Student: Laksono kurnianggoro
Mentor: Delia Passalacqua
Link to commits: https://github.com/opencv/opencv_contrib/pull/1257/commits
Link to codes: https://github.com/opencv/opencv_contrib/pull/1257/files
Facial landmark detection is a useful algorithm with many possible applications including expression transfer, virtual make-up, facial puppetry, faces swap, and many mores. This project aims to implement a scalable API for facial landmark detector. Furthermore, it will also implement 2 kinds of algorithms, including active appearance model (AAM) [1] and regressed local binary features (LBF) [2].
References
[1] G. Tzimiropoulos and M. Pantic, "Optimization problems for fast AAM fitting in-the-wild," ICCV 2013.
[2] S. Ren, et al. , “Face alignment at 3000 fps via regressing local binary features”, CVPR 2014.
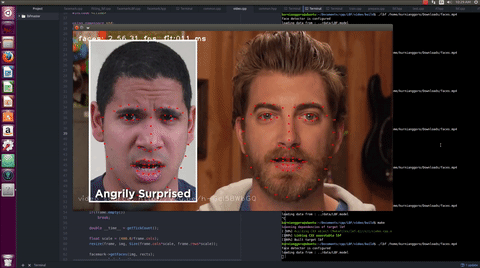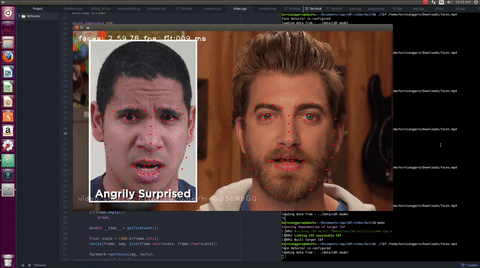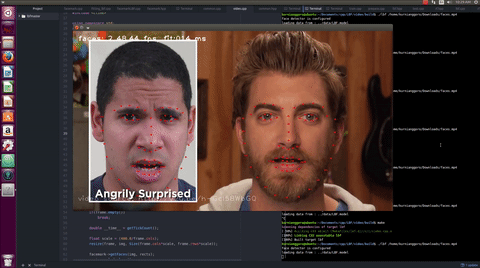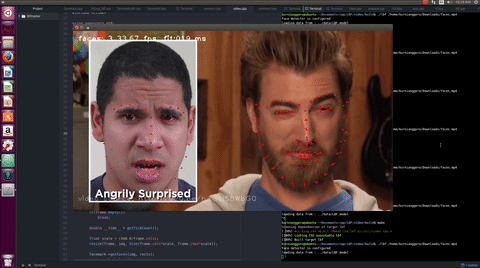
The works in this project is summarized in this commits list. In the proposal, there were few list of functionalities to be added to the API. However, during the coding period, in order to make the proposed API more reliable, various new functionalities were added as suggested by the mentors and another student who works in similar project.
- base class of the API (Facemark class) (done).
This base class provides several functionalities includingread(),write(),setFaceDetector(),getFaces(),training(),loadModel(), andfit(). - User defined face detector (done)
The configurable face detector is stored in the instance of a landmark detection algorithm and can be set using thesetFaceDetector()function. This allows the users to use their own face detector in the algorithm. - dataset parser (done).
There are 3 kinds of utility functions that parse the information from dataset:loadTrainingData(),loadDatasetList(), andloadFacePoints(). - documentation (done) see preview
- Tutorials (done) see preview
- sample codes (done : 3 programs are available)
- 2 algorithms, AAM and LBF (done)
- Extra parameter for the fitting function.
Each face landmark detector might needs their own parameters in the fitting process. Some parameter are fixed in all the time but some other might changes according to the input data. In the case of fixed parameter, the developer can just add this parameter as the member ofParams. However, in the case of dynamic parameter, the fitting function should allow extra parameter in the runtime. Hence the optional extra parameter is added to the fitting function by passing it as void parameter (void* extra_params) which can holds any types of parameter. - Allows extra parameters in the user defined face detector
Because of the same reason as the previously explained extra parameter for the fitting function, the user defined face detector also should allow extra parameter. - Test codes
Test codes are useful to perform automatic assessment to make sure that the implementation is compatible to various devices. - Functionality to add the dataset one by one in the training process\n
As the discussion with another student who works on similar project, this functionality should be added since the code developer suggested that the module should not have dependency on
imgcodecs. Previously, this dependency is needed because the dataset loading function was programmed to loads image inside the API. After this discussion, the image loading was removed from the API and theaddTrainingSample()function is added to the base class to alleviate this problem.
During the coding period, there are some improvements (not listed in original plan) that were tested but failed to be merged to the OpenCV.
- Trainer for the LBF algorithm.
The LBF algorithm utilize liblinear to trains it regressor. During the coding period, there was an initiative to liberate the implementaion of LBF from this dependency as liblinear provides to much functionalities that are not needed. Two kinds of methods were tested to train the regressor including stochastic gradient descent (SGD) and regularized least square (RLS) regression method. However, during the test, SGD cannot produces optimal solution in general since the parameters should be set properly and depends on the characteristic of the dataset. Meanwhile for the RLS, it requires a lot of time and memory due to the needs of inverse matrix computation. Thus this method is not scalabe and will be useless for large-sized dataset.
Mat FacemarkLBFImpl::Regressor::regressionSGD(Mat x, Mat y,
int max_epoch, int batch_sz, double lambda, double eta){
Mat pred;
x.convertTo(x, CV_64F);
y.convertTo(y, CV_64F);
Mat w = Mat::zeros(x.cols, 1, CV_64F);
cv::theRNG().state = cv::getTickCount();
randn(w,0.0,1.0);
Mat dw = Mat::zeros(x.cols, 1, CV_64F);
std::vector<double> E;
Mat dE;
double gamma = 0.7;
int maxIdx;
for(int i=0;i<max_epoch;i++){
pred = x*w;
double err = norm(pred-y)/x.rows;
if(i%10==0 || i==max_epoch-1)
printf("%i/%i: %f\n", i, max_epoch, err);
dE = Mat::zeros(w.rows, w.cols, CV_64F);
for(int j=0;j<x.rows;j+=batch_sz){
if(j+batch_sz>=x.rows){
maxIdx = x.rows;
}else{
maxIdx = j+batch_sz;
}
Mat x_batch = Mat(x,Range(j,maxIdx));
Mat y_batch = Mat(y,Range(j,maxIdx));
dE = dE + x_batch.t()*(x_batch*(w-gamma*dw)-y_batch)+lambda*w;
}//batch
dw = gamma*dw + eta*dE/norm(dE);
w = w - dw;
}
pred = x*w;
std::cout<<sum(abs(pred-y))<<std::endl;
std::cout<<Mat(pred-y,Range(0,30));
return Mat(w.t()).clone();
}- Custom extra parameters for the default face detector.
This functionality is failed to be merged and throw compilation error due problems with python wrapper.
struct CV_EXPORTS_W CParams{
String cascade; //!< the face detector
double scaleFactor; //!< Parameter specifying how much the image size is reduced at each image scale.
int minNeighbors; //!< Parameter specifying how many neighbors each candidate rectangle should have to retain it.
Size minSize; //!< Minimum possible object size.
Size maxSize; //!< Maximum possible object size.
CParams(
String cascade_model,
double sf = 1.1,
int minN = 3,
Size minSz = Size(30, 30),
Size maxSz = Size()
);
};
CV_EXPORTS_W bool getFaces( InputArray image,
OutputArray faces,
void * extra_params
);- There many possibilities to use parallelization in both implementation of LBF and AAM algorithms. Currently the parallelization is not implemented for both of them.
- The AAM algorithm produce big-sized training model since it basically store all the face region from the dataset. An alternative to reduce this trained model size is by limiting the size of the base shape. The faces region are wrapped into the base shape. If the base shape is resized into smaller size, then each wrapped face region will be stored in smaller size.
- As explained in the previous part, the dependency to libnear can be eliminated.
- The performance and processing time analysis is not yet provided. It will be useful to provide this information so that the end user could pick their setting based on the assessment data. As an example, in the LBF algorithm, the performance and processing speed changes according to number of the refinement stages, amount of depth and number of trees. Currently, the result as demonstrated in the video works at 50~90fps for both face detection and landmark fitting. However, the user might try other setting to get their desired result. If the comparison data is provided, it will be beneficial for the user.
- As pointed out by another student, the binary format was giving problem when the trained model is distributed as the data format is device dependent (i.e. model trained in linux64 could not be loaded properly in android). Therefor, saving the trained model in text file or xml format is better since the data is not dependent to the device.
- The face swapping functionality that demonstrated by the other student can be added in the API as a utility function.
This API extends the face module in current OpenCV contrib repository. The list of files in this extension is listed as follows:
| Component | Remarks |
|---|---|
| include/opencv2/face: | The required header files |
| facemark.hpp | Header for the base class of Facemark API |
| facemarkAAM.hpp | Header for the AAM algorithm |
| facemarkLBF.hpp | Header for the LBF algorithm |
| src: | Implementations of the algorithm are stored in this folder |
| facemark.cpp | Contains the implementation of several utility functions |
| facemarkAAM.cpp | Contains the implementation of the AAM algorithm |
| facemarkLBF.cpp | Contains the implementation of the LBF algorithm |
| tutorials: | Tutorials for the users |
| facemark_tutorial.markdown | The main menu |
| facemark_add_algorithm | Tutorial on how to extends the API with a new facial landmark detection algorithm |
| facemark_usage | Tutorial on how to use the API |
| samples: | Several sample codes are provided as the reference for the users |
| facemark_demo_aam.cpp | Demo for the AAM algorithm |
| facemark_demo_lbf.cpp | Demo for the LBF algorithm |
| facemark_lbf_fitting.cpp | Demo to detect facial landmarks on video |
| test: | Test code to make sure that the implementations are able to works in various environments |
| test_facemark.cpp | Test the utility functions |
| test_facemark_aam.cpp | Test the implementation of AAM algorithm |
| test_facemark_lbf.cpp | Test the implementation of LBF algorithm |
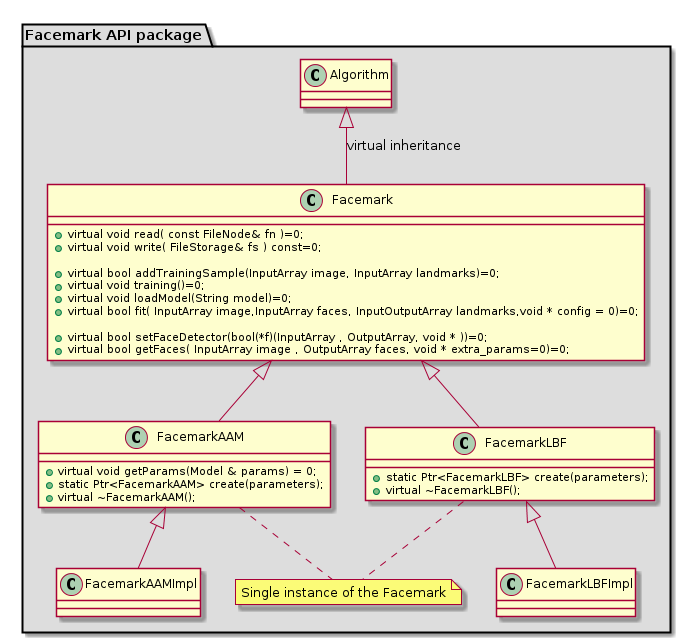
The Facemark class is a base class for all of facial landmark recognition algorithms. As shown in the UML diagram ,there are several interfaces are provided. Here are the brief explanation for each function, the more comprehensive information is provided at the documentation.
read: read the parameters from a configuration filewrite: save the parameters to a configuration fileaddTrainingSample: add one training sample to the trainer, each sample sample is consist of image data and its corresponding ground-truth landmark points.training: the training processloadModel: load a trained model to the algorithmfit: fitting processsetFaceDetector: set a user defined face detector function for the algorithm, this function can be utilized for both training and fitting process.getFaces: this function is used to perform the face detection process which is required before the fitting process.
Alongside the base class, there are several utility functions that are useful for the user.
getFaces: This is the standard function provided by the API. This detector utilize the OpenCV's CascadeClassifier to perform the detection process.loadDatasetList: This functions is useful to load the list of files in the dataset which are provided in a pair of text files. These input files contains the paths to the training images and annotation files, respectively. Each path is separated by a new line.loadTrainingData: There are 2 overloads of this function, both of them are used to load the path of images and ground-truth points in vector of vector format. The ground-truth points for each sample is stored invector<Point2f>. The difference between overloads is the input parameter. The first version accept 2 input file paths, one for image list and the other for ground-truth list. Meanwhile for the second version, it only accept 1 input which represent path to file which contains the path of the training image followed by the ground-truth points in each line. The more detailed information is available in the documentation.loadFacePoints: This function is useful to load the data of facial points stored in a path referred by the input parameter.drawFacemarks: This functions is useful to draw the landmark points into a given image.
There are 2 kinds of annotation format supported by the loadTrainingData, standard form and one line style format. The first format also supported by the loadFacePoints function.
An example of the standard format is shown below:
version: 1
n_points: 68
{
212.716603 499.771793
230.232816 566.290071
...
}
And here is an example for the one sample one line format:
/home/user/ibug/image_003_1.jpg 336.820955 240.864510 334.238298 260.922709 335.266918 ...
/home/user/ibug/image_005_1.jpg 376.158428 230.845712 376.736984 254.924635 383.265403 ...
...
The main purpose of this API is to provides as simple as possible interfaces for performing the facial landmark detection process. Here are the example for each main task, training and fitting where both of them requires few lines of codes.
Example of code for the training process:
/*declare the facemark instance*/
Ptr<Facemark> facemark = FacemarkLBF::create();
/* load the dataset list*/
String imageFiles = "../data/images_train.txt";
String ptsFiles = "../data/points_train.txt";
std::vector<String> images_train;
std::vector<String> landmarks_train;
loadDatasetList(imageFiles,ptsFiles,images_train,landmarks_train);
/*add the training samples to the trainer*/
Mat image;
std::vector<Point2f> facial_points;
for(size_t i=0;i<images_train.size();i++){
image = imread(images_train[i].c_str());
loadFacePoints(landmarks_train[i],facial_points);
facemark->addTrainingSample(image, facial_points);
}
/*training process*/
facemark->training();Example of code for the fitting process:
/*load a trained model*/
facemark->loadModel("../data/lbf.model");
Mat image = imread("image.jpg");
/*the the faces*/
std::vector<Rect> faces;
facemark->getFaces(img, faces);
/*perform the fitting process*/
std::vector<std::vector<Point2f> > landmarks;
facemark->fit(image, faces, landmarks);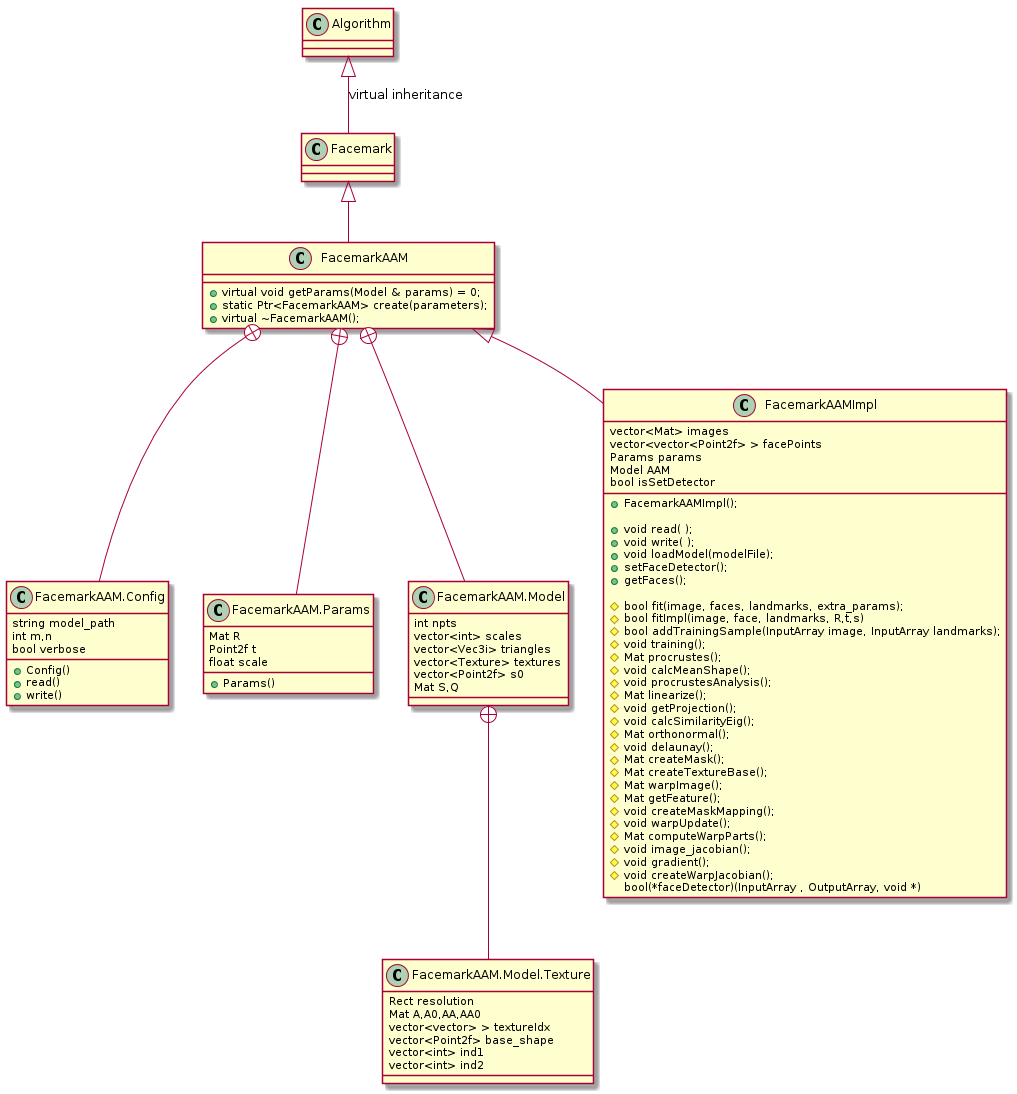
The AAM algorithm is ported from the Matlab version which is provided by the original author of the related paper. In the original implementation, the data are processed in double precission format (64bit) while in this Facemark API the data are processed in float (32bit) datatype.
This algorithm works better whenever initialization information is provided (rotation, translation, and scale). Thus this algorithm needs extra parameters in the fitting process. These initialization parameters can be obtained using user defined function (default face detector with pose and scale is not provided in the API, however and example of this function is available at the sample code).
Here is a snippet taken from the sample code that demonstrating the utilization of extra parameter in the fitting process:
std::vector<FacemarkAAM::Config> conf;
std::vector<Rect> faces_eyes;
for(unsigned j=0;j<faces.size();j++){
if(getInitialFitting(image,faces[j],s0,eyes_cascade, R,T,scale)){
conf.push_back(FacemarkAAM::Config(R,T,scale));
/*filter the detected faces, only use those which have initialization*/
faces_filtered.push_back(faces[j]);
}
}
if(conf.size()>0){
std::vector<std::vector<Point2f> > landmarks; //output
facemark->fit(image, faces_filtered, landmarks, (void*)&conf);
for(unsigned j=0;j<landmarks.size();j++){
drawFacemarks(image, landmarks[j]);
}
}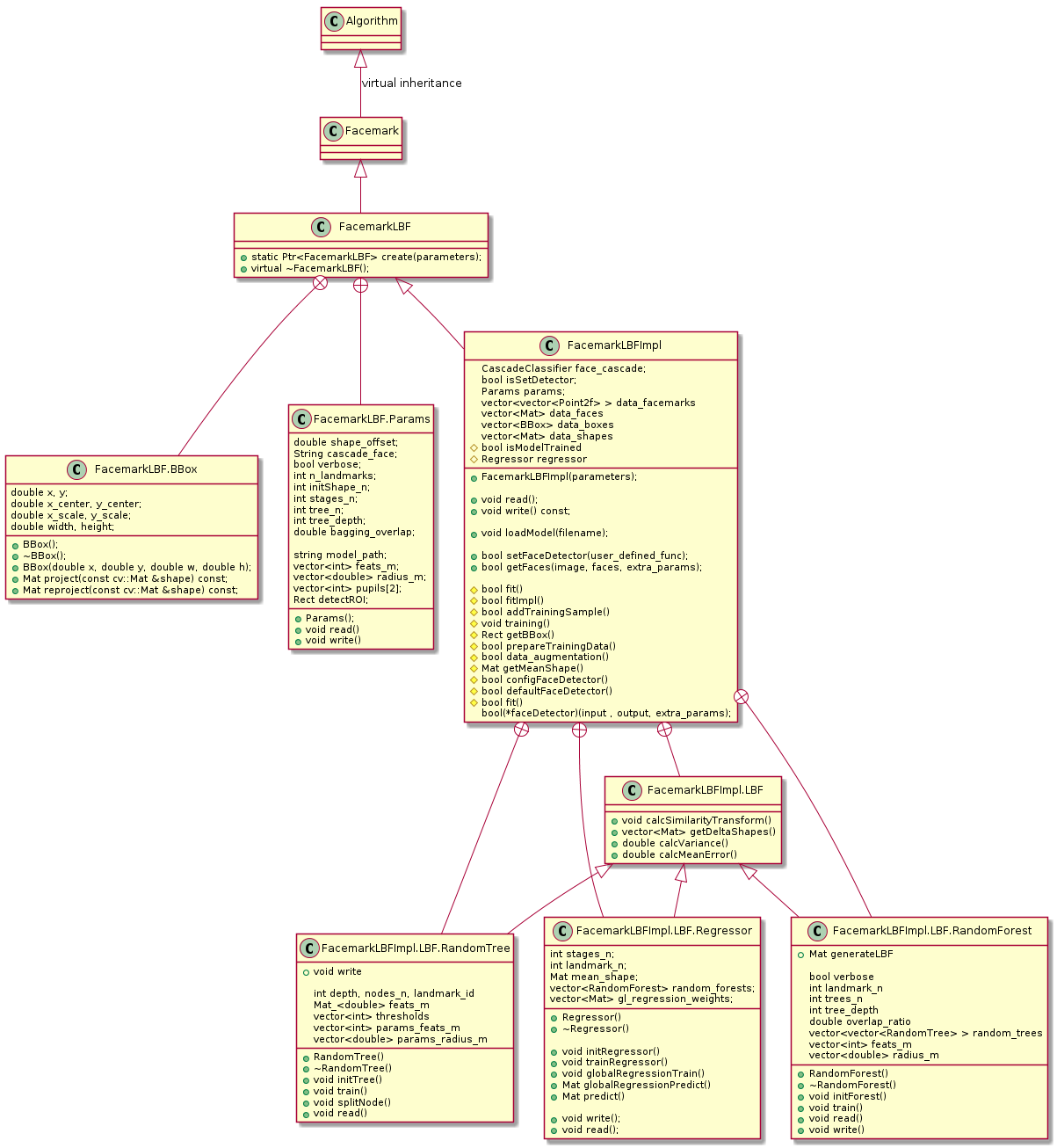
The LBF algorithm is an algorithm that can works in real time and provides reasonable results as demonstrated in the video. The users can train their own model using a dataset which contains large amount of training samples.
A trained model is provided for the user for their convenience. This model delivers reasonable result as demonstrated in the video.
Here is the snippet of code demonstrating the utilization of the trained model for detecting the facial landmarks points on a given face image:
/*Create a new instance of FacemarkLBF*/
Ptr<Facemark> facemark = FacemarkLBF::create();
/*get the input image*/
Mat image = imread("image.jpg");
/*load a trained model*/
facemark->loadModel("../data/lbf.model");
/*get faces*/
std::vector<cv::Rect> faces;
facemark->getFaces(img, faces);
/*detect the landmarks*/
std::vector<std::vector<Point2f> > landmarks;
facemark->fit(image, faces, landmarks);