-
Probabilistic Data Structure - there is a chance for false positives, but it is very memory/space-efficient compared to'conventional' error-free hashing data structures which require an enormous amount of memory/space
-
Returns only False Postives, no False Negatives - a database query can only return two possible outcomes: 'Probably in database' or 'Definitely NOT in database'
-
Database entries cannot be removed, only be added
-
Probability of false positives increases as more entries are added to the database
-
A bloom filter does not store the ACTUAL element, this is a crucial characteristic - it's not used to test whether an entry exists, only that an entry definitely does NOT exist (since there can NOT be any false negatives)
- Extremely memory/space-efficient, you do not need to store the actual elements, you only keep track of the possibility of their existence
- Prevents extra work looking-up elements that do NOT exist (once you hit a 0, return non-existence - to be elaborated on later)
- Time complexity for adding entries and looking up entries (actually, the possibility of the entry) is O(k) where k is the number of hash functions - bloom filter's become even more amazing because, in practice, these k lookups are independent and can be parallelized
- Because of the unlikelihood of getting a collision across all hash functions, the number of false positives can be effectively reduced
- There is the possibility of false positives - you can't be absolutely certain an entry you queried for is really in the database
- Database entries cannot be removed (caveat: can be addressed with the addition of a so-called 'counting' filter)
We intialize our 'storage' as an array of 0's, in this example we will use an array of size 10 with 3 hash different hash functions, each of which will take the entry and return an index between 0 to 9
Entry 'Insertion'
Our entry will be run through each function, and for every index returned, we will change the 0 to a 1

Entry 'Query'
For a query, we do the same thing, running the entry through each hash function
- Success (Probably exists) - storage value at every index returned via the k hash functions returns 1

- Failure (Definitely does not exist) - storage value at any one index returned via the k hash functions returns 0

Notice, the moment we verify there is a 0, we know the entry definitely does NOT exist. For large data sets this is very advantageous as it prevents extra look-ups.
credit to Patrick Brodie for his images
You can determine the optimal storage size, m, and optimal number of hash functions, k, via the given formulas:
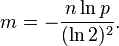

Where n is the number of entries you plan to store, and p is the acceptable probability for a false positive.
credit to Wikipedia for the formulas and their derivations
-
Complete the BloomFilterTable class (pseudo-classical) in BloomFilter.js
-
Fill out
BloomFilterclass so that m and k meet the requirements for the input n and p, also intialize the storage to all 0's -
Fill out the
.insert()method to input a '1' in the storage at every index returned via the k hash functions on an entry -
Fill out the
.query()method to return a boolean indicating whether an entry possibly exists
-
-
Pass the Specs
-
Should return true for query on entries that were inserted
-
Should return false for query on entries that were not inserted
-
Credit to Cory Dang for inspiring me to take on this assignment, without whom, I probably would not have given it a second look. He deserves the opportunity more than I ever could or should, and I borrowed heavily from his repo
Credit to Patrick Brodie for his images
Credit to Wikipedia for the formulas and their derivations