Zijian Jin, Liangfu Zhong, Xihong Jiang
- Motivation
We decided to do a natural language processing project, and we took named entity recognition as our research direction.
As there are lots of characters are classified into “o”(others) in the text which may cause data imbalance when we train the model, we want to find a way to diminish the influence. As we learned in the SVM chapter, we can use the hinge loss to classify the data and maximize the distance of different classes to the SVs. Besides, we also want to maximize the distance between the "other" class and the real target of the character. So we propose a loss function named ThresholdLossI.
After tuning, the accuracy of ThresholdLossI far exceeds that of Softmax, and it is close to CRF in a shorter time.
Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entity mentions in unstructured text into pre-defined categories such as the person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
In NLP tasks, we often encounter this kind of trouble: the problem of data imbalance. The sample sizes of different categories vary greatly.
The problem of data imbalance mainly exists in supervised machine learning tasks. When encountering unbalanced data, the traditional classification algorithm that takes the overall classification accuracy as the learning goal will pay too much attention to the majority class, which will reduce the classification performance of the minority class samples. Most common machine learning algorithms do not work well with unbalanced data sets.
In the NLP task, most of the token tags in the sentence are “O”
- ThresholdLossI
- Flair Embedding
- char CNN
- Tuning
The targets of a character may have several values closed to each other, so we want to add some bias when the value is not large enough and try to classify the real target and "other" classes. As is done in SVM, we set a Threshold and margin so that when the target is less than the (Threshold+margin), we add bias of (Threshold + margin -target) even though the target we choose is the right one. Similarly, add bias to the not_target values more than(Threshold -margin). Additionally, if all the targets are less than (Threshold -margin), we think the character belongs to the "other" class. Thus we can diminish the imbalance caused by a large number of "other" classes and get a similar result as using RFC.

The model uses the character as the atomic unit. In the network, each character has a corresponding hidden state.
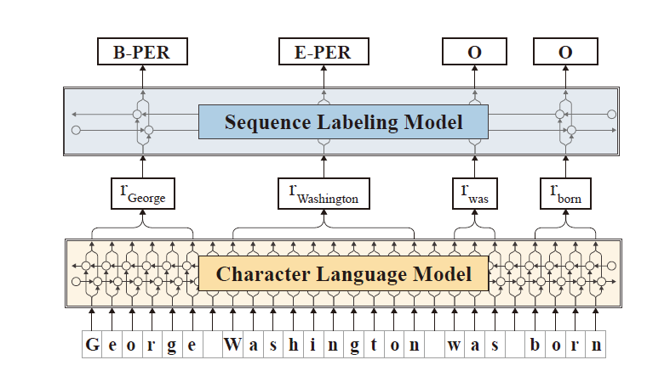
The model output embedding in word units. This embedding is composed of the hidden state of the last letter of the word in the forward LSTM and the hidden state of the first letter of the word in the reverse LSTM, so that context information can be taken into account.
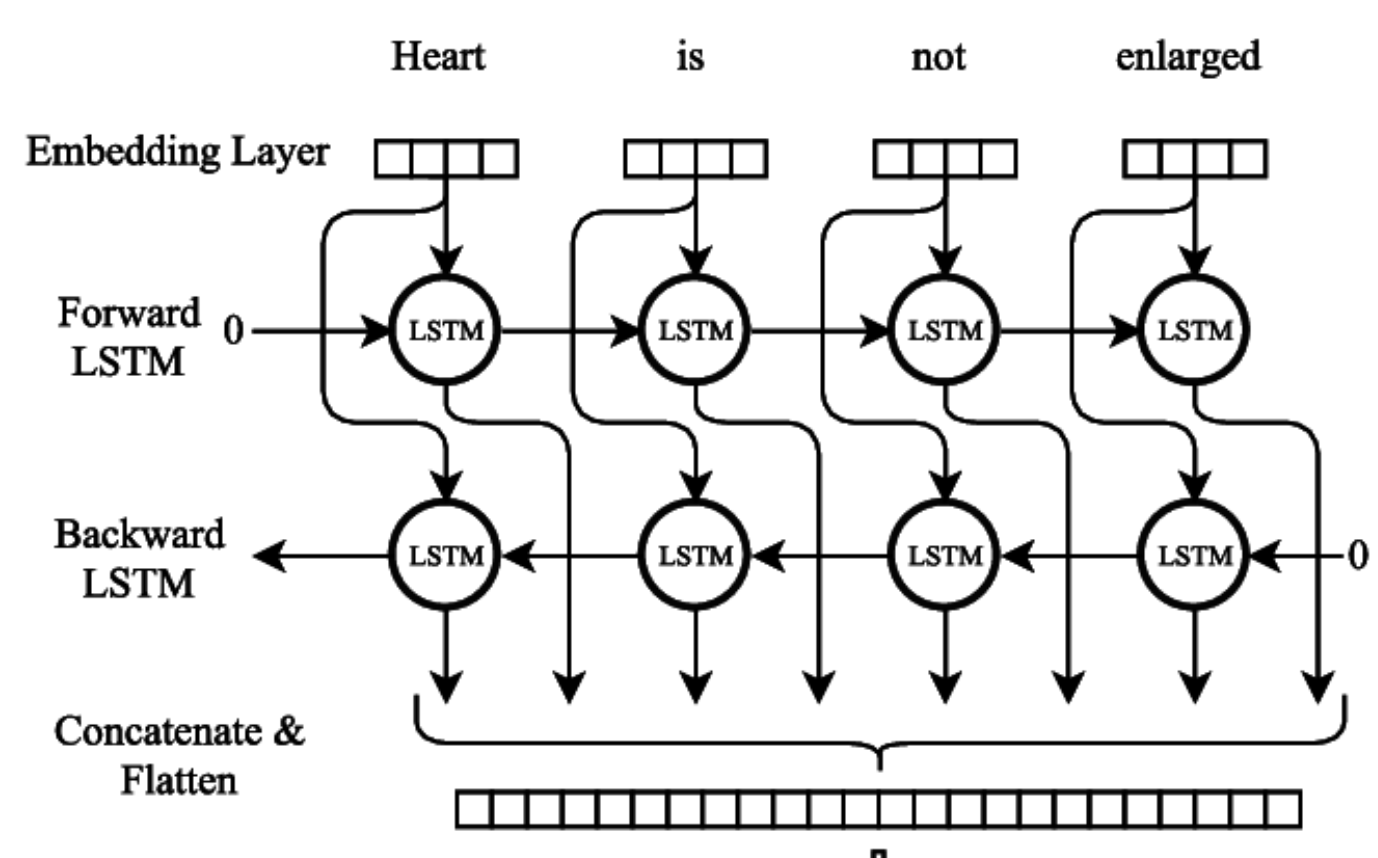
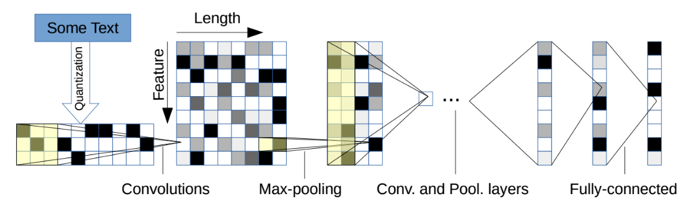
Different from what we learned in the class using CNN to processing the image, we need to use char CNN to achieve it. First, the char CNN make character table and transfer the characters to one-hot vector with a zero vector to represent the character not in the table so that a sentence will be transferred to a matrix. And then put the matrix to several convolutional layers and full-connected layers. But the difference between processing text and image in CNN is that when we processing images, we always process the region of pixels with height and width we defined by ourselves but in char CNN the weight of the kernel will always be the length of a single character.
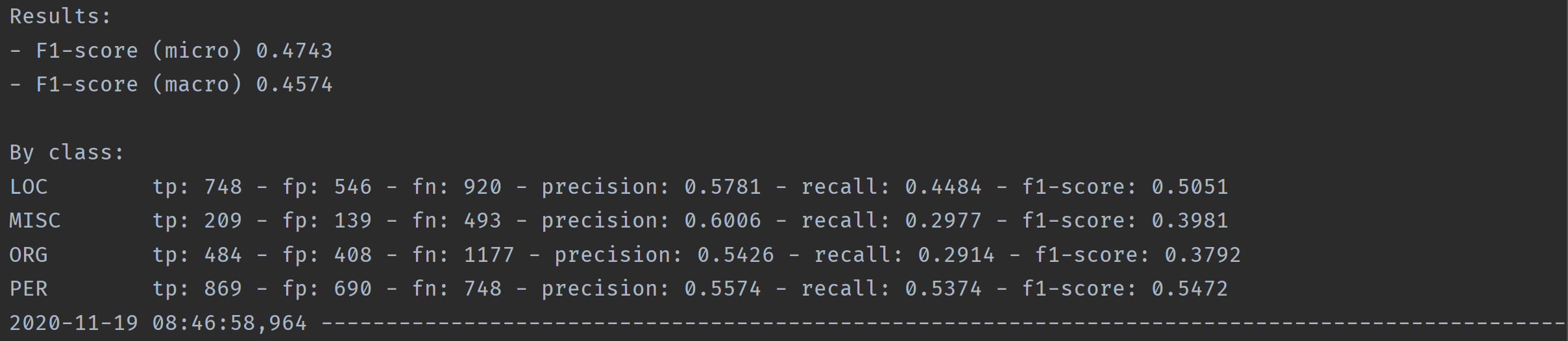
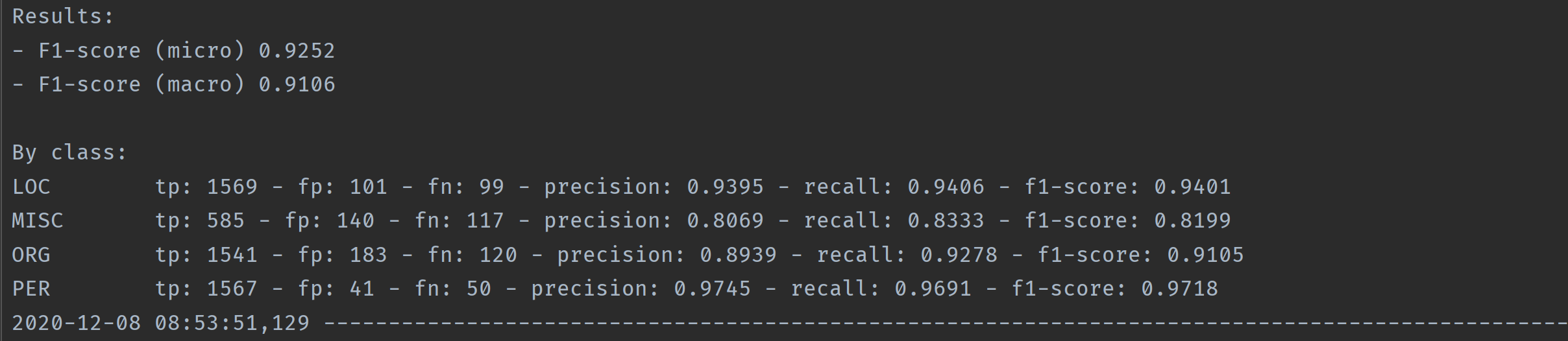
After training with processed CoNLL-2003 English dataset:
BiLSTM+Softmax: 0.9017 BiLSTM+CRF: 0.9307 BiLSTM+ThresholdLossI: 0.9252
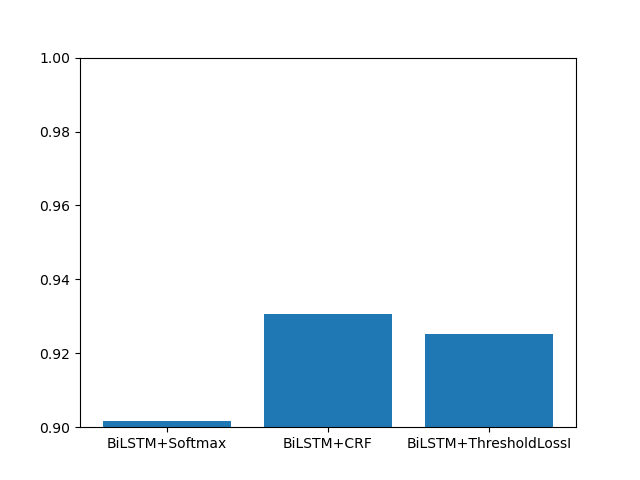
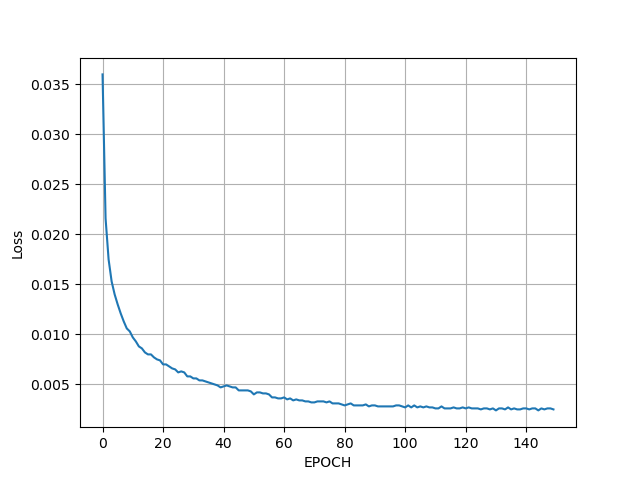
The accuracy of ThresholdLossI far exceeds that of Softmax, and it is close to CRF in a shorter time.
It is expected that in the future, we will be able to make further improvements to our proposed method In the future we plan to combine our existing methods and CRF to achieve higher accuracy and higher speed We hope our method can be used in more NLP tasks and will play a role in promoting NLP research.