
The wrens are mostly small, brownish passerine birds in the mainly New World family Troglodytidae. ... Most wrens are small and rather inconspicuous, except for their loud and often complex songs. - Wikipedia
PyWren -- it's like a mini condor, in the cloud, for often-complex calls. You can get up to 25 TFLOPS peak from AWS Lambda:
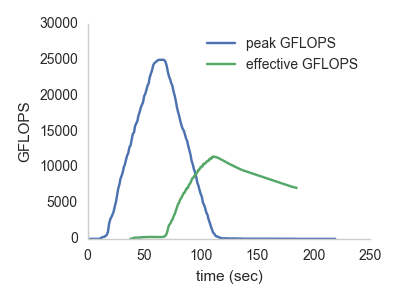
For more information see this blog post, Microservices and teraflops
Goal: Dispatch of small efficient tasks with as close to zero user overhead as possible. In particular, entirely serverless -- use as many AWS services as necessary.
def foo(b):
x = np.random.normal(0, b, 1024)
A = np.random.normal(0, b, (1024, 124))
return np.dot(A, x)
pwex = pywren.default_executor()
res = pwex.map(foo, np.linspace(0.1, 100, 1000)- AWS Lambda for containerized, stateless compute
- s3 for event coordination
- Conda for up-to-date python packages
- cloudpickle for shipping functions back and forth
We're trying to mimic the python 3.x futures interface as much as makes sense
http://pythonhosted.org/futures/
NOTE: The interfaces are close but not identical, because DISTRIBUTED COMPUTATION IS HARD. The cloud is stormy!
- low limit of simultaneous workers (maybe 2k if you reserve ahead)
- finite amount of time per worker (300 seconds)
- possibly slow deploy process
- high latency if cold process
- challenges in supporting entire python / anaconda stack
- At the moment, you're using my gzipped environment from my bucket. That could be compromised, or I could be mailicious, and then I'd have access to parts of your aws account
- Even if your account was locked down, you are then unpickling code returned by this remote process
First, make sure you have boto set up to use your AWS credentials and have a sane python installation (I recommend Anaconda. Clone the repo from git and invoke:
python setup.py install
Before you get started, make sure you have your AWS credentials set up properly for use via Boto. You also need a s3 bucket that you can write to to save data and retrieve results.
Run the following from the prompt:
pywren create_config --bucket_name YOUR_S3_BUCKET_NAME
pywren create_role
pywren deploy_lambda
- This will create a default configuration file and place it in
~/.pywren_config. - Create the default IAM role to run the lambda process as
pywren_exec_role - Deploy the lambda function to AWS using your account as
pywren1. - Place all intermediate data in
$YOUR_S3_BUCKET_NAME/pywren.jobs.
You should now be able to run examples/simpletest.py. You should see the following:
# python examples/simpletest.py
# Linux ip-10-13-24-185 4.4.19-29.55.amzn1.x86_64 #1 SMP Mon Aug 29 23:29:40 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
pip install --editable ./
Pywren will print logging info to console by setting the environment varible as follows:
PYWREN_LOGLEVEL=INFO
I think we're following this guy's advice for logging: https://fangpenlin.com/posts/2012/08/26/good-logging-practice-in-python/
When logging and storing metadata, try and differentiate between:
host (things that occur on user computer) and other time (how long something took, sec) and timestamp (unix timestamp)
Logging: