![]()
Wordsiv is a Python package for generating text with a limited character set. It is designed for type proofing, but it may be useful for generating lipograms.
Let's say you have the letters HAMBURGERFONTSIVhamburgerfontsiv and
punctuation ., in your font. Wordsiv might generate the following drivel:
True enough, for a fine enough to him at the thrones above, some time for at that first the business. She is that he hath set as a thought he even from its substratums It is the rest of it is not the things the savings of a movement that he measures about the matter, Ahab gives to the boats at noon, or from the Green Forest, this high as on Ahab.
While designing a typeface, it is useful to examine text with a partial character set. Wordsiv tries its best to generate realistic-looking text with whatever glyphs are available.
- Determine available glyphs from a font file
- Generate sorta-realistic-looking text with a variety of models
- Filter words by number of characters and approximate rendered width
- be an easy-to-use and easy-to-extend meaningless language generation framework
- support many languages and scripts (please help me!)
- A realistic langauge generator
- A responsible human forming sentences
First, install wordsiv with pip:
# we install straight from git (for now!)
$ pip install git+https://github.com/jmsole/wordsiv # byexample: +passNext, install one or more source packages from the releases page of the source packages repo:
$ base=https://github.com/jmsole/wordsiv-source-packages/releases/download
$ pkg=fa_wordcount_subs-0.1.0/fa_wordcount_subs-0.1.0-py3-none-any.whl
$ pip install $base/$pkg # byexample: +passNow you can make bogus sentences in Python!
>>> import wordsiv
>>> wsv = wordsiv.WordSiv(limit_glyphs=('HAMBURGERFONTSIVhamburgerfontsiv'))
>>> wsv.sentence(source='en_markov_gutenberg')
('I might go over the instant to the streets in the air of those the same be '
'haunting')If you prefer to work in the DrawBot app, you can follow this procedure to install Wordsiv:
-
Install the
wordsivpackage via Python->Install Python Packages:- Enter
git+https://github.com/jmsole/wordsivand click Go! - Note: you'll probably see lots of red text but it should still work just fine
- Enter
-
Install the desired Source packages in the same window, but add
--no-depsat the end:https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps- Tip: You can copy the
.whlor.tar.gzpackage URLs from the source packages repo's releases page under the assets drop down.
- Tip: You can copy the
-
When you write your DrawBot script, you will add each source using
add_source_module():import wordsiv import en_wordcount_web wsv = wordsiv.WordSiv() wsv.add_source_module(en_wordcount_web) print(wsv.sentence(source="en_wordcount_web"))
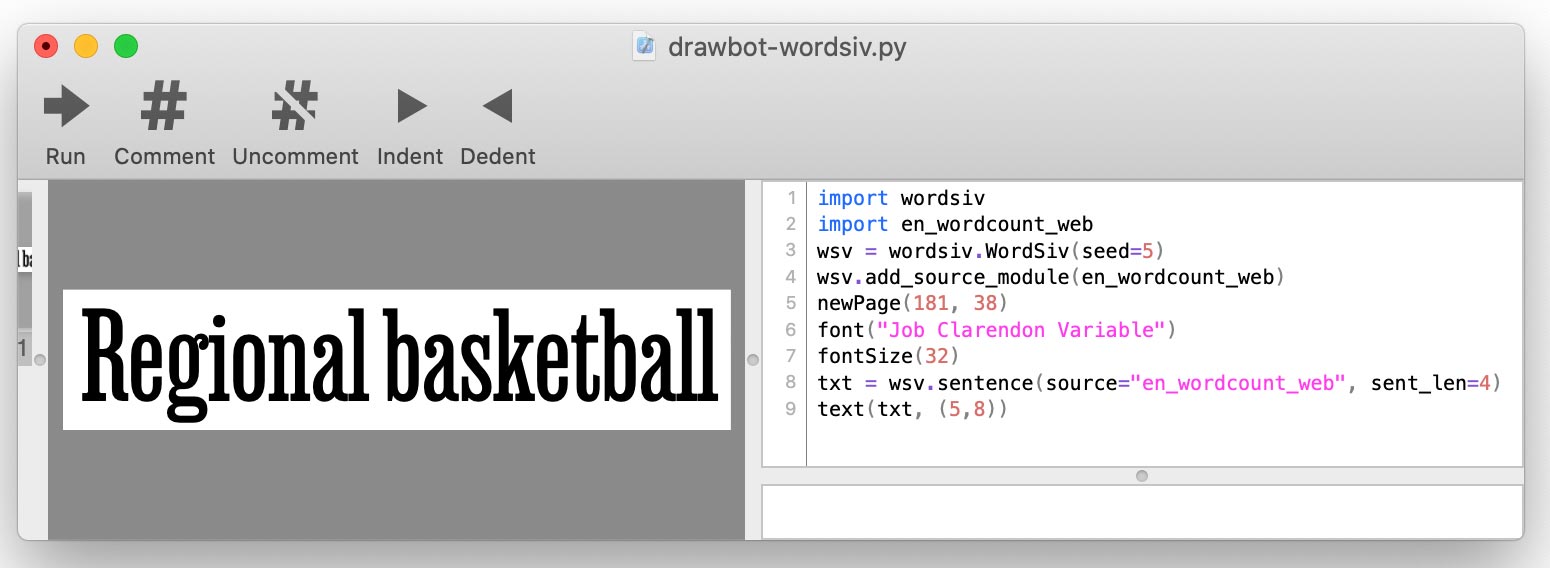


Wordsiv first needs some words, which come in the form of Sources: objects which supply the raw word data.
These Sources are available via Source Packages, which are simply Python Packages. Let's install some:
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base/$pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base/$pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base/$pkg # byexample: +passWordsiv auto-discovers these installed packages, and and can use these sources right away. Let's try a source with the most common words in the English language in modern usage:
>>> from wordsiv import WordSiv
>>> wsv = WordSiv()
>>> wsv.sentence(source='en_wordcount_web')
('Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.')How does a Wordsiv know how to arrange words from a Source into a sentence? This is where Models come into play.
The source en_wordcount_web uses model rand by default. Here we explicitly
select the model rand to achieve the same result as above:
>>> wsv = WordSiv()
>>> wsv.sentence(source='en_wordcount_web', model="rand")
('Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.')Notice we get the same sentence when we initialize a new WordSiv() object. This is because Wordsiv is designed to be determinisic.
If we want text that is somewhat natural-looking, we might use our
MarkovModel (model='mkv').
>>> wsv.paragraph(source="en_markov_gutenberg", model="mkv") # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."A Markov model is trained on real text, and forecasts each word by looking at the preceding word(s). We keep the model as stupid as possible though (one word state) to generate as many different sentences as possible.
WordCount Sources and Models work with simple lists of words and occurence counts to generate words.
The RandomModel (model='rand') uses occurence counts to
randomly choose words, favoring more popular words:
# Default: probability by occurence count
>>> wsv.paragraph(source='en_wordcount_web', model='rand') # byexample: +skip
'Day music, commencement protection to threads who and dimension...'The RandomModel can also be set to ignore occurence counts and choose words completely randomly:
>>> wsv.sentence(source='en_wordcount_web', sent_len=5, prob=False) # byexample: +skip
'Conceivably championships consecration ects— anointed.'The SequentialModel (model='seq') spits out words in the
order they appear in the Source. We could use this Model to display the top 5
trigrams in the English language:
>>> wsv.words(source='en_wordcount_trigrams', num_words=5) # byexample: +skip
['the', 'ing', 'and', 'ion', 'tio']Wordsiv is built around the idea of selecting words which can be rendered with the glyphs in an incomplete font file. Wordsiv can automatically determine what glyphs are in a font file.
Let's load a font with the characters HAMBURGERFONTSIVhamburgerfontsiv
>>> wsv = WordSiv(font_file='tests/data/noto-sans-subset.ttf')
>>> wsv.sentence(source='en_markov_gutenberg', max_sent_len=10)
'Nor is fair to be in as these annuities'We can limit the glyphs in the same way, but manually with limit_glyphs
>>> wsv = WordSiv(limit_glyphs='HAMBURGERFONTSIVhamburgerfontsiv')
>>> wsv.sentence(source='en_wordcount_web')
'Manage miss ago are motor to rather at first to be of has forget'It can be useful at times to specify the character set we want to display, and
only using those characters if we have them in the font file. We can do
this by specifying both font_file and limit_glyphs:
>>> wsv = WordSiv(
... font_file='tests/data/noto-sans-subset.ttf',
... limit_glyphs='abcdefghijklmnop'
... )
>>> wsv.sentence('en_wordcount_web', cap_sent=False, min_wl=3)
'eng gnome gene game egg one aim him again one game one image boom'There are a variety of ways text can be manipulated. Here are some examples:
Both the MarkovModel and WordCount models allow us to uppercase or lowercase text, whether or not the source words are capitalized or not:
>>> wsv = WordSiv()
>>> wsv.sentence('en_wordcount_web', uc=True, max_sent_len=8)
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
>>> wsv.sentence(
... 'en_markov_gutenberg', lc=True, min_sent_len=7, max_sent_len=10
... )
'i besought the bosom of the sun so'The RandomModel by capitalizes sentences by default, but we can turn this off:
>>> wsv.sentence('en_wordcount_web', cap_sent=False, sent_len=10)
'egcs very and mortgage expressed about and online truss controls.'By default the WordCount models insert punctuation with probabilities roughly derived from usage in the English language.
We can turn this off by passing our own function for punctuation:
>>> def only_period(words, *args): return ' '.join(words) + '.'
>>> wsv.paragraph(
... source='en_wordcount_web', punc_func=only_period, sent_len=5, para_len=2
... )
'By schools sign I avoid. Or about fascism writers what.'For more details on punc_func, see punctuation.py.
This only applies for WordCount models, as the
MarkovModel uses the punctuation in it's source data.
Models take care of generating sentences and words, so parameters
relating to these are handled by the models. For now, please refer to the source
code for these models to learn the parameters accepted for word(), words(),
and sentence() APIs:
The WordSiv object itself handles sentences(), paragraph(),
paragraphs() and text calls with their parameters. See the WordSiv
Class source code to learn how to customize the text output.
When proofing type, we probably want our proof to stay the same as long as we have the same character set. This helps us compare changes in the type.
For this reason, Wordsiv uses a single pseudo-random number generator, that is seeded upon creation of the WordSiv object. This means that a Python script using this library will produce the same outcome wherever it runs.
If you want your script to generate different words, you can seed the WordSiv object:
>>> wsv = WordSiv(seed=6)
>>> wsv.sentence(source="en_markov_gutenberg", min_sent_len=7)
'even if i forgot the go in their'After watching the documentary Coded Bias, I considered whether we should even generate text based on historical (or even current) data, because of the sexism, racism, colonialism, homophobia, etc., contained within the texts.
This section attempts to address some of these ethical questions that arose for me (Chris Pauley), and try to steer this project away from generating offensive text.
First off, this library was designed for the purposes of:
- generating text that isn't intended to be read, just looked at:
- type design proofing: in which we are examining how words, sentences, and paragraphs look.
Of course, we naturally read words (duh), so it goes without saying that you should supervise text generated by this library.
I considered if there were more progressive texts I could train a Markov model on. However, we are scrambling the source text to meaninglessness anyway, to maximize sentences made with a limited character set.
Even the most positive text can get dark really quick when scrambled. A Markov model of state size 1 (ideal for limited character sets) trained with the UN Universal Declaration of Human Rights made this sentence:
Everyone is entitled to torture
or other limitation of brotherhood.
The point is, semi-random word generation ruins the meaning of text, so why bother picking a thoughtful source? However, we should really try to stay away from offensive source material, because offensive patterns will show up if there is any probability involved.
If you're wanting to contribute a source and/or model to this project, here are some guidelines:
Generate sentences that are largely nonsensical
For example, we keep MarkovModel from picking up too much context from the original text by keeping a state size of 1. Having a single word state also increases the amount of potential sentences as well, so it works out.
The sentences we generate make less sense, but since this is designed for dummy text for proofing, this is a good thing!
It's tricky filtering out "offensive" words, since:
- the offensiveness of words depends on context
- offensiveness is largely subjective
- "offensive" word lists could potentially be used to silence important discussions
Since we're generating nonsensical text for proofing, we should try our best to filter wordlists by offensive words lists. If you really need swears in your text, you can create sources for your own purposes.
We can't prevent random words from forming offensive sentences, but we can at least restrict words that tend to form offensive sentences.
Statistical models like those used in WordSiv will pick up on patterns in text— especially MarkovModels. Try to pick source material that is fairly neutral (not that anything really is).
I trained en_markov_gutenberg with these public domain texts from nltk, which seemed safe enough for a dumb, single-word-state Markov model:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
If you notice any particular models generating offensive sentences more than not, please file an issue at the wordsiv-source-packages repo.
I'm definitely not the first to generate words for proofing. Check out these cool projects, And let me know if you know of more I should add!
- word-o-mat: Nina Stössinger's RoboFont extension for making test words. Also ported to Glyphs and Javascript.
- adhesiontext: a web-based tool by Miguel Sousa for generating text from a limited character set.
I probably wouldn't have got very far without the inspiration of word-o-mat, and a nice DrawBot script that Rob Stenson shared with me. The latter is where I got the idea to seed the random number generator to make it deterministic.
I also borrowed heavily from spaCy in how I set up the Source packages.
Also want to thank my wife Pammy for kindly listening as I explain each esoteric challenge I've tackled, and lending me emotional support when I almost wiped out 4 hours of work with a careless Git mistake.