This repository extends and adds to the original training repo for Stable Diffusion. Be careful using this repo, it's by personal Stable Diffusion playground and backwards compatibility breaking changes might happen anytime. So use at your own risk. I recommend sticking to a particular git commit if you are depending on some functionality.
Currently it adds:
- Image Mixer
- Super Resolution
- Imagic
- Fine tuning
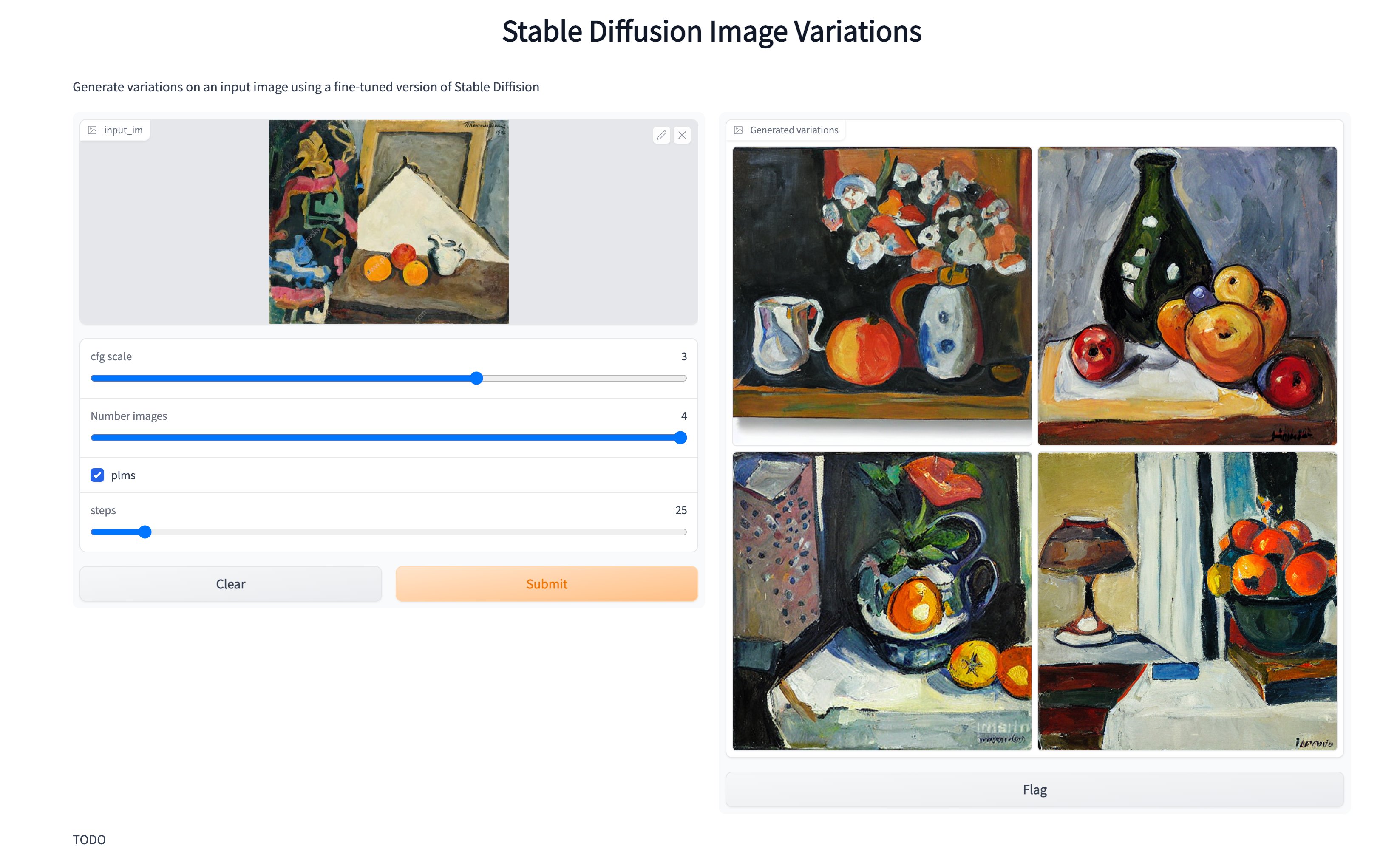
- Image variations
- Conversion to Huggingface Diffusers

The model is available on huggingface spaces or to run locally do the following:
git clone https://github.com/justinpinkney/stable-diffusion.git
cd stable-diffusion
git checkout 1c8a598f312e54f614d1b9675db0e66382f7e23c
python -m venv .venv --prompt sd
. .venv/bin/activate
pip install -U pip
pip install -r requirements.txt
python scripts/gradio_image_mixer.pyThen navigate to the gradio demo link printed in the terminal.
For details on how to use the model outside the app refer to the run function in gradio_image_mixer.py
I fine tuned a version of Stable Diffusion 1.4 for the task of super-resolution, you can find the trained model on huggingface hub and can run a gradio demo as follows:
git clone https://github.com/justinpinkney/stable-diffusion.git
cd stable-diffusion
python -m venv .venv --prompt sd
. .venv/bin/activate
pip install -U pip
pip install -r requirements.txt
python scripts/gradio_superres.pyNote since I trained this model there is now an 'official' super res model for Stable Diffusion 2 which you might prefer to use.
Makes it easy to fine tune Stable Diffusion on your own dataset. For example generating new Pokemon from text!

Girl with a pearl earring, Cute Obama creature, Donald Trump, Boris Johnson, Totoro, Hello Kitty
For a step by step guide see the Lambda Labs examples repo.

For more details on the Image Variation model see the model card.
- Get access to a Linux machine with a decent NVIDIA GPU (e.g. on Lambda GPU Cloud)
- Clone this repo
- Make sure PyTorch is installed and then install other requirements:
pip install -r requirements.txt - Get model from huggingface hub lambdalabs/stable-diffusion-image-conditioned
- Put model in
models/ldm/stable-diffusion-v1/sd-clip-vit-l14-img-embed_ema_only.ckpt - Run
scripts/image_variations.pyorscripts/gradio_variations.py
All together:
git clone https://github.com/justinpinkney/stable-diffusion.git
cd stable-diffusion
mkdir -p models/ldm/stable-diffusion-v1
wget https://huggingface.co/lambdalabs/stable-diffusion-image-conditioned/resolve/main/sd-clip-vit-l14-img-embed_ema_only.ckpt -O models/ldm/stable-diffusion-v1/sd-clip-vit-l14-img-embed_ema_only.ckpt
pip install -r requirements.txt
python scripts/gradio_variations.py
Then you should see this:
Trained by Justin Pinkney (@Buntworthy) at Lambda