- Introduction
- Why Any-to-Any?
- Roadmap
- Getting Started
- Current A2A Architecture
- The Future of A2A
- Incentives
- Acknowledgements
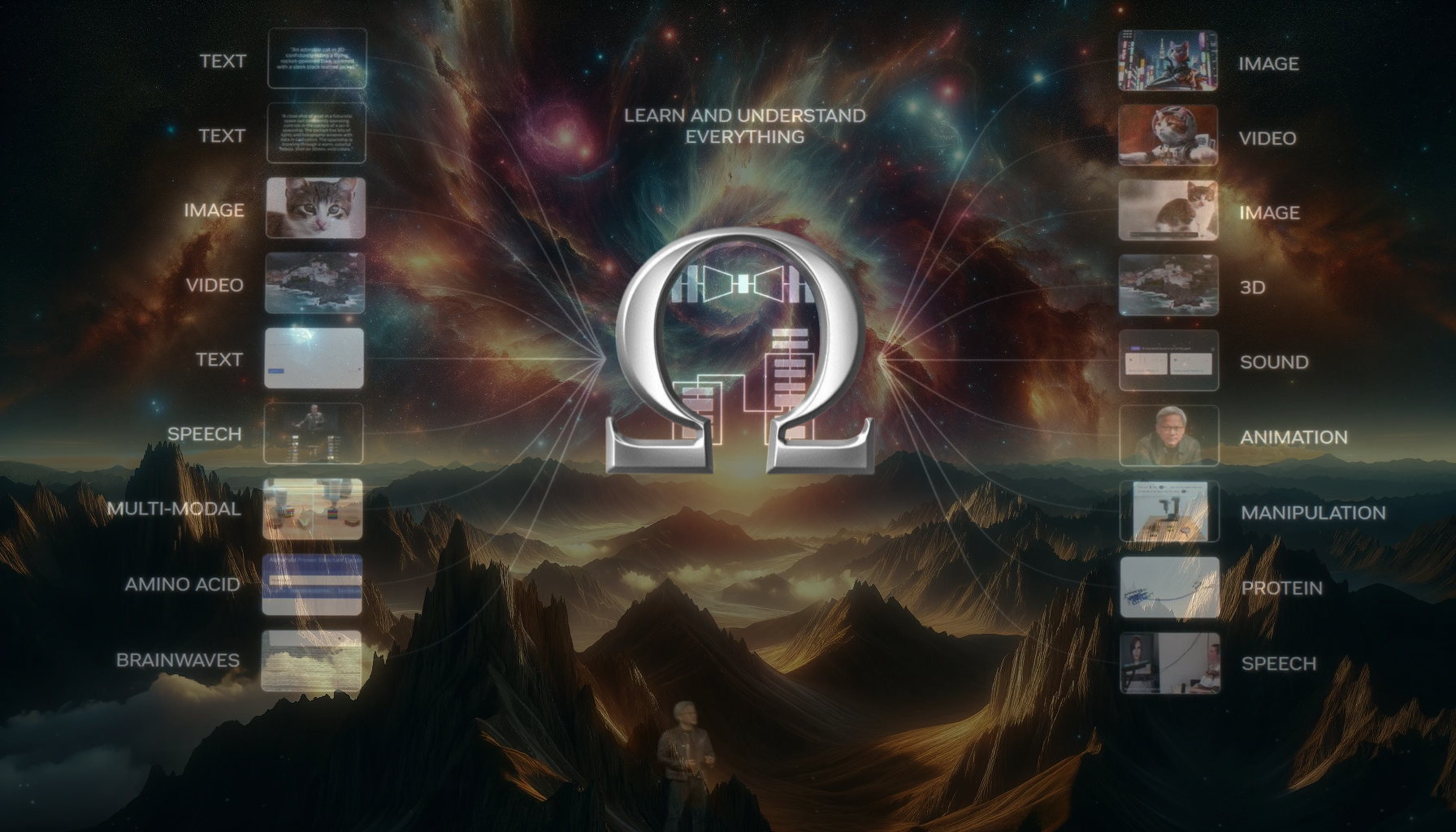
OMEGA Any-to-Any is a decentralized, open-source AI project built on the Bittensor blockchain by OMEGA Labs. Our mission is to create state-of-the-art (SOTA) multimodal any-to-any models by attracting the world's top AI researchers to train on Bittensor, taking advantage of Bittensor's incentivized intelligence platform. Our goal is to establish a self-sustaining, well-resourced research lab, where participants are rewarded for contributing compute and/or research insight.
TestNet UID: 157
- Multimodal First: A2A jointly models all modalities (text, image, audio, video) at once, with the belief that true intelligence lies in the associative representations present at the intersection of all modalities.
- Unified Fundamental Representation of Reality: The Platonic Representation Hypothesis suggests that as AI models increase in scale and capability, they converge towards a shared, fundamental representation of reality. A2A models, by jointly modeling all modalities, are uniquely positioned to capture this underlying structure, potentially accelerating the path towards more general and robust AI.
- Decentralized Data Collection: Thanks to our SN24 data collection, we leverage a fresh stream of data that mimics real-world demand distribution for training and evaluation. By frequently refreshing our data collection topics based on gaps in the current data, we avoid the issue of underrepresented data classes (see this paper for more discussion on this issue). Through self-play, our SN's best checkpoints can learn from each other and pool their intelligence.
- Incentivized Research: World class AI researchers and engineers already love open source. With Bittensor's model for incentivizing intelligence, researchers can be permissionlessly compensated for their efforts and have their compute subsidized according to their productivity.
- Bittensor Subnet Orchestrator: Incorporates specialist models from other Bittensor subnets, acting as a high-bandwidth, general-purpose router. By being the best open source natively multimodal model, future AI projects can leverage our rich multimodal embeddings to bootstrap their own expert models.
- Public-Driven Capability Expansion: Public demand dictates which capabilities the model learns first through the decentralized incentive structure.
- Beyond Transformers: Integrate emerging state-of-the-art architectures like early fusion transformers, diffusion transformers, liquid neural networks, and KANs.
- Design a hard-to-game validation mechanism that rewards deep video understanding
- Produce the first checkpoint with SOTA image and video understanding capabilities with our ImageBind + Llama-3 architecture as a proof-of-concept starting point
- Generalize the validation mechanism to enable broad architecture search and new multimodal tokenization methods
- Onboard 20+ top AI researchers from frontier labs and open source projects
- Expand SN24 data collection beyond YouTube to include multimodal websites (e.g. Reddit, blogposts) and synthetic data pipelines
- Launch OMEGA Focus screen recording app, providing rich data for modelling long-horizon human workflows, combatting the hallucination and distraction problem found in top closed-source LLMs
- Produce the first any-to-any checkpoint natively modelling all modalities that can beat other OSS models on top multimodal and reasoning benchmarks
- Develop a user-friendly interface for miners and validators to interact with the subnet's top models
- Onboard 50 more top AI researchers from top labs and open source research collectives
- Publish a research paper on A2A's architecture, incentive model, and performance
- Release open source multimodal embedding models (based on our top A2A checkpoint's internal embedding space) for other labs to condition their models on
- Integrate a framework that can auto-evaluate all the models & commodities produced by other subnets on Bittensor which our top models can then interact with, both through tool-use and through native communication in the latent-space via projection modules
- Produce the first any-to-any OSS checkpoint that beats all closed-source SOTA general intelligence models
- Establish partnerships with AI labs, universities, and industry leaders to drive adoption
- Expand our one-stop-shop Bittensor model evaluation and router framework to arbitrary open source and closed-source checkpoints and APIs
- Implement task-driven learning, with OMEGA Labs routinely curating high-signal tasks for model trainers to master
- Start crafting an entirely new "online" validation mechanism that rewards miners for producing agentic models that can complete real-world tasks
- Use our top checkpoint to power up the multimodal intelligence features of the OMEGA Focus app
- Launch our agent-focused "online" validation mechanism centered around long-range task completion
- Achieve SOTA performance on agent benchmarks
- Use OMEGA Focus as an outlet to provide OMEGA digital twin companions to users
- Launch an app store for A2A-powered applications leveraging our open source models
- Reach 10M+ users with the OMEGA Focus app
- Python 3.11+ with pip
- GPU with at least 40 GB of VRAM; NVIDIA RTXA6000 is a good choice, or use a 1024xH100 if you wanna train a really good model 😎
- At least 40 GB of CPU RAM
- If running on runpod,
runpod/pytorch:2.2.1-py3.10-cuda12.1.1-devel-ubuntu22.04is a good base template.
- Clone the repo and
cdinto it:
git clone git@github.com:omegalabsinc/omegalabs-anytoany-bittensor.git
cd omegalabs-anytoany-bittensor- Install the requirements:
- Using docker:
make build-and-run - Using your local Python:
pip install -e .
- Start a finetuning run:
make finetune-x1
- Tweak
config/8B_lora.yamlto change the hyperparameters of the training run.
- Upload the model to Huggingface:
python miner_utils/upload_model.py \
--hf_repo_id {HF REPO ID e.g. omegalabsinc/omega_agi_model} \
--wallet.name {miner wallet name} \
--wallet.hotkey {miner hotkey} \
--model_dir {the directory that the checkpoint is saved in e.g. output_checkpoints/experiment_1/} \
--epoch 0 \
--netuid NETUID
NOTE: If you want to run on testnet, simply add --subtensor.network test at the end of the command and use --netuid 157.
- Python 3.11+ with pip
- GPU with at least 40 GB of VRAM; NVIDIA RTXA6000 is a good choice
- At least 40 GB of CPU RAM
- If running on runpod,
runpod/pytorch:2.2.1-py3.10-cuda12.1.1-devel-ubuntu22.04is a good base template.
- Clone the repo and
cdinto it:
git clone git@github.com:omegalabsinc/omegalabs-anytoany-bittensor.git
cd omegalabs-anytoany-bittensor- Run the validator:
make validator NETUID={netuid} WALLET_NAME={wallet} WALLET_HOTKEY={hotkey} PORT={port}- Check your logs:
make check-logs
- Clone the repo and
cdinto it:
git clone git@github.com:omegalabsinc/omegalabs-anytoany-bittensor.git
cd omegalabs-anytoany-bittensor- Install the requirements:
pip install -e . - Run the validator script:
pm2 start neurons/validator.py --name omega-a2a-validator -- \
--netuid {netuid} \
--wallet.name {wallet} \
--wallet.hotkey {hotkey} \
--axon.port {port} \
--logging.trace- Check the logs:
pm2 logs omega-a2a-validator
At launch, we are starting with an approach that builds on one of the most powerful and mainstream LLMs as a backbone: Llama 3. A multilayer perceptron (MLP) projects Imagebind embeddings directly into the pretrained Llama 3 internal state, allowing a finetuned model to develop video understanding.
The provided mining repo with default settings will train both:
- the encoding projection layer, which encodes Imagebind embeddings into Llama 3 states, and
- a LoRA adapter which allows the underlying LLM to develop multimodal understanding
There are several immediate areas miners can investigate in order to produce a checkpoint with improved multimodal understanding:
- Train for longer,
- Find better hyperparameters: learning rate, optimizer, batch sizes, gradient accumulation, etc.,
- Use additional datasets (more diverse, or even larger than the SN24 dataset),
- Try different LoRA parameters, or finetune all parameters.
In the near future we'll enable much deeper architecture search, allowing researchers to experiment with different LLM backbones, vastly different encoders and decoders.
OMEGA A2A is poised to revolutionize the AI landscape by harnessing the power of Bittensor's incentivized intelligence model and attracting the world's top AI researchers. Our mission is to push the boundaries of what's possible in decentralized AI, focusing on:
- Developing fully multimodal, any-to-any models that outperform all other open-source solutions
- Creating an AI gateway framework to seamlessly integrate and evaluate models from across the Bittensor ecosystem and beyond
- Implementing task-driven learning and agent-focused validation to create models capable of completing complex, real-world tasks
- Powering up the OMEGA Focus app with cutting-edge multimodal intelligence and personalized digital twin companions
As we progress, we will explore fully decentralized infrastructure and governance to ensure a truly democratized AI ecosystem. Our research will explore groundbreaking architectures beyond transformers and attention mechanisms, pushing the limits of AI capabilities.
By hyper-connecting to the Ω SN24, we will access diverse, high-quality data that fuels our models' growth and enables them to tackle a wide range of tasks. Innovative monetization strategies will be implemented to sustain and grow the ecosystem, ensuring long-term success and viability.
Through the tireless efforts of our decentralized OMEGA A2A research collective, we aim to showcase the immense potential of Bittensor's incentivized intelligence model and establish ourselves as leaders in the AI research community and beyond.
Join us on this transformative journey as we shape the future of decentralized AI, unlocking new possibilities and creating a more accessible, powerful, and innovative AI ecosystem for all. 🚀
We aim to collectively push forward the SOTA of multimodal and agentic AI research. The incentives in this subnet will evolve as we add modalities and tasks, but they will consistently reflect this underlying goal.
The initial reward structure has two parts:
- Video understanding: can your checkpoint understand and accurately caption video embeddings?
- Language capabilities: does your checkpoint retain the language capabilities of the LLM backbone?
As we improve the incentive scheme over time to create better and more diverse multimodal capabilities, we'll give ample notice and detail of upcoming changes.
Thank you to Nous Research, MyShell, and Impel for the structure of the miner chain model upload and validator comparison scoring logic!