딥러닝 기반의 실시간 입모양 인식 시스템 구현 (Real-Time Lip Reading System Implementation Based on Deep Learning)
This is the PyTorch implementation of CNN-LSTM trained on Ouluvs2 dataset.
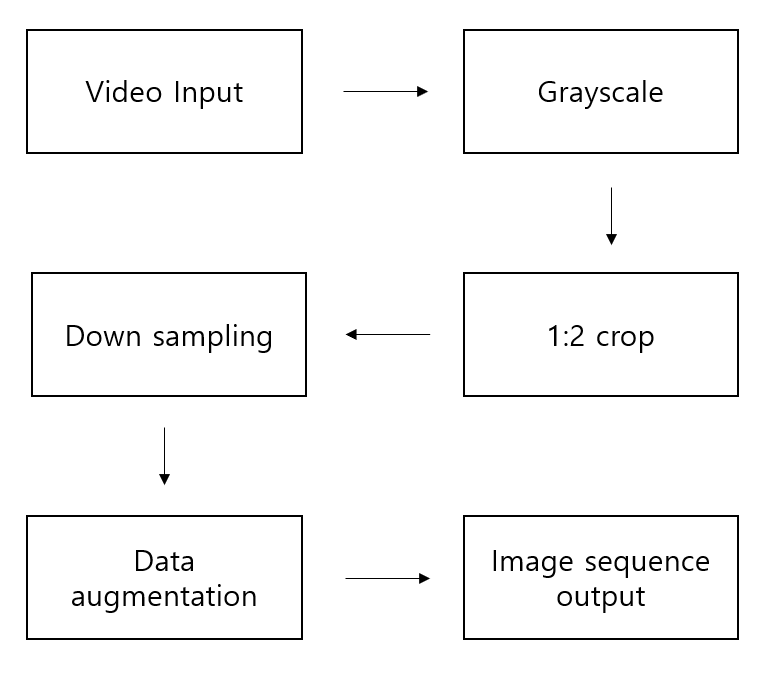
After extracting lip area from the video of speaking ten daily-use short English phrases, classify using the designed model.
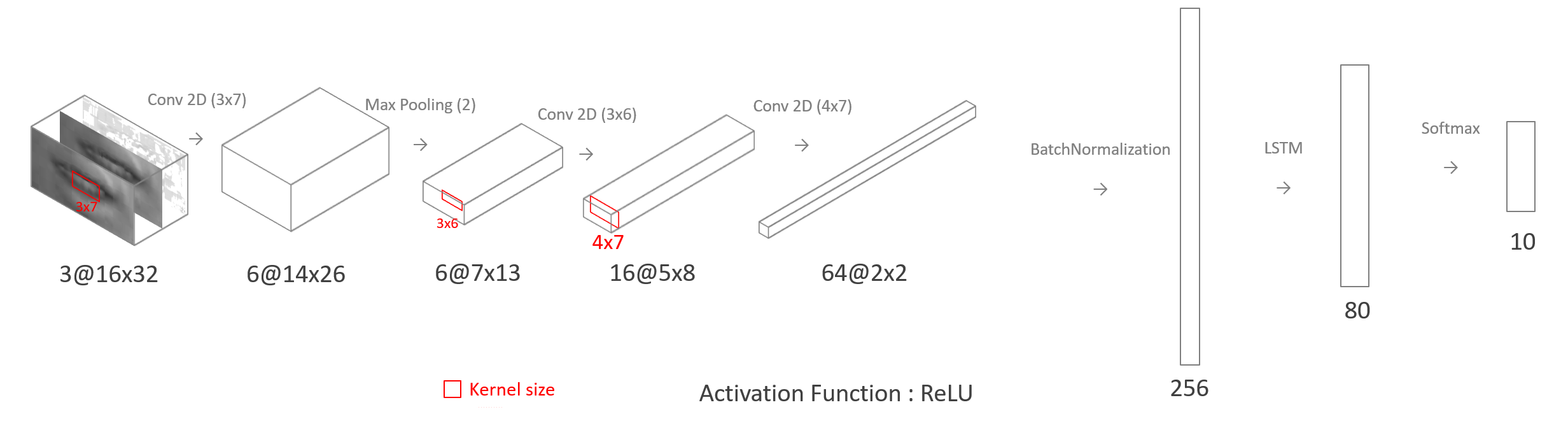
Use a three-channel image as input. The first channel uses the image of the previous frame. The second channel uses the image of the current frame. The third channel uses a different image of two consecutive images.


- Python >= 3.5
- Pytorch 0.4.0
- OpenCV >= 3.4
- Facial landmarks with dlib
- CUDA (if CUDA available)
-
Ouluvs2 (Phase 2)
the subject was asked to speak ten daily-use short English phrases. The same set of phrases was used in our previously collected OuluVS database. Every phrase was uttered three times.
- "Excuse me" : 63.50% [8271 / 13024]
- "Goodbye" : 86.46% [7429 / 8592]
- "Hello" : 32.32% [1986 / 6144]
- "How are you" : 59.73% [6279 / 10512]
- "Nice to meet you" : 63.13% [9253 / 14656]
- "See you" : 58.00% [4687 / 8080]
- "I am sorry" : 50.24% [5507 / 10960]
- "Thank you" : 61.42% [4973 / 8096]
- "Have a good time" : 68.83% [9791 / 14224]
- "You are welcome" : 51.81% [6641 / 12816]
Total Accuracy : 76.67%