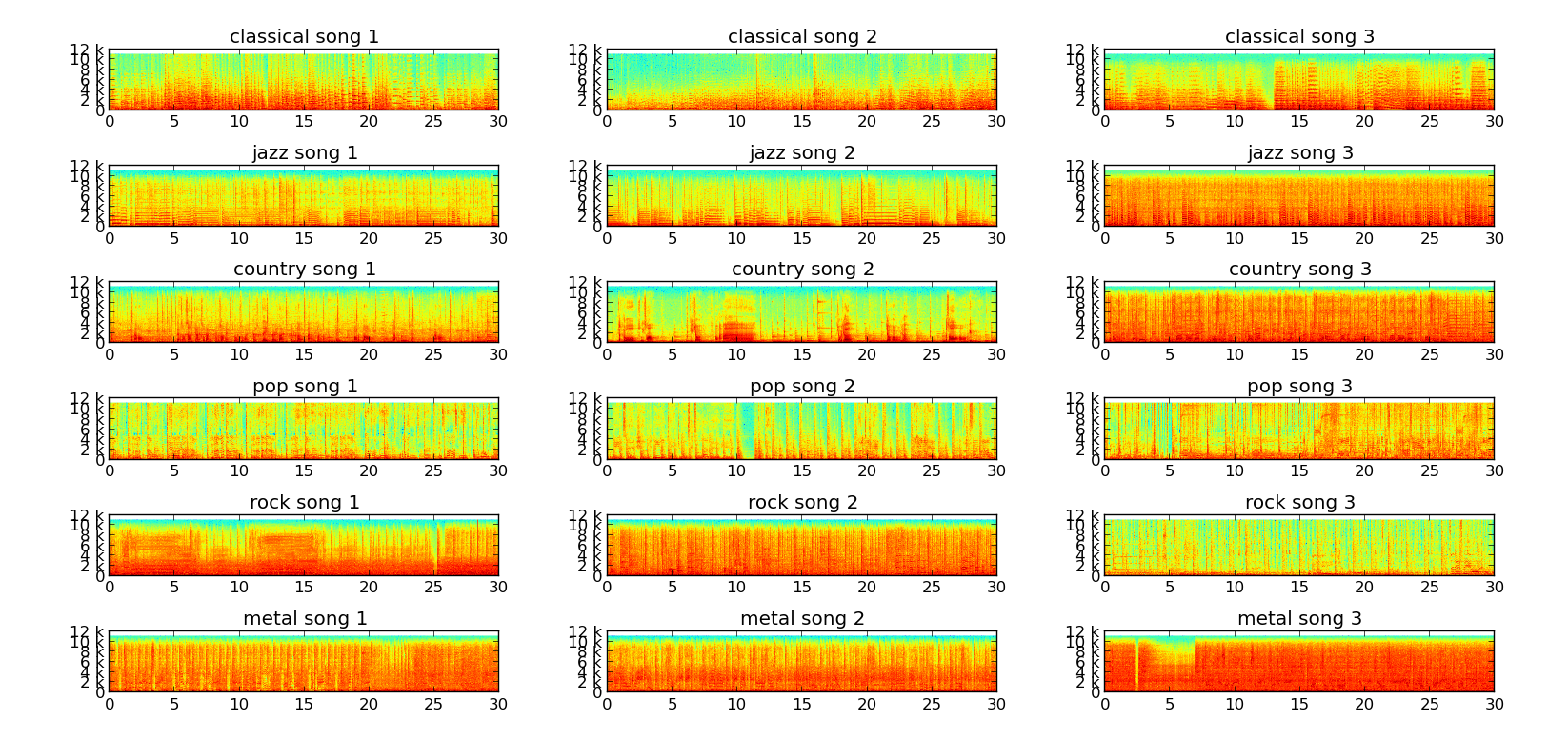
It can be clearly seen from the above image that songs belonging to the same genre have similar spectrograms. Keeping this in mind, we can easily design a classifier that can learn to differentiate between the different genres with sufficient accuracy.
MFCC = Mel Frequency Cepstral Coefficients
The Mel Frequency Cepstrum (MFC) encodes the power spectrum of a sound. It is calculated as the Fourier transform of the logarithm of the signal's spectrum. The Talkbox SciKit (scikits.talkbox) contains an implementation of of MFC that we can directly use. The data that we feed into the classifier is stored as ceps, which contain 13 coeffecients to uniquely represent an audio file.