

- Readability reference to Arc90's.
- Scrape article from any page (automatically).
- Make any web page readable, no matter Chinese or English.
快速抓取网页文章标题和内容,适合node.js爬虫使用,服务于ElasticSearch。
- Features
- Performance
- Installation
- Usage
- Debug
- Score Rule
- Extract Selectors
- Image Fallback
- Threshold
- Customize Settings
- Output
- Notes
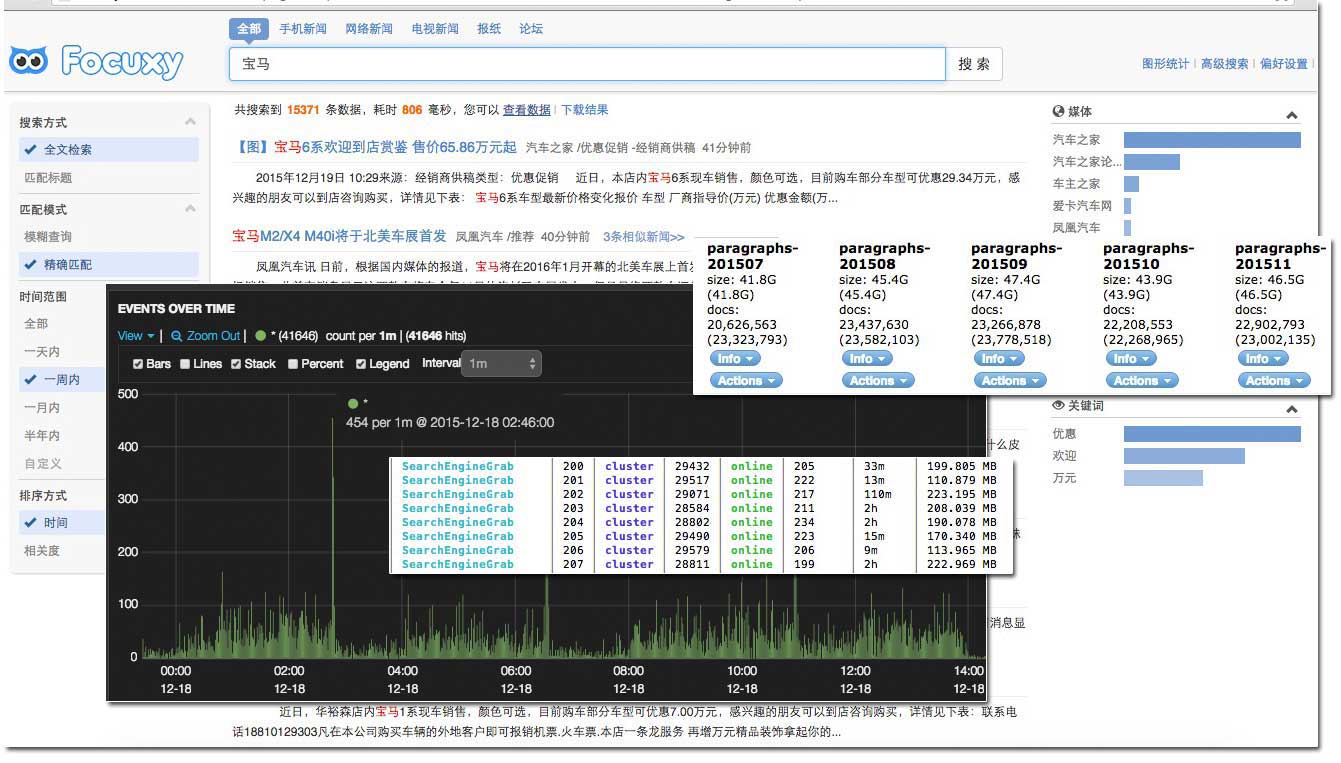
## Installation ```javascript npm install read-art --production ``` ## Usage ```javascript read( [, options], [callback]) ```Server infos:
- 20M bandwidth of fibre-optical
- 8 Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz cpus
- 32G memory
It supports the definitions such as:
- html|uri|cheerio Html, Uri string or Cheerio instance.
- options An optional options object, including:
- output The data type of article content, head over to Output to get more information.
- killBreaks A value indicating whether or not kill breaks, blanks, tab symbols(\r\t\n) into one
<br />,trueby default. - betterTitle Defined how to extract the title, read more.
- minTextLength If the content is less than
[minTextLength]characters, don't even count it,25by default. - minParagraphs A number indicates whether or not take the top candidate as a article candidate,
3by default, i.e.: IftopCandidatedom has more than3<p>children,topCandidatewill be considered as the article dom, otherwise, it will be the parent oftopCandidate(not<body>). - tidyAttrs Remove all the attributes on elements,
falseby default. - keepAllLinks A value indicates whether or not keep all the links, especially the useless anchors such as pagination, print, email and so on,
falseby default. - forceDecode A value indicates whether or not decode the full text/html by (https://github.com/fb55/entities)[entities],
falseby default. - dom Will return the whole cheerio dom (proceeded) when this property is set to
true,falseby default, try to useart.domto get the dom object in callback function (uses the$_to get the original). - damping The damping to calculate score of parent node,
1/2by default. e.g.: the score of current document node is20, the score of parent will be20 * damping. - scoreRule Customize the score rules of each node, one arguments will be passed into the callback function, read more.
- selectors Customize the data extract selectors.
- imgFallback Customize the way to get source of image, read more.
- thresholdScore A number/function indicates whether or not drop the article content, read more.
- thresholdLinkDensity A
0~1decimal indicates whether or not drop the article content, read more. - options from cheerio
- options from req-fast
- callback Fire after the article has been crawled -
callback(error, article, options, response), arguments are:- error
Errorobject when exception has been caught. - article The article object, including:
article.title,article.contentandarticle.html. - options The request options.
- response The response of your request, including:
response.headers,response.redirects,response.cookiesandresponse.statusCode.
- error
### Examples ```javascript var read = require('read-art'); // read from google: read('http://google.com', function(err, art, options, resp){ if(err){ throw err; } var title = art.title, // title of article content = art.content, // content of article html = art.html; // whole original innerHTMLHead over to test or examples directory for a complete example.
console.log('[STATUS CODE]', resp && resp.statusCode); }); // or: read({ uri: 'http://google.com', charset: 'utf8' }, function(err, art, options, resp){
}); // what about html? read('<title>node-art</title>
hello, read-art!
}); // of course could be var $ = cheerio.load('<title>node-art</title>
hello, read-art!
}); read({ uri: '<title>node-art</title>
hello, read-art!
}); /* Promise */ read('
Hello, read-art
') .then(function (art, options, httpResponse) { // TODO: }, function (err) { // Handle error. }) .catch(function (err) { // Catch exception. })**CAUTION:** Title must be wrapped in a `<title>` tag and content must be wrapped in a `<body>` tag.
**With High Availability: [spider2](https://github.com/Tjatse/spider2)**
<a name="debug" />
## Debug
See the [debug](https://github.com/visionmedia/debug) module.
### Wildcards
read-art.main read-art.article read-art.doctype read-art.reader
### Example
```bash
$ DEBUG=read-art.* node app.js
-
scoreRule You can customize the score rules manually, e.g.:
scoreRule: function(node){ if (node.hasClass('w740')) { return 100; } }The elements which have the
w740className will get100bonus points, that will make thenodeto be the topCandidate, which means it's enough to make thetextofDIV/P.w740to be the content of current article.node The cheerio object.
read('http://club.autohome.com.cn/bbs/thread-c-66-37239726-1.html', {
minTextLength: 0,
scoreRule: function(node){
if (node.hasClass('w740')) {
return 100;
}
}
}, function(err, art){
});read({
html: '<title>read-art</title><body><div class="article"><h3 title="--read-art--">Who Am I</h3><p class="section1">hi, dude, i am <b>readability</b></p><p class="section2">aka read-art...</p><small class="author" data-author="Tjatse X">Tjatse</small></div></body>',
selectors: {
title: {
selector: '.article>h3',
extract: ['text', 'title']
},
content: '.article p.section1',
author: {
selector: '.article>small.author',
skipTags: 'a,span',
extract: {
shot_name: 'text',
full_name: 'data-author',
custom_name: function(node, options) {
return options.source + ':' + node.text
}
}
},
source: {
selector: '.article>.pub_source',
skipTags: false,
extract: function(node, options) {
return options.domain + ':' + node.text()
}
}
},
}, function (err, art) {
// art.title === {text: 'Who Am I', title: '--read-art--'}
// art.content === 'hi, dude, i am <b>readability</b>'
// art.author === {shot_name: 'Tjatse', full_name: 'Tjatse X'}
});Properties:
-
selector the query selector, e.g.:
#article>.title,.articles:nth-child(3) -
extract the data that you wanna extract, could be one of following:
-
Array: each item should be a prop name, e.g.:text=>node.text()href=>node.attr('href')data-src=>node.attr('src') -
Object: key-value pairs, the key is a field name, and the value could be:propName: property name ofnodeFunction: callback funtion with two aguments passing in -nodeandoptions.
-
-
skipTags a value indicating whether or not skip the tags (remove)
Booleanskip nothing if this property is set tofalseStringskip the specific tags (supports CSS3 selectors)
Notes The binding data will be an object or array (object per item) if the extract option is an array object, title and content will override the default extracting methods, and the output of content depends on the output option.
imgFallback: function(node, src){
if (src){
return src;
}
return node.attr('base') + '/' + node.attr('rel-path');
}read({
imgFallback: true
}, function(err, art){});
read({
imgFallback: 'the-src-attr'
}, function(err, art){});
read({
imgFallback: function(node, src){
if (src){
return src;
}
return node.attr('base') + '/' + node.attr('rel-path');
}
}, function(err, art){});After read-art got the top candidate, it starts to analyze the children of top candidate, if the score of current child is greater than thresholdScore, the child will be appended to article body directly.
Math.max(10, topCandidate.data(scoreKey) * 0.2) by default.
read({
thresholdScore: 20
}, function(err, art){});
read({
thresholdScore: function(node, scoreKey){
return Math.max(10, node.data(scoreKey) * 0.2);
}
}, function(err, art){});read({
thresholdLinkDensity: 0.25
}, function(err, art){});
The `[usage]` could be one of following:
- `this.reset()`
Reset the settings to default.
- `this.skipTags([tags], [override])`
Remove useless elements by tagName, e.g. `this.skipTags('b,span')`, if `[override]` is set to `true`, `skiptags` will be `"b,span"`, otherwise it will be appended to the origin, i.e. :
aside,footer,label,nav,noscript,script,link,meta,style,select,textarea,iframe,b,span
- `this.medias([medias], [override])`
Append the medias dom to article by tagName, e.g. `this.medias('video,img,embed')`, if `[override]` is set to `true`, `medias` will be `"video,img,embed"`, otherwise it will be appended to the origin - the original tags are:
img,video,object,embed
- `this.regexps.positive([re], [override])`
If `positive` regexp test `id` + `className` of node success, it will be took as a candidate. `[re]` is a regexp, e.g. `/dv101|dv102/` will match the element likes `<div class="dv101">...` or `<div id="dv102">...`, if `[override]` is set to `true`, `positive` will be `/dv101|dv102/i`, otherwise it will be appended to the origin, i.e. :
/article|blog|body|content|entry|main|news|pag(?:e|ination)|post|story|text|dv101|dv102/i
- `this.regexps.negative([re], [override])`
If `negative` regexp test `id` + `className` of node success, it will not be took as a candidate. `[re]` is a regexp, e.g. `/dv101|dv102/` will match the element likes `<div class="dv101">...` or `<div id="dv102">...`, if `[override]` is set to `true`, `negative` will be `/dv101|dv102/i`, otherwise it will be appended to the origin, i.e. :
/com(?:bx|ment|-)|contact|comment|captcha|foot(?:er|note)?|link|masthead|media|meta|outbrain|promo|related|scroll|shoutbox|sidebar|sponsor|util|shopping|tags|tool|widget|tip|dialog|copyright|bottom|dv101|dv102/i
- `this.regexps.uselessAnchors([re], [override])`
If `uselessAnchors` regexp test `text content` of adjacent sibling anchors(`a+a+a`) success, and the `keepAllLinks` is set to `false`, the parent node of anchor will be removed - normally it could be the pagination, print/email nodes. `[re]` is a regexp, e.g. `/next\spage|previous\spage/i` will match the element likes `<a href="2.htm">Next Page</a>` or `<a href="1.htm">Previous Page</a>`, if `[override]` is set to `true`, `uselessAnchors` will be `/next\spage|previous\spage/i`, otherwise it will be appended to the origin, i.e. :
/(\d+|next|prev|first|last|print|comment|mail|font|about|contact|(下|下|前|后)一|(首|尾)页)|打印|评论|邮件|信箱|转发|关于|联系|^(大|中|小)$|next\spage|previous\spage/i
- `this.regexps.unlikely([re], [override])`
If `unlikely` regexp test `id` + `className` of node success, it probably will not be took as a candidate. `[re]` is a regexp, e.g. `/dv101|dv102/` will match the element likes `<div class="dv101">...` or `<div id="dv102">...`, if `[override]` is set to `true`, `unlikely` will be `/dv101|dv102/i`, otherwise it will be appended to the origin, i.e. :
/agegate|auth?or|bookmark|cat|com(?:bx|ment|munity)|date|disqus|extra|foot|header|ignore|link|menu|nav|pag(?:er|ination)|popup|related|remark|rss|share|shoutbox|sidebar|similar|social|sponsor|teaserlist|time|tweet|twitter|\bad[\s_-]?\b|dv101|dv102/i
- `this.regexps.maybe([re], [override])`
If `maybe` regexp test `id` + `className` of node success, it probably will be took as a candidate. `[re]` is a regexp, e.g. `/dv101|dv102/` will match the element likes `<div class="dv101">...` or `<div id="dv102">...`, if `[override]` is set to `true`, `maybe` will be `/dv101|dv102/i`, otherwise it will be appended to the origin, i.e. :
/and|article|body|column|main|column|dv101|dv102/i
- `this.regexps.div2p([re], [override])`
If `div2p` regexp test `id` + `className` of node success, all divs that don't have children block level elements will be turned into p's. `[re]` is a regexp, e.g. `/<(span|label)/` will match the element likes `<span>...` or `<label>...`, if `[override]` is set to `true`, `div2p` will be `/<(span|label)/i`, otherwise it will be appended to the origin, i.e. :
/<(a|blockquote|dl|div|img|ol|p|pre|table|ul|span|label)/i
- `this.regexps.images([re], [override])`
If `images` regexp test `src` attribute of node success, it will be picked as a normal `img`, otherwise will be dropped. `[re]` is a regexp, e.g. `/\.(gif|jpe?g|png)$/i` will match the `image` that `src` likes `/path/to/foo.jpg`, if `[override]` is set to `true`, `readart.regexps.images` will be replaced by `[re]`, otherwise it will be appended to the origin.
### Example
```javascript
read.use(function(){
this.reset();
this.skipTags('b,span');
this.regexps.div2p(/<(span|b)/, true);
});
` (Only affects JSON output).
Returns the inner text, e.g.:
read('http://example.com', {
output: 'text'
}, function(err, art){
// art.content will be formatted as TEXT
});
// or
read('http://example.com', {
output: {
type: 'text',
stripSpaces: true
}
}, function(err, art){
// art.content will be formatted as TEXT
});Returns the inner HTML, e.g.:
read('http://example.com', {
output: 'html'
}, function(err, art){
// art.content will be formatted as HTML
});
// or
read('http://example.com', {
output: {
type: 'html',
stripSpaces: true
}
}, function(err, art){
// art.content will be formatted as HTML
});Notes Videos could be scraped now, the domains currently are supported: youtube|vimeo|youku|tudou|56|letv|iqiyi|sohu|sina|163.
Returns the restful result, e.g.:
read('http://example.com', {
output: 'json'
}, function(err, art){
// art.content will be formatted as JSON
});
// or
read('http://example.com', {
output: {
type: 'json',
stripSpaces: true,
break: true
}
}, function(err, art){
// art.content will be formatted as Array
});The art.content will be an Array such as:
[
{ "type": "img", "value": "http://example.com/jpg/site1/20140519/00188b1996f214e3a25417.jpg" },
{ "type": "text", "value": "TEXT goes here..." }
]Util now there are only two types - img and text, the src of img element is absolute even if the original is a relative one.
Returns the cheerio node, e.g.:
read('http://example.com', {
output: 'cheerio'
}, function(err, art){
// art.content will be a cheerio node
art.content.find('div.what>ul.you>li.need');
});
// or
read('http://example.com', {
output: {
type: 'cheerio',
stripSpaces: true
}
}, function(err, art){
// art.content will be a cheerio node
art.content.find('div.what>ul.you>li.need');
});Notes The video sources of the sites are quite different, it's hard to fit all in a common way, I haven't find a good way to solve that, PRs are in demand.
## Notes / Gotchas **Pass the charset manually to refrain from the crazy messy codes** ```javascript read('http://game.163.com/14/0506/10/9RI8M9AO00314SDA.html', { charset: 'gbk' }, function(err, art){ // ... }); ```Generate agent to simulate browsers
read('http://example.com', {
agent: true // true as default
}, function(err, art){
// ...
});Use proxy to avoid being blocked
read('http://example.com', {
proxy: {
host: 'http://myproxy.com/',
port: 8081,
proxyAuth: 'user:password'
}
}, function(err, art){
// ...
});npm test
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.