Obtenga su copia del repositorio de la práctica accediendo a Práctica 4
y pulsando sobre el botón Fork situado en la esquina superior derecha. A continuación, siga las
instrucciones de la Práctica 3 para crear una rama con el apellido de
los integrantes del grupo de prácticas, dar de alta al resto de integrantes como colaboradores del proyecto
y crear la copias locales del repositorio.
También debe descomprimir, en el directorio PAV/P4, el fichero db_spk.tgz
con la base de datos oral que se utilizará en la parte experimental de la práctica.
Como entrega deberá realizar un pull request con el contenido de su copia del repositorio. Recuerde que los ficheros entregados deberán estar en condiciones de ser ejecutados con sólo ejecutar:
make release
run_spkid mfcc train test classerr verify verifyerrA modo de memoria de la práctica, complete, en este mismo documento y usando el formato markdown, los ejercicios indicados.
- Escriba el pipeline principal usado para calcular los coeficientes cepstrales de predicción lineal
(LP), en el fichero
scripts/wav2lp.sh:
sox $inputfile -t raw - | $X2X +sf | $FRAME -l 200 -p 40 | $WINDOW -l 200 -L 200 |
$LPC -l 200 -m $lpc_order > $base.lp- Escriba el pipeline principal usado para calcular los coeficientes cepstrales de predicción lineal
(LPCC), en su fichero
scripts/wav2lpcc.sh:
sox $inputfile -t raw - dither -p12 | $X2X +sf | $FRAME -l 200 -p 40 | $WINDOW -l 200 |
$LPC -l 200 -m $lpc_order | $LPC2C -m $lpc_order -M $nceps > $base.cep- Escriba el pipeline principal usado para calcular los coeficientes cepstrales en escala Mel (MFCC), en
su fichero
scripts/wav2mfcc.sh:
sox $inputfile -t raw - dither -p12 | $X2X +sf | $FRAME -l 200 -p 40 |
$MFCC -l 200 -m $mfcc_order -s 8 -n $ncoef > $base.mfcc- Indique qué parámetros considera adecuados para el cálculo de los coeficientes LPCC y MFCC.
LPCC:
EXEC="wav2lpcc 16 20 $db/$filename.wav $w/$FEAT/$filename.$FEAT"Hemos decidio probando un orden de lpcc de 16 i número de cepstrums 20 consiguiendo un error rate bueno. Para el cálculo de los coeficientes MFCC:
EXEC="wav2mfcc 13 16 $db/$filename.wav $w/$FEAT/$filename.$FEAT"En este caso usamos un orden de mfcc de 13 (el que se usa de forma habitual) y 16 coefs. También con mfcc hemos obtenido un resultado aceptable.
-
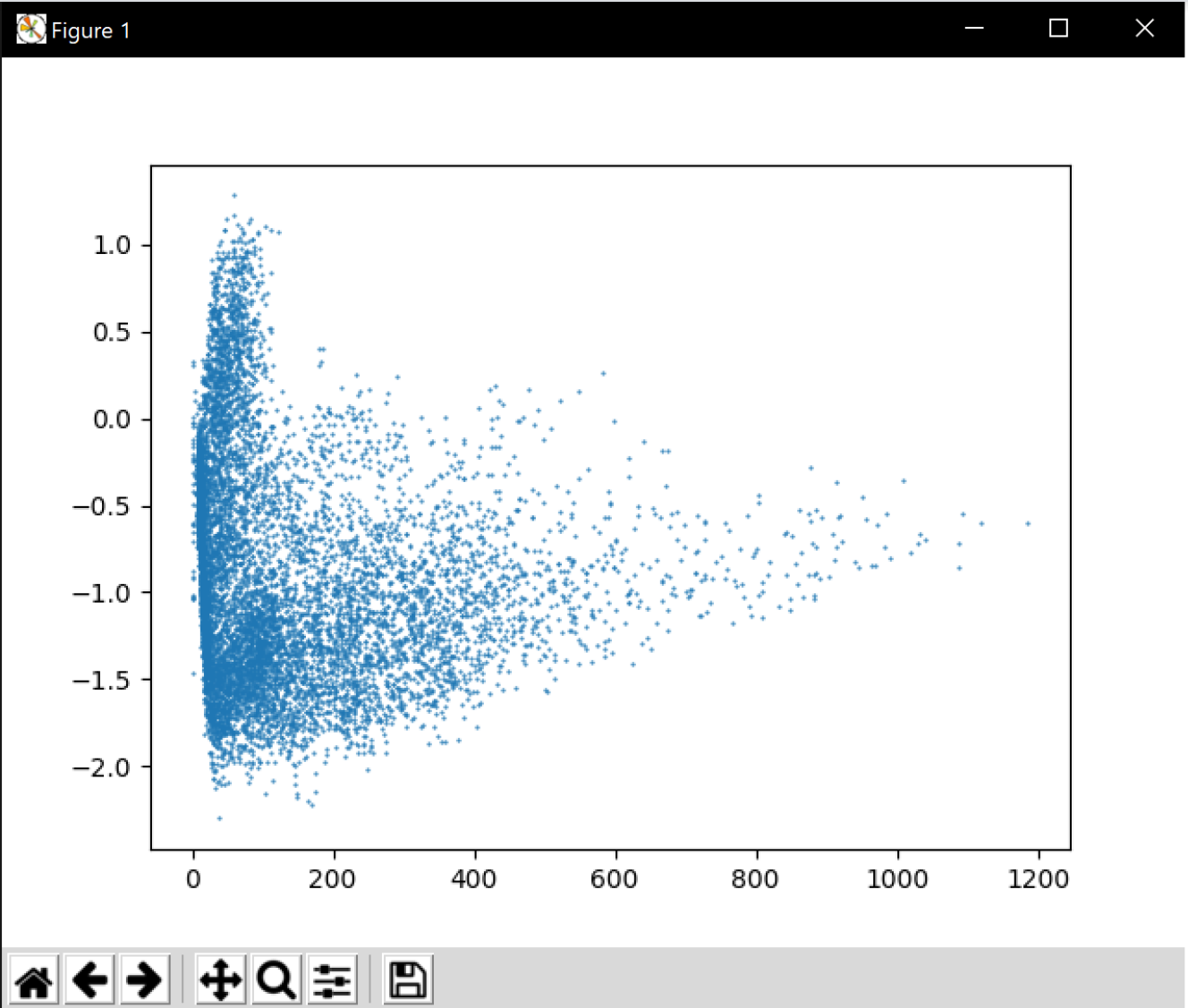
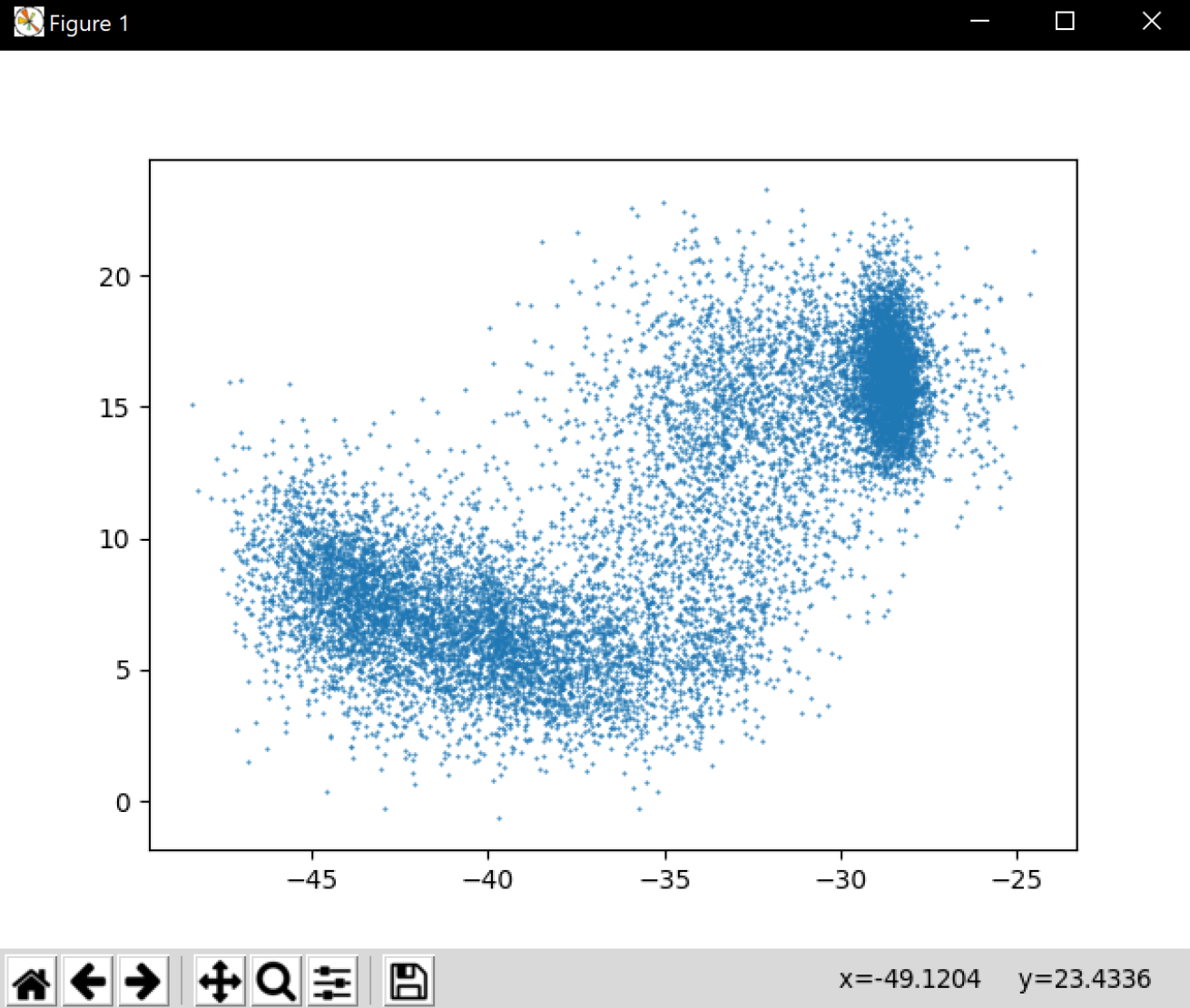
Inserte una imagen mostrando la dependencia entre los coeficientes 2 y 3 de las tres parametrizaciones para una señal de prueba.
Parametrización LP
Parametrización MFCC
Parametrización LPCC
- ¿Cuál de ellas le parece que contiene más información?



La representación del mel-cepstrum és la que muestra la información más completa, debito a que este oncentra la información del trozo de señal analizado en un numero reducido de muestras y tiene coeficientes más incorrelados que en los demas casos. Por lo tanto,en el momento de la clasificación habrá menos redundancia. La percepción acústica de el sistema auditivo humano funciona diferente según las bandas frecuenciales. El mel cepstrum es el que se usa normalmente para este tipo de aplicaciones, ya que concentra la información en los primeros coeficientes.
-
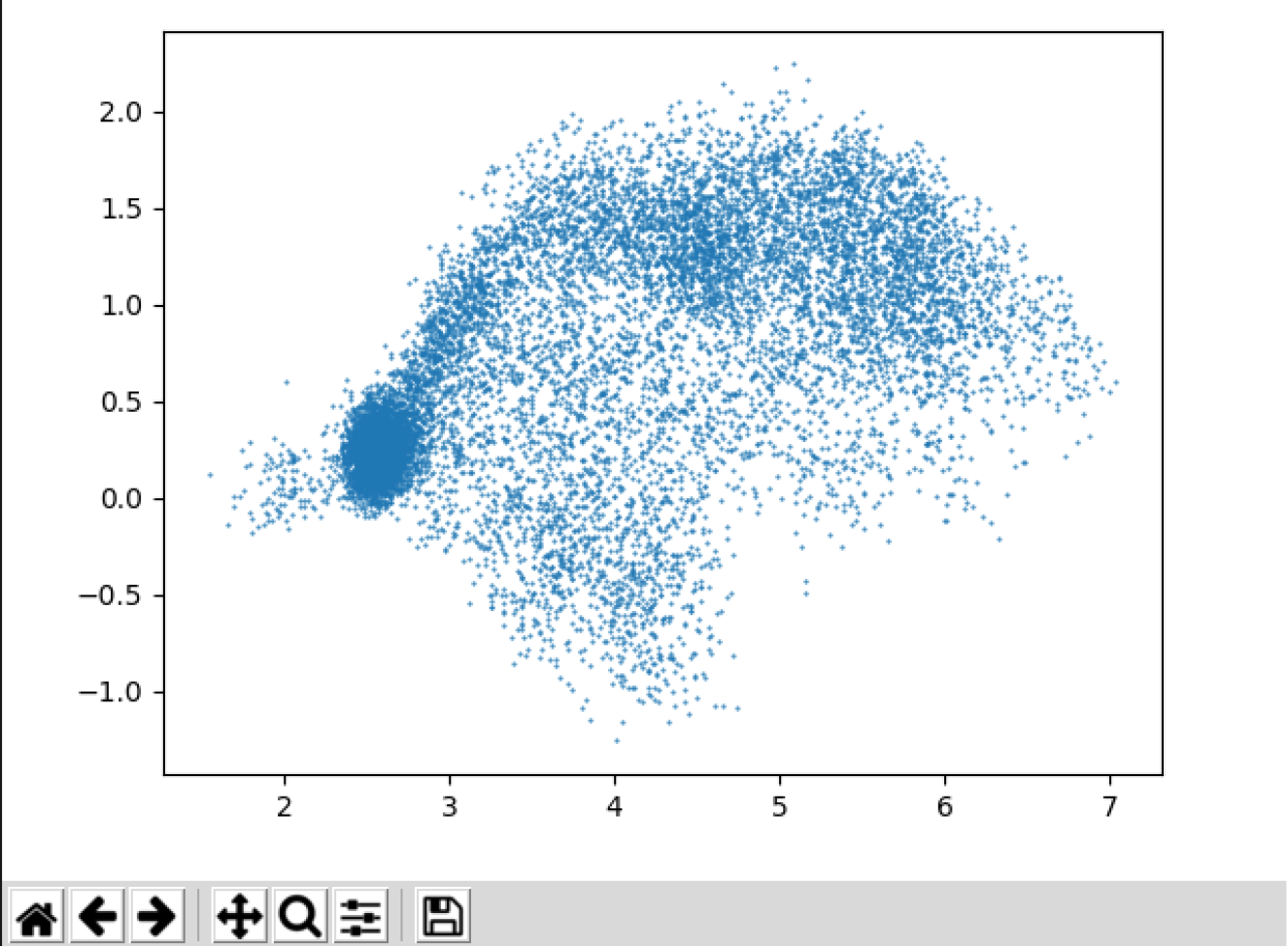
Inserte una gráfica que muestre la función de densidad de probabilidad modelada por el GMM de un locutor para sus dos primeros coeficientes de MFCC.
-
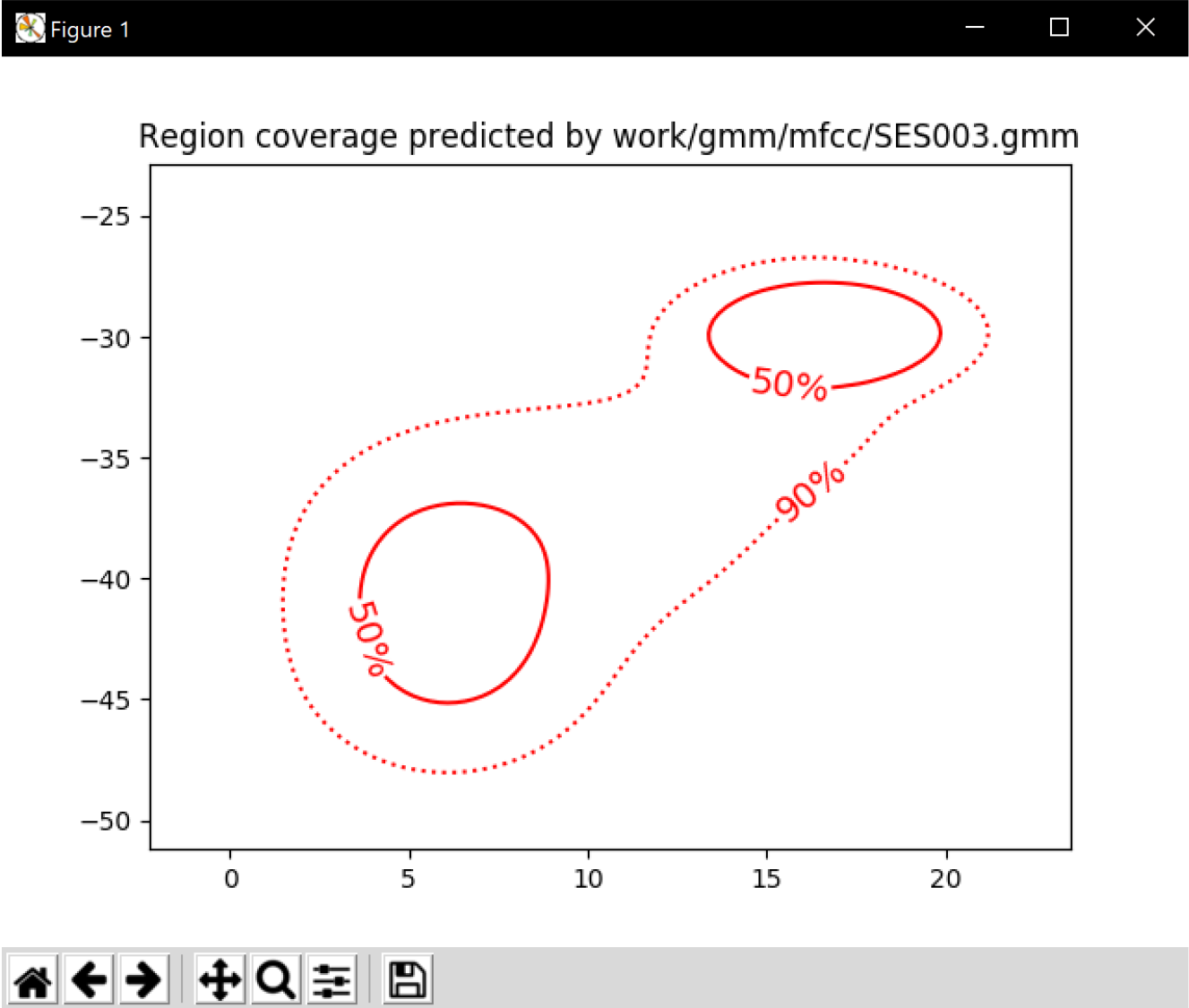
Inserte una gráfica que permita comparar los modelos y poblaciones de dos locutores distintos. Comente el resultado obtenido y discuta si el modelado mediante GMM permite diferenciar las señales de uno y otro.
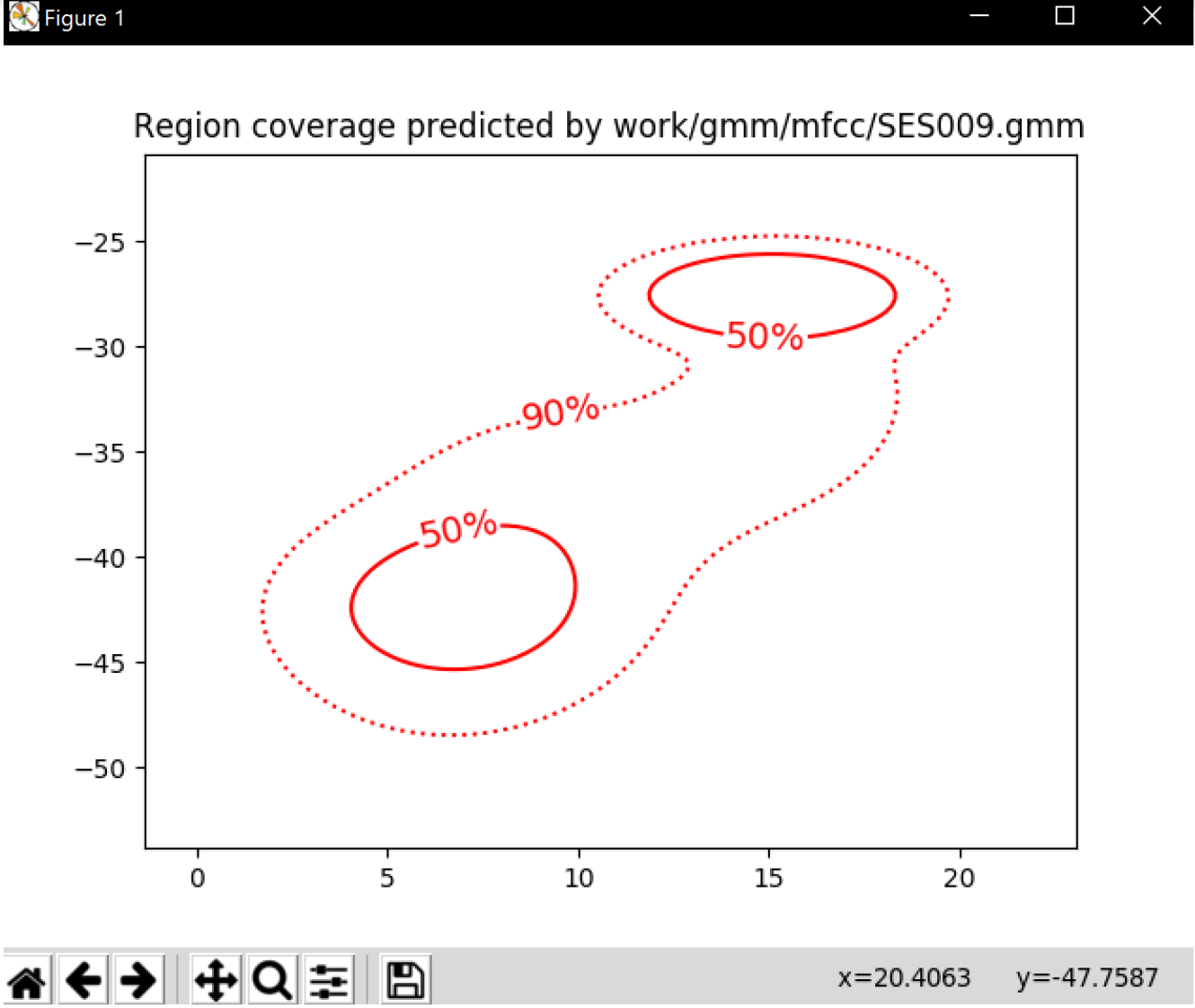


La imagen corresponde a la GMM obtenida de un locutor distinto de la pregunta anterior. Como podemos ver si comparamos las dos gráficas se diferencian en la probabilidad de decisión. La salida se representa con las direcciones de máxima varianza. Una vez obtenidas las características se hace la parametrización a partir de las fdp gaussianas.
-
Inserte una tabla con la tasa de error obtenida en el reconocimiento de los locutores de la base de datos SPEECON usando su mejor sistema de reconocimiento para los parámetros LP, LPCC y MFCC.
LP LPCC MFCC ERROR_RATE 2,32% 0,64% 0,64%
-
Inserte una tabla con el score obtenido con su mejor sistema de verificación del locutor en la tarea de verificación de SPEECON. La tabla debe incluir el umbral óptimo, el número de falsas alarmas y de pérdidas, y el score obtenido usando la parametrización que mejor resultado le hubiera dado en la tarea de reconocimiento.
LP LPCC MFCC COSTDETECT 62,4% 16,7% 83,2% MISSED 156/250 17/250 208/250 FALSE AL 0/1000 1/1000 0/1000
-
Recuerde adjuntar los ficheros
class_test.logyverif_test.logcorrespondientes a la evaluación ciega final. -
Recuerde, también, enviar a Atenea un fichero en formato zip o tgz con la memoria con el trabajo realizado como ampliación, así como los ficheros
class_ampl.logy/overif_ampl.log, obtenidos como resultado del mismo.+