The goal of this challenge is to get experience doing quality control for labeled data.
The original source of this data and the project is a UPenn class: http://crowdsourcing-class.org/. Highly suggest checking it out to learn more about crowdsourcing / data labeling!
Note: it is not necessary to use pyenv, but you do need python 3.6.
Follow this tutorial to install pyenv and learn about it:
https://amaral.northwestern.edu/resources/guides/pyenv-tutorial
Then create a virtual env for this project:
pyenv virtualenv 3.6.5 labeling-challenge
pyenv activate 3.6.5/envs/labeling-challenge
Run the following:
pip install -r requirements.txt
This data is from a real mTurk project for Adjectives and Attribute Matching.
First, take a close look at the instructions that were provided to the labelers:
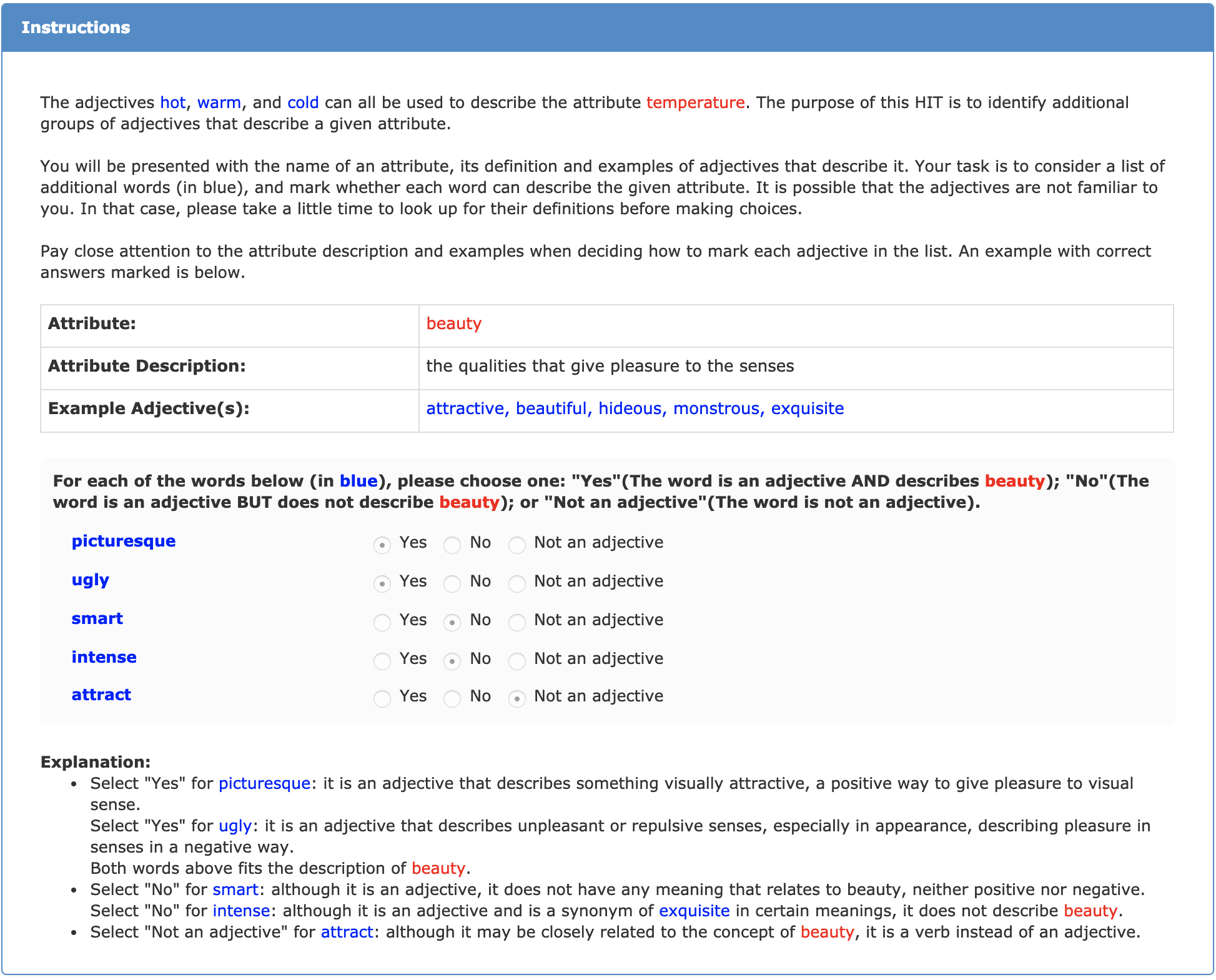
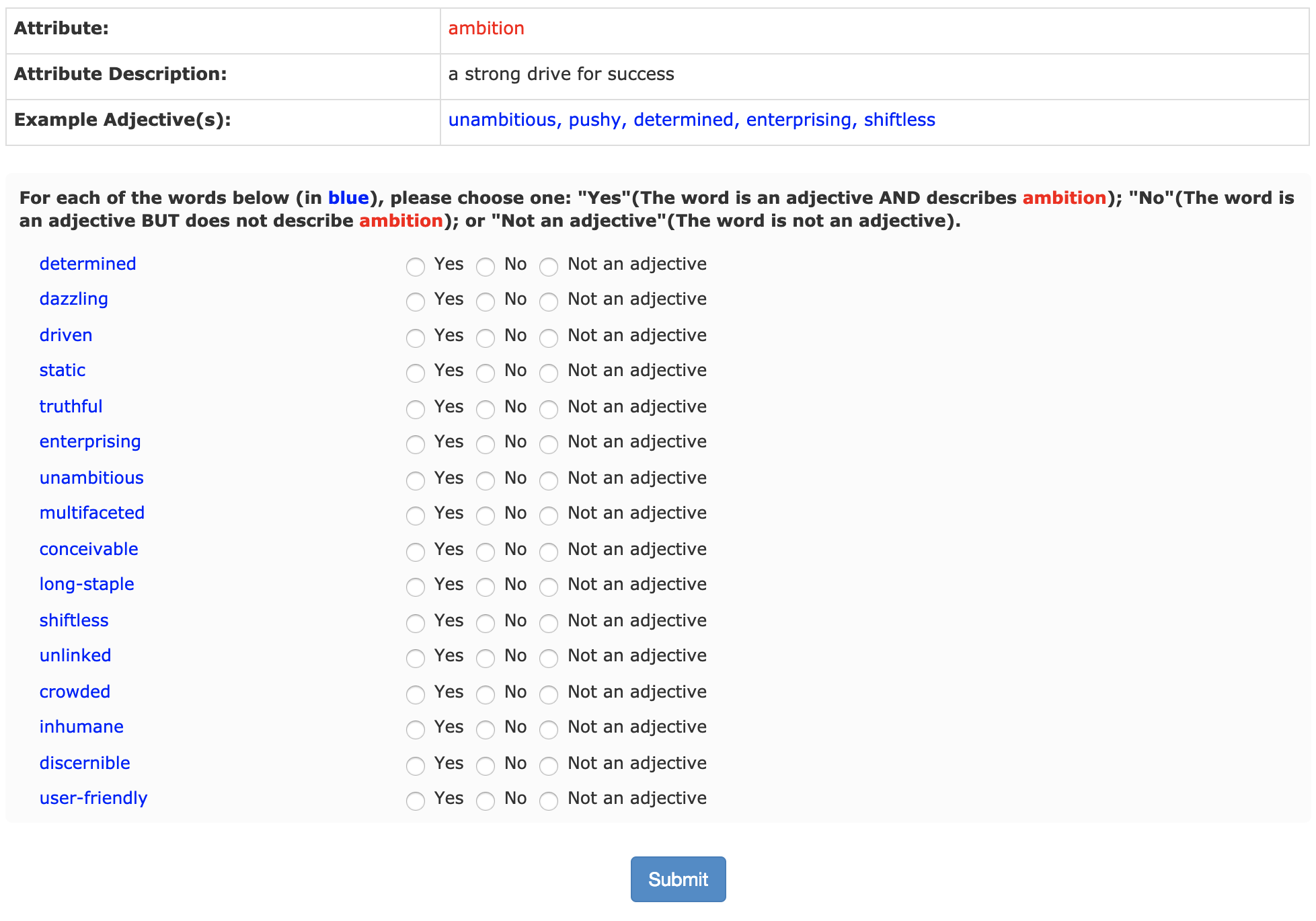
Now inspect the raw data file, raw_data.csv.
A few things to note:
- You can get a unique id for the worker in column
WorkerId - Lifetime approval rate: percentage of times requester has approved work of this mTurker across all tasks
Input.attr_idis the unique id for the attribute,Input.adj_*are the adjectives andAnswer.adj_*the labeler's answers- If the labeler answered 'No' or 'not an adj', these are both listed as no in the dataset
Open summarize_labels.py and take a look.
Then try to run it:
python summarize_labels.py
And inspect the answers it produces by opening summarized_data.csv.
How good are the labels? Run
python evaluate_results.py
Write your own label summarization algorithm in summarize_labels.py.
Want a hint?
Think about how you can assess whether certain labelers are reliable or not.
You could also think about whether 50% is the right threshold to use.
Want another hint?
Columns Input.adj_11 through Input.adj_16 have known ground truth. 11-15 are True and 16 is False. How can you use this to evalute the labelers?
One last hint!
Come up with a "reliability score" for the labelers by assessing their performance on columns 11-16. Predict the label based on the weighted average of scores, not the simple average. You can also consider dropping unreliable labelers.