Documento introdutório ao conceito de autoencoders, suplementado com exemplos de código pormenorizadamente explicado dos vários tipos referidos, assim como os modelos já treinados. Conhecimento básico das várias camadas de uma rede neuronal ajudará na compreensão deste guia.
Documento baseado neste post
Conhecimento básico sobre redes neuronais será bastante útil na compreensão deste documento
- Conceito de Autoencoders
- Bibliotecas e datasets utilizados
- Autoencoder simples
- Autoencoder esparso
- Autoencoder profundo
- Autoencoder convolucional
- Aplicações em data denoising
- Autoencoder variacional
Um autoencoder é um tipo algoritmo de compressão e descompressão de dados baseado em redes neuronais
Um autoencoder é, na verdade, composto por duas redes neuronais: um encoder e um decoder
-
encoder - Responsável pela compressão. Recebe como input os nossos dados na sua forma original e devolve como output esses dados representados numa dimensionalidade inferior. (ex: representar uma imagem 28x28 (784 píxeis) em apenas 32 neurónios. Compressão de 784 valores para 32 )
-
decoder - Responsável pela descompressão. Recebe como input o output do encoder, ou seja, uma representação comprimida dos nossos dados originais. É-lhe também dada a representação original e, a partir daí, o decoder será treinado para conseguir reconstruir a imagem original a partir da versão comprimida. (ex: recebe a informação dos 32 neurónios e reconstrói a imagem de 784 píxeis)
Os autoencoders são:
- Data-specific. Só conseguem processar tipos de dados semelhantes àqueles em que foram treinados.
- Lossy. Os dados descomprimidos nunca serão 100% idênticos aos originais
- Learned automatically. Não é necessário ser o programador a codificar um algoritmo de compressão. A rede neuronal encarregarse-à de encontrar a melhor maneira que consegue de comprimir e descomprimir a informação.
Devido a estas características, a utilização de autoencoders na compressão de dados não é muito comum, no entanto, algumas outras aplicações têm surgido, como data denoising, que será discutida posteriormente neste documento.
- TensorFlow 2.0. Implementação das redes neurais
- Keras. API de alto nível assente por cima do tensorflow e permite maior facilidade na inplementação dos modelos
- Numpy. Manipulação de arrays
- Matplotlib. Visualização dos resultados
Estas bibliotecas tanto podem ser instaladas no próprio computador, utilizando para isso o pip para instalá-las, ex:
pip install tensorflow==2.0.0-beta1
ou, pode-se utilizar o Google Colaboratory, uma ferramenta da google que nos disponibiliza virtual boxes com as ferramentas já pré-instaladas. Para correr este código basta escolher Runtime-> Change Runtime: GPU (para que a versão mais eficaz para gpu do tensorflow seja utilizada) e colocar lá o código presente neste repositório.
Em todos os exemplos foi sempre utilizado o dataset MNIST. Este dataset contém dígitos desenhados à mão e é considerado quase o hello world do mundo da inteligência artificial. Nos nossos exemplos iremos tentar reconstruir estes dígitos
O resultado de todos os autoencoders pode ser verificado ao correr os scripts dentro da pasta de cada um dos autoencoders
Caso se pretenda treinar novamente os modelos basta eliminar os ficheiros .h5 e correr de novo o ficheiro .py.
Exemplo mais simples de um autoencoder, apenas utiliza uma input layer e duas Dense Layers. Uma dense layer nada mais é do que um conjunto de neurónios que se encontram TODOS ligados a TODOS os neurónios da layer anterior e da posterior, caso existam. A última dense layer será a responsável por reconstruir a imagem.
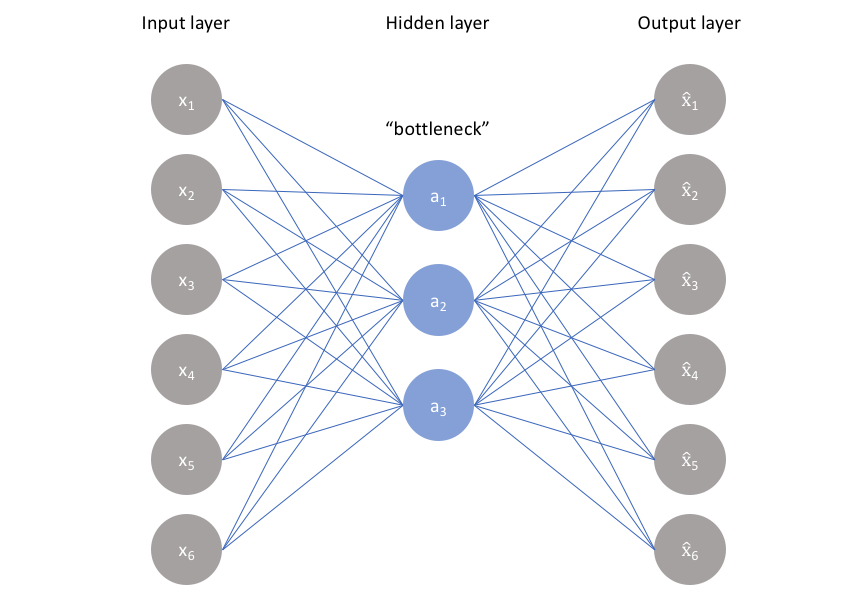
Disclaimer: É comum indicar a presença de uma input layer, deste modo:
keras.layers.Input(shape=(784,))
keras.layers.Dense(32, activation='relu')No entanto, por uma questão de comodidade, o keras permite-nos especificar o input logo na layer seguinte:
keras.layers.Dense(32, activation="relu", input_shape=(784,))Este segundo modo foi escolhido para este documento devido a um bug com a versão beta do tensorflow que não permite que se guardem e leiam modelos com input layers discriminadas como no primeiro exemplo.
Um autoencoder esparso assemelha-se bastante a um autoencoder simples, sendo a diferença entre eles o número de neurónios que podem ser disparados a qualquer segundo. Num autoencoder esparso limitamos o número de neurónios que estão a ser disparados utilizando um activity_regularizer
keras.layers.Dense(32, activation="relu", input_shape=(784,),activity_regularizer=keras.regularizers.l1(10e-5))Um autoencoder profundo baseia-se numa rede neural profunda. Uma rede neural profunda é uma rede que em vez de possuir apenas uma hidden layer, utilizará um conjunto de dense layers

Este é o tipo de encoder recomendado para o processamento de imagens devido a utilizar redes neurais convolucionais(CNNs).
Neste tipo de rede são usados três tipos de layers específicos:
- Layers de convolução. Layers responsáveis por aplicar filtros à imagem. Estes filtros tentarão salientar aspetos chave da imagem como, por exemplo, traços horizontais/ verticais.
- Layers de pooling. Layer que irá reduzir o tamanho da imagem. Um método bastante utilizado é o maxPooling em que entre 2 pixeis se mantém apenas o que contém maior valor
- Layers de upsampling/ depooling. Oposto do pooling. A partir de uma imagem de menores dimensões irão expandir a imagem. O método mais comum é a duplicação dos píxeis
Para além destas layers, é comum utilizar também uma dense layer devido à sua eficácia.

Como as redes neurais convolucionais se focam nos aspets chave de uma imagem, os autoencoders convolucionais possuem uma performance melhor do que outras técninas utilizadas no que toca a recuperar dados corrompidos.
No código exemplo que se encontra neste repositório, corrompemos propositadamente as imagens dos dígitos desenhados à mão e fornecemo-las ao autoencoder. De seguida demos ao autoencoder as imagens antes de serem corrompidas para que ele treinasse com o propósito de recuperar as imagens originais.
imagens corrompidas

Vertente mais moderna e complexa dos autoencoders. Este encoder foca-se nas variáveis latentes de uma imagem, isto é, as características que nós não lhe especificamos mas que ele infere através de calculos matemáticos. Um dos modos como faz isso é, ao invés do encoder devolver apenas um array/tensor correspondente aos dados, devolve 2: um tensor da média e um do desvio padrão.

Utilizando esta metodologia, o autoencoder aprende quais são as características associadas com uma certa probabilidade a cada tipo de dígito.
Esta característica permite-lhe gerar dígitos novos, bastando ao utilizador fornecer-lhe valores para as variáveis latentes e não as imagens. Um autoencoder variacional é então um modelo generativo
Post com uma explicação mais detalhada deste tipo de autoencoders.
Projeto em que são utilizados VAEs para criar novas caras a partir da cara de pessoas famosas