Visually explore semantic relationships within the dictionary
This project takes advantage of NLP word embeddings to enable the user to navigate the latent space of a dictionary by adding & subtracting semantic meanings between words.
Input a word to find similar words on the 3D visualization of word embeddings. Further refine your query by layering positive or negative relationships of other words onto the query. You can see how your query evolves by watching the gray line move around the vector space.
See the Live Demo 🔗
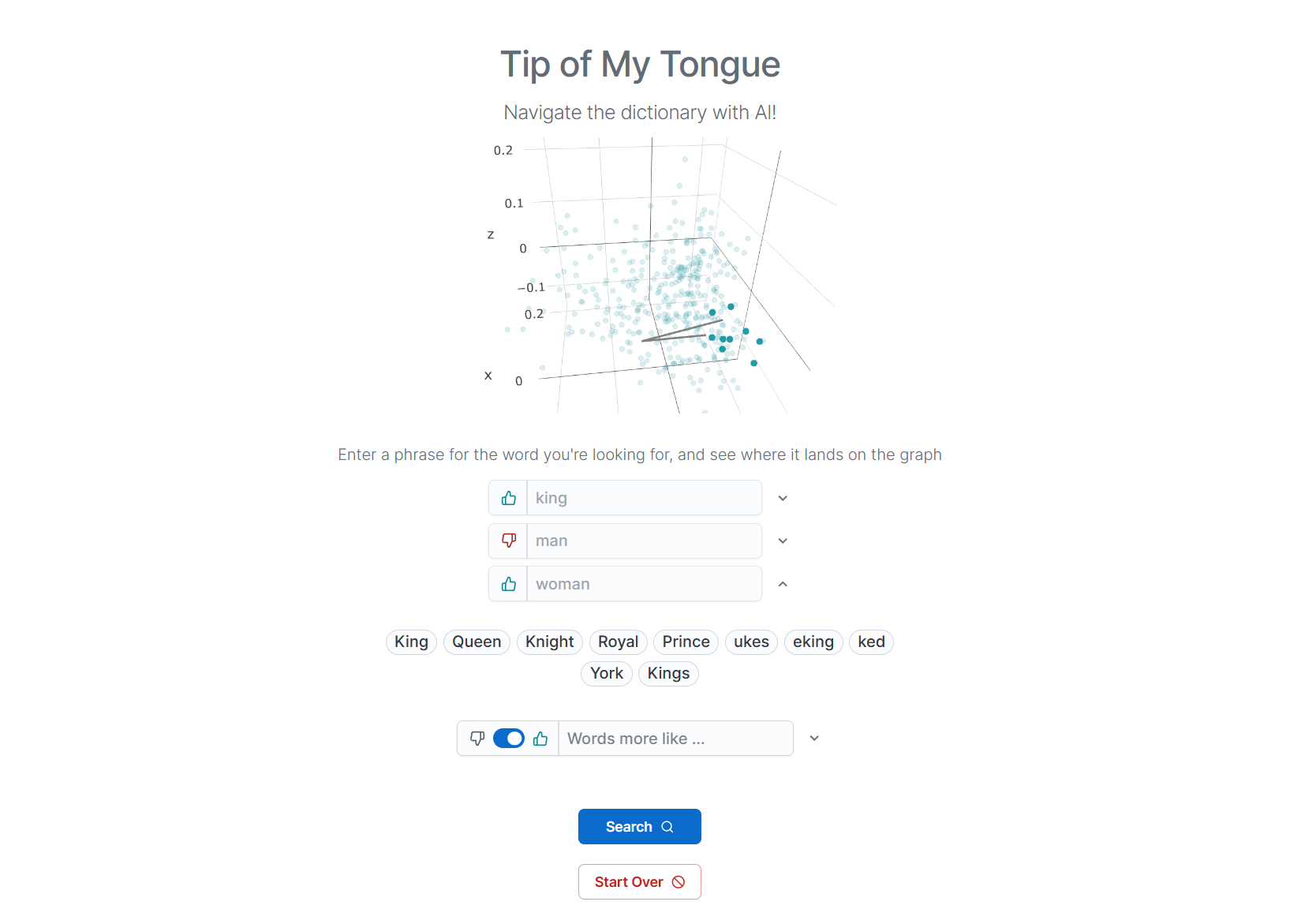
The graph's initial state plots a subset of the reference dictionary as word embeddings. These embeddings are reduced from 1536 dimensions to 3D for visual rendering (see Dimension Reduction for details).
Once the user inputs the first query, words with similar semantic similarity are added to the plot & listed for the user.
If you'd like to run this project locally, you can follow these steps to get started.
To run the service you will need:
- OpenAI API Key
- Docker + Docker Compose
Follow the directions in the backend's readme to build the following resources:
| Component | Filepath | Description | Build Step | |
|---|---|---|---|---|
| Vocabulary List | res/words.txt |
a list of words to query against | Step #1 | |
| Embedding Cache | res/word_embeddings_cache.npz |
a cache of embeddings for each of the words in vocabulary | Step #3 | |
| PCA Transform Model | res/pca_transform.pkl |
the trained PCA model | Step #5 | |
| PCA Transform Cache | res/pca_transform_weights.npy |
a cache of precomputed 3D transforms of the embeddings in the Embedding Cache | Step #5 |
At this point, you should be able to launch the service using Docker.
# Make sure you've configured the
# OPENAI_API_KEY in docker-compose.yml
$ docker compose upIn order to find words similar to the user's query, the query vector is compared against a pre-computed database of embeddings for all known words in the server's dictionary. As text embeddings encode the semantic relationships of words into embeddings, similarities between two pieces of text correspond to similarities in their respective embedding vectors.
Two separate statistical models are used to identify the best fit for a user's query.
First, a K-nearest-neighbor algorithm is applied to find the local neighbors of the query vector using a simple Euclidian distance function. As the initial database used contained a staggering 436,000 English words, this step reduces the search space for the next step.
To further refine the results, a Support Vector Machine (SVM) is trained on the fly to bisect the remaining vectors into two groups - those similar to the query vector & and those which are not. This step is helpful, as it helps identify the vectors which are most similar to the query vector in ways that are unique to the query itself.
Both of these strategies are outlined in Karpathy's quick comparison here. This solution stacks both strategies on top of each other, using KNN as a coarse search, and the SVM to identify a best match.
At scale, searching over a large number of embeddings can warrant the need for an efficient vector database like Faiss or Pinecone. In this case, the quantity of embeddings was small enough that a simple Numpy array was sufficient (though this is starting to push the limit).
To enable combining & refining the user's inputs into a final query vector, each input's embedding updates the query using simple vector math. The logic behind this attempts to replicate the simplicity of popular examples used as an introduction to word embeddings:
King - Man + Woman = Queen
In order to model this, queries are processed as an sequence of individual embedding Operations. Each operation consists of an input text & mathematical transform. Query vectors are calculated by applying each operation's transform to a running value that is carried over from the result of the previous operation. After each iteration, the result is normalized to eliminate the compounding effect on the magnitude of the vector (while preserving the vector's direction).
As embeddings from OpenAI's model (text-embedding-ada-002) are of dimensions (1536,1), they cannot be plotted directly to a 3D space. In order to visualize these embeddings, a transform must be applied to reduce the dimensionality of the vectors from 1536 to 3D. For this application, Principal Component Analyis (PCA) is used to train a model that projects the embeddings onto a lower dimension. While this operation is lossy, relationships between vectors are preserved in the resultant 3D vectors.
The Operation is the core data model of this service. An Operation represents a single mathematical operator that uses the result of the previous operation
An Operation is comprised of two inputs, description & function (also referred to as an Action in some parts of the code due to sloppy naming). The final attribute, results, is a response variable returned by the server, corresponding to a list of similar words returned by the query logic
type WordOperation = {
function: "start" | "more_like" | "less_like",
description: string,
results?: WordPrediction[],
}Description - The description is the new user input to be embedded & used to build the query.
Function - The function specifies the mathematical transform to apply to at this step in building a query
As the backend is entirely stateless, every API request must contain all of the information needed to compute a response in isolation. As such, a sequence of Operations are submitted to API requests as a list.
The WordPrediction is the response format of the query logic. Each word prediction consists of a result word, and a corresponding similarity score dist.
type WordPrediction {
word: string;
dist: number
};The /operations endpoint performs the core lookup functionality for the service. Given a list of semantic operations, a list of words similar to the resultant query is returned.
- Request Body:
Operator[] - Response Body:
Operator[]
For simplicity, the request & response share the same format. The list of Operators is modified to populate the results attribute as part of this operation.
Note: Despite being a POST request, this operation is idempotent
{
"search_vectors": search_vectors,
"result_vectors": result_vectors,
}Note - this was intended to be a "weekend project" & as such, many shortcuts were taken. Here's a quick list of awful code-smells that I'd like to fix, but probably won't.
- The APIs were defined incredibly lazily & have many issues
- Defined paramaters as part of the data model that were never used
id,selected_words, etc - Used the incorrect HTTP verbs (neither API is writable API). Both should be
GETrequests, but I didn't want to give up using the HTTPbody - Used the same data model for input & output of the
/operationsAPI
- Defined paramaters as part of the data model that were never used