Super offers a zero-config and zero-code entry to your Cloud. It
does so by running normal UNIX command lines against Cloud data,
using Cloud compute. Super takes care of hooking these complex and
disparate resources together under one command: super run.
🚀 Take me to the Installation Instructions
- Exploring Big Data with a CLI
- Bash the Cloud
- Analyzing Big Data with
grepandawk - Using IBM Cloud Code Engine to Analyze Big Data without Writing a Single Line of Code
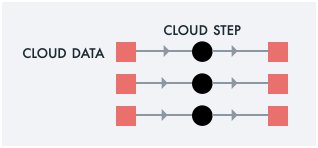
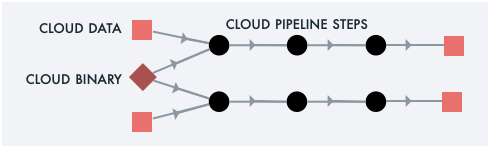
For example, Super can copy a set of files from one place in the Cloud to another.
super run -- cp /s3/ibm/default/src/foo*.txt /s3/aws/dstBehind the scenes, Super spawns Cloud Compute to mediate the
Cloud-to-Cloud data transfer. It uses
"glob" patterns to
determine how many concurrent jobs to run. For example, if foo*.txt
matches 5 files, Super spawns a set of concurrent jobs, grants each
job the least privilege to access its assigned files, and more!
Because Super intelligently parses your command line, it can automatically inject progress trackers. Super tracks the progress of any job against your Cloud data.

Super leverges any Kubernetes cluster for Compute and any S3
provider for Data. If you wish to target a very large cluster, Super
integrates with IBM Cloud Code
Engine. It also can hook your
Compute jobs up with IBM Cloud Object
Storage. The super up command gives you an easy way to
leverage both.
There is no need to code to the Cloud API of the week to make any of this happen.
Click on an image for more detail on that use case.
| macOS | Others |
|---|---|
brew tap IBM/super https://github.com/IBM/super
brew install super
super |
Coming soon |
You should now see usage information for Super, including the main
sub-command: super run.
Out of the box, super run will use your current Kubernetes
context as the target for Compute, and will have read-only access to
public S3 buckets.
If this works for you, then try super run -p5 -- echo hello. Above, we used a glob pattern to specify the
Cloud jobs we needed; here, since we are not pulling in Cloud data, we
instead use -p5 to specify that we want to execute the given command
line as five Cloud jobs.


To browse for interesting CommonCrawl
input data, you may use super browse cc. Super pipelines can access
S3 data via a pseudo /s3 filepath; e.g. /s3/aws/commoncrawl is the
prefix for CommonCrawl data.
By default, super run will target jobs against your currently
selected Kubernetes context. You may switch contexts using standard
kubectl commands. Strictly for convenience, Super offers super target to smooth the enumeration and selection of a context. In
particular, if you are using IBM Cloud Code Engine, the super target
command seamlessly integrates with CodeEngine projects.

The super up command will attempt to
connect super run to your AWS credentials and to IBM Cloud. The
latter allows super run to scale to a large Kubernetes cluster with
hundreds of nodes, via IBM Cloud Code
Engine; super up can also
connect you to your IBM Cloud Object
Storage instances.