Historically, deploying front-end user interfaces for machine learning models to the web has been extremely complicated. In many businesses that rely on machine learning for decision support or process automation, the team that designs and trains the machine learning models is seperate from the devops team that deploys those models.
Today, it is possible for forward-thinking businesses to empower their machine learning engineers to deploy their models without having to incur the overhead costs associated with having to rely on a devops support team. The key is to deploy machine learning models as serverless lambdas, taking advantage of the function-as-a-service trend in cloud computing.
In order to demonstrate how straightforward it has become for machine learning engineers to deploy their models, in this repository we'll be deploying a Single Shot Multibox Detector object detection machine learning model to the cloud as a serverless lambda using ZEIT Now.
ZEIT Now is the best choice for deploying serveless lambdas for several reasons:
-
The Now Platform is deployed on both AWS and GCP around the world.
-
Configuring human readable URLs for model deployments is very straightforward because you can buy domain names from ZEIT.
-
Converting existing apps to serverless instead of starting from scratch is possible due to ZEIT Now Builders.
-
Monorepo support: mix code in different programming languages easily.
- Clone this repository to your local development environment.
$ git clone https://github.com/jdamiba/object-detection.git
$ cd object-detection
- Deploy to
now.
$ now
- Go to your deployment URL.
Getting computers to be able to better recognize objects in images is one of the most popular applications of machine learning.
Classification algorithms take an image and return a single output- the probability distribution over the classes of objects the algorithm has been trained to know about.
In order to train a classification algorithm, you need to provide it with a dataset of images labeled by humans. Using this training dataset, the algorithm learns to recognize the objects that have been labeled in images it has never seen.
Classification algorithms can work well for images that only have one object of interest in them, but they are not very useful when there is more than one object of interest.
In order to get the computer to recognize distinct objects, we need to provide it with training data with ground-truth boxes drawn around the labeled objects in the image. Using this more detailed training dataset, an object detection algorithm can predict bounding boxes around objects in images it has never seen.
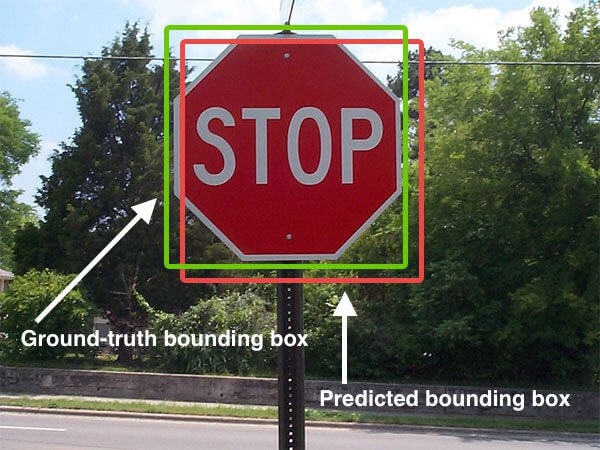
photo credit- pyimagesearch

photo credit- zeit blog
There are two approaches to generating bounding boxes around predicted objects in images using machine learning.
Traditional algorithms like Faster R-CNN use the region proposal method while the newer Single Shot Multibox Detector algorithm uses a fixed grid of detectors.
Region proposal object detection algorithms operate in two steps. First, the image is broken down into regions that are likely to contain an object.
Then, bounding box detectors are used to make a prediction in each proposed region.
Fixed-grid object detection algorithms break the image down into equally sized regions, and bounding box detectors are used to make predictions in each region. Since these algorithms don't have to first break the image down into irregular regions, they are considered to be one-shot algorithms relative to the two-step region proposal family of algorithms.
The major advantage of using a fixed-grid instead of proposing regions is that your bounding box detectors can be much more specialized in the former case than in the latter since they only need to worry about identifying objects in their region of the grid. Since a bounding box detector in a region proposal algorithm needs to be able to identify an object no matter where it appears in the image, it needs to be much more generalized than a bounding box detector that only has to worry about a small part of the image and can specialize in recognizing particular objects or shapes.
As a result of these architectural improvements, fixed-grid object detection algorithms can be trained more quickly and cheaply than other image recognition algorithms. This is especially true using neural networks like Google's MobileNetV2, which was designed to be performant in the context of CPU-constrained mobile computing devices.
A pre-trained version of a fixed-grid object detection algorithm developed by Liu et. al in 2016, the Single Shot Multibox Detector model, is made avalaible as part of Google's Tensorflow machine learning library.
The web application which will deploy the SSD model has six important concerns.
-
Allow users to upload an image. (FE)
-
Convert that image into a tensor. (BE)
-
Fetch a pre-trained version of SSDlite_MobileNetV2. (BE)
-
Run the tensor of the user's image through SSDlite_MobileNetV2. (BE)
-
Convert the tensor output by the neural network into x and y coordinates describing bounding boxes. (BE)
-
Draw bounding boxes around objects detected in the user's image and display the result. (FE)
Concerns 1 and 6 will be handled by the application's front-end, which will be written with HTML/CSS/JS using ZEIT's Next.js framework.
Concerns 2-5 will be handled by the application's back-end API, which will be written in JS and deployed as a serverless lambda alongside the front-end.
In a traditional client-server architecture, we would be able to use the ubiquitous @tensorflow/tfjs-node npm package in order to fetch a pre-trained version of the SSDlite_MobileNetV2 object detection machine learning model. This package provides a JavaScript implementation of the Tensorflow API that works in the Node.js runtime environment.
The function .loadModel() allows you to load a JSON object which describes a machine learning model. Helpfully, the Tensorflow library includes several pre-trained models. All we need to do is make a call to the Google Storage API and download the model we want into our web server's local memory.
Unfortunately, one of the limitations of serverless lambdas is that they are more memory-constrained than traditional web servers. Clocking in at over 100MB, the @tensorflow/tfjs-node library is too big for us to upload to a serverless lambda, which usually has a 50MB max size limit. In order to work around this limitation, we will use the tensorflow-lambda npm package developed by Luc Leray, which uses Google Brotli to compress @tensorflow/tfjs-node to a manageable size.
Using JavaScript's new async/await syntax, we can use the tensorflow-lambda library to load our pre-trained machine learning model in our severless lambda.
Caching the pre-trained model object detection model in local storage the first time the lambda is invoked comes with some small CPU overhead but provides a significant performance benefit for users who will persist their connection with the lambda.
const loadTf = require('tensorflow-lambda')
let tfModelCache;
async function loadModel() {
try {
const tf = await loadTf()
if (tfModelCache) {
return tfModelCache
}
tfModelCache = await tf.loadGraphModel(`${https://storage.googleapis.com/tfjs-models/savedmodel/ssdlite_mobilenet_v2}/model.json`)
return tfModelCache
} catch (err) {
console.log(err)
throw BadRequestError('The model could not be loaded')
}
}async function predict(tfModel, tensor) {
const tf = await loadTf()
const batched = await tf.tidy(() => tensor.expandDims())
const result = await tfModel.executeAsync(batched)
const scores = result[0].arraySync()[0]
const boxes = result[1].dataSync()
batched.dispose()
tf.dispose(result)
return { scores, boxes }
}The application's back-end will serve an object detection API at the route /predict.
Our front-end interface is divided into two parts- a sidebar with an input section where images can be uploaded and a display area where the results are presented to the user.
When an image is uploaded, the front-end makes an API call to the back-end. Hopefully, it recieves as a response a JavaScript object which describes where it should draw bounding boxes.
For example, this image would return the following:
[
{
"bbox": [{ "x": 205.61, "y": 315.36 }, { "x": 302.98, "y": 345.72 }],
"class": "airplane",
"score": 0.736
}
]In case users don't have an image handy, we'll provide them with options pulled from a public image API in the sidebar.
Instructions for using the app will also be in the sidebar.
Now is a global serverless deployment platform, which means that it allows you to deploy machine learning models to the web without having to configure and manage a traditional web server.
It can be installed as a command line utilty using npm or yarn.
To deploy your applications, you simply run the now command in the terminal. Deployment settings can be managed by adding a now.json file in the root of your project directory.
Get a feel for how easy it is to deploy sites to the web using Now:
-
mkdir my_first_app && cd my_first_app -
cat > index.html -
<h1>hello, world!</h1> -
now