InfluxDB是当前世界排名第一的时序数据库,具有繁荣的生态系统,目前很多用户使用它来作为自己的第一选择。但是,实际上线后,会有高可用,高扩展的需求。如果换成别的数据库,会有比较高的迁移成本。
开发一套Java版本的适配器可以使IotDB兼容InfluxDB协议,完善IotDB的功能。
- IotDB-InfluxDB:支持InfluxDB写入;支持InfluxDB部分查询;支持完整的InfluxDB查询。
- 对正确性和性能的测试,不仅要适配InfluxDB,也要知道在繁重的负载下是否可以很好的工作,例如:以非常高的频率生成数据
- 正确性测试:通过适配器以influxb的协议插入数据,然后查询IotDB数据库,将我们认为发送的内容与我们希望存储的内容进行比较。进行正确性测试
- 性能测试:以多线程的方式或者以Fiber多协程方式并发写入和读取,进行性能测试,类似的 demo:https://github.com/Tencent/TencentKona-8/tree/KonaFiber/demo/fiber/iotdb-sync-stress-demo
适配器是一个继承至InfluxDB基类的子类,实现了InfluxDB主要的写入和查询方法,用户通过改变代码中InfluxDB的实现类,从而使InfluxDB原有的操作函数没有改变,但是会以IotDB的协议写入IotDB数据库中。

-
问题:InfluxDB中Tag的顺序不敏感,而在IoTDB中是敏感的。
a. InfluxDB的时序构成
i. measurement
ii.tag key tag value
iii. field key field value
b. IotDB的时序构成
i. storage group
ii. path(time series ID)
iii. measurement
-
关键点:需要记录每个tag对应的顺序,确保InfluxDB中label顺序不同的同一条时序对应到IoTDB中也是一条时序
-
需要解决的事情
- 怎样映射tag key和它对应的order
- 在不知道所有的label key的情况下,怎么维护他们之间的顺序
- 内存中Map <Database_Measurement, Map <Tag Key, Order> > table结构维护Tag之间的顺序
- InfluxDB中时序根据label顺序对应到IoTDB
a. 添加时序
- InfluxDB时序(database=testdabase):
(1)student{name=A,phone=B,sex=C}
(2)student{address=D}
(3))student{name=A,phone=B,sex=C,address=D}
-
简单对上述InfluxDB的时序进行解释,database是testdatabase;measurement是student;tag分别是name,phone、sex和address
-
(1)对应的记录tag顺序的table为
| database_measurement | tag_key | order |
| -------------------- | ------- | ----- |
| testdatabase_student | name | 0 |
| testdatabase_student | phone | 1 |
| testdatabase_student | sex | 2 |
(2)对应的记录tag顺序的table为
| database_measurement | tag_key | order |
| -------------------- | ------- | ----- |
| testdatabase_student | name | 0 |
| testdatabase_student | phone | 1 |
| testdatabase_student | sex | 2 |
| testdatabase_student | address | 3 |
(3)对应的记录tag顺序的table为
| database_measurement | tag_key | order |
| -------------------- | ------- | ----- |
| testdatabase_student | name | 0 |
| testdatabase_student | phone | 1 |
| testdatabase_student | sex | 2 |
| testdatabase_student | address | 3 |
-
(1)对应IotDB时序为root._testdatabase_student.A.B.C
(2)对应IotDB时序为root._testdatabase_student.ph.ph.ph.D(�其中ph表示占位符)
(3)对应IotDB时序为root._testdatabase_student.A.B.C.D
-
为了重启时候对table的恢复,在IoTDB中记录数据
root.TAG_INFO.database_nameroot.TAG_INFO.measurement_nameroot.TAG_INFO.tag_nameroot.TAG_INFO.tag_ordertestdatabase student name 0 testdatabase student phone 1 testdatabase student sex 2 testdatabase student address 3
b. 查询数据
1. 查询student中phone=B的数据。在testdatabase_student中phone的顺序为1,order最大值是3,对应到IotDB的查询为:select * from root.testdatabase_student.*.B
2. 查询student中phone=B且存储的socre>97的数据,对应到IotDB的查询为:select * from root.testdatabase_student.*.B where socre>98
3. 查询student中phone=B且存储的socre>97且时间在最近七天内的的数据,对应到IotDB的查询为:select * from root.testdatabase_student.*.B where socre>98 and time > now()-7d
- database
- measurement
- tag key tag value. field key field value
- storage group
- device
- timeseries
我们将上面对应的三点一一对应,举例如下
inlfuxbd的写入语句分别为(默认database=testdata)
- insert cpu,host=serverA,region=us value=0.64(tag为host、region)
- insert cpu,host=serverA,region=us,sex=n value=0.64(tag为host、region、sex)
最终写入情况为:

iotdb的写入数据为
- insert into root.testdata.cpu(timestamp,host,region,value) values(now(),"serverA","us",0.64)
- insert into root.testdata.cpu(timestamp,host,region,sex,value) values(now(),"serverA","us","n",0.64)
最终写入情况为:

我们可以发现,二者实际存储对表面形式也比较类似。
当把influxdb的tag和field都当作timeseries写入数据中时,由于存储的表面形式比较类似,最终查询就比较方便了。
-
根据值查询
select * from root.testdata.cpu where value = 0.64
-
根据tag查询
select * from. root.testdata.cpu where region = "us"
-
根据time查询
select * from root.testdata.cpu where time>now()-7d
-
混合查询
由于把tag和filed都当作timeseries查询,混合查询也同理。
-
group by
influxdb中group by可以按照tag分组展示
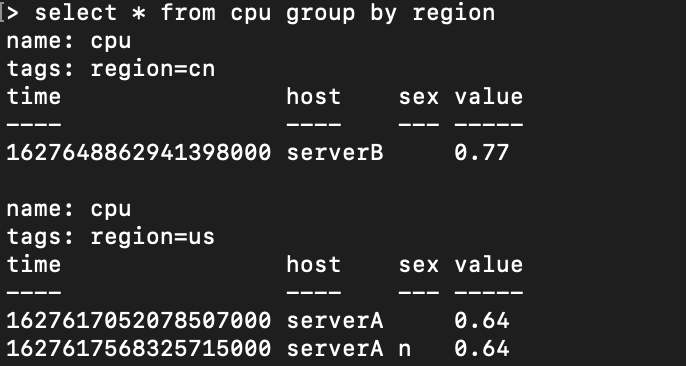
inflxudb中的group by功能不太类似,因此实现方法是:先获取所有的数据,然后在列表中以hash的方式手动分组,理论上复杂度为O(n),复杂度可以接受。

- influxdb的tag和filed均当作iotdb的timeseries

- influxdb的tag当作路径

-
查找条件为select * from root.teststress.test1 where RL = 1 and A = 1 and B =1 and C=1
其中RL是tag,A,B,C均为field
-
取中间值情况,即当有十个tag时,取中间第五个累积递增
SessionDataSet dataSet = session.executeQueryStatement("select * from root.teststress.test2.*.*.*.*.SL where A=1 and B=1 and C=1"); dataSet = session.executeQueryStatement("select * from root.teststress.test2.*.*.*.*.SL.* where A=1 and B=1 and C=1"); dataSet = session.executeQueryStatement("select * from root.teststress.test2.*.*.*.*.SL.*.*.* where A=1 and B=1 and C=1"); dataSet = session.executeQueryStatement("select * from root.teststress.test2.*.*.*.*.SL.*.*.*.* where A=1 and B=1 and C=1"); dataSet = session.executeQueryStatement("select * from root.teststress.test2.*.*.*.*.SL.*.*.*.*.* where A=1 and B=1 ");
-
为了存储的方便,第二种情况的存储,没有把tag的value存入路径中,即直接把tag的key存入路径中。其表现为
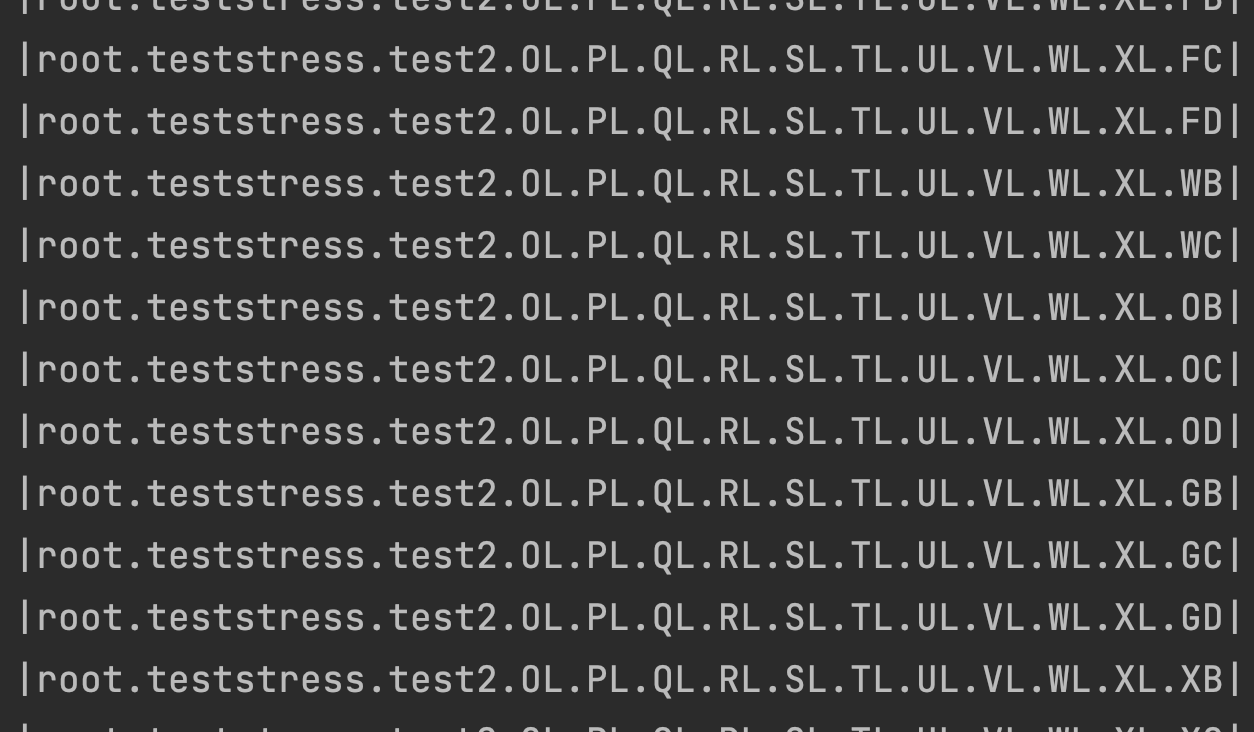
前面累积的path都是相同的,这样最后会导致的结果是:会加快根据path过滤的查找,如:
select * from root.teststress.test2.*.*.*.*.SL.*.*.*.*.*
这时只有一条路径,所有速度会变快,即第二种查找的时间会比实际的快一些

第一种查找的时间平均可以达到1000多ms,第二种查找的时间在300ms附近
同时如果第二种查找的时候,在较靠前的路径使用*,(select * from root.teststress.test2.* where A=1 and B=1 )会导致需要查找的path过多,报错信息如下
Too many paths in one query! Currently allowed max deduplicated path number is 715, this query contains 1000 deduplicated path. Please use slimit to choose what you real want or adjust max_deduplicated_path_num in iotdb-engine.properties.
综上所述,建议采取第二种方案(把tag放在path中存储)(同时需要解决上述提到的问题:Too many paths in one query)。
为了尽可能的降低session查询的次数,应将一些可以合并的过滤条件进行合并,从而减少查询的次数。
同时需要注意的是,由于tag过滤是通过path进行过滤,而filed过滤是通过iotdb的where值过滤,因此二者的or过滤无法合并成一次过滤。即where tag1=value1 or field1=value2这种情况,无法合并成一次过滤。因此下文中尝试解决就是把可以合并的情况进行合并,即将and过滤进行合并。为了减少查询的次数,该算法使用递归的方法,对子树进行判断并尝试合并。
举例如下:
select * from cpu where (host = 'serverA' and regions='us') or (regions = 'us' and value=0.77)InfluxDB语法解析器生成的语法树如下图所示:
 此时我们由两种解决思路:
此时我们由两种解决思路:
- 分别进行四次查询,host=serverA ;regions=us;regions=us和value=0.77四次查询,然后分别按照树的token,即or或者and进行合并。
- 将and的子树进行合并,即查询host=serverA and regions=us ;regions=us and value=0.77.只需要进行两次查询。也就是本文提到的查询优化算法。
当然,如果根节点是and,同时左右子树分别对应的两个操作也是and,那么最终会合并成一次查询。
返回非空字段值的数目。
COUNT(field_key)
返回field key对应的field values的数目。
COUNT(/regular_expression/)
返回匹配正则表达式的field key对应的field values的数目。
COUNT(*)
返回measurement中的每个field key对应的field value的数目。
在已经生成的QueryResult中找到满足条件的column,遍历获取非空字段的数目
返回field value的不同值列表。
DISTINCT(field_key)
返回field key对应的不同field values。
DISTINCT(/regular_expression/)
返回匹配正则表达式的field key对应的不同field values。
DISTINCT(*)
返回measurement中的每个field key对应的不同field value。
DISTINCT()支持所有数据类型的field value,InfluxQL支持COUNT()嵌套DISTINCT()。
在已经生成的QueryResult中找到满足条件的column,遍历获取不同值的列表
返回字段曲线下的面积,即是积分。
InfluxDB计算字段曲线下的面积,并将这些结果转换为每unit的总和面积。unit参数是一个整数,后跟一个时间字符串,它是可选的。如果查询未指定单位,则单位默认为1秒(1s)。
INTEGRAL(field_key)
返回field key关联的值之下的面积。
INTEGRAL(/regular_expression/)
返回满足正则表达式的每个field key关联的值之下的面积。
INTEGRAL(*)
返回measurement中每个field key关联的值之下的面积。
INTEGRAL()不支持fill(),INTEGRAL()支持int64和float64两个数据类型。
返回字段的平均值
MEAN(field_key)
返回field key关联的值的平均值。
MEAN(/regular_expression/)
返回满足正则表达式的每个field key关联的值的平均值。
MEAN(*)
返回measurement中每个field key关联的值的平均值。
MEAN()支持int64和float64两个数据类型。
在已经生成的QueryResult中找到满足条件的column,遍历求和然后求其平均值
在已经生成的QueryResult中找到满足条件的column,遍历获取不同值的列表
MEDIAN(field_key)
返回field key关联的值的中位数。
MEDIAN(/regular_expression/)
返回满足正则表达式的每个field key关联的值的中位数。
MEDIAN(*)
返回measurement中每个field key关联的值的中位数。
MEDIAN()支持int64和float64两个数据类型。
注意:
MEDIAN()近似于PERCENTILE(field_key,50),除了如果该字段包含偶数个值,MEDIAN()返回两个中间字段值的平均值之外。
在已经生成的QueryResult中找到满足条件的column,排序找到其中位数
返回字段中出现频率最高的值。
MODE(field_key)
返回field key关联的值的出现频率最高的值。
MODE(/regular_expression/)
返回满足正则表达式的每个field key关联的值的出现频率最高的值。
MODE(*)
返回measurement中每个field key关联的值的出现频率最高的值。
MODE()支持所有数据类型。
注意:
MODE()如果最多出现次数有两个或多个值,则返回具有最早时间戳的字段值。
在已经生成的QueryResult中找到满足条件的column,找到其出现频率最高的值,如果有出现多个,那么取最早时间戳的字段值。
返回字段中最大和最小值的差值。
SPREAD(field_key)
返回field key最大和最小值的差值。
SPREAD(/regular_expression/)
返回满足正则表达式的每个field key最大和最小值的差值。
SPREAD(*)
返回measurement中每个field key最大和最小值的差值。
SPREAD()支持所有的数值类型的field。
在已经生成的QueryResult中找到满足条件的column,找到其最大和最小的差值。
返回字段的标准差。
STDDEV(field_key)
返回field key的标准差。
STDDEV(/regular_expression/)
返回满足正则表达式的每个field key的标准差。
STDDEV(*)
返回measurement中每个field key的标准差。
STDDEV()支持所有的数值类型的field。
在已经生成的QueryResult中找到满足条件的column,计算其标准差。
返回字段值的和。
SUM(field_key)
返回field key的值的和。
SUM(/regular_expression/)
返回满足正则表达式的每个field key的值的和。
SUM(*)
返回measurement中每个field key的值的和。
SUM()支持所有的数值类型的field。
在已经生成的QueryResult中找到满足条件的column,计算其和。
返回最小的N个field值。
BOTTOM(field_key,N)
返回field key的最小的N个field value。
BOTTOM(field_key,tag_key(s),N)
返回某个tag key的N个tag value的最小的field value。
BOTTOM(field_key,N),tag_key(s),field_key(s)
返回括号里的字段的最小N个field value,以及相关的tag或field,或者两者都有。
BOTTOM()支持所有的数值类型的field。
说明:
- 如果一个field有两个或多个相等的field value,
BOTTOM()返回时间戳最早的那个。BOTTOM()和INTO子句一起使用的时候,和其他的函数有些不一样。
在已经生成的QueryResult中找到满足条件的column,遍历找到其最小的N个值
返回时间戳最早的值
FIRST(field_key)
返回field key时间戳最早的值。
FIRST(/regular_expression/)
返回满足正则表达式的每个field key的时间戳最早的值。
FIRST(*)
返回measurement中每个field key的时间戳最早的值。
FIRST(field_key),tag_key(s),field_key(s)
返回括号里的字段的时间戳最早的值,以及相关联的tag或field,或者两者都有。
FIRST()支持所有类型的field。
在已经生成的QueryResult中找到满足条件的column,找到其时间戳最早的值
返回时间戳最近的值
LAST(field_key)
返回field key时间戳最近的值。
LAST(/regular_expression/)
返回满足正则表达式的每个field key的时间戳最近的值。
LAST(*)
返回measurement中每个field key的时间戳最近的值。
LAST(field_key),tag_key(s),field_key(s)
返回括号里的字段的时间戳最近的值,以及相关联的tag或field,或者两者都有。
LAST()支持所有类型的field。
在已经生成的QueryResult中找到满足条件的column,找到其时间戳最近的值
返回最大的字段值
MAX(field_key)
返回field key的最大值。
MAX(/regular_expression/)
返回满足正则表达式的每个field key的最大值。
MAX(*)
返回measurement中每个field key的最大值。
MAX(field_key),tag_key(s),field_key(s)
返回括号里的字段的最大值,以及相关联的tag或field,或者两者都有。
MAX()支持所有数值类型的field。
在已经生成的QueryResult中找到满足条件的column,找到其最大的值
返回最小的字段值
MIN(field_key)
返回field key的最小值。
MIN(/regular_expression/)
返回满足正则表达式的每个field key的最小值。
MIN(*)
返回measurement中每个field key的最小值。
MIN(field_key),tag_key(s),field_key(s)
返回括号里的字段的最小值,以及相关联的tag或field,或者两者都有。
MIN()支持所有数值类型的field。
在已经生成的QueryResult中找到满足条件的column,找到其最小的值。
返回较大百分之N的字段值
PERCENTILE(field_key,N)
返回field key较大的百分之N的值。
PERCENTILE(/regular_expression/,N)
返回满足正则表达式的每个field key较大的百分之N的值。
PERCENTILE(*,N)
返回measurement中每个field key较大的百分之N的值。
PERCENTILE(field_key,N),tag_key(s),field_key(s)
返回括号里的字段较大的百分之N的值,以及相关联的tag或field,或者两者都有。
N必须是0到100的整数或者浮点数。
PERCENTILE()支持所有数值类型的field。
返回N个随机抽样的字段值。SAMPLE()使用reservoir sampling来生成随机点。
SAMPLE(field_key,N)
返回field key的N个随机抽样的字段值。
SAMPLE(/regular_expression/,N)
返回满足正则表达式的每个field key的N个随机抽样的字段值。
SAMPLE(*,N)
返回measurement中每个field key的N个随机抽样的字段值。
SAMPLE(field_key,N),tag_key(s),field_key(s)
返回括号里的字段的N个随机抽样的字段值,以及相关联的tag或field,或者两者都有。
N必须是整数。
SAMPLE()支持所有类型的field。
返回最大的N个field值。
TOP(field_key,N)
返回field key的最大的N个field value。
TOP(field_key,tag_key(s),N)
返回某个tag key的N个tag value的最大的field value。
TOP(field_key,N),tag_key(s),field_key(s)
返回括号里的字段的最大N个field value,以及相关的tag或field,或者两者都有。
TOP()支持所有的数值类型的field。
说明:
- 如果一个field有两个或多个相等的field value,
TOP()返回时间戳最早的那个。TOP()和INTO子句一起使用的时候,和其他的函数有些不一样。
在已经生成的QueryResult中找到满足条件的column,遍历找到其最大的N个值