This repository contains the code to deploy the infrastructure needed to deploy and manage timeoff-management application in AWS.
The application is deployed on a docker swarm cluster on AWS. Swarm was selected because of its simple installation and the ease of use and administration. The cloud infrastructure is deployed using Infrastructure as Code with terraform. For cloud provisioning Ansible was used, and drone.io CI/CD was selected for the application deployment.
All of the code is stored in the following github repositories:
Application and deploy files:
Terraform and ansible code:
- timeoff cluster (this repo)
The swarm cluster uses a single manager node with multiple workers that handle the cluster workload. All cluster nodes are deployed on different Availability Zones to increase availability. The EFS filesystem is multi AZ and it's available on all nodes. The decision to use a single manager node was to simplify the deployment and concentrate on the display of skills on the technologies asked by the challenge. The last section deals with improvements that could be applied to this architecture to improve it in many aspects.
When the infrastructure is up, the application and additional services are available at the following adresses:
- Timeoff management application: https://timeoff.juanbaptiste.tech/
- Drone.io CI/CD: https://drone.juanbaptiste.tech/
- Traefik dashboard: https://traefik.juanbaptiste.tech/
- Portainer dashboard: https://portainer.juanbaptiste.tech/
The following diagram depicts the selected architecture:
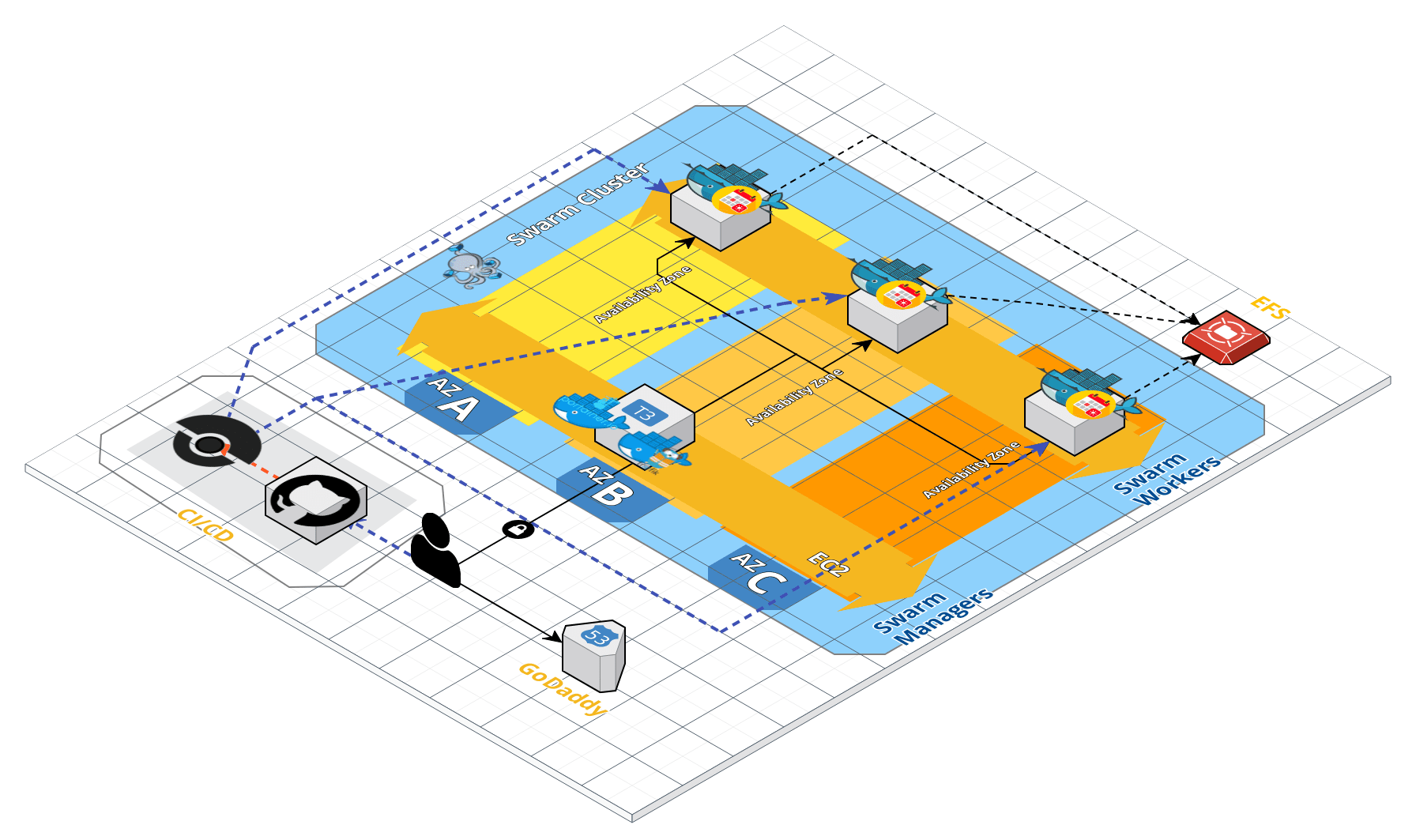
Each of the components of this architecture are described in more detail bellow.
Terraform was selected to do the cloud provisioning in AWS. The terraform code is separated in three projects:
- elastic_ips: this project will create an specified amount of elastic IP addresses to be associated with the managers of the swarm cluster.
- swarm_cluster: this project will create a docker swarm cluster with an specified amount of manager and worker, and from an specified size (instance type) each.
- efs: this project will create a shared EFS filesystem inside the cluster's VPC were the application code will reside and be shared among all the worker nodes of the cluster.
All of the projects use custom terraform modules (also developed by myself and published as open source) to do the work, and their state files are stored in s3. For the documentation of module usage see its README.md file of each project. Projects must be launched in the same order as the preious list, first create the elastic IP addresses, then the cluster and lastly the EFS filesystem.
The Cluster provisioning is done using ansible. A set of playbooks and roles were written to handle provisioning tasks that range from basic instance configuration to cluster installation.
For load balancing and access to the applications deployed in the cluster traefik was selected. This proxy/load balancer is deployed on the manager node(s) of the cluster and will balance the access to the deployed applications by a set of criteria configured using docker labels written on the stack.yml file of the application. The criteria can be by hostname, path or a combination of both. Additionally traefik is configured to secure the applications using SSL with Letsencrypt. Traefik will take charge of the SSL certificate generation and update for each deployed application.
For cluster administration and debugging portainer was selected. This tool provides easy access to the containers running on the cluster, were tasks like reviewing of logs, console access or basic stats monitoring can be accessed. It also allows to do administrative tasks like manually redeployment of services or increasing the amount of conatiner replicas.
These are the ansible playbooks:
- deploy.yml: Main playbook that include the bellow playbooks to do all the provisioning
- deploy_swarm.yml: This playbook will provision the ec2 instances, installing all the needed software and configuring the swarm cluster.
- configure_efs.yml: This playbook will configure each ec2 instance to mount the EFS filesystem at boot.
- deploy_infra.yml: This playook will install the cluster infrastructure services, like traefik and portainer.
- provision_apps.yml: This playbook will copy the application configuration files into a directory in the EFS filesystem.
Playbooks can be run individually using tags.
The docker image generation and application deployment in the cluster is done with drone.io. drone.io is an open source CI/CD platform that was written with the cloud in mind and it's very easy to use. Each application will have a .drone.yml file with the CI/CD pipeline that needs to be executed when updates to the application are pushed to the application's git repository.
The application pipeline contains two jobs:
- Build docker image: This job will create a new docker image with the updated application code and push it to docker hub pubblic registry.
- Deploy docker image: This job will pull the new image from docker hub and redeploy the application. This job tasks run on the cluster manager node (all cluster administrative task are executed on manager nodes).
The pipeline workflow is like this:
- The developer commits and push a code update to the timeoff management application fork that will trigger the drone.io pipeline.
- image build job will clone the timeoff management application fork, build the image and push it to docker hub using a native drone plugin.
- If the previous job is successfull the de deployment job will connect vía ssh and run the
deploy.shscript. This script will pull the new image, remove the current deployed version of the application and redeploy the new version.
The application is dpeloyed on the cluster with multiple replicas that run on different worker nodes to increase the application availability. Also hardware resources like the amount of memory or CPU's it can use can be controlled through the stack.yml file. This is used by the orchestrator to choose a node with enough resources to run the application.
Access to the application is done through a load balancer (traefik). The configuration is done using docker labels that define the hostname the application answers to and the port it listens on. Other options can be specified, like doing redirects, cookie handling, among others. Also health checks can also be configured so the load balancer can query the state of the container, and avoid sending traffic to it if it is not available.
The selected architecture has some limitations mostly related to the orchestrator in use. Here is a list of what could be done to improve some aspects without switching orchestrators:
By using a single manager node, the cluster has a single point of failure that can risk the applcation availability. This can be improved by increasing the managers amount to a higher odd number like 3, 5, 7 or more (this is to maintain the raft consensus in the cluster). But increasing the amount of managers brings a new issue: the load balancing of the manager nodes.
If the manager nodes amount is increased then some sort of load balancing needs to be implemented. One option and the easiest to implement would be to do DNS round-robbin balancing. This is a really simple method to implement, but lacks advanced features that can produce better results, like resource based, least connections, etc. This load balancing methods can be achieved by using specialized solutions.
The second option would be to use one of those solutions, for this case a cloud based offering like the AWS application or network load balancers would make more sense. The load balancer would be placed in front of the manager nodes so it can balance traffic between the local traefik on each node, using a health check to be notified when one of the nodes in the group becomes unavailable. When this happens the load balancer will stop sending traffic to the node until the health check reports that it is again available.
One important feature that docker swarm clusters lack is auto escalability. This does not mean that it cannot be achieved by other means, but there are other orchestrating solutions like k8 or AWS ECS that can can do it "out of the box". On this case an auto escalating solution could be implemented with some scripting and a monitoring tool like Zabbix.
With the current architecture the escalablity can be manually achieved. An admin can increase the amount of workers nodes in terraform and then apply the changes. When it finishes the ansible playbooks will be run to add the new node(s) to the cluster. The last step would be to increase the amount of container replicas in the application stack.ymlfile commit and push changes so the CI/CD platform can redeploy it.
To improve this situation, monitoring alerts could be configured to monitor specific health metrics over a period of time. When these alerts are triggered, a program could be executed to scale out and and later scale back when conditions return to a expected state. An example of such a metric could be to monitor the average CPU usage of all worker nodes during an specified amount of time. When the CPU usage goes beyond a certain threshold, the alert will trigger and will execute a program to scale out the cluster. Later when that condition reverts another program could be executed to scale back in the cluster and destroy the additional resources that were created to handle the additional load.
The scaling programs could follow a set of instructions roughly like these:
- Clone the git repo were the terraform and ansible code lives.
- Increase the amount of workers by an specified step size (ej. 1).
- Commit and push the changes.
- The CI/CD platform will launch a pipeline that will excute the terraform code and the ansible provisioning playbooks to add the new node(s) to the cluster and give them access to the EFS filesystem.
- Clone the git repo were the application code lives.
- Modify the
stack.ymlfile to increase the amount of container replicas by the same step size as the nodes. - Commit and push the changes. This will trigger an application redeployment and more containers will be created on all the available nodes.
After this the cluster will have an increased capcity that should help it manage the additional load. When the CPU usage goes bellow the threshold another program could be launched to do the inverse steps than the previous program:
- Clone the git repo were the terraform and ansible code lives.
- Decrease the amount of workers by an specified step size (ej. 1) and checking that it always is > 1.
- Commit and push the changes.
- The CI/CD platform will launch a pipeline that will excute
terraform destroy, decreasing the cluster size. - Clone the git repo were the application code lives.
- Modify the
stack.ymlfile to decrease the amount of container replicas by the same step size as the nodes and checking that it always is > 1. - Commit and push the changes. This will trigger an application redeployment.
For the monitoring of the cluster nodes two approaches are available. One would be to modify the user_data script in terraform code to install and configure the Zabbix agent so it auto registers with the server inmediately it is created. The second option would be to use an ansible playook to do the same as part of the escaling program steps.
Currently when the CI/CD pipeline is executed, the deploy.sh script will remove and re-deploy the application. Doing this is more risky when application tests are not being done first to guarantee the proper operation of the application's new version. If the there is an issue with the new version it cannot easily be rolled back to the previous version, only by manually pushig the previous version to the git repository so the pipiline redeploys the last working version.
Using swarm rolling updates could be a better approach on this case as it will secuentially update all the apllication containers to the new version, allowing a zero downtime deployment. Also old containers are not deleted, allowing for a rollback operation if needed.
The timeoff application is using the development mode, this means that it uses sqlite as the database platform. On a produtcion mode a more robust database must be used, the application supports MySQL which can be deployed using an AWS RDS insntance. This service comes with many features geared to increase service availability. The service can be configured to have automatic storage scaling, vertical scaling, read replicas replicas and multi AZ deployments. It also has automatic backups using database snapshots.