Turn your voice into a prompt!
FFmpeg must be installed to run Whisper.
Please install FFmpeg compatible with your OS from the following link.
FFmpeg: https://ffmpeg.org/download.html
After installing FFmpeg, make sure to add the FFmpeg/bin folder to your system PATH!
git clone https://github.com/jhj0517/stable-diffusion-webui-Speech-To-Text-Prompter.git to your stable-diffusion-webui extensions folder.
or alternatively, download and unzip the repository in your extensions folder!
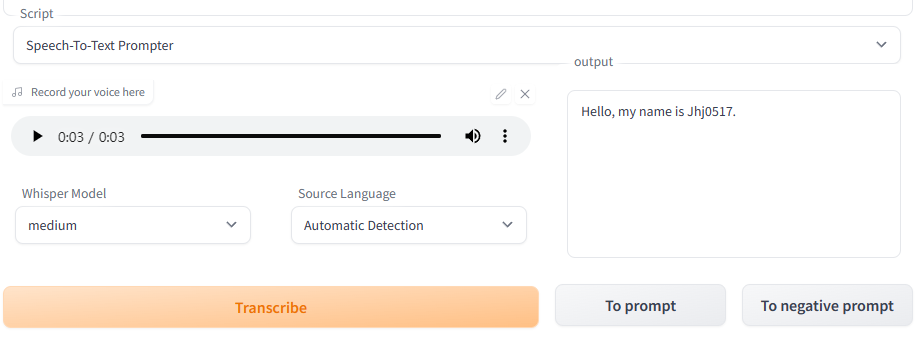
- Select "Speech-To-Text Prompter" in the Script drop-down.
- Record your voice, select the model you want, and choose the source language (usually "Automatic detection" works fine).
- Run the transcrption. This may take some time. Once it's done you can move the prompts on the UI.
The Extension uses the Open AI Whisper model
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
.en models are for English only, and the cool thing is that you can use the Translate to English option from the "large" models!