I want to build a real product end to end and share it with everyone. It’s easy to find system designs like these but finding a practical implementation + explanation is hard and rare. I’m here to fill that gap.
- Before this I tried doing everything from scratch on Kubernetes. This time focusing on getting the job done, keeping it simple and using a managed solution in every possible place. The simpler it is, the better.
- That is why it’s Cloudflare Queues instead of Kafka, Cloudflare KV instead of Redis, Cloudflare Workers instead of Kubernetes microservices, PlanetScale instead of Postgres Operator and Algolia instead of Elasticsearch.
- This time I’m not using any GPT3 or BERT vectors, I’ll rely on Algolia to handle the semantic search. Algolia also supports autocomplete, so I won’t have to reinvent that either.
- This time I’m using plain old JSON instead of gRPC. Of course gRPC has its host of advantages but I’m more fascinated by JSON’s simplicity at the moment.
- Simple
- Cheap
It’s not deployed anywhere right now, it’s a work in progress.
- PlanetScale - It's a serverless Postgres offering. We can use their API and not worry about managing/upgrading servers.
- Algolia - It's a serverless search index offering. It's a nicer version of Elasticsearch.
- Cloudflare Workers KV - It's like Redis but serverless and provided by Cloudflare.
- Cloudflare Queues - It's like Kafka but simpler, serverless and provided by Cloudflare.
- Cloudflare R2 - It's Cloudflare's version of AWS S3.
- Cloudflare Workers - It's like AWS Lambda but with no cold starts and cheaper.
- PlanetScale - Each web page links to other webpages, forming a graph. This repo stores webpages and their links between them in the form of two indexed columns: source and destination
- Algolia - Algolia will store and index the webpage, so we can search for it later on.
- PageHashes - This will help us check if a web page has already been processed before.
- Frontend - Simple React app to search webpages stored in Algolia.
- LinkFetcher - Get a random link from PlanetScale and queue it for processing.
- PageRenderer - Takes a link and returns contents of the rendered webpage. It needs to support static and dynamic web pages.
- PageProcessor - Takes a rendered web page and extracts links/text from it.
- PageSaver - Save web page to Algolia and Cloudflare R2. Save links to PlanetScale.
- PageRankQueuer - PageRank processing happens in iterations, so this will find a random webpage in the current stage and queue it for processing.
- PageRankProcessor - Takes a queued web page, computes its new PageRank score and sends it to Algolia. If the web page has links to more web pages in it, those are also queued for processing [only if they are in the same stage]. It's the Breadth First Search Algorithm at work here. This particular web page is moved to the next iteration.
- PageRankState - Stores variables like iteration number, residual value for current iteration, etc that are needed for the PageRank algorithm. It uses Cloudflare KV for storage.
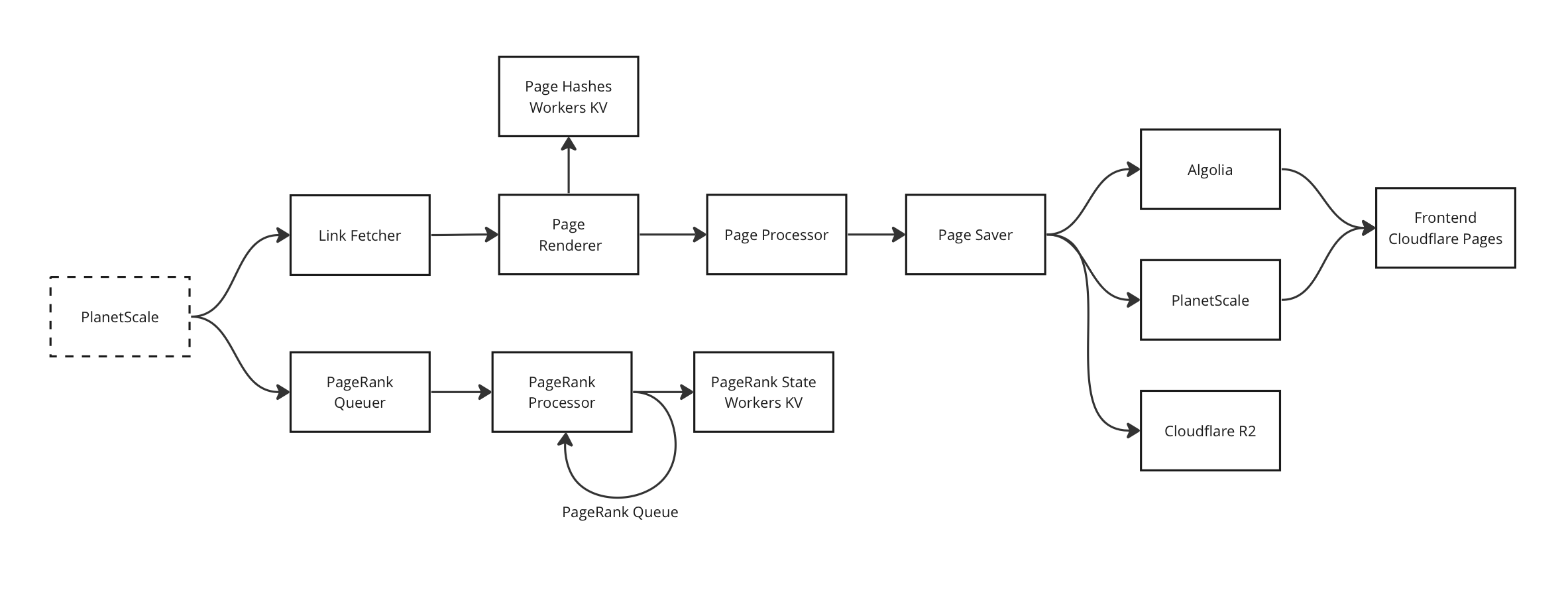 Cloudflare Queues act as a glue for the whole pipeline. Cloudflare Workers will work to perform each of these individual steps. Each worker will take data from a queue, process it and put it in another queue. The workers are all independent of each other, each one does their job regardless of what the other ones do.
Cloudflare Queues act as a glue for the whole pipeline. Cloudflare Workers will work to perform each of these individual steps. Each worker will take data from a queue, process it and put it in another queue. The workers are all independent of each other, each one does their job regardless of what the other ones do.

- User login and link tracking
- Support for image searches
- Frontend with autocomplete