| Group Member | Email Address | SID |
|---|---|---|
| Jiehong Jiang | jjhjiang@ucdavis.edu | 914974552 |
| Colin Beardshear | crbeardshear@ucdavis.edu | 914385840 |
| Malini Pathakota | mmpathakota@ucdavis.edu | 913241367 |
| Hoseung Lee | hoslee@ucdavis.edu | 914001975 |
| Lacey Campbell | lbcampbell@ucdavis.edu | 912170808 |
| Sri Kavya Dindu | sdindu@ucdavis.edu | 913022557 |
PROJECT REPORT:https://github.com/jjiangweilan/Dynamic-Army-Prediction/blob/master/FinalProjectReport-2.PDF
StarCraft II is a RTS game where players gather resources and strategically spend them on units, buildings and research in order to achieve the ultimate goal of overpowering the opponent and winning. Because this game relies heavily on choosing the right strategy early in the game, being able to predict the enemy’s army formation becomes a very valuable skill. If the player can correctly predict the exact units that are coming for them at specific times during the game, they can make better decisions on how to counter the enemy. In addition, being able to determine the effectiveness of an opening strategy is very beneficial- allowing the player to utilize a different strategy in order to increase their chance of victory.
Our main objective is to create an algorithm that predicts the the enemy’s army composition given the information that’s been gathered by scouts, including construction units, buildings, and current army formation. We call this Dynamic Army Prediction. Our secondary objective is to further utilize the same extracted data to create a model that predicts the player’s chance of winning based on their opening strategy. We call this Win Loss Prediction. Click this for more information on these models.
Our solution combines two ideas that we call First Encounter and Build Time Density. First Encounter is designed to calculate the “relative strength” relationship between any units, buildings and technologies in an unsupervised manner. We define this term as the difference between the time of creations of units. We calculate these values for each unit and then create an array of the “first encounter” values in the following format:
data[‘race’][‘observedUnit’][‘comparedUnit’] = [array of first encounters]
After creating the first encounter array for all units, we take the variance of each array and define this term as its “relative strength.” The main idea behind this is that among all StarCraft games, there is a high probability of a set of units being created following the creation of other specific units. The relative strength relationships mentioned earlier are represented by the variance that is calculated by the combination of all data. The intuition is that if we have low first encounter variance between two units, then we can say that these two units also have a strong relative strength relationship. In short, the lower the variance, the greater the chance of that unit being created. For example, take the relative strength relationship between Spires and other units:
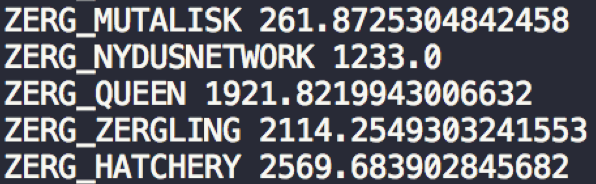
This output contains the “Relative Strength Relationship” between Spires and other units. The numerical values are calculated from the first encounter array mentioned above. Each numerical value corresponds to a score representing the possibility of the related unit being created. The lower the score, the higher the probability of the enemy building that specific unit. From this output we can see that the score for Mutalisk is very low in comparison to the others. This means that these units have the greatest possibility of being built following the creation of Spires. Because we only extracted data from 70 games, our prediction model is inaccurate in predicting build orders late in the game, however, the model performs somewhat accurately for early game predictions.
The relative strength and first encounter calculations alone do not take into account the influences the game clock and the number of created units has on build orders. In order to solve this problem, we weight the relative strength values by the normalized “Build Time Density.” The intuition behind this is that specific units are more likely to be created during specific times of the game. For example, take the graphs of the Build Time and Build Density for Hydralisks:
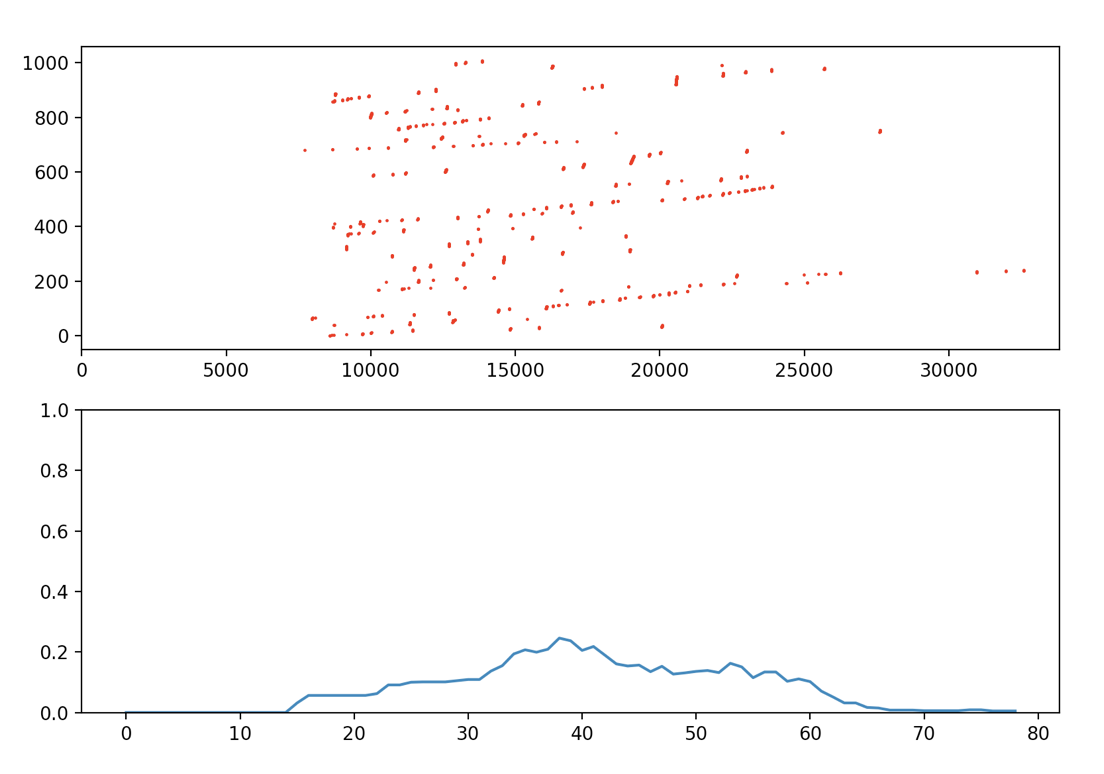
From these graphs, we can clearly see that Hydralisks are more likely to be built in the middle of the game rather than right at the start or closer to the end. By weighing the relative strength with the normalized unit density, we are able to increase and decrease the scores shown in Figure 2 based on the probability of these units being created during specific times of the game. At its current state, the Dynamic Army Predictor does not take into account the number of units seen by the player- it creates its predictions based on the unit type and game clock alone.
The win loss predictor predicts the probability of a certain unit winning a game. We used a logistic fitting to go on to predict the win loss probabilities for future units of the same type using their health values and quantities. The health is a good indication of the strength of a certain unit type because the more health a unit has, the longer it is able to withstand attacks and survive. Then it scales the effect across multiple attribution values in order to come up with an accurate fitting. We then take the given fit and use the inbuilt python PANDAS predict mechanism to we predict the win loss probability for the player. However, this prediction model requires both player to be the same race as it compares the amount and total health a specific unit that both sides possess. The coefficients derived from the logistic regression can also be applied to the Lanchester model referenced in the introduction in order to dynamically find the win loss probabilities rather than statically as we currently do. However, due to time constraints, we were not able to finish its implementation of Dynamic Win Loss Prediction. At its current state, Win Loss Prediction can only determine the chance of a player’s victory if they are playing as the same race as the opponent.
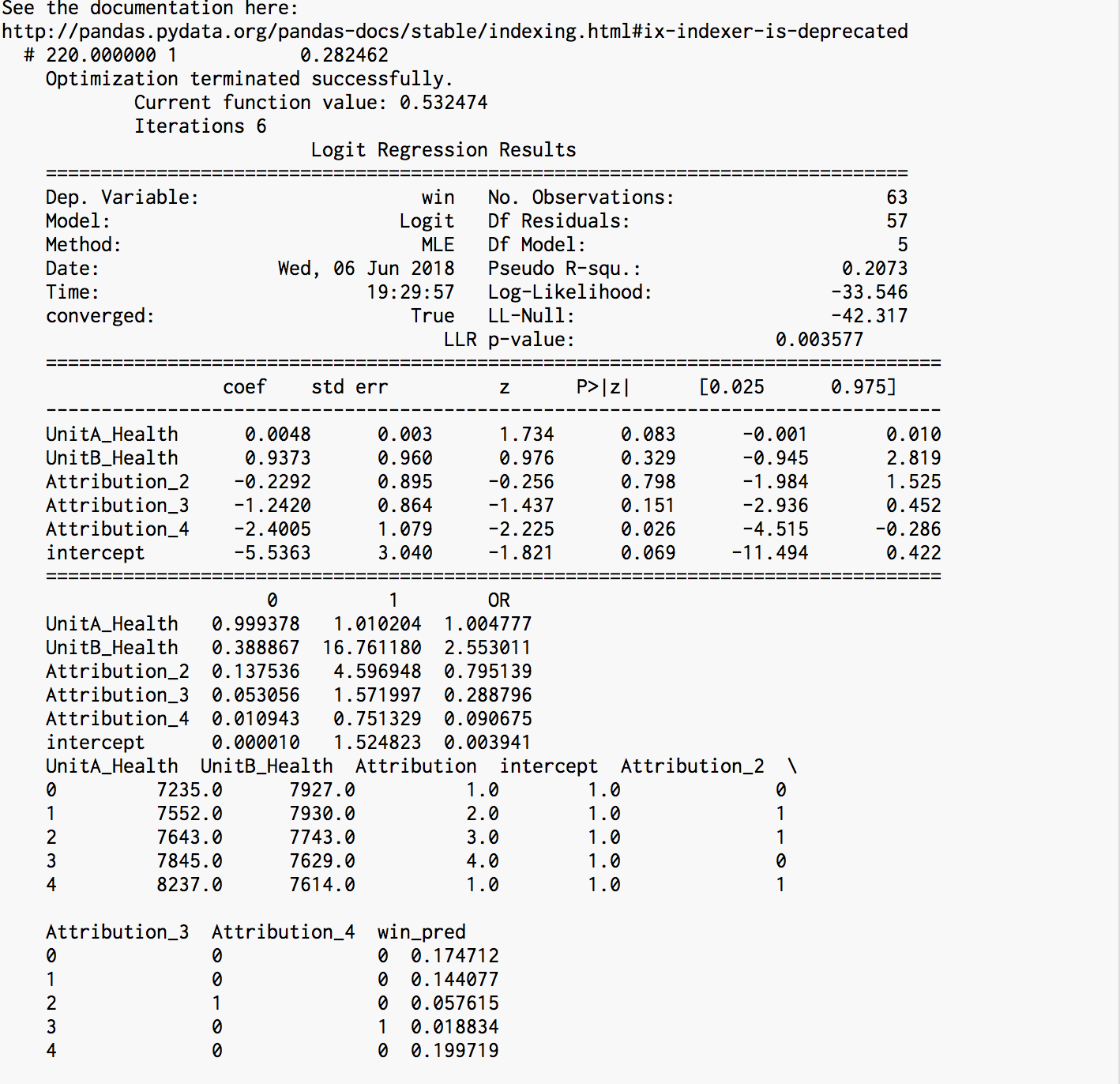
These are the results for a run of Predict.py based of data extracted from replays supplied by the sc2 API. Here we can see that although the probability of winning per unit are being made, they are not accurate.
We manually tested the Dynamic Army Predictor by extracting data from a replay file at a given time and running the prediction model based on the information gathered by scouting. The Dynamic Army Predictor then outputs the probability of certain units appearing based on the scouted information. For example, if scouts saw that the enemy had Zerglings, Roaches, and a Hydralisk Den at minute 14 of the game, the Dynamic Army Predictor would output the following:
'Zergling','hydraliskden','Roach' at 14:
ZERG_HYDRALISK 866.6295873238444
ZERG_MUTALISK 1184.0044180563987
ZERG_ULTRALISK 1631.941048553335
ZERG_ZERGLING 1667.0600759384356
ZERG_ROACH 2246.7335243029793
ZERG_HATCHERY 2256.7266629475075
ZERG_QUEEN 2388.042075678204
ZERG_EXTRACTOR 2493.9337879525756
ZERG_BANELING 2745.264887498538
ZERG_CORRUPTOR 2875.204016145028
ZERG_SPORECRAWLER 3512.5562124820585
ZERG_INFESTOR 3634.2377559254724
ZERG_SWARMHOSTMP 4851.190094561914
ZERG_SPINECRAWLER 4906.350895150753
ZERG_HYDRALISKDEN 5938.999009239683
ZERG_NYDUSCANAL 7064.234813927637
ZERG_ROACHWARREN 7499.128491785
ZERG_SPIRE 9954.722072007273
ZERG_BANELINGNEST 10049.895016369863
ZERG_EVOLUTIONCHAMBER 10477.45197594935
ZERG_INFESTATIONPIT 12011.998827522799
ZERG_ULTRALISKCAVERN 12975.540372735573
ZERG_SPAWNINGPOOL 19491.723274555447
This lists all the units the enemy’s chosen race could have and the probability of them creating that specific unit. More prediction results are shown in here. As mentioned earlier, the lower the score, the more likely the enemy will create that unit. We looked at the units with the lowest scores and then analyzed the replay the data was initially extracted from to see if these units were created. We repeated this process at varied times with different replay files and reached the conclusion that the Dynamic Model Predictor was mostly accurate early on during the game and as the game progresses, becomes more and more inaccurate. With extra time, we would increase the accuracy of our model by introducing a new variable into it- the amount of each unit seen by the player’s scouts. We would also test the data using the k-fold cross validation mentioned above in order to get more accurate results and be able to find the exact percentage of accuracy our model has.
Due to the time restrictions and our last minute addition of the win loss prediction feature we were unable to perform Valgrind Testing as an assessment of accuracy. However based of the outcomes of the validation set and predictions from our predictor, we believe predictor still needs more work. It's slightly accurate when used within the first three or minutes in the game after which it began to scale largely too fast.
How to:
-
Replace your s2client-api/examples/replay.cc file
-
Open the replay.cc file and go to line 21. There should be a line of code that looks something like this :
const char* kReplayFolder = "C:/Program Files (x86)/StarCraft II/Replays/Used/";
This is where the replay files should be located for data extraction.
-
If you wish to change the replay directory, replace the code inside of the quotations marks with your desired directory.
-
Get Microsoft Visual Studio and Build s2client-api (Install api : https://github.com/Blizzard/s2client-api/blob/master/docs/building.md)
-
Run replay.exe (just type this in and press enter on terminal or cmd)
-
At the end of every match, the terminal/cmd should output a json formatted unit count to the screen.
-
At the end of the first game, a file called "data.json" should be created in your s2client-api/build/bin folder
-
Every time the json formatted unit count gets printed on to the terminal/cmd, the data.json file will be updated with the new data
-
This will continue until the program has run through ALL of the replays in the replay directory. So if you just want to analyze one game, make sure that there is only one game in your replay directory.
-
If you wish to rerun this program delete your prior data.json or move it out of the bin folder, then you can run replay.exe again.
-
Open utilities/preprocessData.py, and change the PATH variable to where your data.json is. Then run the program. It will generate a new data.json in the Data folder.
-
Now with the processed data, open Model/predictor.py and change the PATH variable to where the processed data.json is. Please use absolute path.
-
Run the Model/predict.py and follow the prompt
In the UnitLog folder of this repository there are several zip files. Some of these are prototypes of the data extraction replay.cc program. The programs in these zip files are similar to the main replay.cc file in that it prints out data into the bin folder, but it is just a build order txt file instead of the json unit log file. There is also a tutorial.cc file that can log the build order for live games. More details are in the README inside these zip files.
UnitLog.zip : Live Games
UnitLogReplays.zip : Build orders for replays
Win Loss requires specific data and therefore requires additional data collection.
How to:
-
Replace the s2client-api/examples/sc2_coordinator with the coordinator file sc2-Coordinator from the WinLoss prediction repo. This file will extract the enemy data.
-
Now replace the pre-existing s2client-api/examples/replay.cc file with the replay.cc file found in WinLoss prediction.
-
Make sure to change the paths for kReplayFolder to the location of your file. This file extracts health information along with the number of units created at current moment in time.
-
Follow the same steps as stated above for normal data extraction into the JSON file.
-
Convert this JSON into a .txt file and run this file with win_loss_parser.py to compute and extract the necessary data.
-
Launch Microsoft Excel and click on the parsed .txt file and select “import” to display the Text Import Wizard.
-
Select “Fixed Width” and click “Next”.
-
Click on the line in the data preview to create the necessary field break lines. Each break line should be created to separate one field from the other, then click “Next”.
-
Click “Finish”, “Ok”, then import the data
-
Save your file, select “CSV(Comma delimited)”.
-
To run Predict.py, you will need to have Python installed on your system along with the dependencies such as Numpy, Pandas etc. We used Enthought’s python IDE Canopy which supports all the dependencies here: link
-
Be sure to replace the following path in Predict.py to where your specific data file islocated
-
Now simply, if using Canopy, run your files by pressing the build green arrow at the top of the interface.