

| Tyler Woods | Joseph Shanks | Wesley Nguyen |
|---|

It's a bird... it's a plane...it's... a U.F.O. sighting? Over the course of human history U.F.O. sightings seem to be commonplace; commonly described as "flying saucers", strange lights and objects or straight up "Aliens". There are a lot of unknowns that surround the idea of unidentified flying objects, but one thing that is known, are that people are continually fascinated by them. Today, we are looking at reported U.F.O. sightings from . These are anonymous reports from various people all over the U.S. and sometimes even internationally.
Using Natural Language Processing, we are hoping to parse through these sighting reports and explore possible commonalities, insights, and sentiment about these suspicious objects. By doing this, we are hoping to gain a more concrete truth of whether these sightings are figments of people's imaginations, or that there might be actually be an alien overlord visiting us from time to time.
If reports from Alabama mention that this mysterious "object" has the shape of a rectangle, while reports from other states express the same thing, is it possible to make a connection here?
| SOURCE | TIMEFRAME | N_RECORDS |
|---|---|---|
| MAY 10th 2017 | 100 |
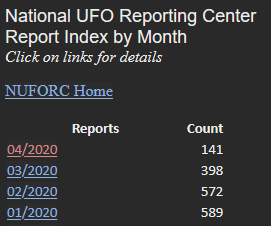
The specific data that we are focusing on today are U.F.O. reports from May 10th, 2017, with a total of 99 sightings. Below is a preview of the format that the data comes in from the website.

Here is a detailed description of the intake data:
ID: Report IDurl: Report URLhtml: Raw HTML from reporttime: Date Time Object of the report

Looking at this data, we noticed that there were a couple things that could be cleaned and changed.
def clean_data(data:pd.DataFrame) -> pd.DataFrame:
"""Cleaner for UFO DataFrame"""
# Copy data to avoid collision
df_copy = data.copy()
# Rename ID Column for Clarity
df_copy.columns.values[0] = 'ID'
# Convert Time to DateTime Object
df_copy['time'] = pd.to_datetime(df_copy['time'])
# Parse data from HTML Column
df_copy['state'] = None
df_copy['content'] = None
df_copy['shape'] = None
for i in range(len(df_copy)):
soup = BeautifulSoup(df_copy['html'][i], 'html.parser')
meta_data = soup.find_all('tbody')[0].find_all('tr')[0]
s = meta_data.get_text('|', strip=True).split("|")
# store data into a dictionary
s_dict = {x.partition(":")[0]:x.partition(":")[-1] for x in s}
state = s_dict['Location'][-2:]
df_copy.loc[i, 'state'] = state
entry = soup.find_all('tbody')[0].find_all('tr')[1]
df_copy.loc[i, 'content'] = entry.get_text(strip=True)
duration = s_dict['Duration']
df_copy.loc[i, 'duration'] = duration
shape = s_dict['Shape']
df_copy.loc[i, 'shape'] = shape
return df_copyWe ended up parsing the data in the 'HTML' rows of our dataframe in order to extract useful information, using the cleaner function above we succesfully created new columns. The resule of this are below:
ID: Report IDurl: Report URLhtml: Raw HTML from reporttime: Date Time Object of the reportstate: Reported Locationcontent: Content of the reportshape: Alleged Shape of the UFOduration: Duration of the report sighting

After creating our stop words list and removing punctuations we tokenized our documents. “Tokenize” means creating “tokens” which are atomic units of the text. These tokens are words extracted by splitting the document.We then used the “SnowballStemmer” to stem our tokenized words. We decided to use the snowball stemmer over the WordNetLemmatizer or the PorterStemmer. The reason for this is show below.
porter = PorterStemmer()
snowball = SnowballStemmer('english')
wordnet = WordNetLemmatizer()
docs_porter = [[porter.stem(word) for word in words]
for words in doc_filter]
docs_snowball = [[snowball.stem(word) for word in words]
for words in doc_filter]
docs_wordnet = [[wordnet.lemmatize(word) for word in words]
for words in doc_filter]
## Print the stemmed and lemmatized words from the first document
print(“%16s | %16s | %16s | %16s |” % (“WORD”, “PORTER”, “SNOWBALL”, “LEMMATIZER”))
for i in range(min(len(docs_porter[0]), len(docs_snowball[0]), len(docs_wordnet[0]))):
p, s, w = docs_porter[0][i], docs_snowball[0][i], docs_wordnet[0][i]
if len(set((p, s, w))) != 1:
print(“%16s | %16s | %16s | %16s |” % (doc_filter[0][i], p, s, w)) WORD | PORTER | SNOWBALL | LEMMATIZER |
hovered | hover | hover | hovered |
looked | look | look | looked |
helicopter | helicopt | helicopt | helicopter |
stayed | stay | stay | stayed |
disappeared | disappear | disappear | disappeared |
appears | appear | appear | appears |
us | us | us | u |
consistent | consist | consist | consistent |
sighting | sight | sight | sighting |
venus | venu | venus | venus |
We chose to stem the words with the Snowball Stemmer due to its preservation of important words for this usecase such as ‘venus’. The Snowball Stemmmer normalizes these words from its appeared form into their root form. We now have our list of clean tokens for each document! We turned this into a pandas Series to compute the TF-IDF
Choropleth Map:
The choropleth map shown in the notebook 'choropleth_map.ipynb' shows the number of reports from each state in the time period, as well as the three most common words from those reports of each state. With this information, we see a detailed image of where the reports are coming from and what the reports are talking about. 15:51
Observed UFO Shapes:
The bar chart shows what the most common shapes are in the reports. We can see that 'Circles' and 'Teardrops' are common shapes, as well as individuals reporting just seeing 'Light'.

Changes in Vocabulary Size Per Minimum Document Frequency:
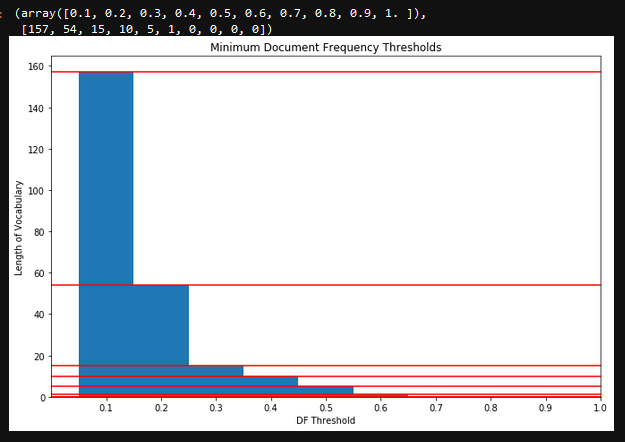
0.1 -- vocabulary (len=157): ['light', 'look', 'nuforc', 'helicopt', 'first', 'bright', 'pd', 'disappear', 'way', 'went', 'sight', 'report', 'seen', 'us', 'one', 'like', 'east', 'appear', 'note', 'hover', 'could', 'sky', 'provid', 'elect', 'stationari', 'star', 'inform', 'anonym', 'contact', 'remain', 'sourc', 'travel', 'notic', 'fli', 'someth', 'approxim', 'clear', 'see', 'would', 'wit', 'sound', 'come', 'direct', 'near', 'craft', 'saw', 'west', 'air', 'north', 'feet', 'object', 'tree', 'mayb', 'shape', 'side', 'view', 'size', 'orang', 'circl', 'never', 'hous', 'gone', 'pass', 'time', 'seem', 'move', 'low', 'almost', 'straight', 'white', 'plane', 'still', 'anoth', 'know', 'quick', 'toward', 'made', 'outsid', 'normal', 'stop', 'make', 'flash', 'mile', 'distanc', 'high', 'insid', 'chang', 'thought', 'go', 'minut', 'back', 'second', 'watch', 'show', 'around', 'two', 'ball', 'even', 'away', 'night', 'south', 'thing', 'came', 'point', 'color', 'end', 'green', 'complet', 'take', 'drive', 'reflect', 'window', 'line', 'nois', 'noth', 'ufo', 'blue', 'left', 'speed', 'red', 'behind', 'live', 'area', 'aircraft', 'get', 'slowli', 'head', 'flew', 'glow', 'across', 'right', 'slow', 'phone', 'fast', 'also', 'larg', 'home', 'cloud', 'big', 'tri', 'photo', 'indic', 'turn', 'video', 'three', 'got', 'eye', 'float', 'moon', 'face', 'street', 'later', 'front', 'observ', 'start', 'visibl', 'think']
0.2 -- vocabulary (len=54): ['light', 'look', 'nuforc', 'first', 'bright', 'pd', 'disappear', 'went', 'sight', 'report', 'seen', 'one', 'like', 'east', 'appear', 'note', 'could', 'sky', 'provid', 'elect', 'inform', 'anonym', 'contact', 'remain', 'sourc', 'notic', 'see', 'would', 'wit', 'sound', 'direct', 'craft', 'saw', 'west', 'object', 'shape', 'time', 'seem', 'move', 'white', 'plane', 'still', 'stop', 'thought', 'go', 'minut', 'back', 'second', 'watch', 'around', 'two', 'night', 'south', 'get']
0.3 -- vocabulary (len=15): ['light', 'look', 'nuforc', 'bright', 'pd', 'report', 'one', 'like', 'note', 'could', 'sky', 'see', 'saw', 'object', 'move']
0.4 -- vocabulary (len=10): ['light', 'look', 'nuforc', 'pd', 'like', 'note', 'sky', 'saw', 'object', 'move']
0.5 -- vocabulary (len=5): ['light', 'look', 'sky', 'saw', 'move']
0.6 -- vocabulary (len=1): ['light']
0.7 -- vocabulary (len=0): []
0.8 -- vocabulary (len=0): []
0.9 -- vocabulary (len=0): []
1.0 -- vocabulary (len=0): []
Document Frequencies at Minimum of 0.5
# See words with a high frequency threshhold 50%
thresh = 0.5
for word, freq in doc_freq.items():
if freq >= thresh:
print(f"{word}: {freq}")light: 0.6767676767676768
look: 0.5252525252525253
sky: 0.5656565656565656
saw: 0.5151515151515151
move: 0.5858585858585859
Using NaieveBayes to test comminalities of words used to derive if these occurences are related.
Do the U.F.O. sightings have a similar distribution of reports from states?