- Cheah Jun Yitt (WQD180107)
- Tan Yin Yen (WQD180108)
- Objective & Acquisition of Data > Management of Data > Processing of Data > Interpretation of Data > Communication of Insights > Recommendations
- To come out with a model to predict the rating of the latest movie with DVD or streaming options available based on its box office performance and user reviews.
- To recommend user the top and latest movies with DVD or streaming options available based on the predicted rating.
Scope: Scrape data of latest 250 movies with DVD or streaming options available.
- Web Scraping (Part 1): Scrape movie information and user reviews from rottentomatoes.com
- Web Scraping (Part 2): Scrape box office data from boxofficemojo.com
- Movie information (rottentomatoes.com): Director, Genre, In Theater Date, On Streaming Date, Rating, Runtime, Studio, Writer, Audience Score, Critics Consensus, Title, Tomatometer, Tomatometer Count, URL, User Rating Count
- Movie Reviews (rottentomatoes.com): Reviews (short paragraph), URL (act as foreign key)
- Movie Box Office Data (boxofficemojo.com): In Release (total days), Widest Release (number of theaters), Domestic Gross, Foreign Gross, Opening Weekend Gross, Opening Statistics, Movie Title (foreign key), Total Gross
- Java
- Hadoop
- Apache derby
- Hive
Refer to: https://github.com/junyitt/DataMiningProject/blob/master/DataManagement/PreMilestone2.md
- Movie information (rottentomatoes.com) - hive_movie_info_semisep.csv
- Movie Reviews (rottentomatoes.com) - hive_movie_reviews_semisep.csv
- Movie Box Office Data (boxofficemojo.com) - hive_movie_box_office_semisep.csv
- Store the 3 CSV to Hive - Refer to: https://github.com/junyitt/DataMiningProject/blob/master/DataManagement/CreateHiveTables.md
- Clean and Extract Features from Rotten Tomatoes Movie Info Data (rottentomatoes.com)
- Clean and Extract Features from Box Office Data (boxofficemojo.com)
- Sentiment Analysis on Rotten Tomatoes Review Data
- Assigning a sentiment score, and aggregating the sentiment score for each movie
- Analysis Goal
- A movie streaming company (Netflix) seeks to maximize customer's retention by recommending highly rated movies with DVD or streaming options available to their users.
- Use sentiment score of user reviews on a movie, movie information and box office data to predict the user ratings of a movie.
Implications:
- By predicting the user ratings of a movie based on its reviews and box office achievement, the movie streaming company can filter out latest movies with DVD or streaming options available that are highly rated and recommend them to its users.
- Customers who are satisfied with the movie recommendations are more likely to subscribe to the movie streaming service in the next month.
- Analysis Data
- Movie information and movie reviews data were scraped from rottentomatoes.com. Movie box office data were scraped from boxofficemojo.com
- The binary target variable (audience score indicator) is balance, i.e. 50% good and 50% bad.
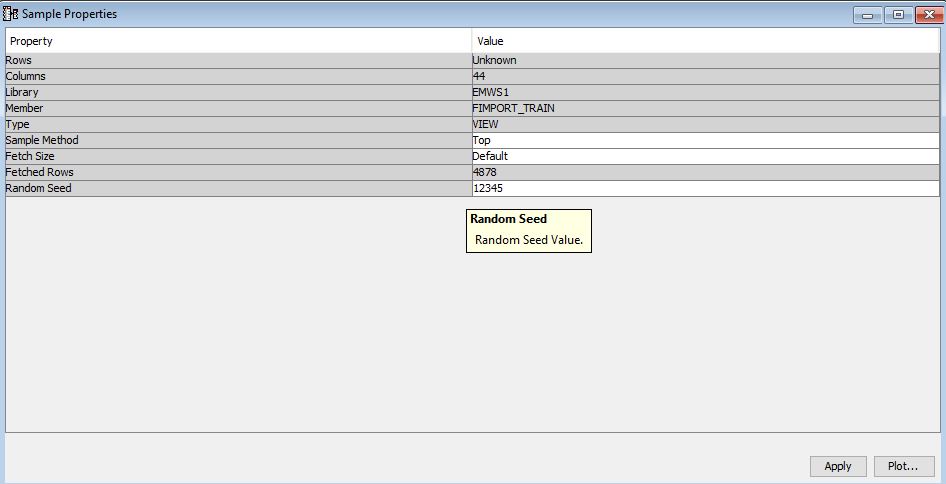
- Table properties
 [File Import, Graph Explore]
[File Import, Graph Explore]
- 4878 rows
- 44 columns
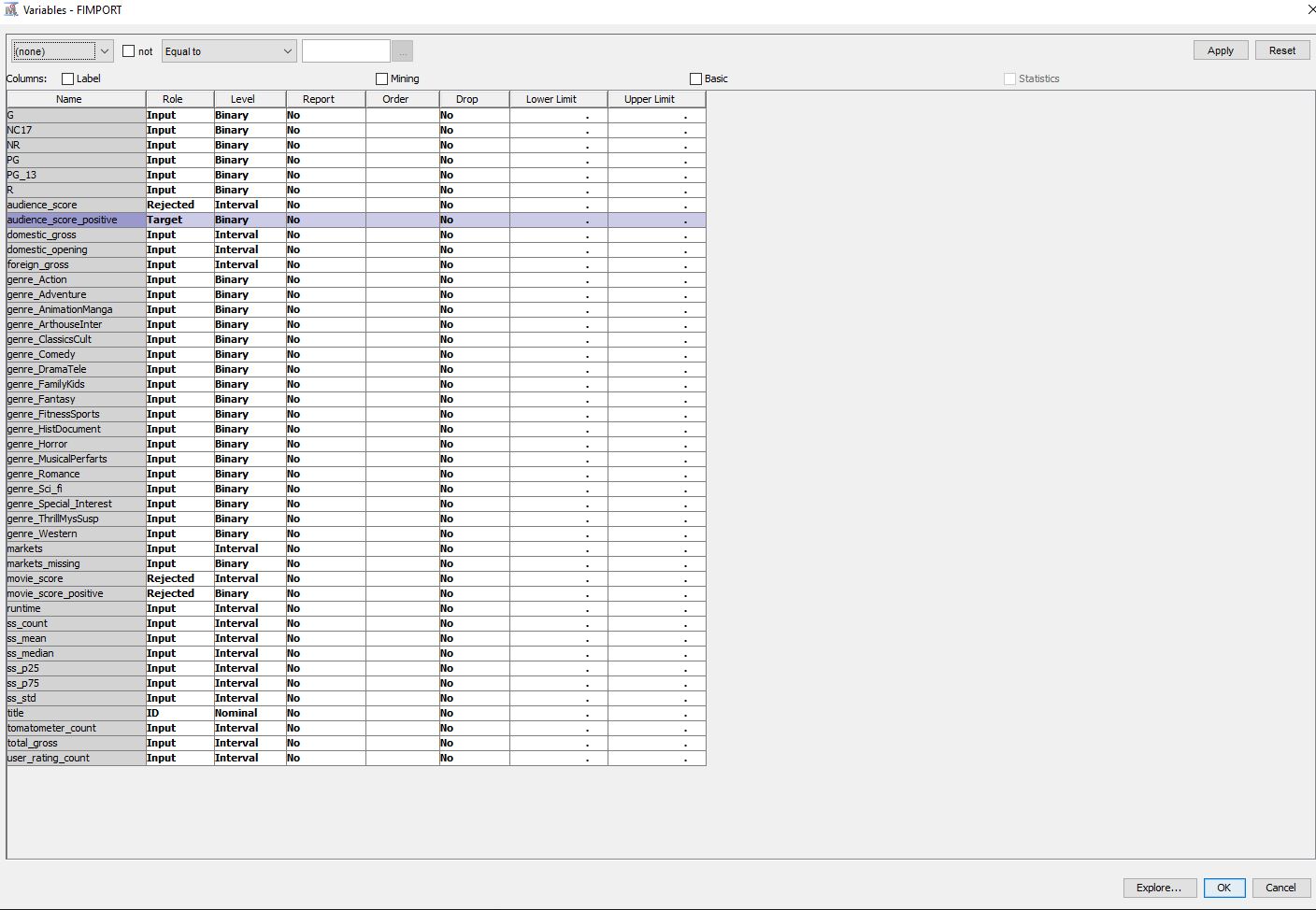
- Column Metadata
 [File Import > Explore]
[File Import > Explore]
- MPAA Film Rating (Binary) (G, NC17,...,R)
- audience_score, audience_score_positive, movie_score, movie_score_positive are the target variables. Currently, we are interested in the audience_score_positive binary target. (Reject the rest)
- The 11 genre clusters are binary values.
- The sentiment, box office values, and number of ratings are all interval values.
- The title (movie title, nominal data) is set as the ID, and should not be used in the analysis.
- Diagram (SEM)
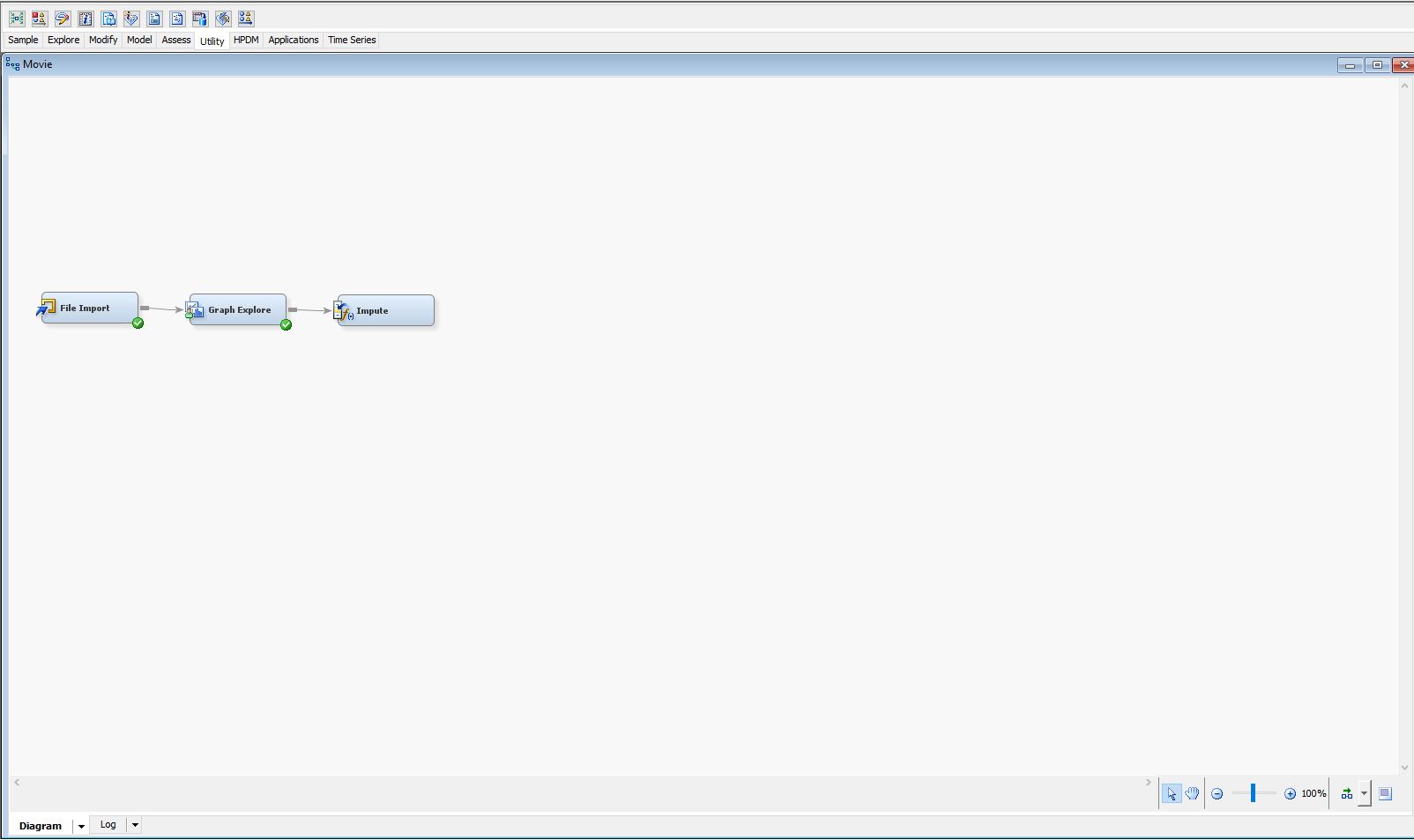
- Sample - File Import
- Explore - Graph Explore and File Import > Explore
- Modify - Impute
- Explore Data Source - First View
- Histogram (File Import > Explore)
- Identify missing data
- Cleansing of Data
- Show missing value in bin
- Impute the missing value
- Pie Chart of Target Variable


- Shows approximately 50% True (good movie) and 50% False (bad movie).
- Split the data into 50% training set and 50% validation set for modelling
- Information gain: Selecting attribute with high information gain is preferred.
- Interpretability: Selecting attribute with a slightly lower information gain but can be easily understood and explained is preferred.
- Diversity: Using attributes from various sources is preferred (as established in previous milestones), hence it is preferred to split the nodes with consideration of attributes from movie information, movie reviews (sentiment score) and movie box office performance.
- Determine how many leaves are sufficient to build a decision tree model that have a low misclassification rate, easily interepreted and understood for decision making.
Refer to Milestone 5 report:
https://github.com/junyitt/DataMiningProject/blob/master/Milestone5_InsightsCommunication/Report_Milestone5.pdf
Refer to the final report.