██╗ ██╗ ██████╗ ██╗ █████╗ ██████╗████████╗ ███████╗██████╗ ██████╗ ███████╗
╚██╗ ██╔╝██╔═══██╗██║ ██╔══██╗██╔════╝╚══██╔══╝ ██╔════╝██╔══██╗██╔════╝ ██╔════╝
╚████╔╝ ██║ ██║██║ ███████║██║ ██║ █████╗ ██║ ██║██║ ███╗█████╗
╚██╔╝ ██║ ██║██║ ██╔══██║██║ ██║ ██╔══╝ ██║ ██║██║ ██║██╔══╝
██║ ╚██████╔╝███████╗██║ ██║╚██████╗ ██║ ███████╗██████╔╝╚██████╔╝███████╗
╚═╝ ╚═════╝ ╚══════╝╚═╝ ╚═╝ ╚═════╝ ╚═╝ ╚══════╝╚═════╝ ╚═════╝ ╚══════╝
YolactEdge, the first competitive instance segmentation approach that runs on small edge devices at real-time speeds. Specifically, YolactEdge runs at up to 30.8 FPS on a Jetson AGX Xavier (and 172.7 FPS on an RTX 2080 Ti) with a ResNet-101 backbone on 550x550 resolution images. This is the code for our paper.
For a real-time demo and more samples, check out our demo video.
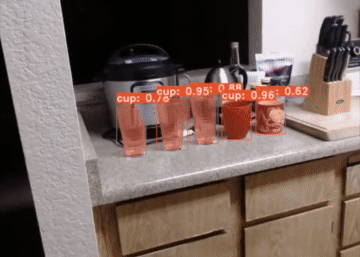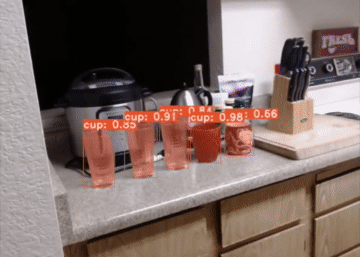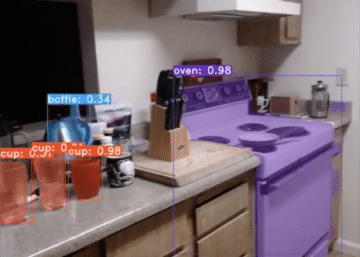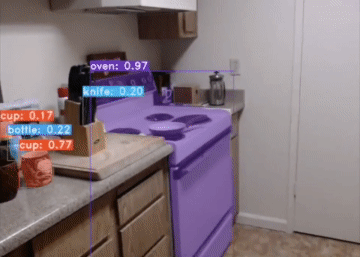


See INSTALL.md.
We provide baseline YOLACT and YolactEdge models trained on COCO and YouTube VIS (our sub-training split, with COCO joint training).
To evalute the model, put the corresponding weights file in the ./weights directory and run one of the following commands.
YouTube VIS models:
| Method | Backbone | mAP | AGX-Xavier FPS | RTX 2080 Ti FPS | weights |
|---|---|---|---|---|---|
| YOLACT | R-50-FPN | 44.7 | 8.5 | 59.8 | download | mirror |
| YolactEdge (w/o TRT) |
R-50-FPN | 44.2 | 10.5 | 67.0 | download | mirror |
| YolactEdge | R-50-FPN | 44.0 | 32.4 | 177.6 | download | mirror |
| YOLACT | R-101-FPN | 47.3 | 5.9 | 42.6 | download | mirror |
| YolactEdge (w/o TRT) |
R-101-FPN | 46.9 | 9.5 | 61.2 | download | mirror |
| YolactEdge | R-101-FPN | 46.2 | 30.8 | 172.7 | download | mirror |
COCO models:
| Method | Backbone | mAP | Titan Xp FPS | AGX-Xavier FPS | RTX 2080 Ti FPS | weights |
|---|---|---|---|---|---|---|
| YOLACT | MobileNet-V2 | 22.1 | - | 15.0 | 35.7 | download | mirror |
| YolactEdge | MobileNet-V2 | 20.8 | - | 35.7 | 161.4 | download | mirror |
| YOLACT | R-50-FPN | 28.2 | 42.5 | 9.1 | 45.0 | download | mirror |
| YolactEdge | R-50-FPN | 27.0 | - | 30.7 | 140.3 | download | mirror |
| YOLACT | R-101-FPN | 29.8 | 33.5 | 6.6 | 36.5 | download | mirror |
| YolactEdge | R-101-FPN | 29.5 | - | 27.3 | 124.8 | download | mirror |
# Convert each component of the trained model to TensorRT using the optimal settings and evaluate on the YouTube VIS validation set (our split).
python3 eval.py --trained_model=./weights/yolact_edge_vid_847_50000.pth
# Evaluate on the entire COCO validation set.
# '--coco_transfer' is used to convert the models trained with YOLACT to be compatible with YolactEdge.
python3 eval.py --coco_transfer --trained_model=./weights/yolact_edge_54_800000.pth
# Evaluate YolactEdge without TensorRT optimization with '_pytorch' configs.
python3 eval.py --config yolact_edge_pytorch_config --coco_transfer --trained_model=./weights/yolact_edge_54_800000.pth
# Output a COCO JSON file for the COCO test-dev. The command will create './results/bbox_detections.json' and './results/mask_detections.json' for detection and instance segmentation respectively. These files can then be submitted to the website for evaluation.
python3 eval.py --coco_transfer --trained_model=./weights/yolact_edge_54_800000.pth --dataset=coco2017_testdev_dataset --output_coco_json# Display qualitative results on COCO. From here on I'll use a confidence threshold of 0.3.
python eval.py --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --display# Benchmark the trained model on the COCO validation set.
# Run just the raw model on the first 1k images of the validation set
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --benchmark --max_images=1000# Display qualitative results on the specified image.
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --image=my_image.png
# Process an image and save it to another file.
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --image=input_image.png:output_image.png
# Process a whole folder of images.
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --images=path/to/input/folder:path/to/output/folder# Display a video in real-time. "--video_multiframe" will process that many frames at once for improved performance.
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --video_multiframe=2 --video=my_video.mp4
# Display a webcam feed in real-time. If you have multiple webcams pass the index of the webcam you want instead of 0.
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --video_multiframe=2 --video=0
# Process a video and save it to another file. This is unoptimized.
python eval.py --coco_transfer --trained_model=weights/yolact_edge_54_800000.pth --score_threshold=0.3 --top_k=100 --video=input_video.mp4:output_video.mp4Use the help option to see a description of all available command line arguments:
python eval.py --helpMake sure to download the entire dataset using the commands above.
- To train, grab an imagenet-pretrained model and put it in
./weights. - Run one of the training commands below.
- Note that you can press ctrl+c while training and it will save an
*_interrupt.pthfile at the current iteration. - All weights are saved in the
./weightsdirectory by default with the file name<config>_<epoch>_<iter>.pth.
- Note that you can press ctrl+c while training and it will save an
# Trains using the base edge config with a batch size of 8 (the default).
python train.py --config=yolact_edge_config
# Resume training yolact_edge with a specific weight file and start from the iteration specified in the weight file's name.
python train.py --config=yolact_edge_config --resume=weights/yolact_edge_10_32100.pth --start_iter=-1
# Use the help option to see a description of all available command line arguments
python train.py --helpYou can also train on your own dataset by following these steps:
- Depending on the type of your dataset, create a COCO-style (image) or YTVIS-style (video) Object Detection JSON annotation file for your dataset. The specification for this can be found here for COCO and YTVIS respectively. Note that we don't use some fields, so the following may be omitted:
infoliscense- Under
image:license, flickr_url, coco_url, date_captured categories(we use our own format for categories, see below)
- Create a definition for your dataset under
dataset_baseindata/config.py(see the comments indataset_basefor an explanation of each field):
my_custom_dataset = dataset_base.copy({
'name': 'My Dataset',
'train_images': 'path_to_training_images',
'train_info': 'path_to_training_annotation',
'valid_images': 'path_to_validation_images',
'valid_info': 'path_to_validation_annotation',
'has_gt': True,
'class_names': ('my_class_id_1', 'my_class_id_2', 'my_class_id_3', ...),
# below is only needed for YTVIS-style video dataset.
# whether samples all frames or key frames only.
'use_all_frames': False,
# the following four lines define the frame sampling strategy for the given dataset.
'frame_offset_lb': 1,
'frame_offset_ub': 4,
'frame_offset_multiplier': 1,
'all_frame_direction': 'allway',
# 1 of K frames is annotated
'images_per_video': 5,
# declares a video dataset
'is_video': True
})- Note that: class IDs in the annotation file should start at 1 and increase sequentially on the order of
class_names. If this isn't the case for your annotation file (like in COCO), see the fieldlabel_mapindataset_base. - Finally, in
yolact_edge_configin the same file, change the value for'dataset'to'my_custom_dataset'or whatever you named the config object above. Then you can use any of the training commands in the previous section.
If you use this code base in your work, please consider citing:
@article{yolactedge,
author = {Haotian Liu and Rafael A. Rivera Soto and Fanyi Xiao and Yong Jae Lee},
title = {YolactEdge: Real-time Instance Segmentation on the Edge (Jetson AGX Xavier: 30 FPS, RTX 2080 Ti: 170 FPS)},
journal = {arXiv preprint arXiv:2012.12259},
year = {2020},
}
@inproceedings{yolact-iccv2019,
author = {Daniel Bolya and Chong Zhou and Fanyi Xiao and Yong Jae Lee},
title = {YOLACT: {Real-time} Instance Segmentation},
booktitle = {ICCV},
year = {2019},
}
For questions about our paper or code, please contact Haotian Liu or Rafael A. Rivera-Soto.