Clone this project to create a 2 - master/slave nodes Apache Hadoop cluster
$ git clone https://github.com/jmargieh/hadoop_multi_node_cluster.gitPrerequisites: : Vagrant & VirtualBox
After cloning this repository, change into the directory and run:
./start.shThis will set up 2 machines - master, slave. Each of them will have a CPU and 2048MB of RAM. If this is too much for your machine, adjust the Vagrantfile to match your needs.
The master machine acts as the datanode, namenode, secondarynamenode, node manager and the yarn resourcemanager, the slave acts as a data node and runs node manager.
$ sudo /usr/lib/jvm/jdk1.8.0_77/bin/jpsinspect ResourceManager, DataNode & NameNode in master & DataNode, NamdeNode in slave
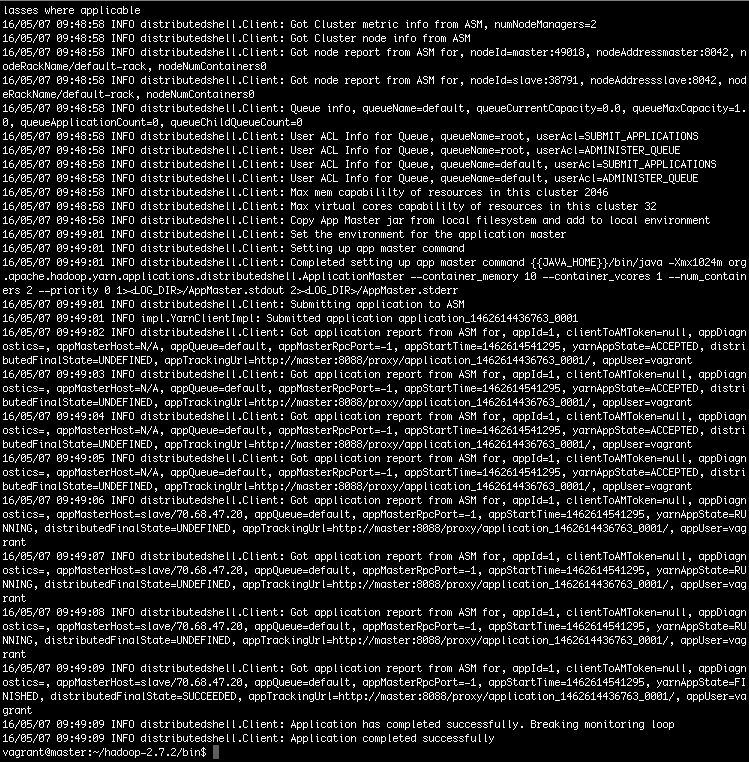
$ hadoop jar ../share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.2.jar \org.apache.hadoop.yarn.applications.distributedshell.Client \--jar ../share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.2.jar \--shell_command date --num_containers 2 --master_memory 1024to run distrebuted shell.
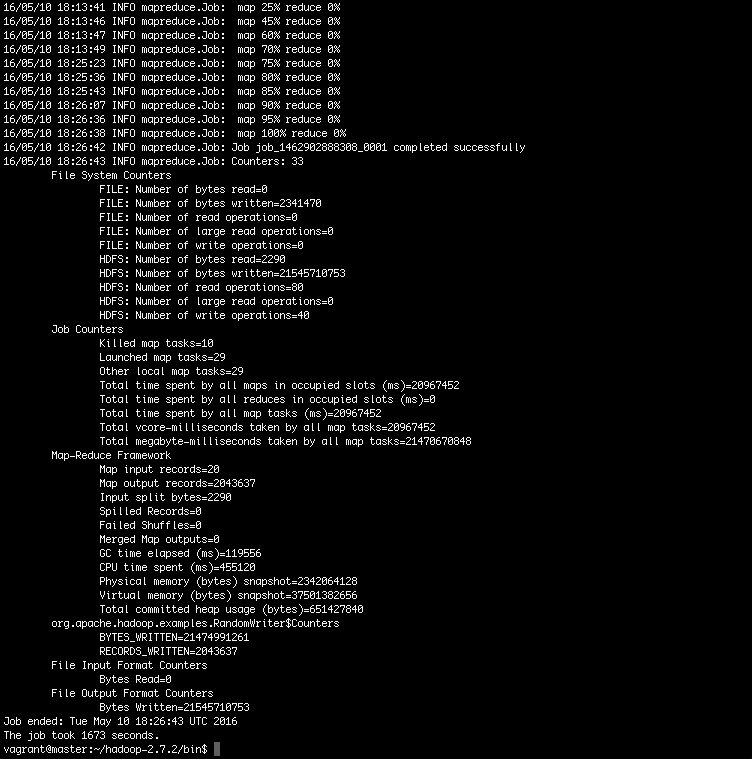
$ hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomwriter \outto run randomwriter mapreduce job
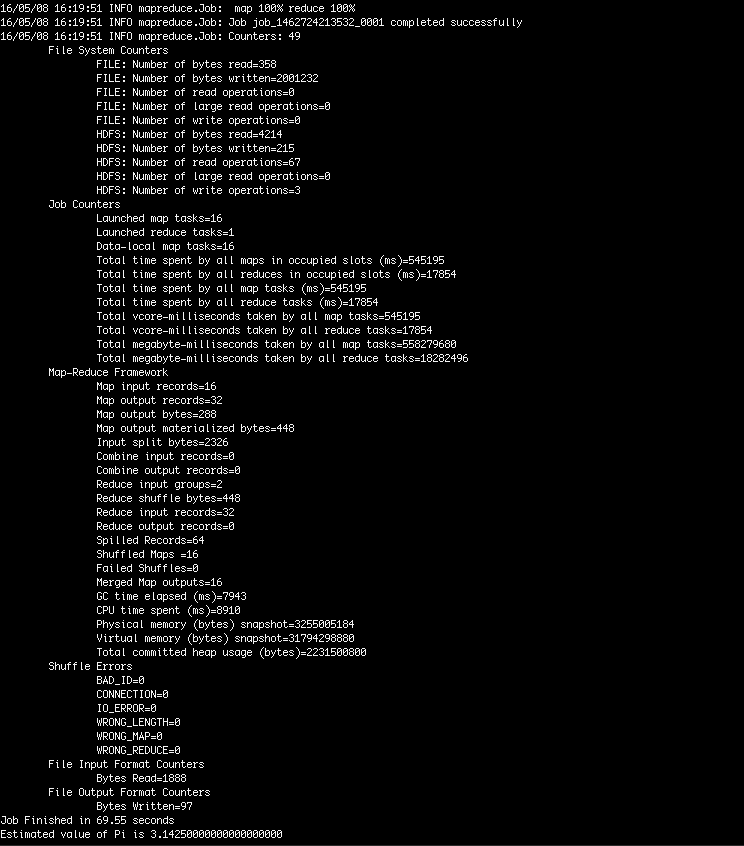
$ hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar pi 16 1000to run Pi mapreduce job
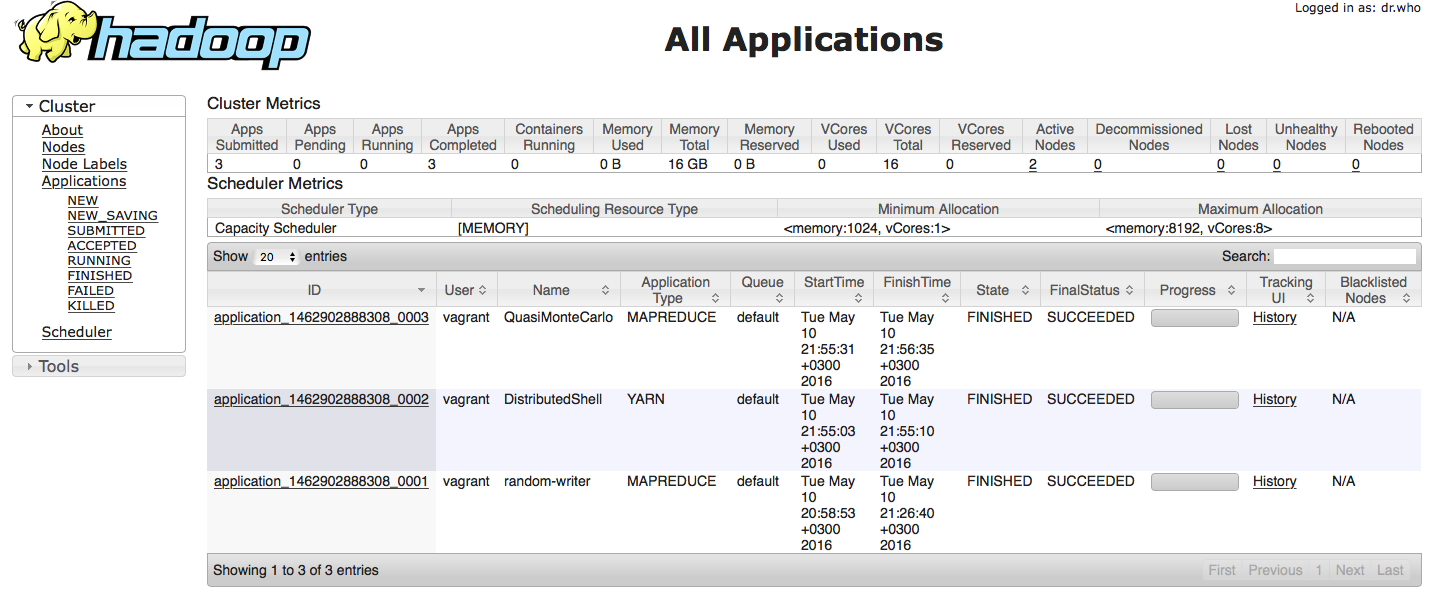
open your browser & navigate - http://70.68.47.19:8088/to view YARN web user interface