Table of Contents
- Intro to Machine Learning with TensorFlow Nanodegree Program
-
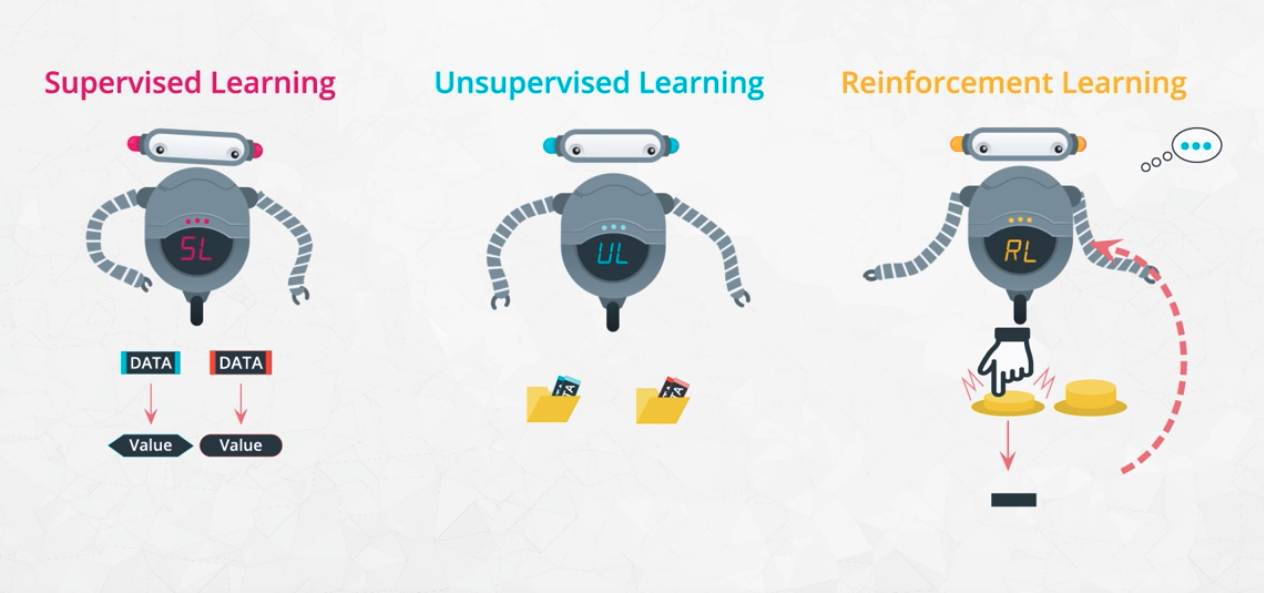
Learning from labelled data
-
Supervised learning can be divided in two models
-
Classification
- Categorical Outcomes
- Any number of categories
- Type of Dog
- In statistics, the logistic model (or logit model) is used to model the probability of a certain class or event existing such as pass/fail, win/lose, alive/dead or healthy/sick. This can be extended to model several classes of events such as determining whether an image contains a cat, dog, lion, etc. Each object being detected in the image would be assigned a probability between 0 and 1 and the sum adding to one.farea_under_curve
-
Regression
- Numeric Outcomes
- A persons height for example
-
-
Unsupervised Learning
- No labelled data
- Grouping similar items
-
Reinforcement Learning
- Training algorithms that take rewards based on actions
- Game playing agents
-

-
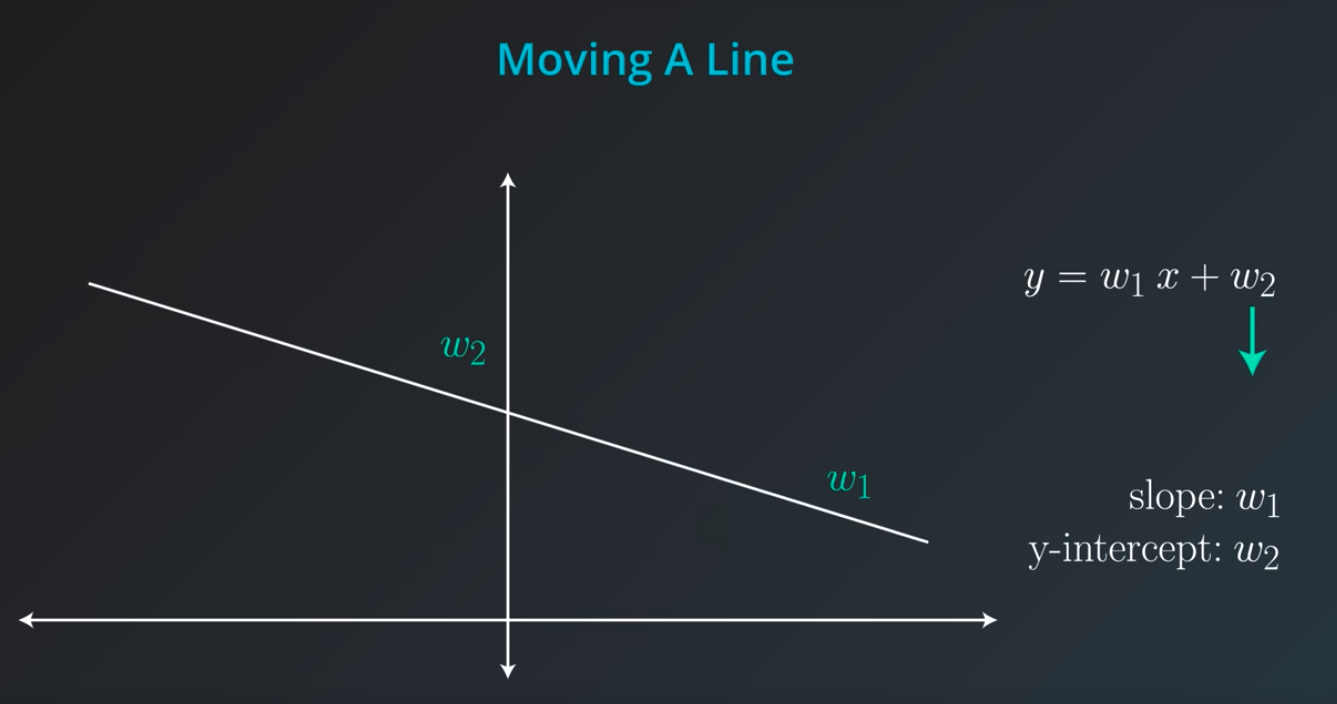
Linear Regression
-
Draw the best fitting line to it
-
-
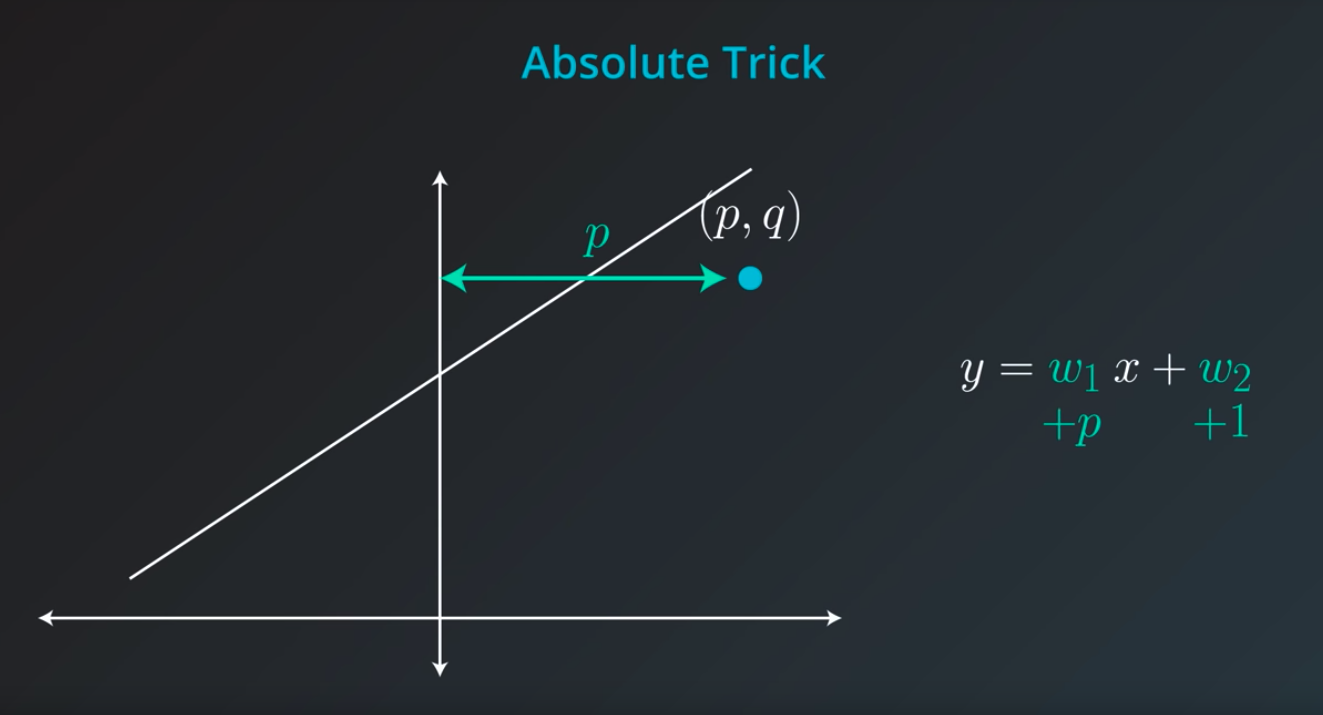
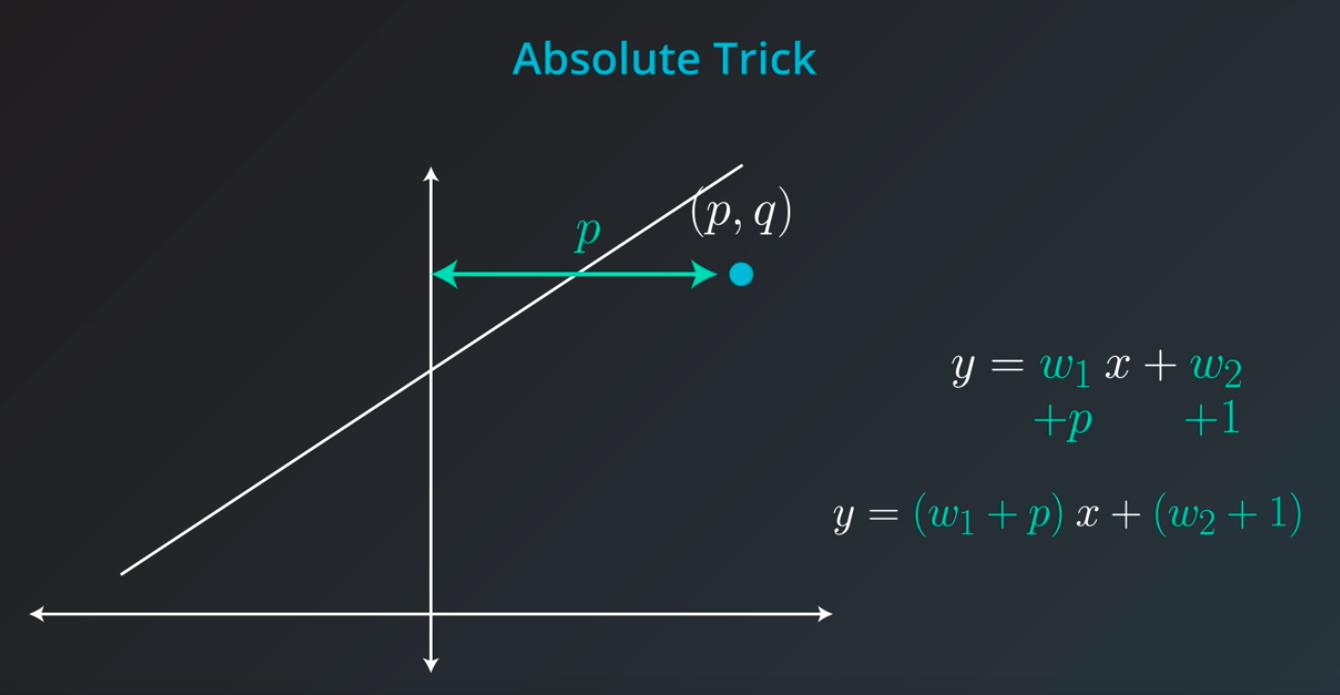
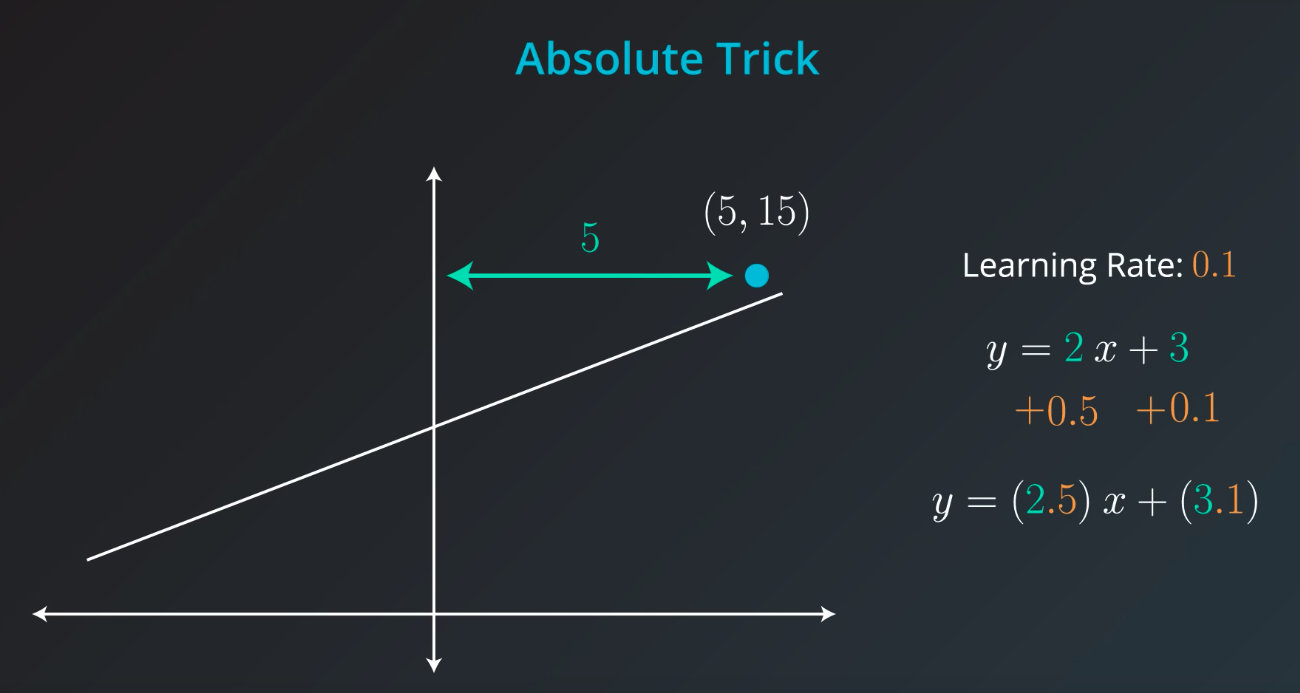
Absolute Trick
-
p: Horizontal -
q: Vertical -
w1: Slop -
w2: Y intercept -
-
-
We want to take tiny steps, so lets multiple this by a small number (learning rate)
-

-
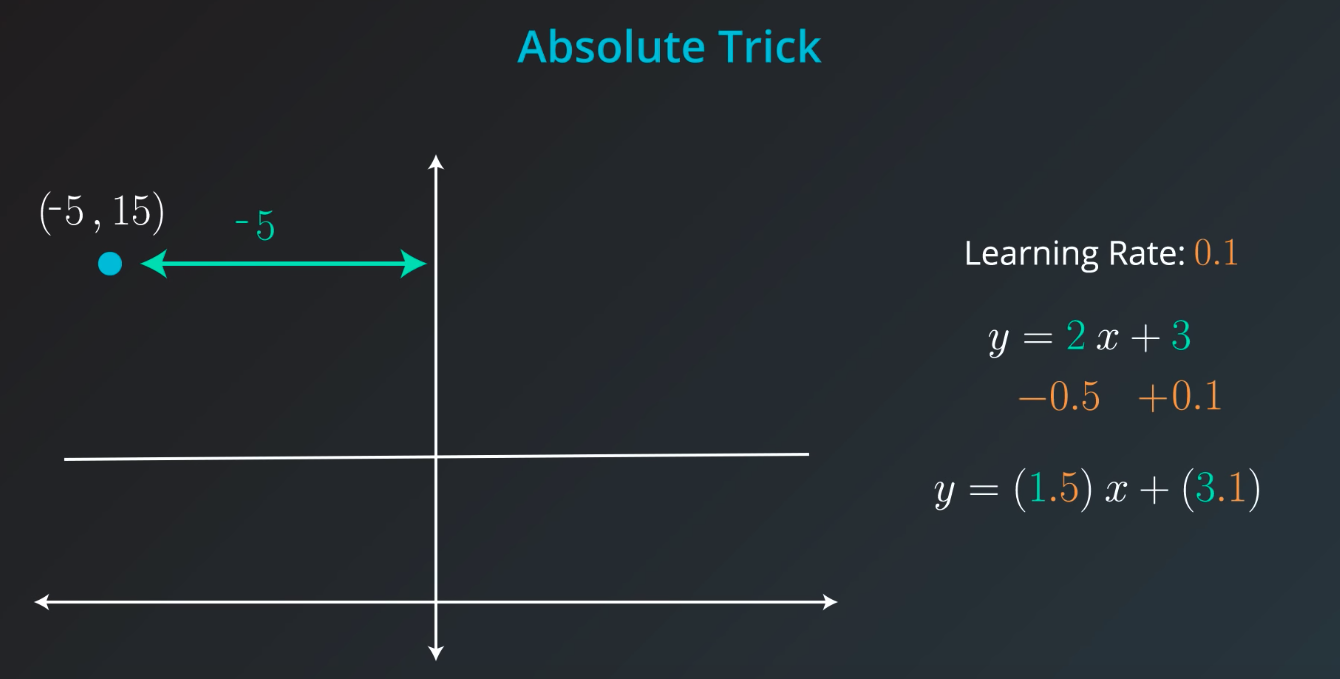
If the point is not on top of the line, but actually underneath we will subtract instead of sum
-
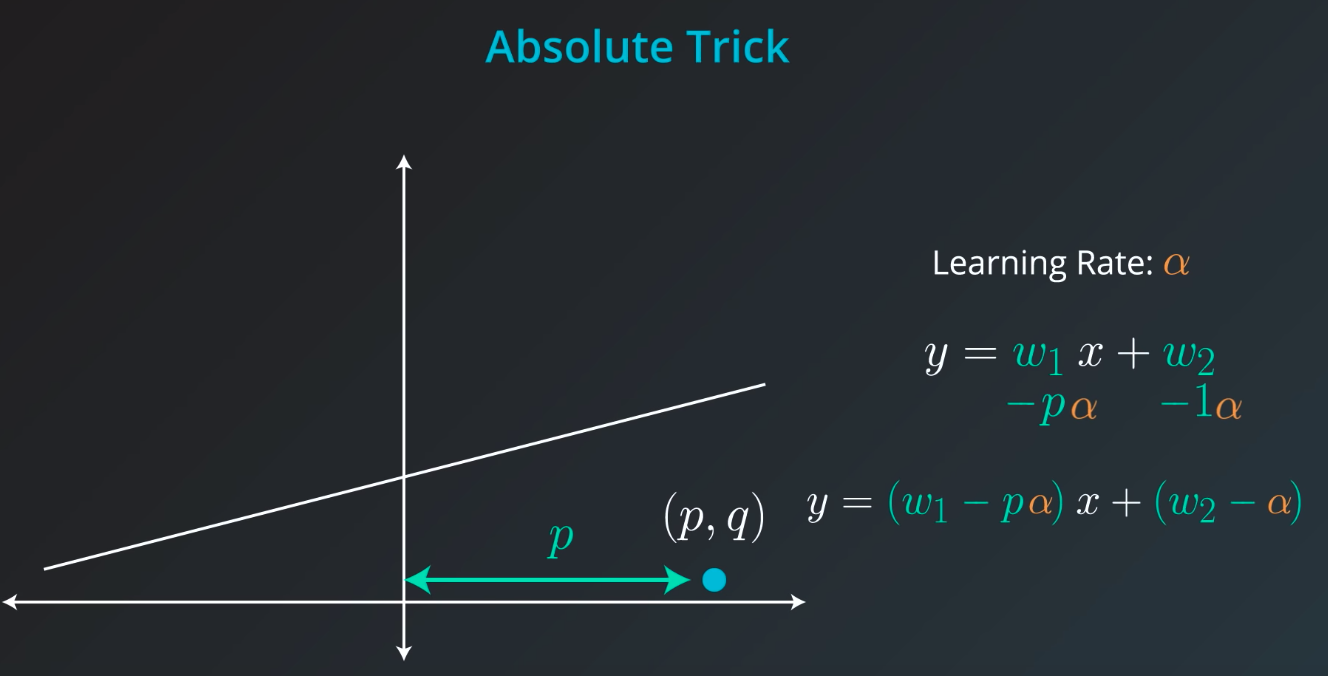
-
The fact we
pis connected with the position of our point. If the point is on the rightw1will move the slop up, but ifpis negativew1will be moved down -
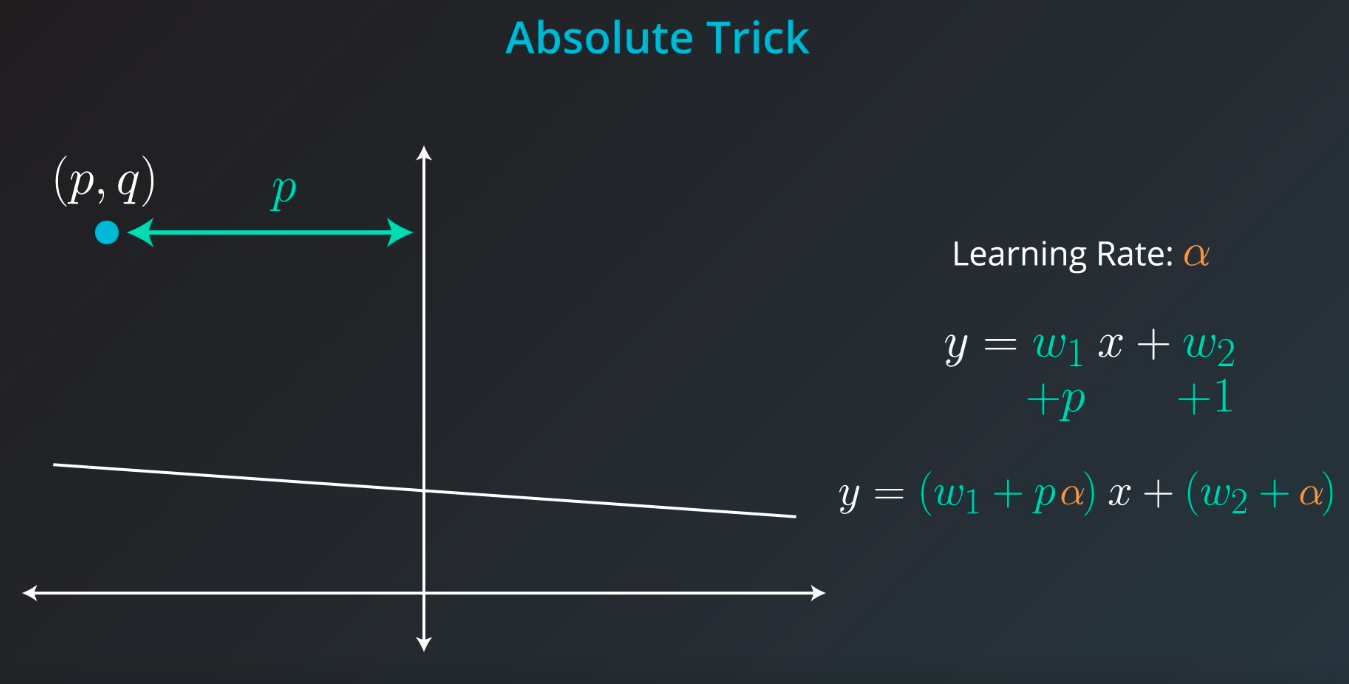
-
Also, if the point distance is small (meaning
pis small), we will add a small value to our slop. However, ifpis large we will add a large number to the slop -
-
-
Great job! Since the point is below the line, the intercept decreases; since the point has a negative x-value, the slope increases.
-
-
-
Square Trick
-

-

-
Besides moving the slop
w1horizontally (pvalue) we will also take(q-q')in order to account to the vertical axis -

-
-
Gradient Descent
-
Minimizing the error
-
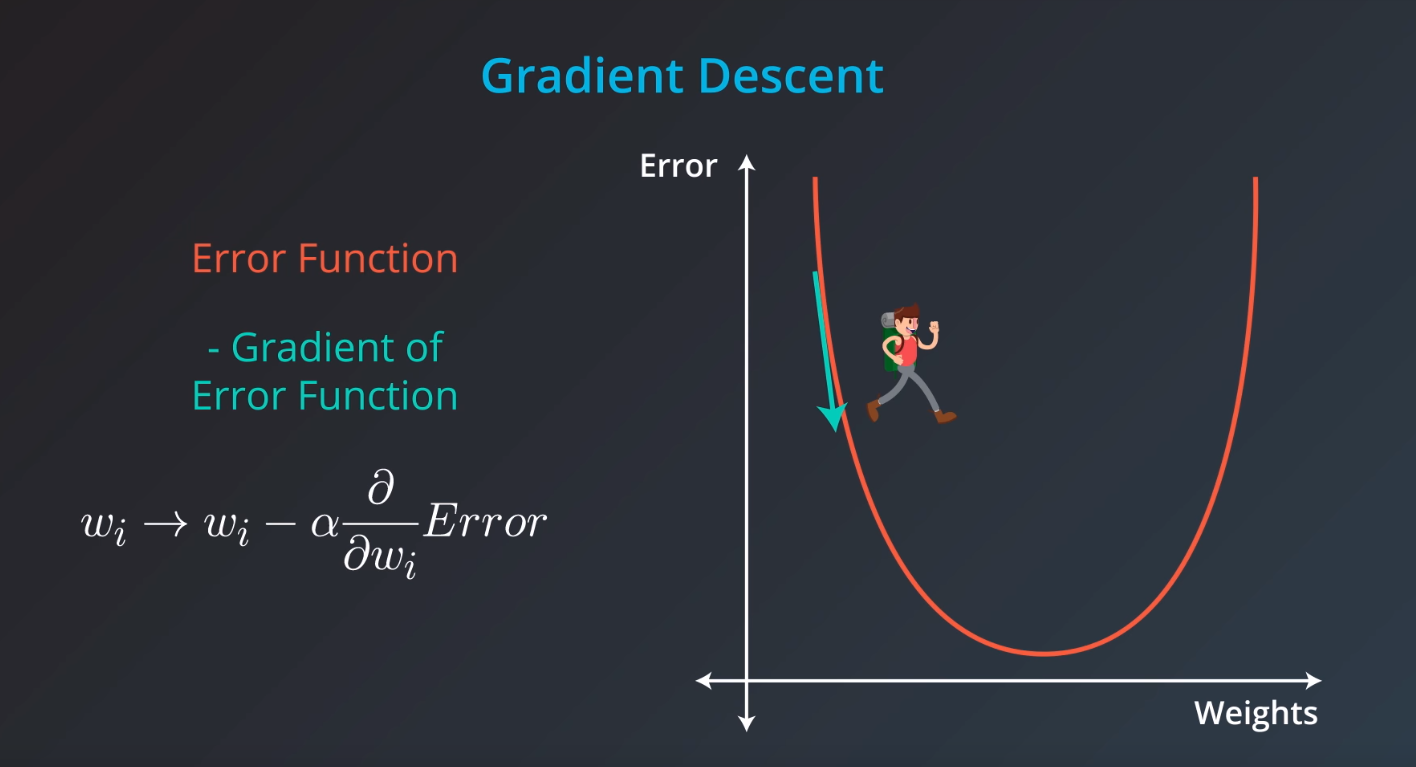
-
-
Error Functions
-
Mean Absolute Error
-

-

- Sum of all errors divided by
mwhich is the number of data points
- Sum of all errors divided by
-

- We take the absolute value so we don't cancel positive errors with negative errors in our data set
-
-
Mean Square Error
-

-

- This is always gonna be a positive error since we are taking the square of it
-
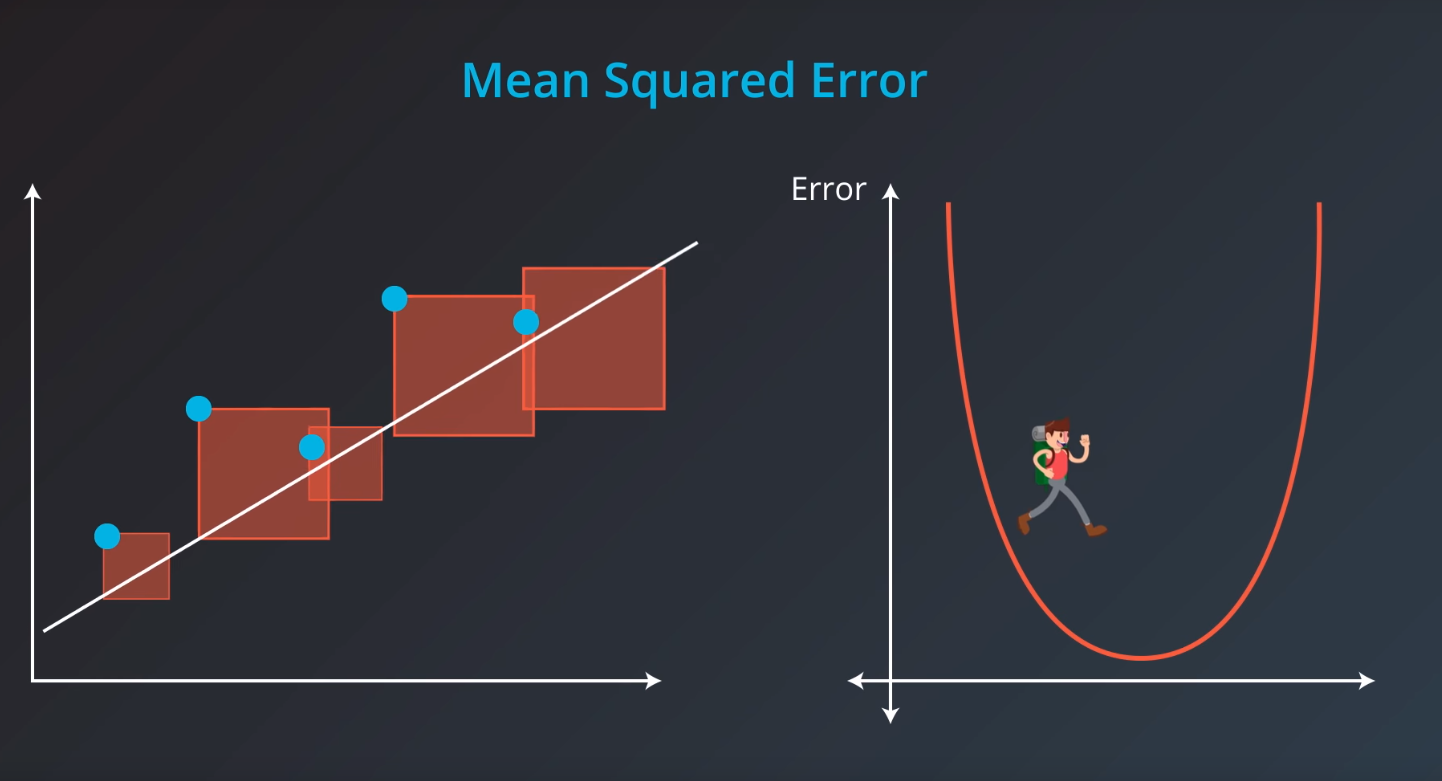
-
-
Minimizing Error Functions
-
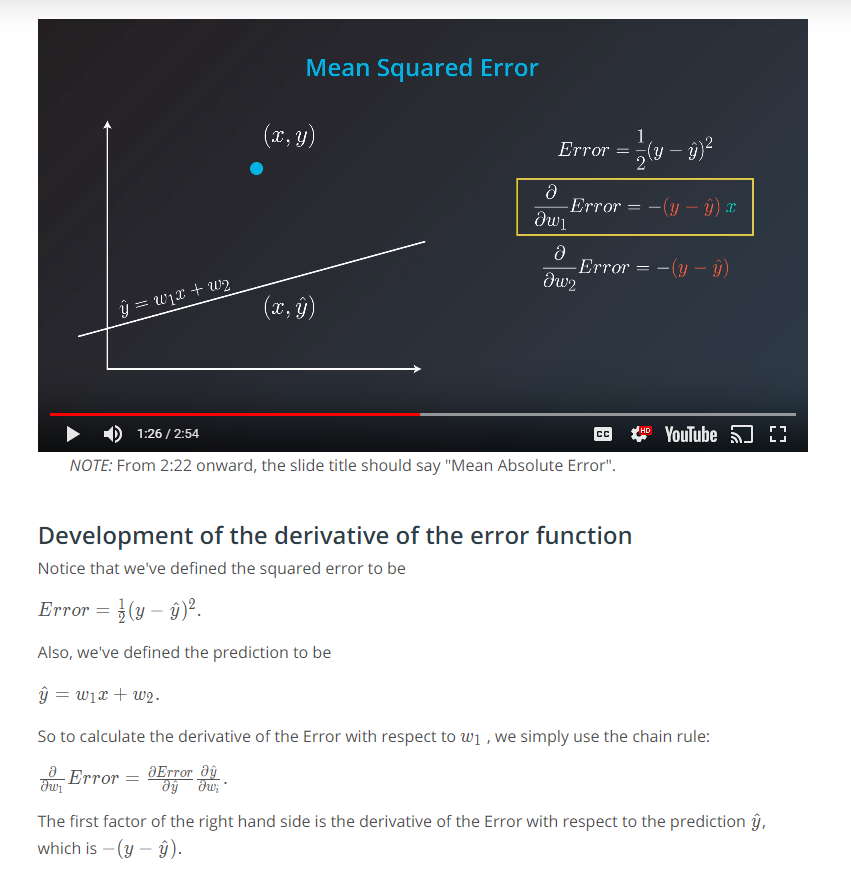
- The tricks we saw before are really similar to our current derivative. Check the tricks again and you will see that
(y - y')xis part of the trick.
- The tricks we saw before are really similar to our current derivative. Check the tricks again and you will see that
-

-
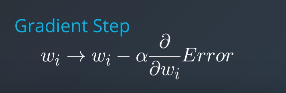
- This is exactly what this gradient descent step is doing. Multiplying
(y - y')xby a learning rate
- This is exactly what this gradient descent step is doing. Multiplying
-

-

-
-
-
Batch vs Stochastic Gradient Descent
-
At this point, it seems that we've seen two ways of doing linear regression.
-
By applying the squared (or absolute) trick at every point in our data one by one, and repeating this process many times.
-
By applying the squared (or absolute) trick at every point in our data all at the same time, and repeating this process many times.
-
-
More specifically, the squared (or absolute) trick, when applied to a point, gives us some values to add to the weights of the model. We can add these values, update our weights, and then apply the squared (or absolute) trick on the next point. Or we can calculate these values for all the points, add them, and then update the weights with the sum of these values.
-
The latter is called batch gradient descent. The former is called stochastic gradient descent.
-
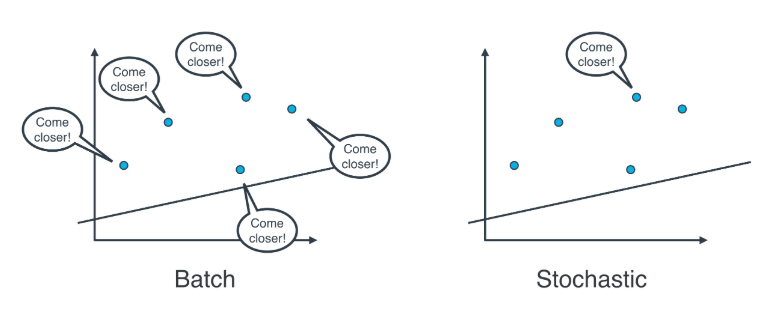
-
The question is, which one is used in practice?
-
Actually, in most cases, neither. Think about this: If your data is huge, both are a bit slow, computationally. The best way to do linear regression, is to split your data into many small batches. Each batch, with roughly the same number of points. Then, use each batch to update your weights. This is still called mini-batch gradient descent.
-
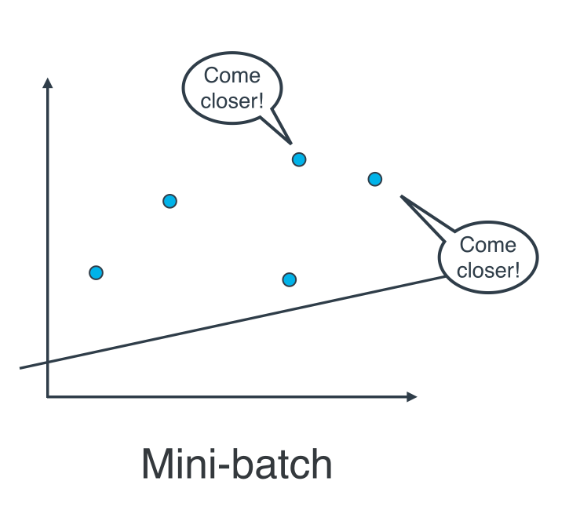
-
-
Mini-Batch Gradient Descent Quiz
-
In this quiz, you'll be given the following sample dataset (as in data.csv), and your goal is to write a function that executes mini-batch gradient descent to find a best-fitting regression line. You might consider looking into numpy's
matmulfunction for this! -
def MSEStep(X, y, W, b, learn_rate = 0.001): """ This function implements the gradient descent step for squared error as a performance metric. Parameters X : array of predictor features y : array of outcome values W : predictor feature coefficients b : regression function intercept learn_rate : learning rate Returns W_new : predictor feature coefficients following gradient descent step b_new : intercept following gradient descent step """ # compute errors y_pred = np.matmul(X, W) + b error = y - y_pred # compute steps W_new = W + learn_rate * np.matmul(error, X) b_new = b + learn_rate * error.sum() return W_new, b_new
-
-
Linear Regression with scikit-learn
-
In this section, you'll use linear regression to predict life expectancy from body mass index (BMI). Before you do that, let's go over the tools required to build this model.
-
For your linear regression model, you'll be using scikit-learn's LinearRegression class. This class provides the function fit() to fit the model to your data.
-
>>> from sklearn.linear_model import LinearRegression >>> model = LinearRegression() >>> model.fit(x_values, y_values)
-
Fitting the model means finding the best line that fits the training data. Let's make two predictions using the model's predict() function.
-
>>> print(model.predict([ [127], [248] ])) [[ 438.94308857, 127.14839521]]
-
The model returned an array of predictions, one prediction for each input array. The first input, [127], got a prediction of 438.94308857. The second input, [248], got a prediction of 127.14839521. The reason for predicting on an array like [127] and not just 127, is because you can have a model that makes a prediction using multiple features. We'll go over using multiple variables in linear regression later in this lesson. For now, let's stick to a single value.
-
# TODO: Add import statements import pandas as pd from sklearn.linear_model import LinearRegression # Assign the dataframe to this variable. # TODO: Load the data bmi_life_data = pd.read_csv("bmi_and_life_expectancy.csv") # Make and fit the linear regression model #TODO: Fit the model and Assign it to bmi_life_model bmi_life_model = LinearRegression() bmi_life_model.fit(bmi_life_data[['BMI']], bmi_life_data[['Life expectancy']]) # Mak a prediction using the model # TODO: Predict life expectancy for a BMI value of 21.07931 laos_life_exp = bmi_life_model.predict(21.07931)
-
-
Multiple Linear Regression
-
In the last section, you saw how we can predict life expectancy using BMI. Here, BMI was the predictor, also known as an independent variable. A predictor is a variable you're looking at in order to make predictions about other variables, while the values you are trying to predict are known as dependent variables. In this case, life expectancy was the dependent variable.
-
Now, let’s say we get new data on each person’s heart rate as well. Can we create a prediction of life expectancy using both BMI and heart rate?
-
Absolutely! As we saw in the previous video, we can do that using multiple linear regression.
-
If the outcome you want to predict depends on more than one variable, you can make a more complicated model that takes this into account. As long as they're relevant to the situation, using more independent/predictor variables can help you get a better prediction.
-
When there's just one predictor, the linear regression model is a line, but as you add more predictor variables, you're adding more dimensions to the picture.
-
When you have one predictor variable, the equation of the line is
-
y = mx + b
-
and the plot might look something like this:
-
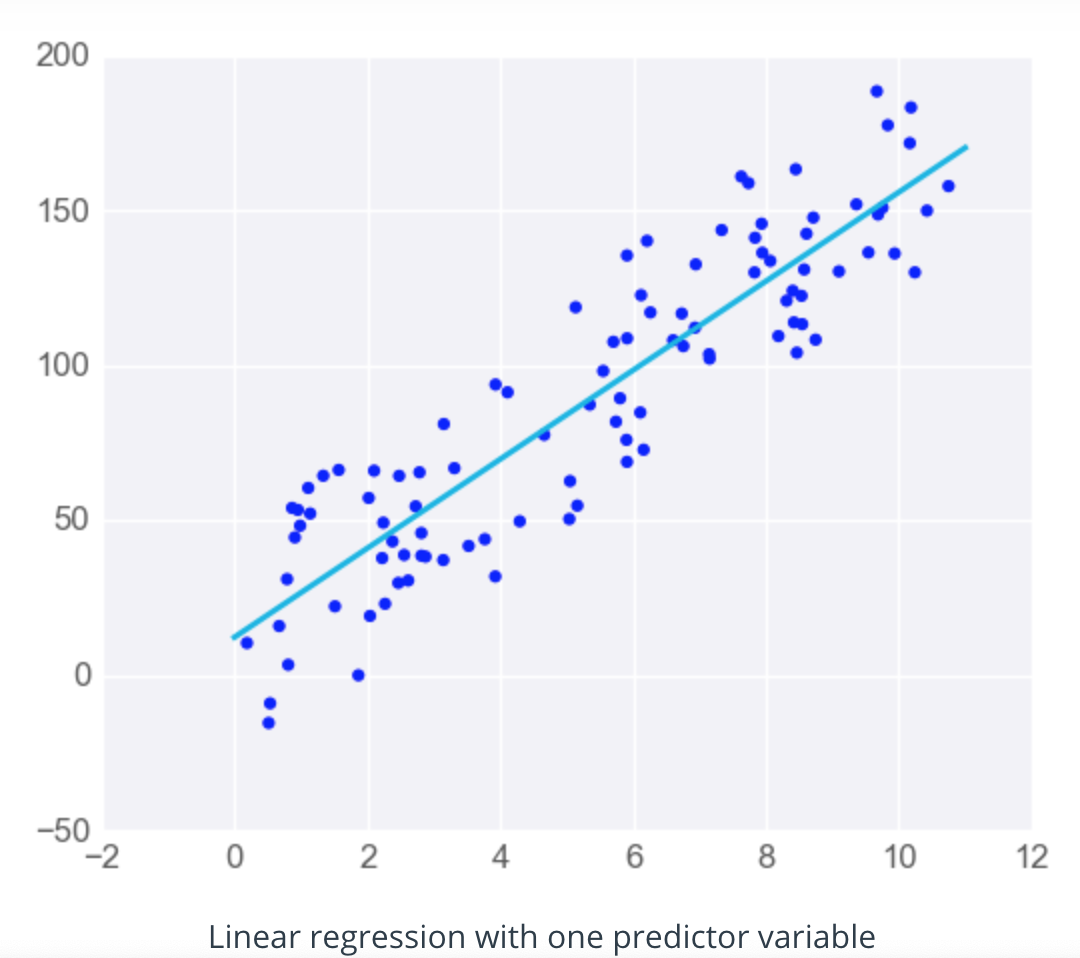
-
Adding a predictor variable to go to two predictor variables means that the predicting equation is:
-
y = m_1 x_1 + m_2 x_2 + b
-
To represent this graphically, we'll need a three-dimensional plot, with the linear regression model represented as a plane:
-
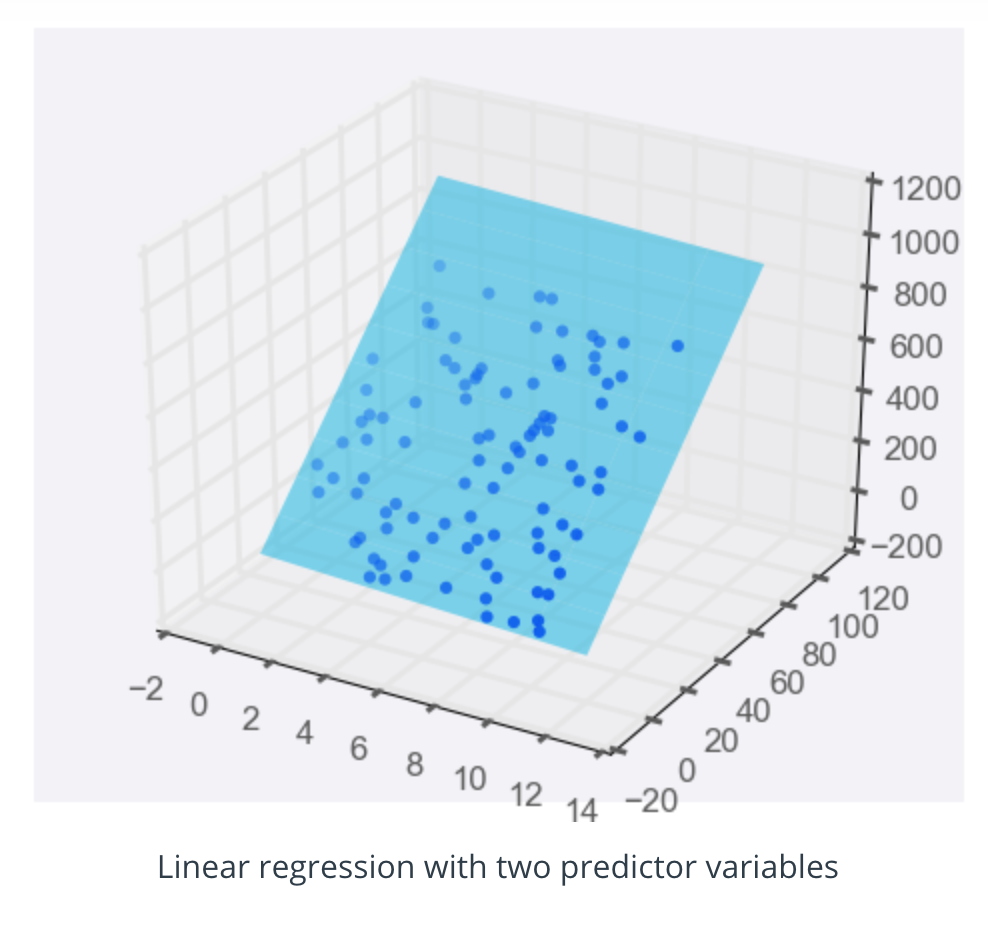
-
You can use more than two predictor variables - in fact, you should use as many as is useful! If you use nn predictor variables, then the model can be represented by the equation
-
y=m1x1+ m2x2 +m3x3+ ... + mnxn +b
-
As you make a model with more predictor variables, it becomes harder to visualise, but luckily, everything else about linear regression stays the same. We can still fit models and make predictions in exactly the same way - time to try it!
-
from sklearn.linear_model import LinearRegression from sklearn.datasets import load_boston # Load the data from the boston house-prices dataset boston_data = load_boston() x = boston_data['data'] y = boston_data['target'] # Make and fit the linear regression model # TODO: Fit the model and Assign it to the model variable model = LinearRegression() model.fit(x, y) # Make a prediction using the model sample_house = [[2.29690000e-01, 0.00000000e+00, 1.05900000e+01, 0.00000000e+00, 4.89000000e-01, 6.32600000e+00, 5.25000000e+01, 4.35490000e+00, 4.00000000e+00, 2.77000000e+02, 1.86000000e+01, 3.94870000e+02, 1.09700000e+01]] # TODO: Predict housing price for the sample_house prediction = model.predict(sample_house)
-
-
Linear Regression Warnings
-
Linear regression comes with a set of implicit assumptions and is not the best model for every situation. Here are a couple of issues that you should watch out for.
-
Linear Regression Works Best When the Data is Linear
-
Linear regression produces a straight line model from the training data. If the relationship in the training data is not really linear, you'll need to either make adjustments (transform your training data), add features (we'll come to this next), or use another kind of model.
-
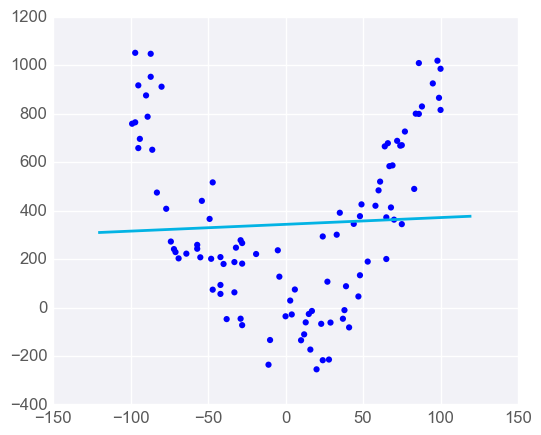
-
Linear Regression is Sensitive to Outliers
-
Linear regression tries to find a 'best fit' line among the training data. If your dataset has some outlying extreme values that don't fit a general pattern, they can have a surprisingly large effect.
-
In this first plot, the model fits the data pretty well.
-
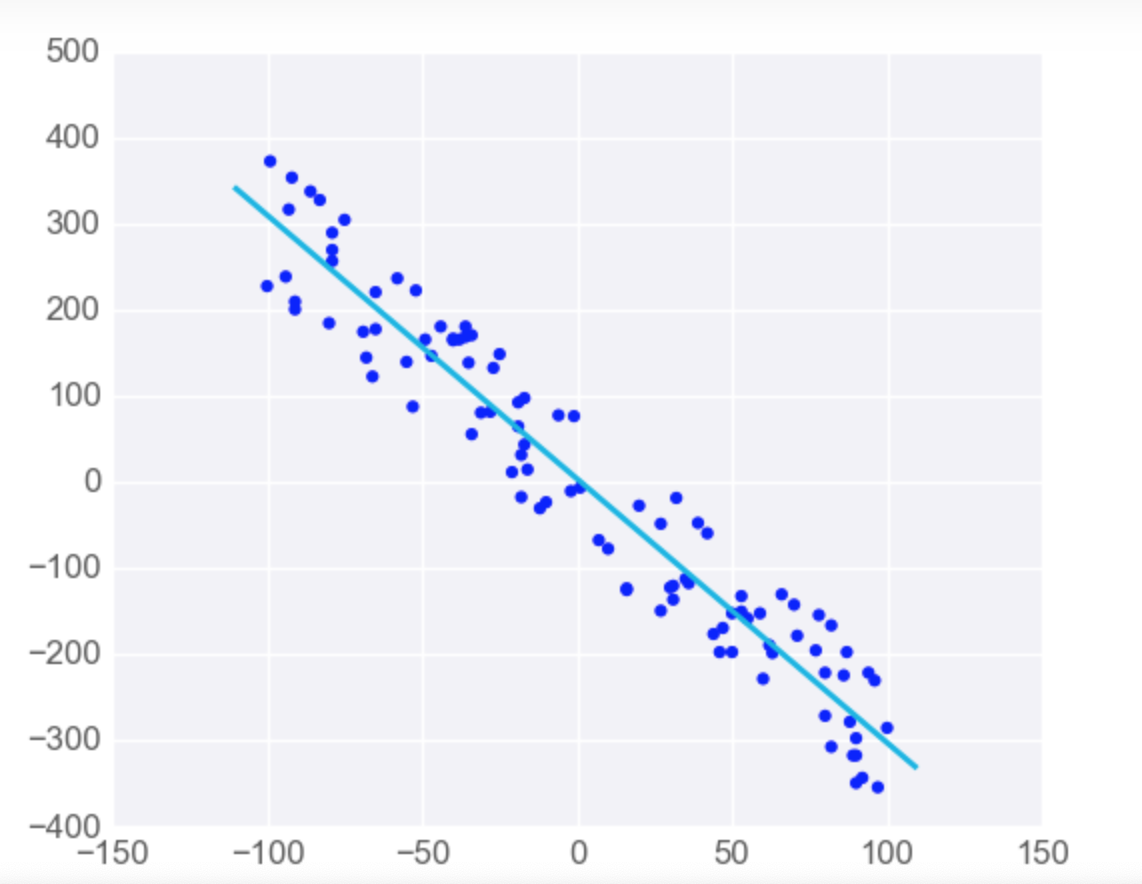
-
However, adding a few points that are outliers and don't fit the pattern really changes the way the model predicts.
-
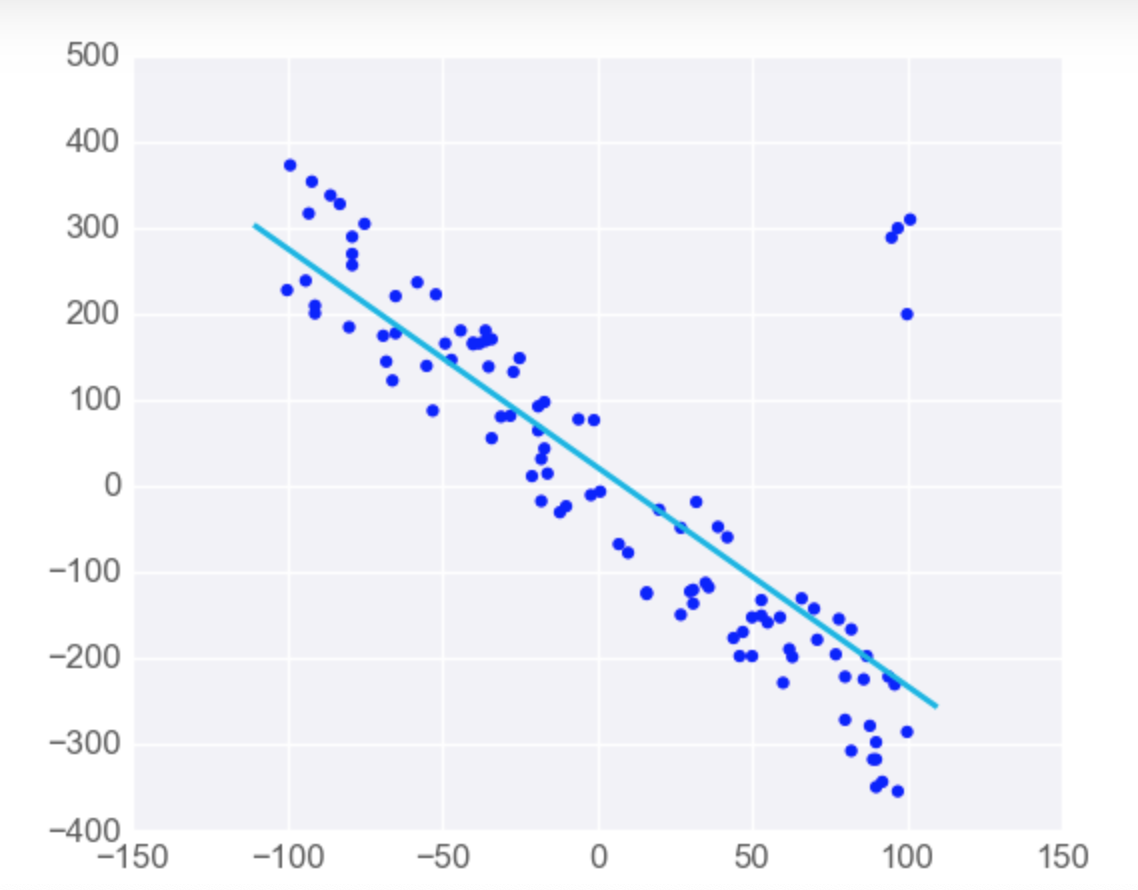
-
-
-
Polynomial Regression
-
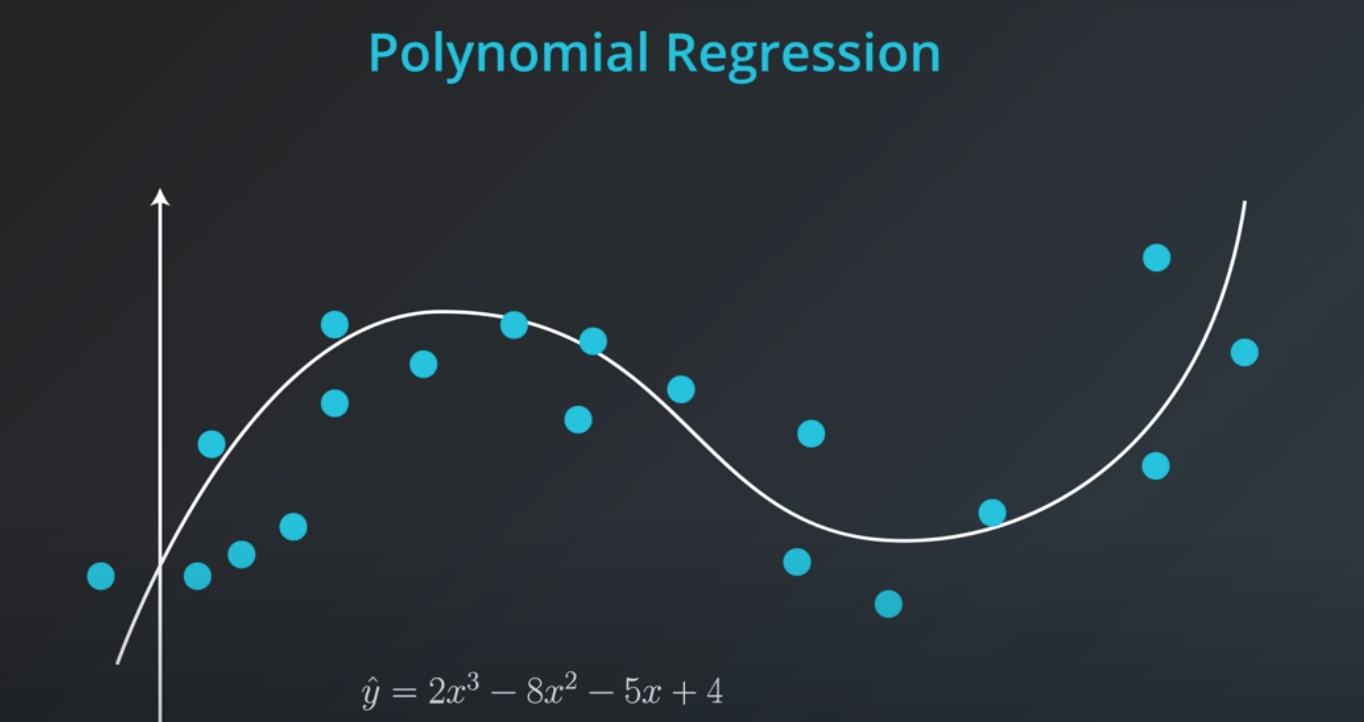
-
In order to represent this line we will need a polynomial equation
-
This will work the same way as the Linear Regression, but with more weights
-
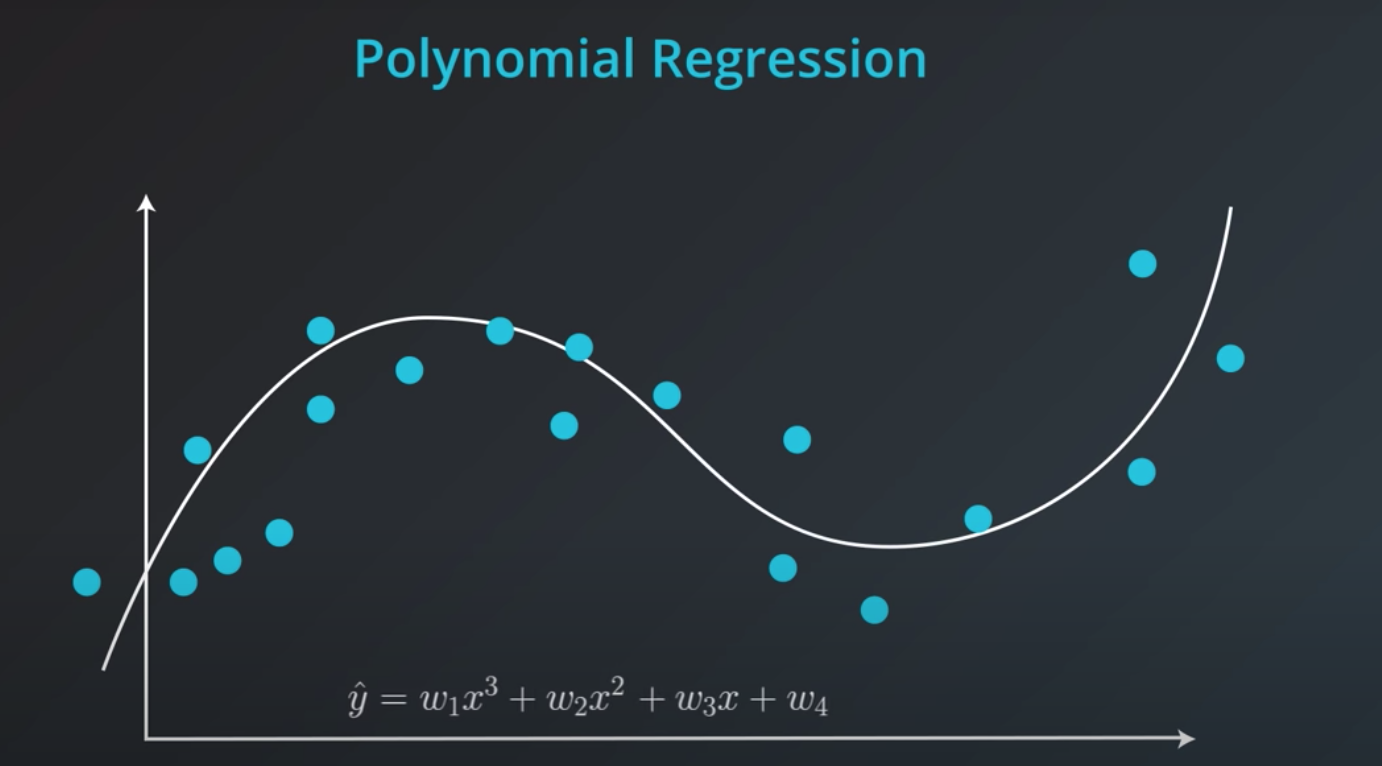
-
The algorithm is the same thing, we take the mean absolute error or mean squared error, and take the derivative to the respect of the 4 variables and use gradient descent to modified this 4 weights in order to minimize the error.
-
-
Get some practice implementing polynomial regression in this exercise. In data.csv, you can see data generated for one predictor feature ('Var_X') and one outcome feature ('Var_Y'), following a non-linear trend. Use sklearn's PolynomialFeatures class to extend the predictor feature column into multiple columns with polynomial features. Play around with different degrees of polynomial and the Test Run button to see what fits best: when you think you have the best-fitting degree, press the Submit button to check your work!
-
# TODO: Add import statements import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures # Assign the data to predictor and outcome variables # TODO: Load the data train_data = pd.read_csv('data.csv') X = train_data['Var_X'].values.reshape(-1, 1) y = train_data['Var_Y'].values # Create polynomial features # TODO: Create a PolynomialFeatures object, then fit and transform the # predictor feature poly_feat = PolynomialFeatures(degree = 4) X_poly = poly_feat.fit_transform(X) # Make and fit the polynomial regression model # TODO: Create a LinearRegression object and fit it to the polynomial predictor # features poly_model = LinearRegression(fit_intercept = False).fit(X_poly, y)
-
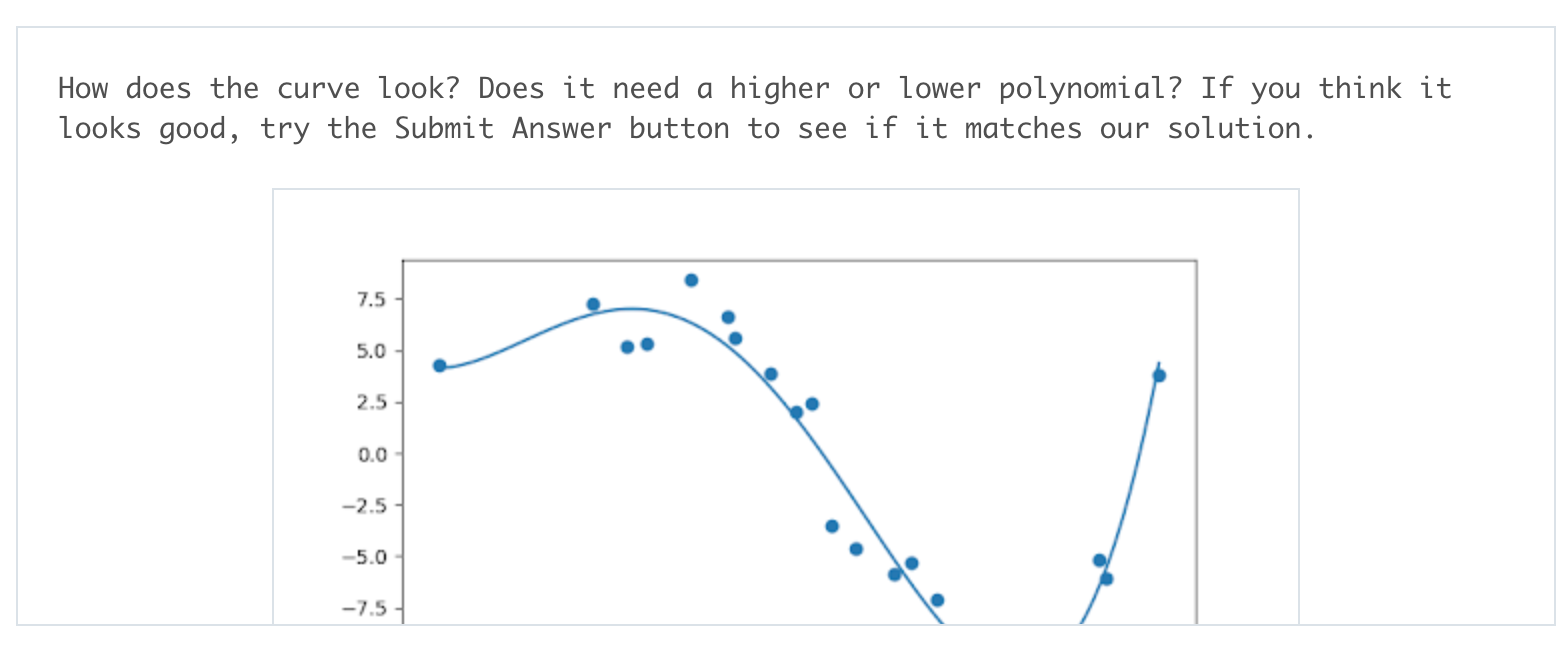
-
-
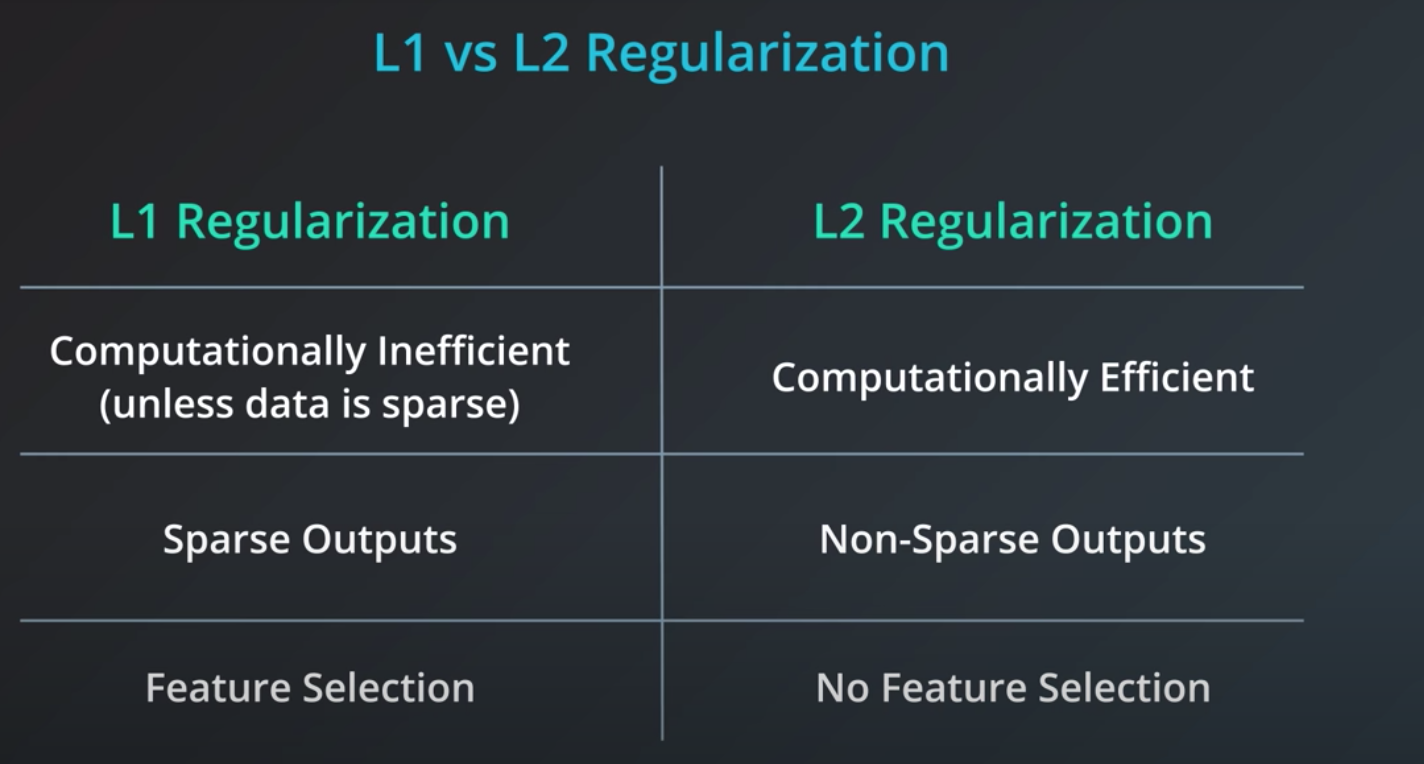
Regularization
-
This concept works for both regression and classification
-
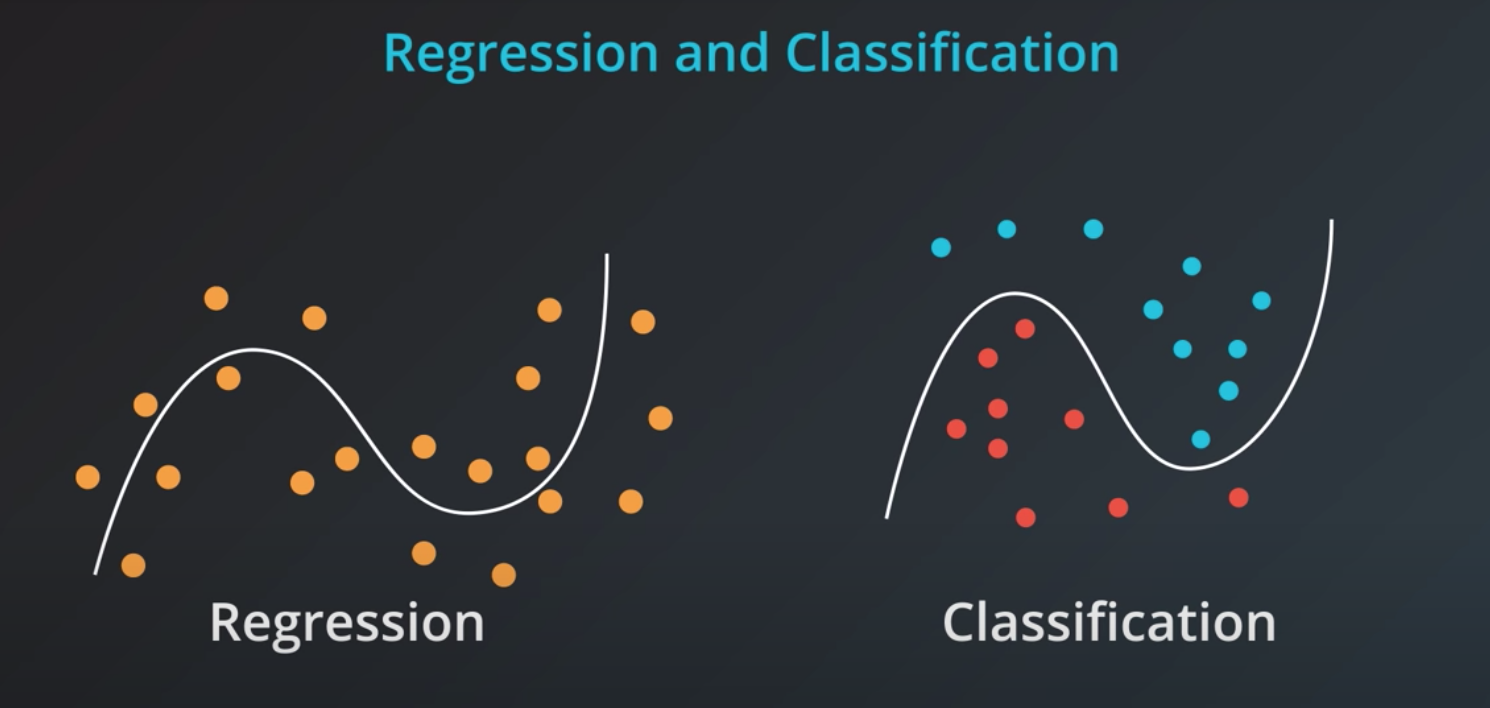
-

-
If we train a model to minimize error we will elect the one in the right. However, this model is probably over fitting
-
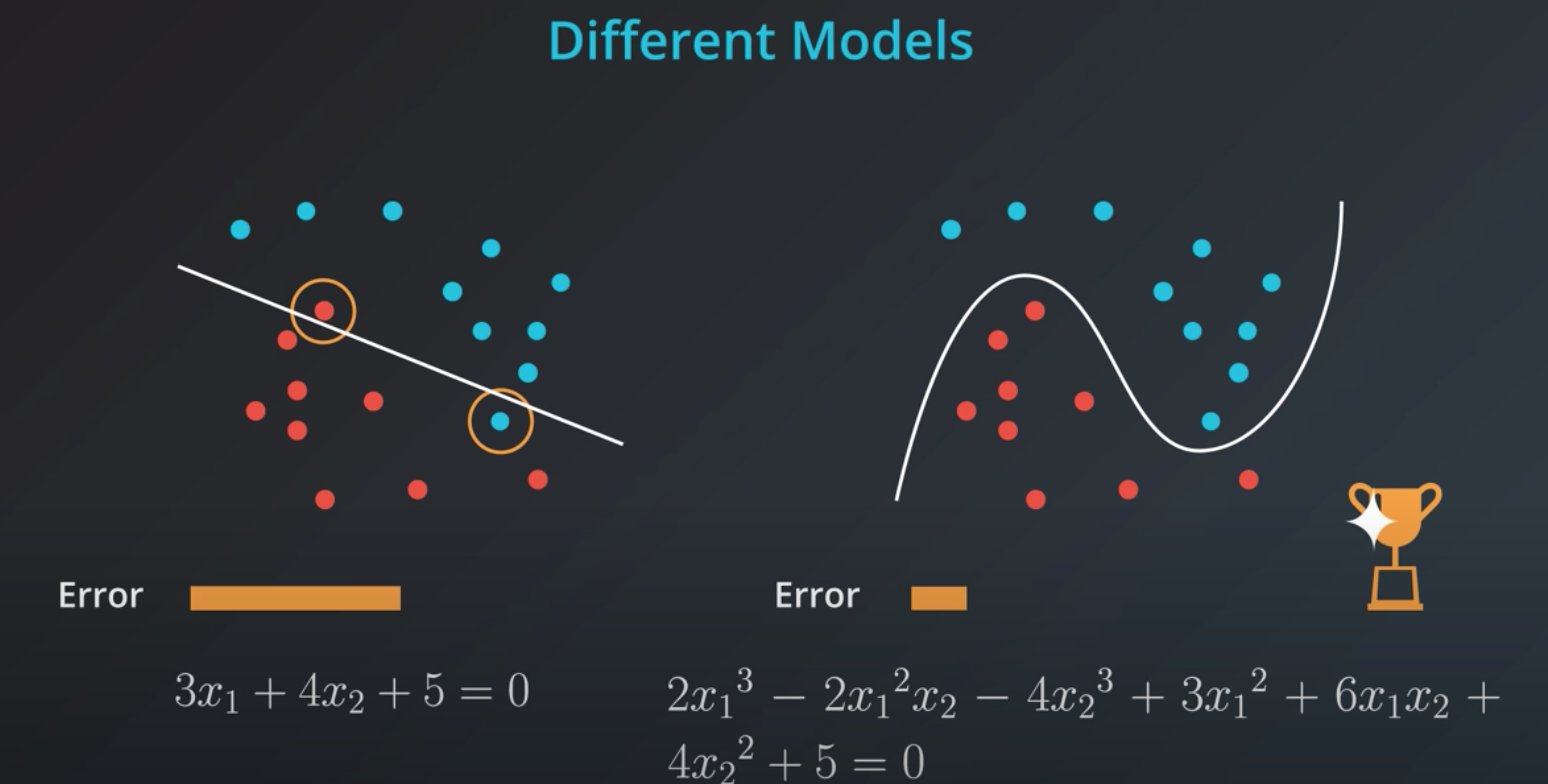
-
The right solution has many more coefficients compared to the left one
-
If we could add those coefficients as the "model complexity" chunk of our error that would be beneficial.
-

-
Simple models has a tendency to generalize better, and that is what we want.
-
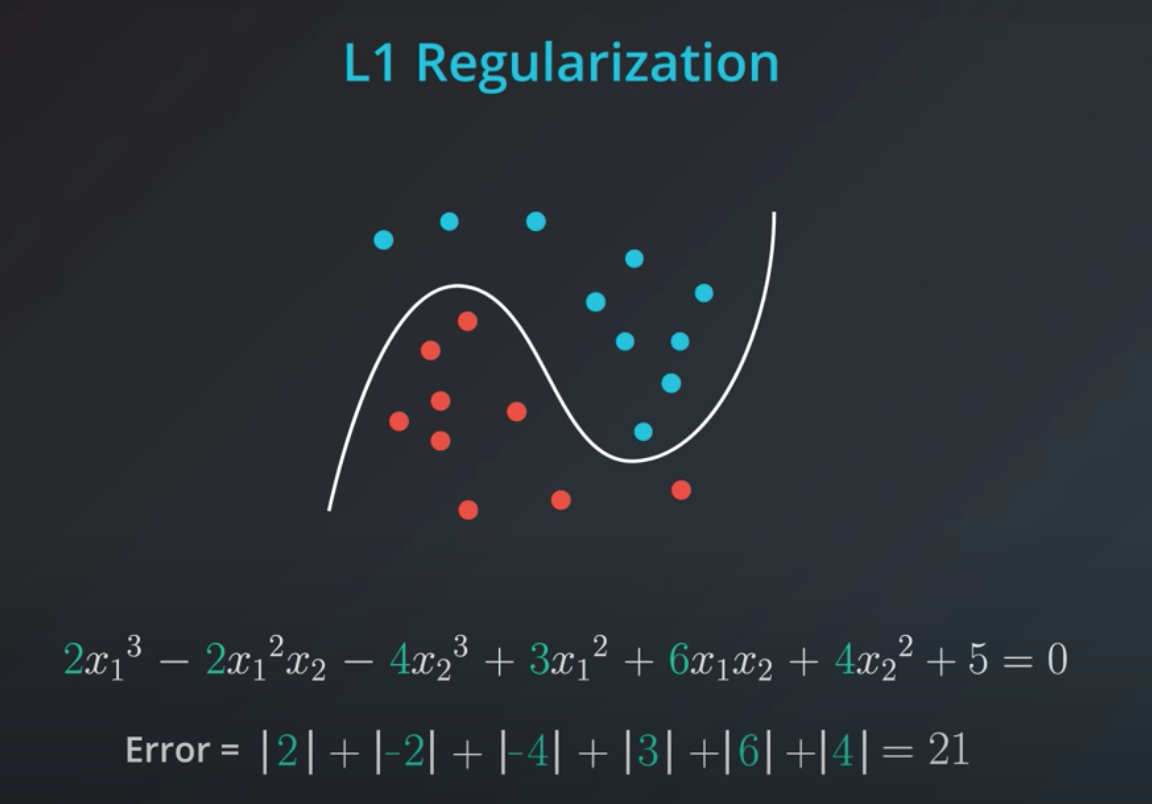
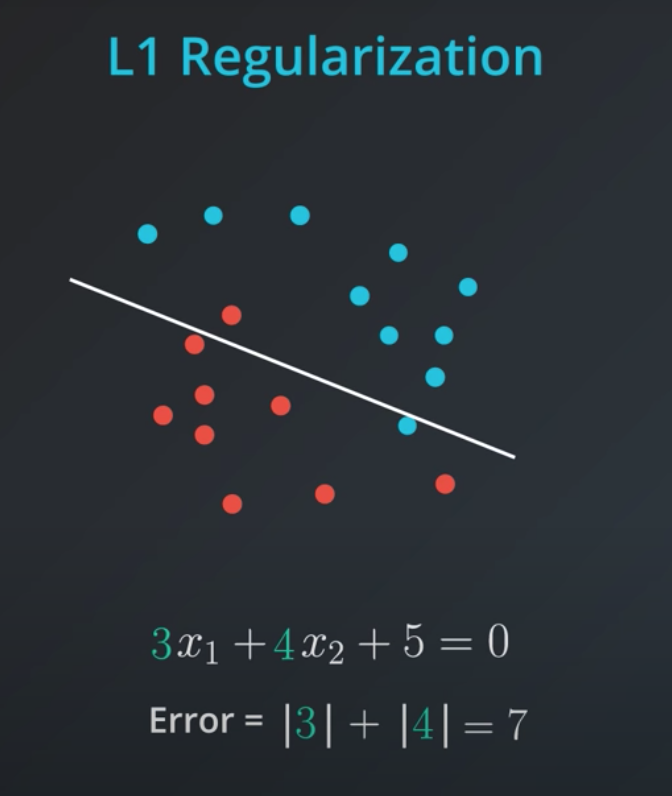
- L1 takes the coefficients and adds their absolute value to the error.
-
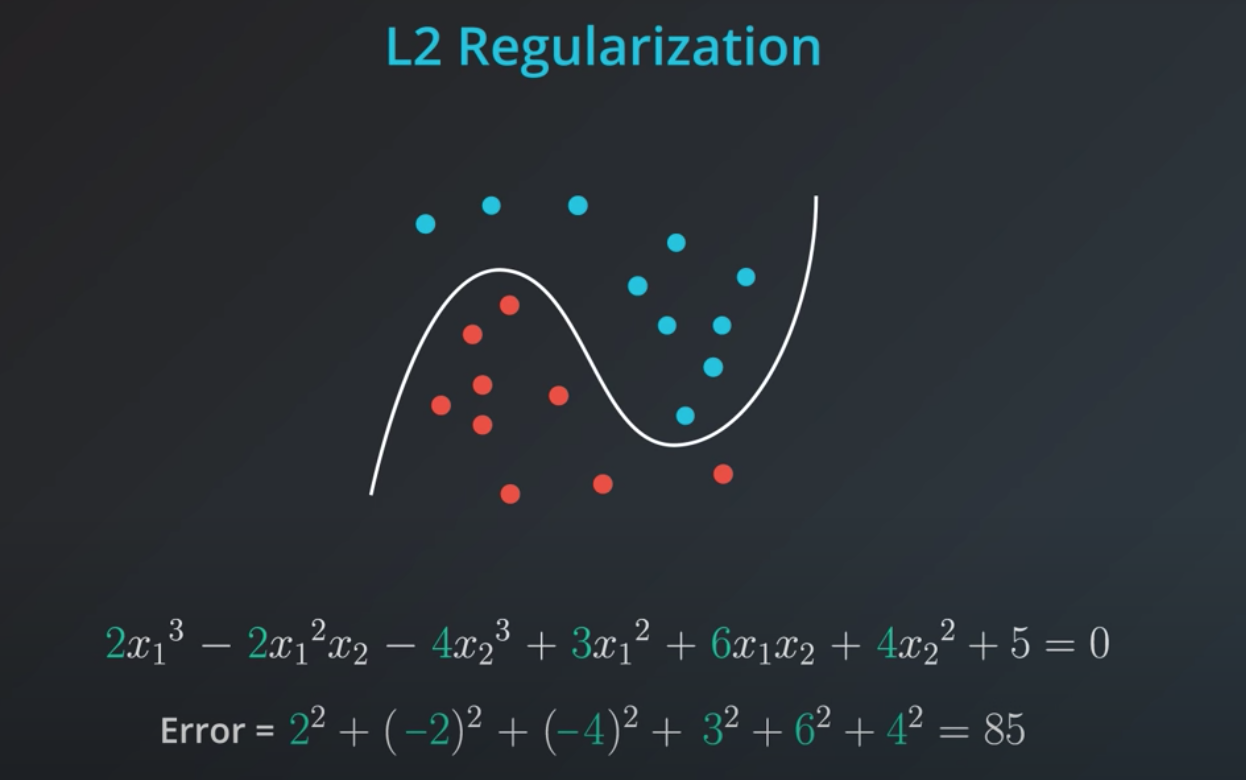
-
L2 regularization is similar, but here we add the squares of the coefficients.
-
-
In order to determine how impactful model complexity is over the error, we introduce a new parameter lambda
-

-

- Small lambda = ok with more complex models
- Big lambda = sensitive to complex models
-
-
# TODO: Add import statements import numpy as np import pandas as pd from sklearn.linear_model import Lasso # Assign the data to predictor and outcome variables # TODO: Load the data train_data = pd.read_csv('data.csv', header = None) X = train_data.iloc[:,:-1] y = train_data.iloc[:,-1] # TODO: Create the linear regression model with lasso regularization. lasso_reg = Lasso() # TODO: Fit the model. lasso_reg.fit(X, y) # TODO: Retrieve and print out the coefficients from the regression model. reg_coef = lasso_reg.coef_ print(reg_coef)
-
-
Feature Scaling
-
What is feature scaling? Feature scaling is a way of transforming your data into a common range of values. There are two common scalings:
- Standardizing
- Normalizing
-
Standardizing
-
Standardizing is completed by taking each value of your column, subtracting the mean of the column, and then dividing by the standard deviation of the column. In Python, let's say you have a column in df called height. You could create a standardized height as:
- In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values.[1] A low standard deviation indicates that the values tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the values are spread out over a wider range.
-
df["height_standard"] = (df["height"] - df["height"].mean()) / df["height"].std() -
This will create a new "standardized" column where each value is a comparison to the mean of the column, and a new, standardized value can be interpreted as the number of standard deviations the original height was from the mean. This type of feature scaling is by far the most common of all techniques (for the reasons discussed here, but also likely because of precedent).
-
-
Normalizing
-
A second type of feature scaling that is very popular is known as normalizing. With normalizing, data are scaled between 0 and 1. Using the same example as above, we could perform normalizing in Python in the following way:
-
df["height_normal"] = (df["height"] - df["height"].min()) / (df["height"].max() - df['height'].min())
-
-
When Should I Use Feature Scaling?
-
In many machine learning algorithms, the result will change depending on the units of your data. This is especially true in two specific cases:
-
When your algorithm uses a distance-based metric to predict.
-
When you incorporate regularization.
-
-
Distance Based Metrics
-
In future lessons, you will see one common supervised learning technique that is based on the distance points are from one another called Support Vector Machines (or SVMs). Another technique that involves distance based methods to determine a prediction is k-nearest neighbors (or k-nn). With either of these techniques, choosing not to scale your data may lead to drastically different (and likely misleading) ending predictions.
-
For this reason, choosing some sort of feature scaling is necessary with these distance based techniques.
-
-
Regularization
-
When you start introducing regularization, you will again want to scale the features of your model. The penalty on particular coefficients in regularized linear regression techniques depends largely on the scale associated with the features. When one feature is on a small range, say from 0 to 10, and another is on a large range, say from 0 to 1 000 000, applying regularization is going to unfairly punish the feature with the small range. Features with small ranges need to have larger coefficients compared to features with large ranges in order to have the same effect on the outcome of the data. (Think about how ab = baab=ba for two numbers aa and bb.) Therefore, if regularization could remove one of those two features with the same net increase in error, it would rather remove the small-ranged feature with the large coefficient, since that would reduce the regularization term the most.
-
Again, this means you will want to scale features any time you are applying regularization.
-
A point raised in the article above is that feature scaling can speed up convergence of your machine learning algorithms, which is an important consideration when you scale machine learning applications.
-
# TODO: Add import statements import numpy as np import pandas as pd from sklearn.linear_model import Lasso from sklearn.preprocessing import StandardScaler # Assign the data to predictor and outcome variables # TODO: Load the data train_data = pd.read_csv('data.csv', header = None) X = train_data.iloc[:,:-1] y = train_data.iloc[:,-1] # TODO: Create the standardization scaling object. scaler = StandardScaler() # TODO: Fit the standardization parameters and scale the data. X_scaled = scaler.fit_transform(X) # TODO: Create the linear regression model with lasso regularization. lasso_reg = Lasso() # TODO: Fit the model. lasso_reg.fit(X_scaled, y) # TODO: Retrieve and print out the coefficients from the regression model. reg_coef = lasso_reg.coef_ print(reg_coef)
-
-
-
-
Recap
-
In this lesson, you were introduced to linear models. Specifically, you saw:
-
Gradient descent as a method to optimize your linear models.
-
Multiple Linear Regression as a technique for when you are comparing more than two variables.
-
Polynomial Regression for relationships between variables that aren't linear.
-
Regularization as a technique to assure that your models will not only fit to the data available, but also extend to new situations.
-













































-
Perceptron Algorithm
- For classification (matching values to labels), check the (AI Programming README)[https://github.com/danielmapar/AIProgramming]
- Neural Networks section
- For classification (matching values to labels), check the (AI Programming README)[https://github.com/danielmapar/AIProgramming]
-
Decision Trees
-
Entropy
-
This is a concept that comes from physics and it measures how much a particle can move.
- Example: water, gas and solid
- Solid has low entropy, gas has high entropy
-
Entropy also works in probability
-
The more homogeneous (less variaty), the less entropy
-
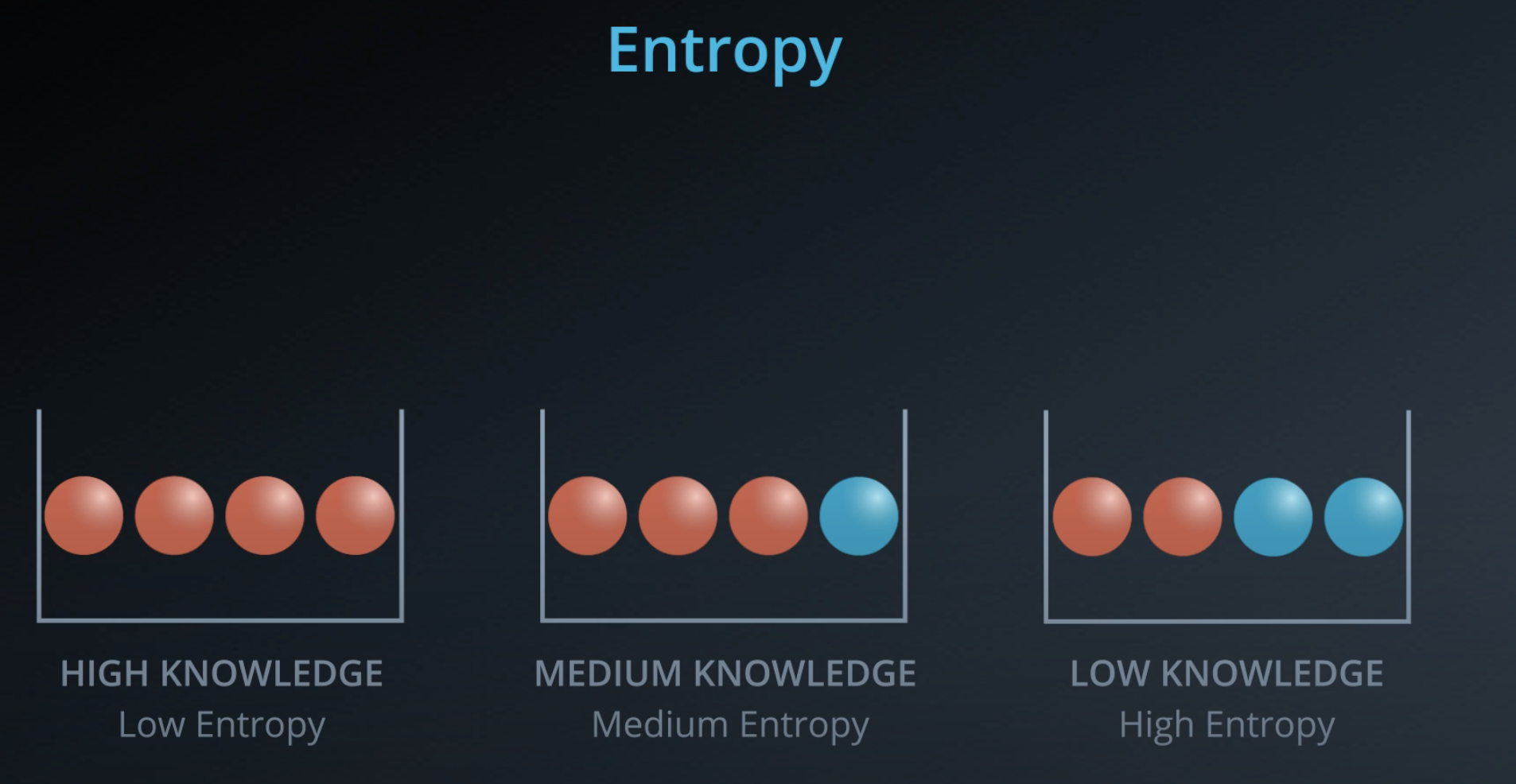
- The more knowledge one has, the less entropy it is
-
-
-
-
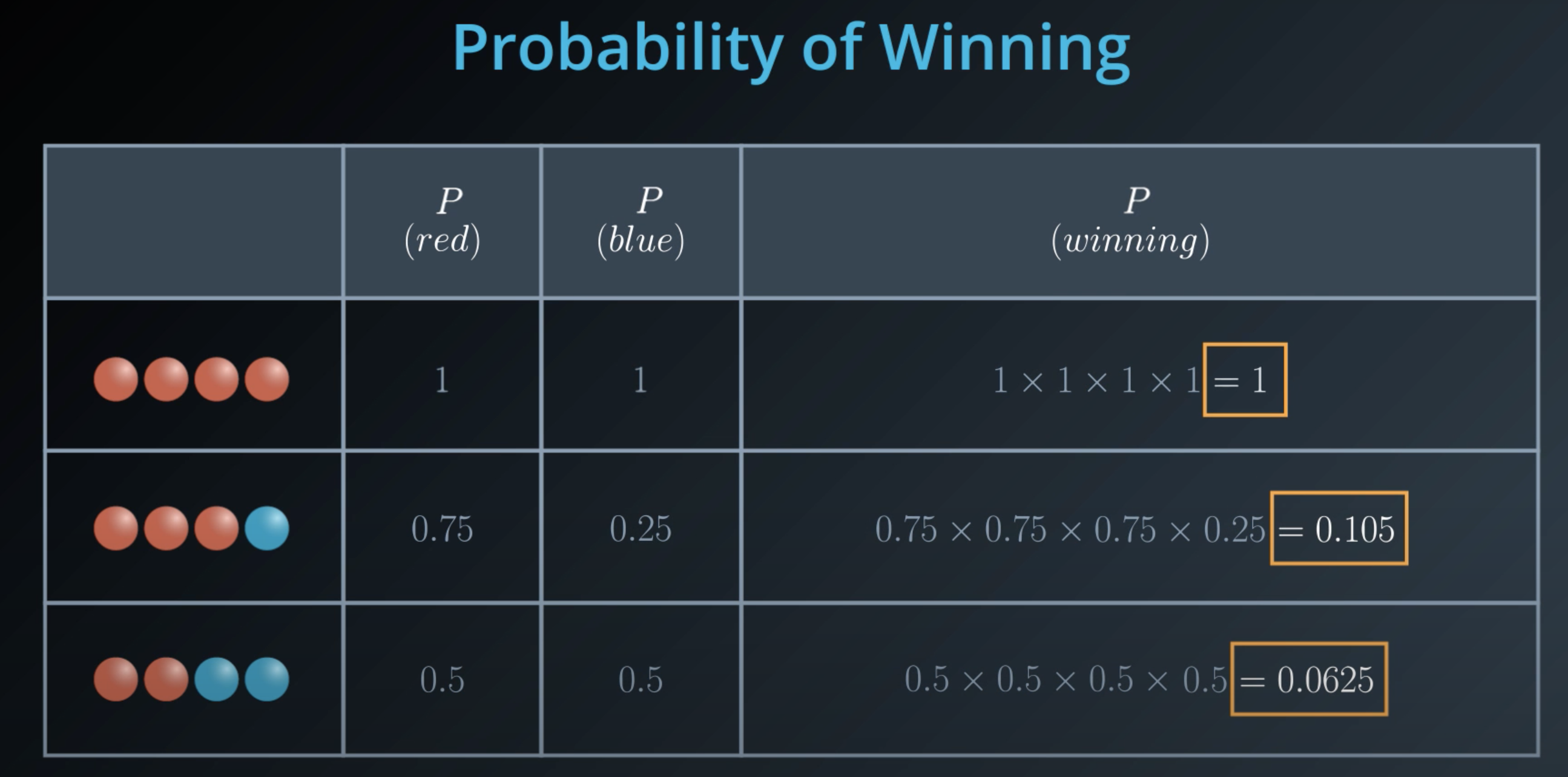
-

-

-
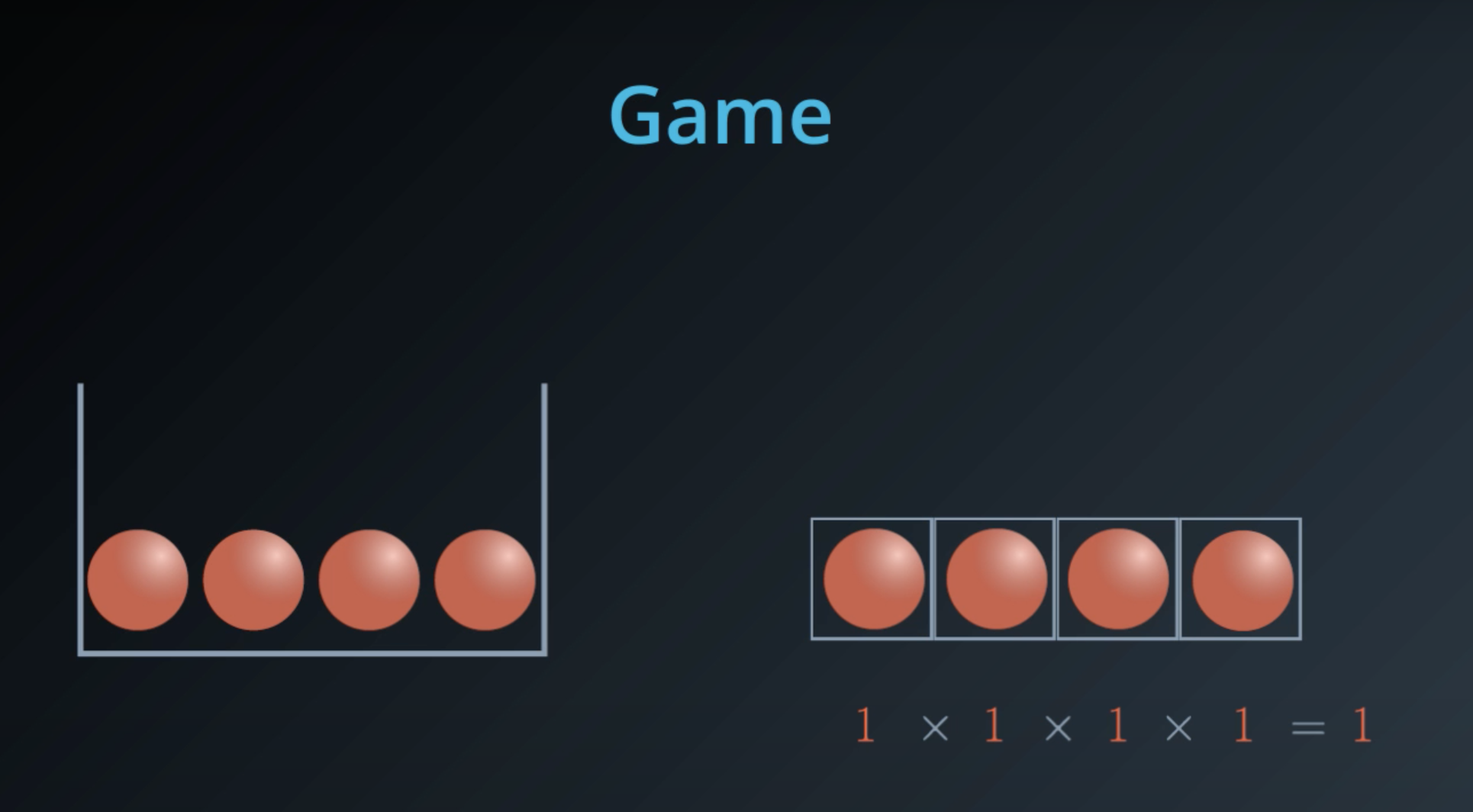
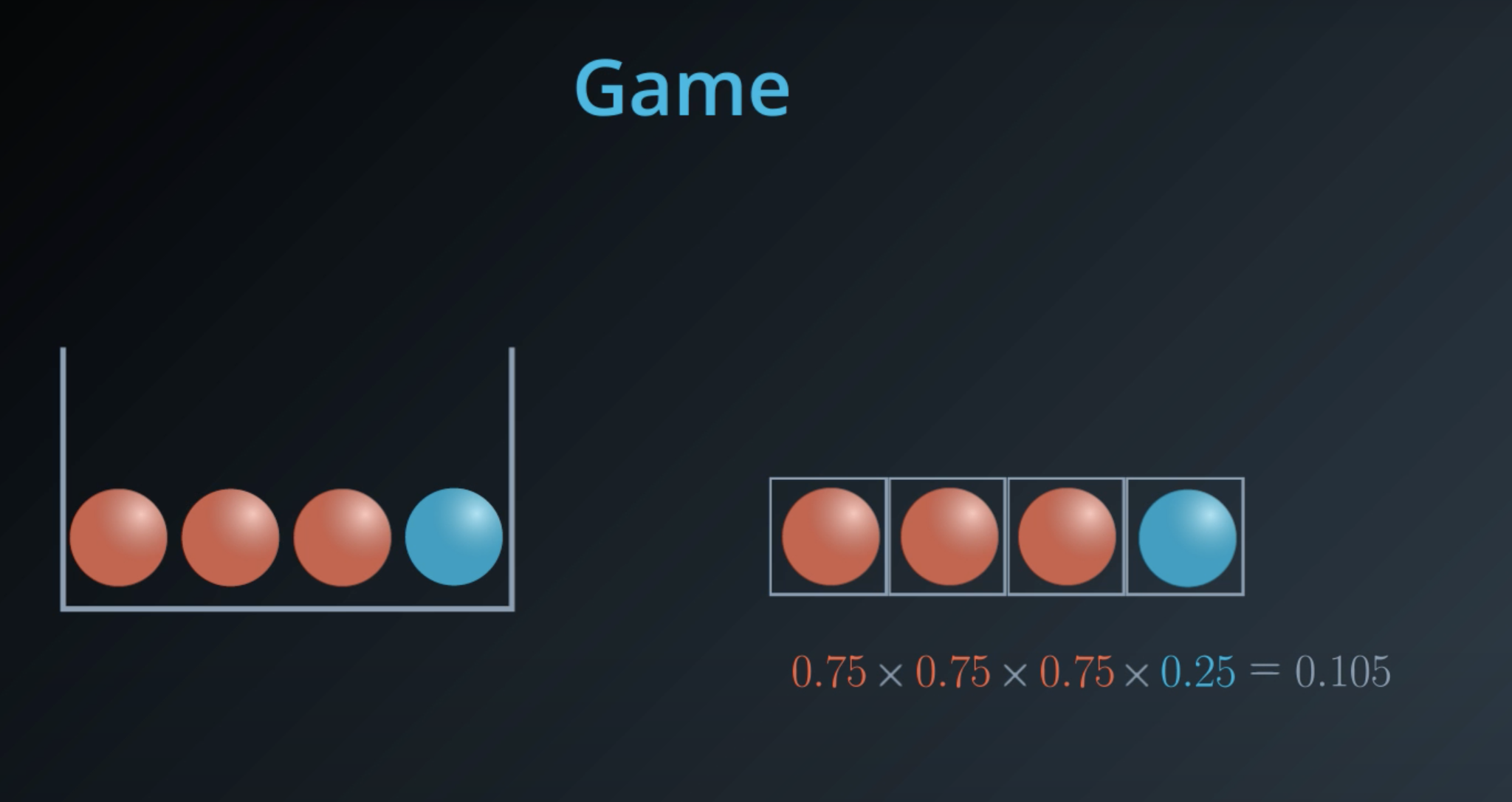
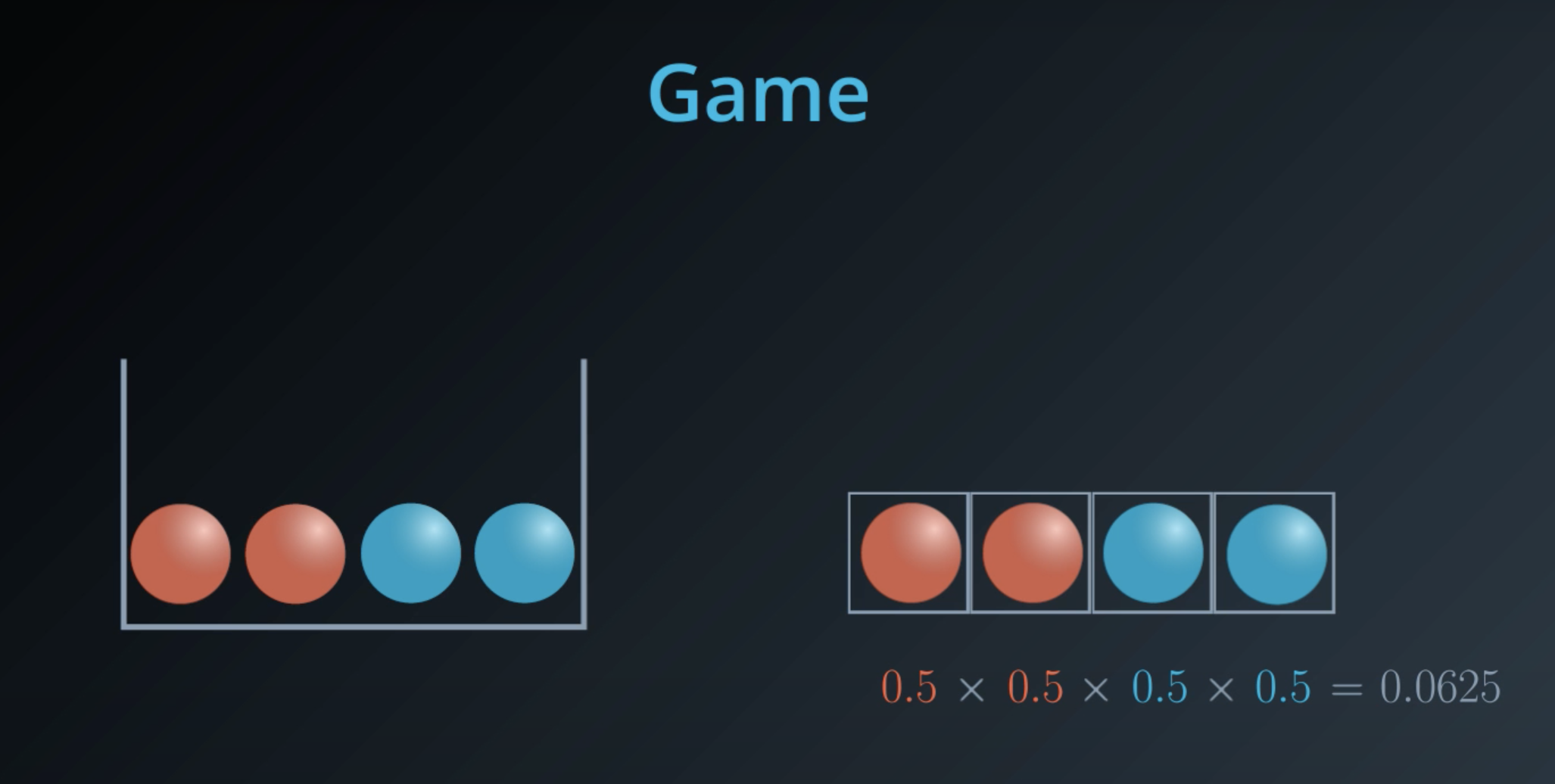
Instead of multiplying the probabilities, we will take their
log(it is computationaly cheaper) -
log(ab) = log(a) + log(b) -
Since the
logvalues are negative, we will make sure we take the negativelogof those probabilities -
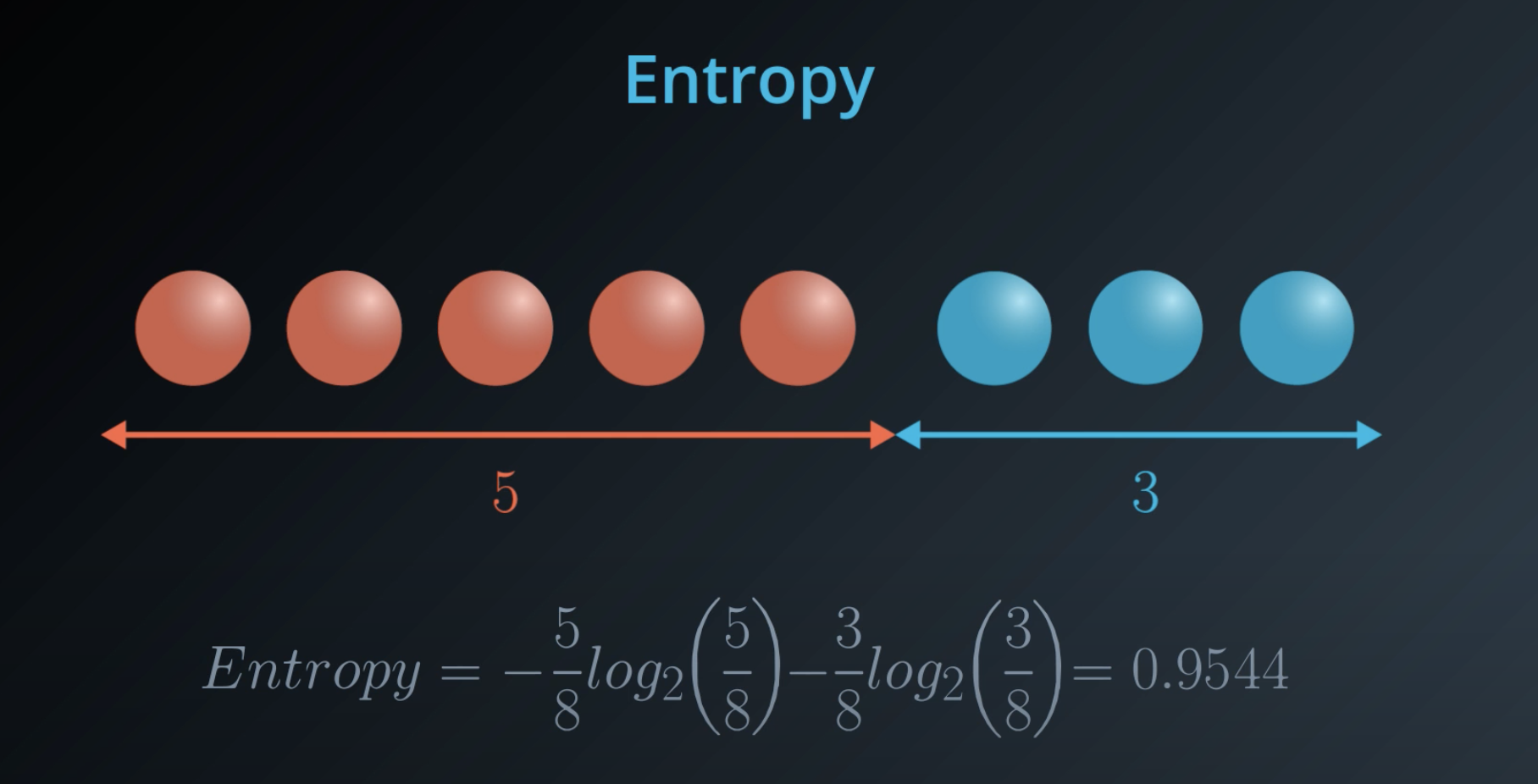
-
5 times the probability of red balls, plus 3 times the probability of blue balls
-

- This is a general formula for entropy when we have 2 colors (2 types)
-
Last time, you saw this equation for entropy for a bucket with mm red balls and nn blue balls:
-
We can state this in terms of probabilities instead for the number of red balls as p_1 and the number of blue balls as p_2:
-
-
This entropy equation can be extended to the multi-class case, where we have three or more possible values:
-
The minimum value is still 0, when all elements are of the same value. The maximum value is still achieved when the outcome probabilities are the same, but the upper limit increases with the number of different outcomes. (For example, you can verify the maximum entropy is 2 if there are four different possibilities, each with probability 0.25.)
-
-
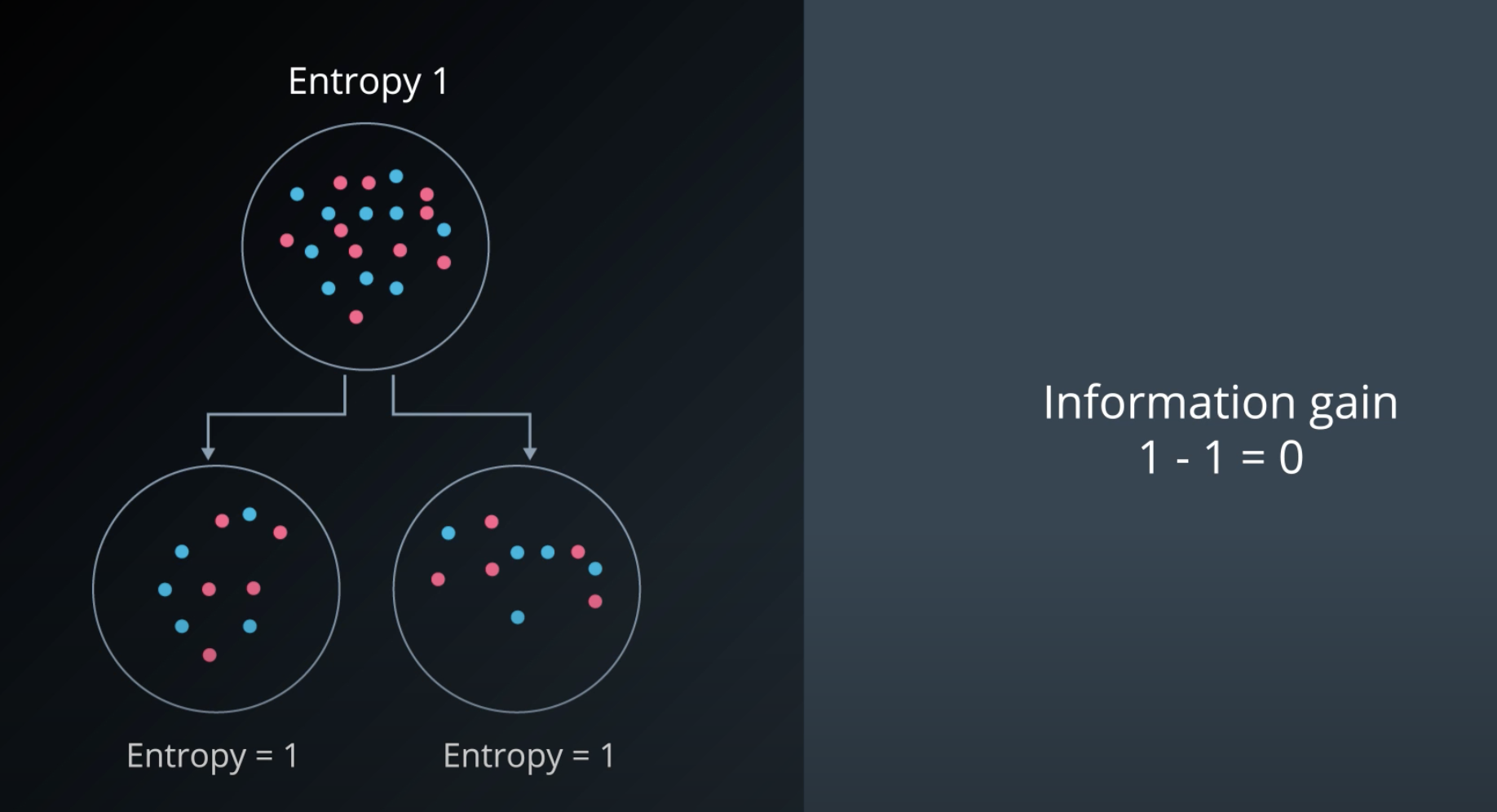
Information Gain
-
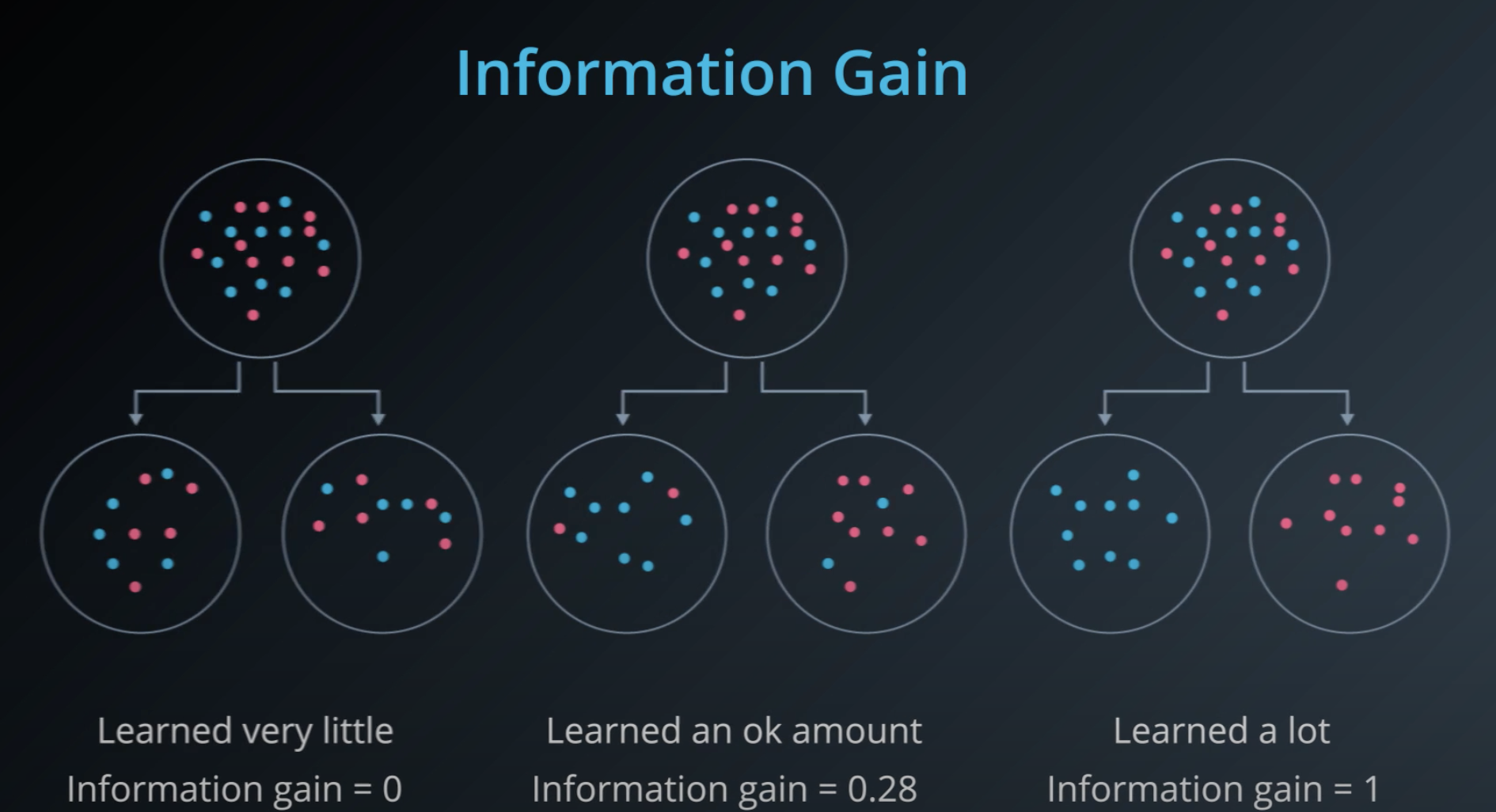
-
Information gain = Change in entropy
-
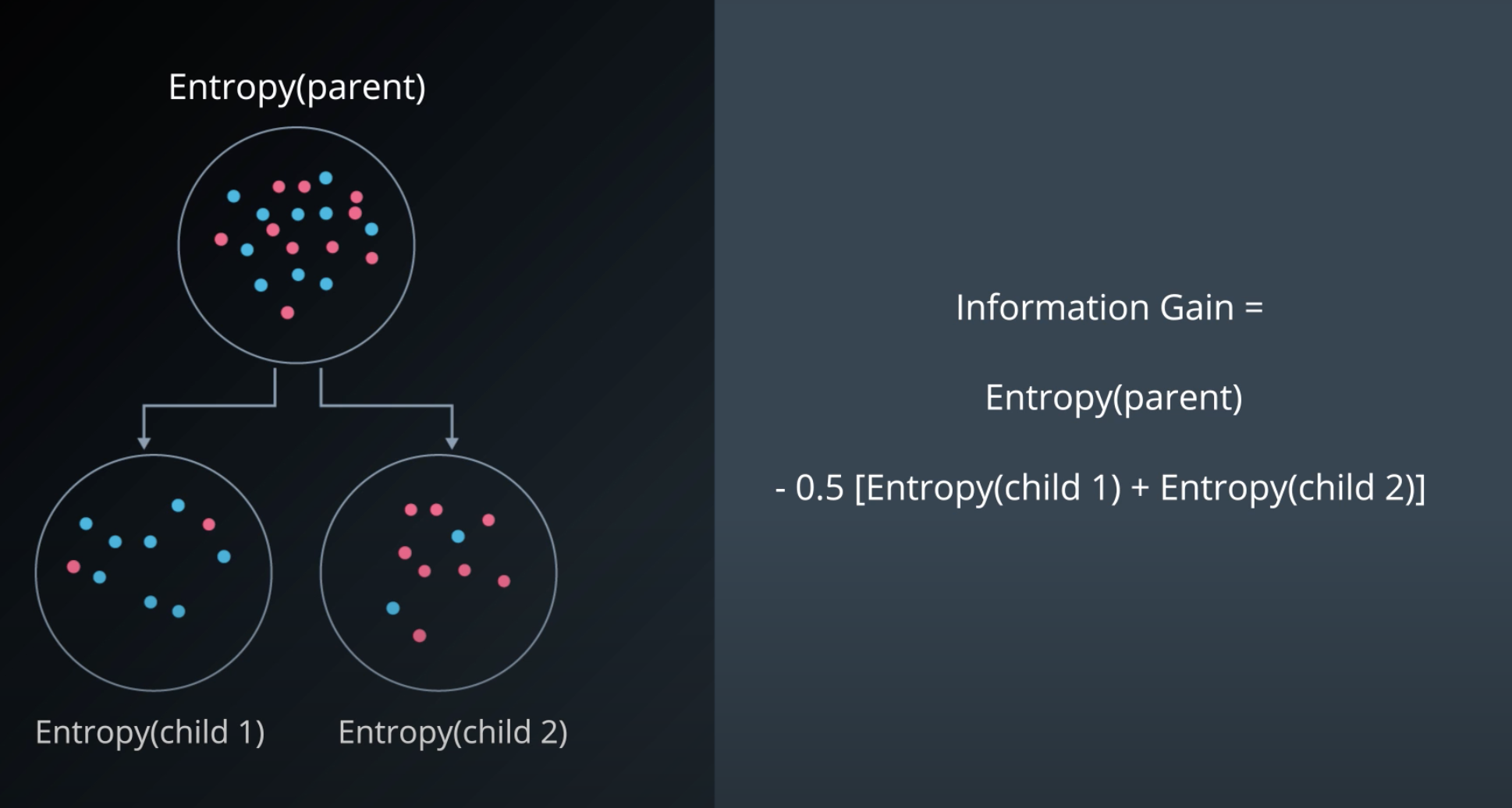
-
To calculate Information Gain we first check the entropy of the parent, then we subtracts by the average entropy of the children
-

-
-
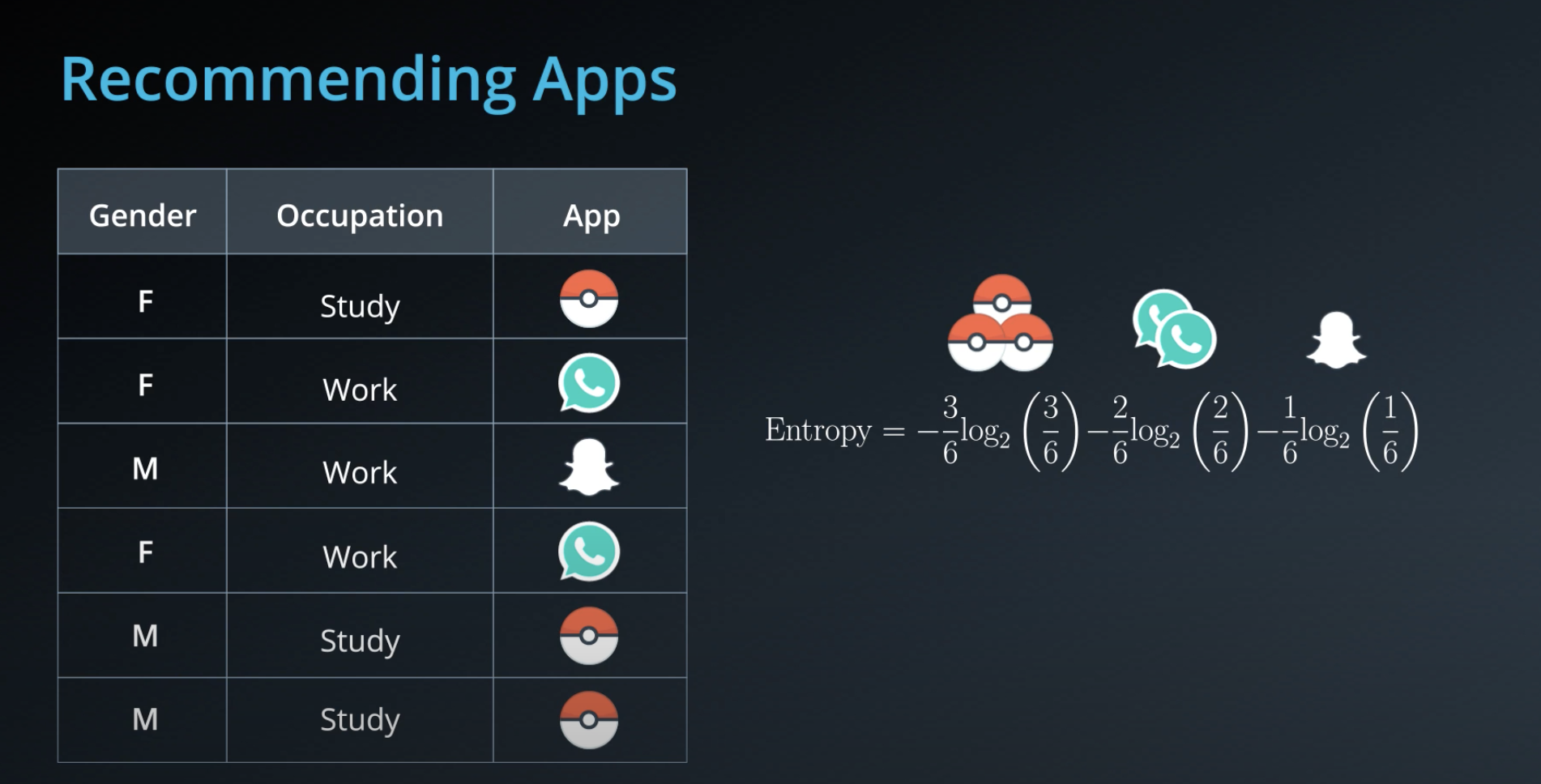
- Calculating entropy for the "app" property
-

-
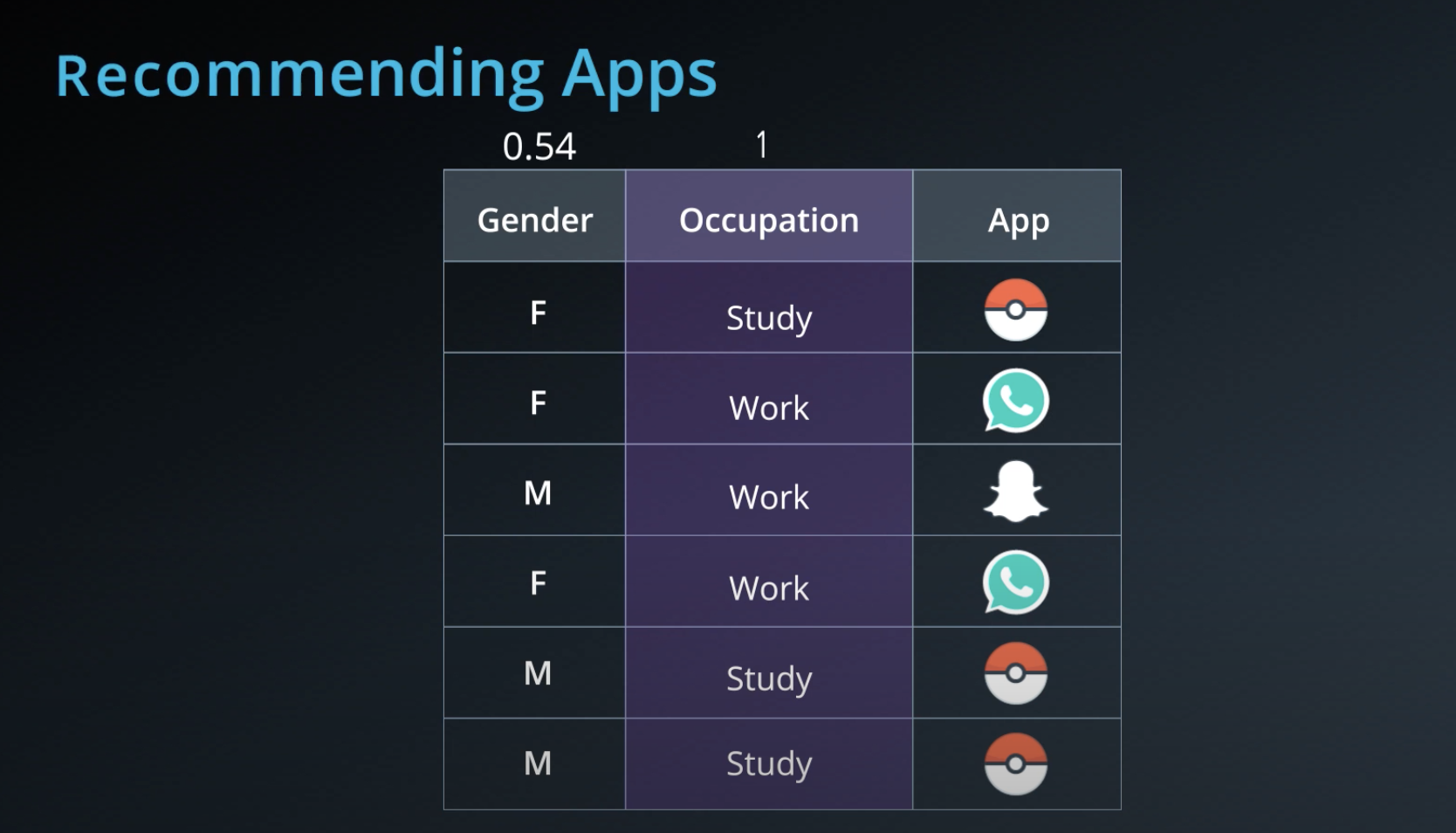
- The algorithm selects the column with highest information gain, in this case "Question"
-
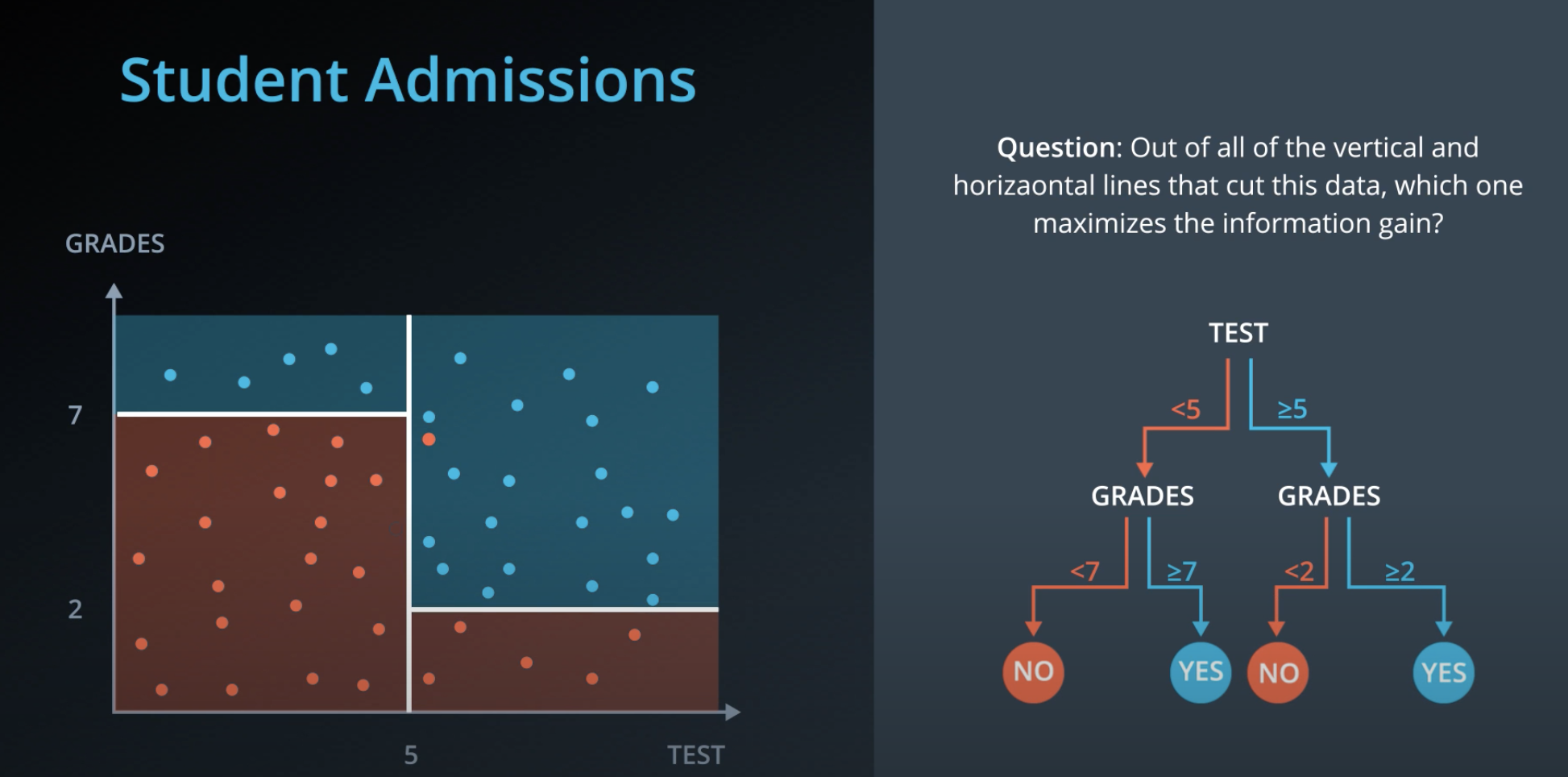
- We can also use decision trees with continuos data
-
-
Hyperparameters for Decision Trees
-
In order to create decision trees that will generalize to new problems well, we can tune a number of different aspects about the trees. We call the different aspects of a decision tree "hyperparameters". These are some of the most important hyperparameters used in decision trees:
-
Maximum Depth
-
The maximum depth of a decision tree is simply the largest possible length between the root to a leaf. A tree of maximum length kk can have at most 2^k2 k leaves.
-
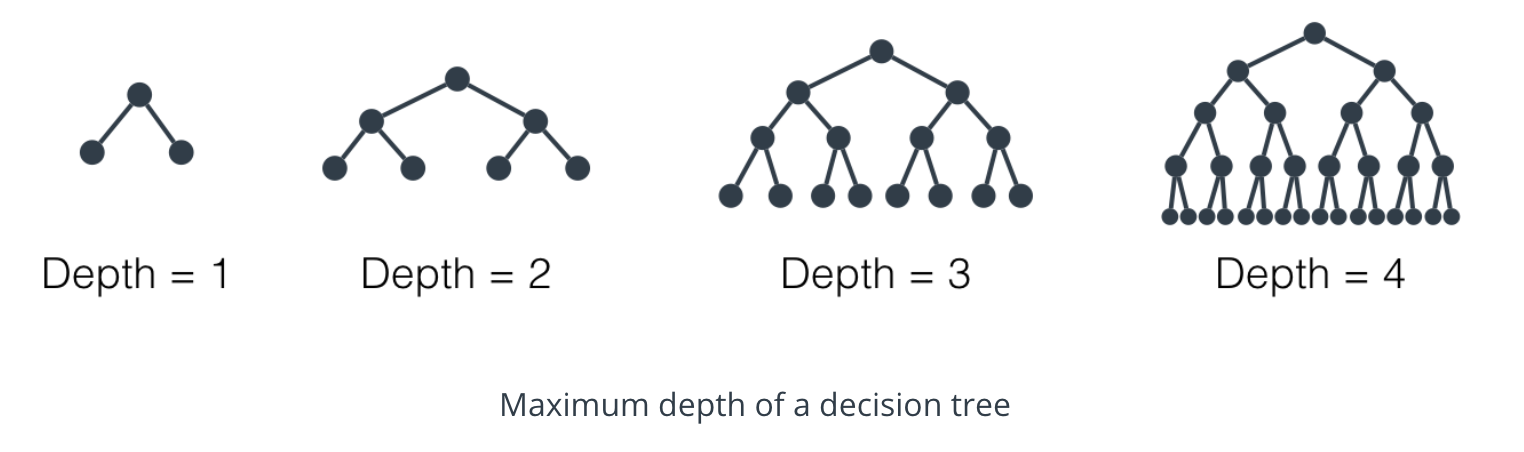
-
-
Minimum number of samples to split
-
A node must have at least
min_samples_splitsamples in order to be large enough to split. If a node has fewer samples thanmin_samples_splitsamples, it will not be split, and the splitting process stops. -
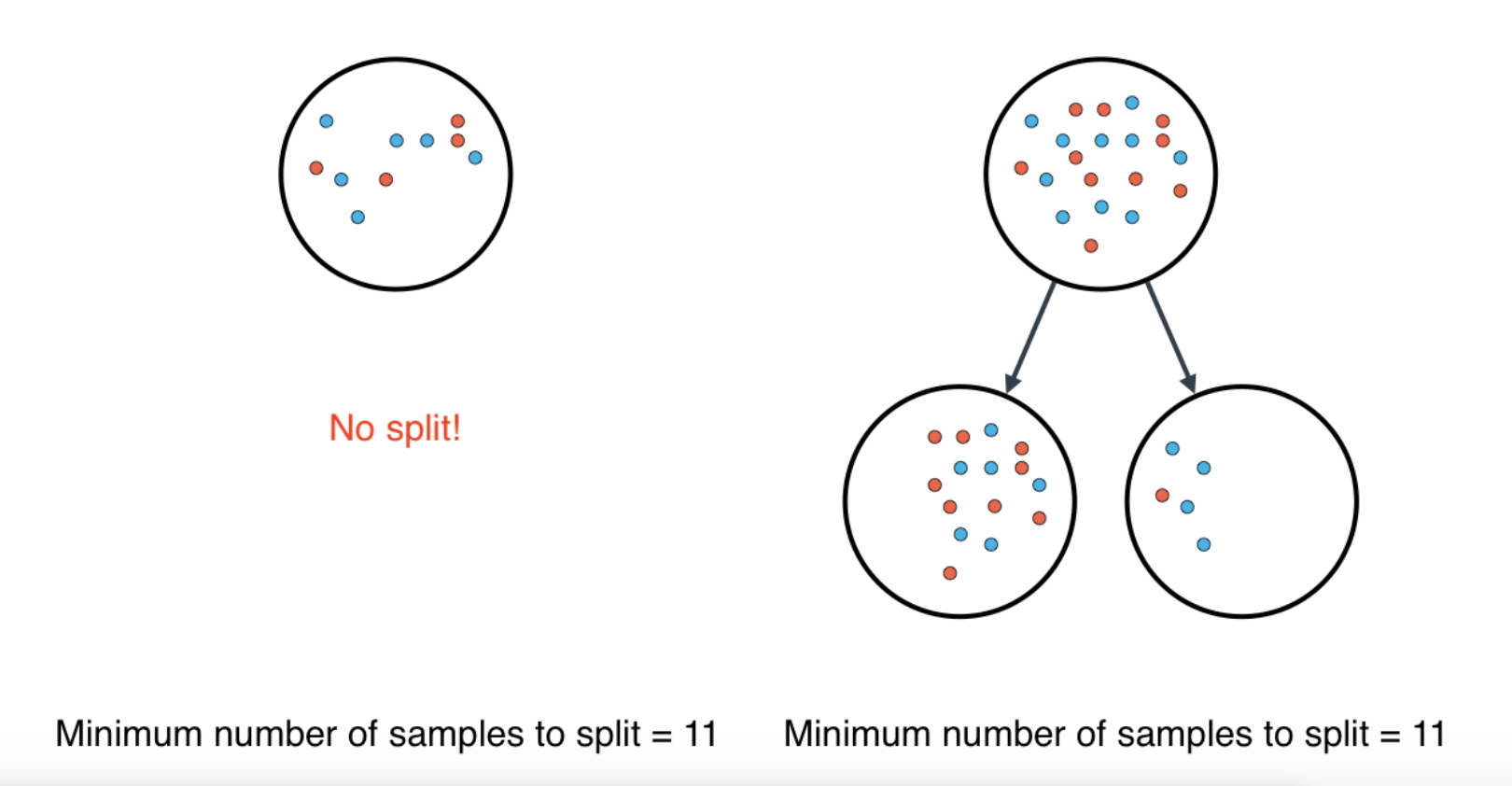
-
However,
min_samples_splitdoesn't control the minimum size of leaves. As you can see in the example on the right, above, the parent node had 20 samples, greater thanmin_samples_split = 11, so the node was split. But when the node was split, a child node was created with that had 5 samples, less thanmin_samples_split = 11.
-
-
Minimum number of samples per leaf
-
When splitting a node, one could run into the problem of having 99 samples in one of them, and 1 on the other. This will not take us too far in our process, and would be a waste of resources and time. If we want to avoid this, we can set a minimum for the number of samples we allow on each leaf.
-
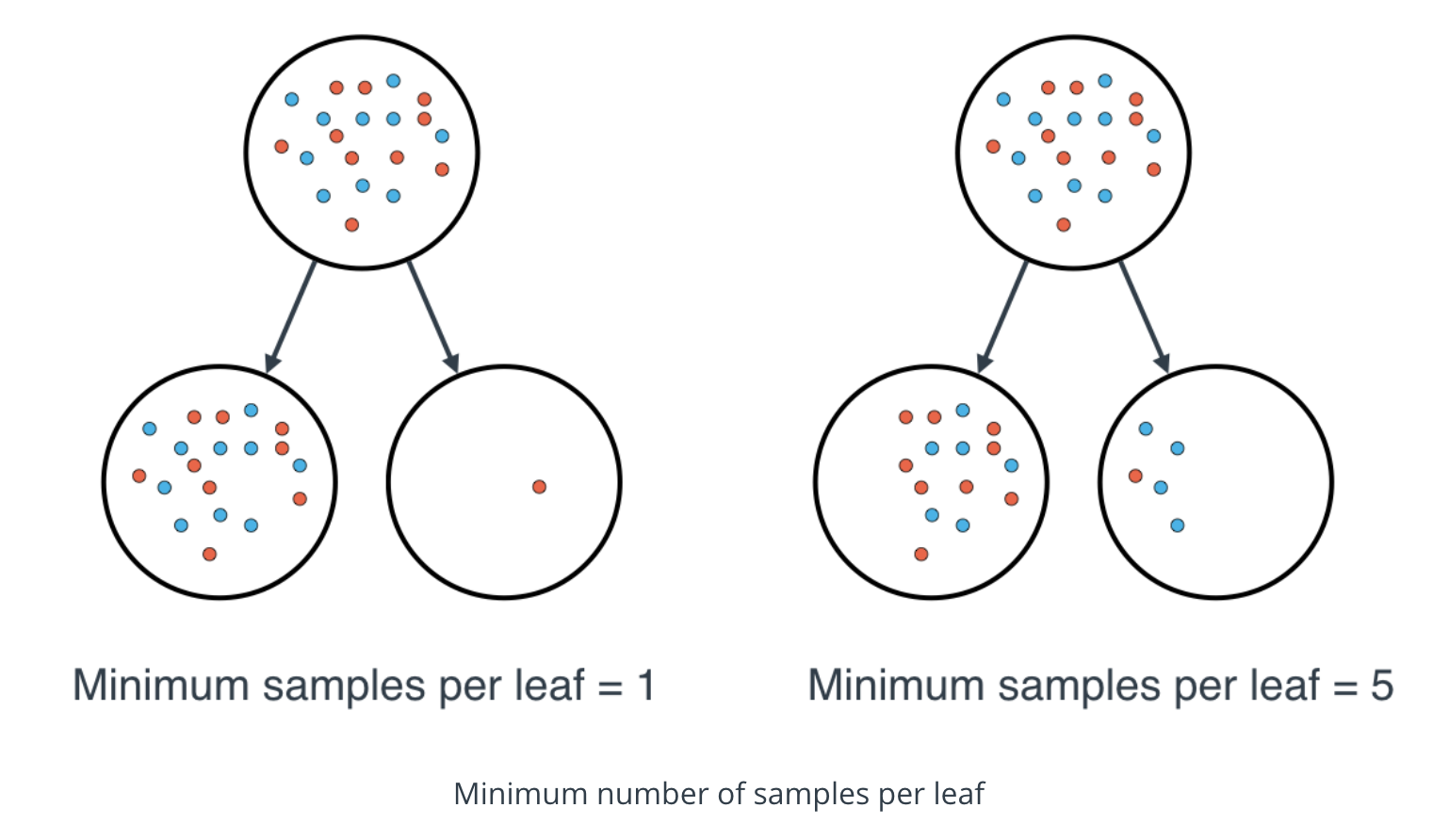
-
This number can be specified as an integer or as a float. If it's an integer, it's the minimum number of samples allowed in a leaf. If it's a float, it's the minimum percentage of samples allowed in a leaf. For example, 0.1, or 10%, implies that a particular split will not be allowed if one of the leaves that results contains less than 10% of the samples in the dataset.
-
If a threshold on a feature results in a leaf that has fewer samples than
min_samples_leaf, the algorithm will not allow that split, but it may perform a split on the same feature at a different threshold, that does satisfymin_samples_leaf.
-
-
Large depth very often causes overfitting, since a tree that is too deep, can memorize the data. Small depth can result in a very simple model, which may cause underfitting.
-
Small minimum samples per split may result in a complicated, highly branched tree, which can mean the model has memorized the data, or in other words, overfit. Large minimum samples may result in the tree not having enough flexibility to get built, and may result in underfitting.
-
-
Decision Trees in sklearn
-
sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.fit(x_values, y_values)
-
In the example above, the
modelvariable is a decision tree model that has been fitted to the datax_valuesandy_values. Fitting the model means finding the best tree that fits the training data. Let's make two predictions using the model's predict() function. -
print(model.predict([ [0.2, 0.8], [0.5, 0.4] ])) [[ 0., 1.]]
-
The model returned an array of predictions, one prediction for each input array. The first input,
[0.2, 0.8], got a prediction of0.. The second input,[0.5, 0.4], got a prediction of1..
-
-
Hyperparameters
-
When we define the model, we can specify the hyperparameters. In practice, the most common ones are
max_depth: The maximum number of levels in the tree.min_samples_leaf: The minimum number of samples allowed in a leaf.min_samples_split: The minimum number of samples required to split an internal node.
-
For example, here we define a model where the maximum depth of the trees
max_depthis 7, and the minimum number of elements in each leafmin_samples_leafis 10.model = DecisionTreeClassifier(max_depth = 7, min_samples_leaf = 10)
-
-
Decision Tree Quiz
-
In this quiz, you'll be given the following sample dataset, and your goal is to define a model that gives 100% accuracy on it.
-
Also check the
decision_tree_labfor more examples -
# Import statements from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score import pandas as pd import numpy as np # Read the data. data = np.asarray(pd.read_csv('data.csv', header=None)) # Assign the features to the variable X, and the labels to the variable y. X = data[:,0:2] y = data[:,2] # TODO: Create the decision tree model and assign it to the variable model. model = DecisionTreeClassifier() # TODO: Fit the model. model.fit(X,y) # TODO: Make predictions. Store them in the variable y_pred. y_pred = model.predict(X) # TODO: Calculate the accuracy and assign it to the variable acc. acc = accuracy_score(y, y_pred)
-
Note: This quiz requires you to find an accuracy of 100% on the training set. This is like memorizing the training data! A model designed to have 100% accuracy on training data is unlikely to generalize well to new data. If you pick very large values for your parameters, the model will fit the training set very well, but may not generalize well. Try to find the smallest possible parameters that do the job—then the model will be more likely to generalize well. (This aspect of the exercise won't be graded.)
-
-

























-
Naive Bayes
-

-

-
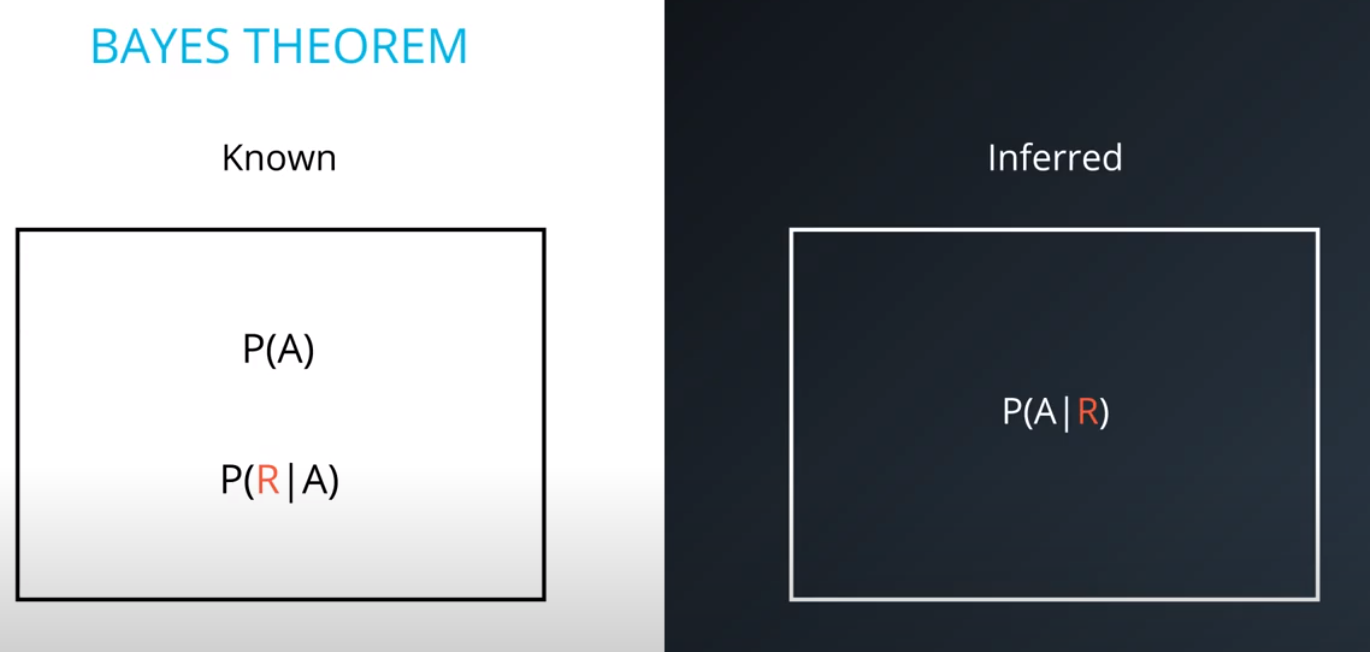
-

-

-

-
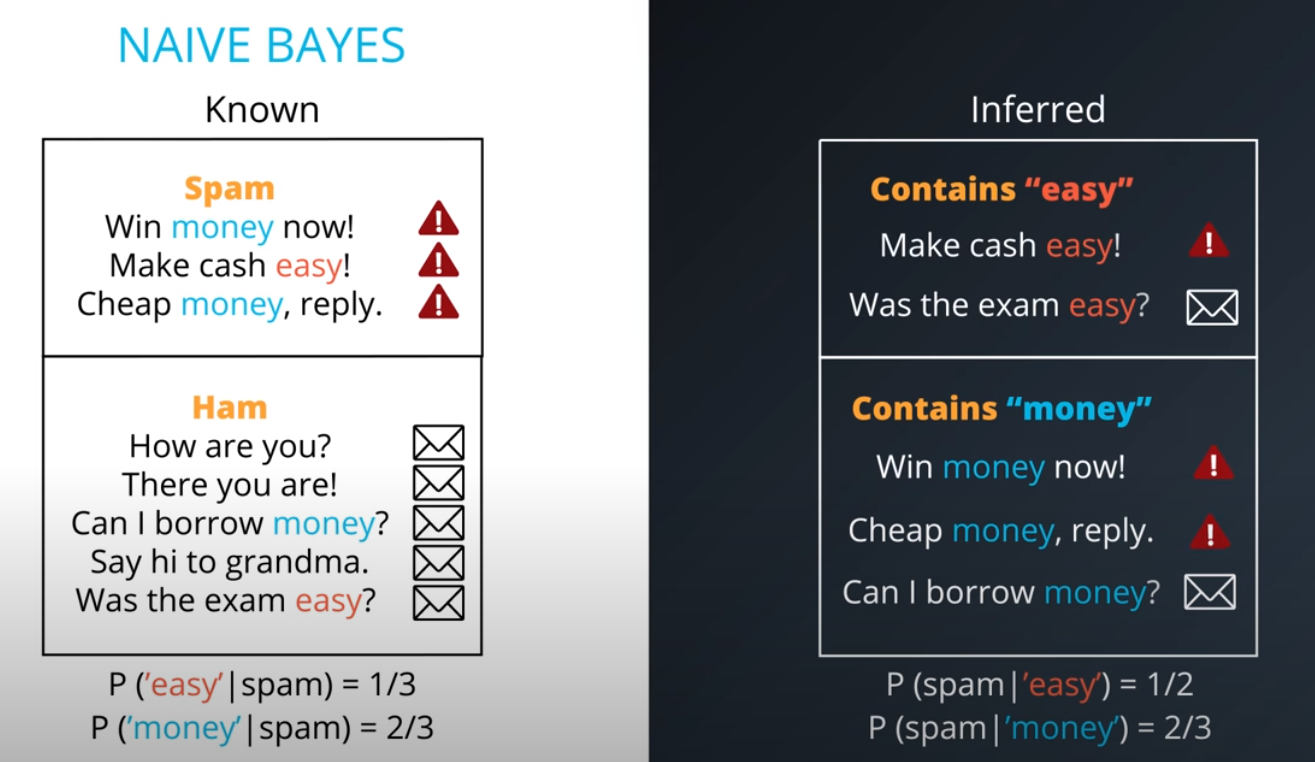
Prior = Known
-
Posterior = Inferred (after we knew R occurred)
-
It is composed of a prior(the probabilities that we are aware of or that is given to us) and the posterior(the probabilities we are looking to compute using the priors).
-
-

- The formula for bayes theorem
-

-

-
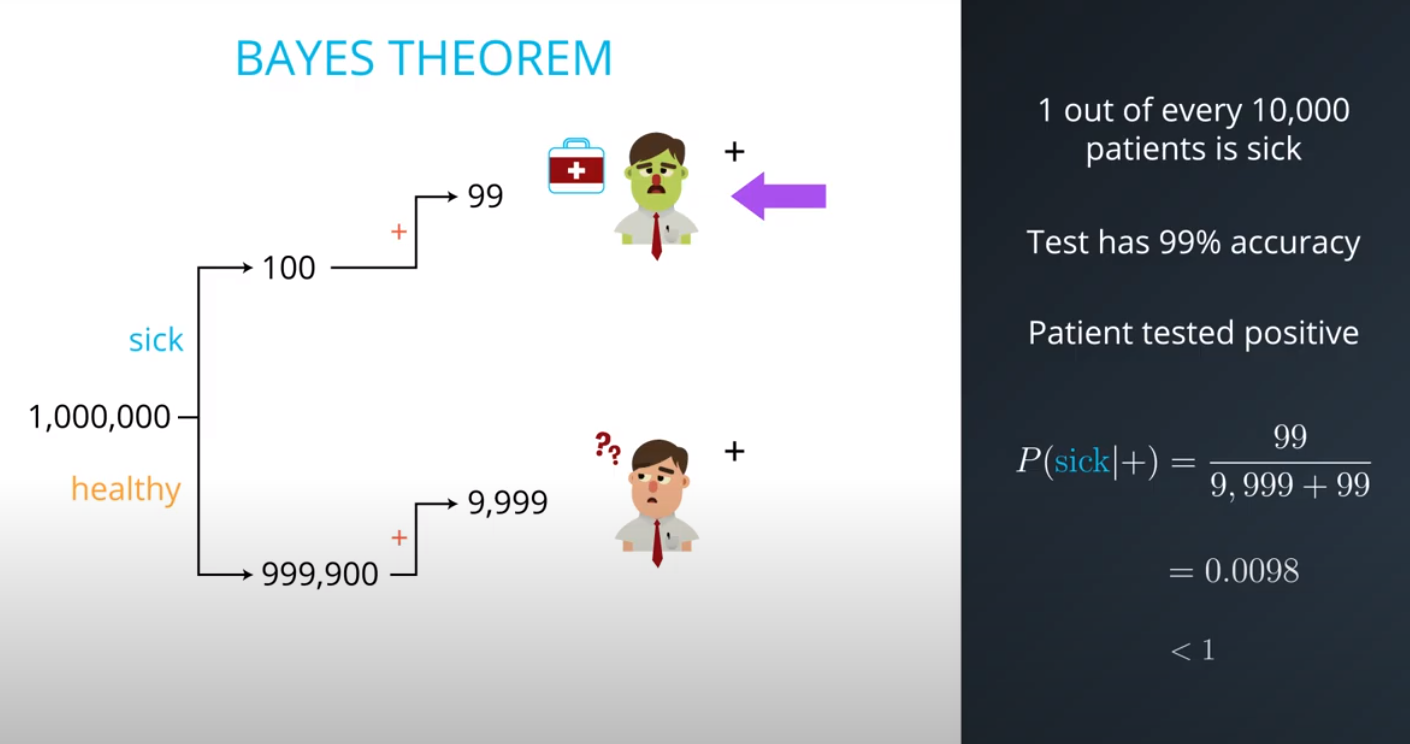
-
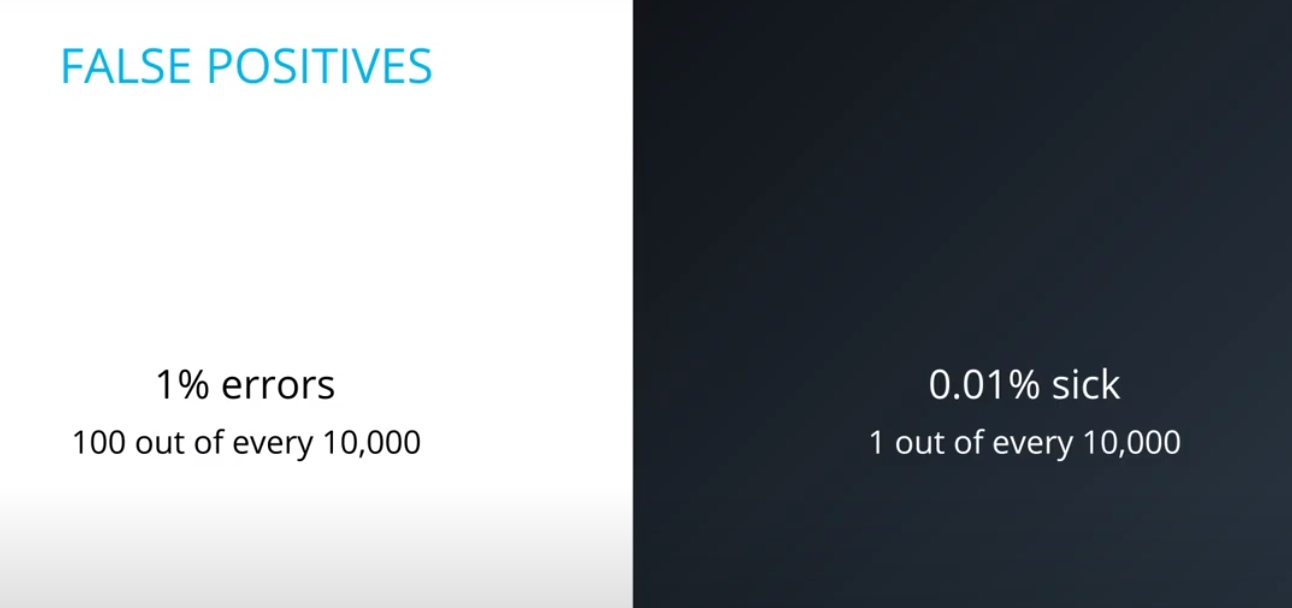
- Although you tested positively, it is more probable (100x to be more exact) that you are among the 100 out of every 10,000 (bad test) then the 1 out of every 10,000 (sick population)
- This is an example of a false positive
-

-
-
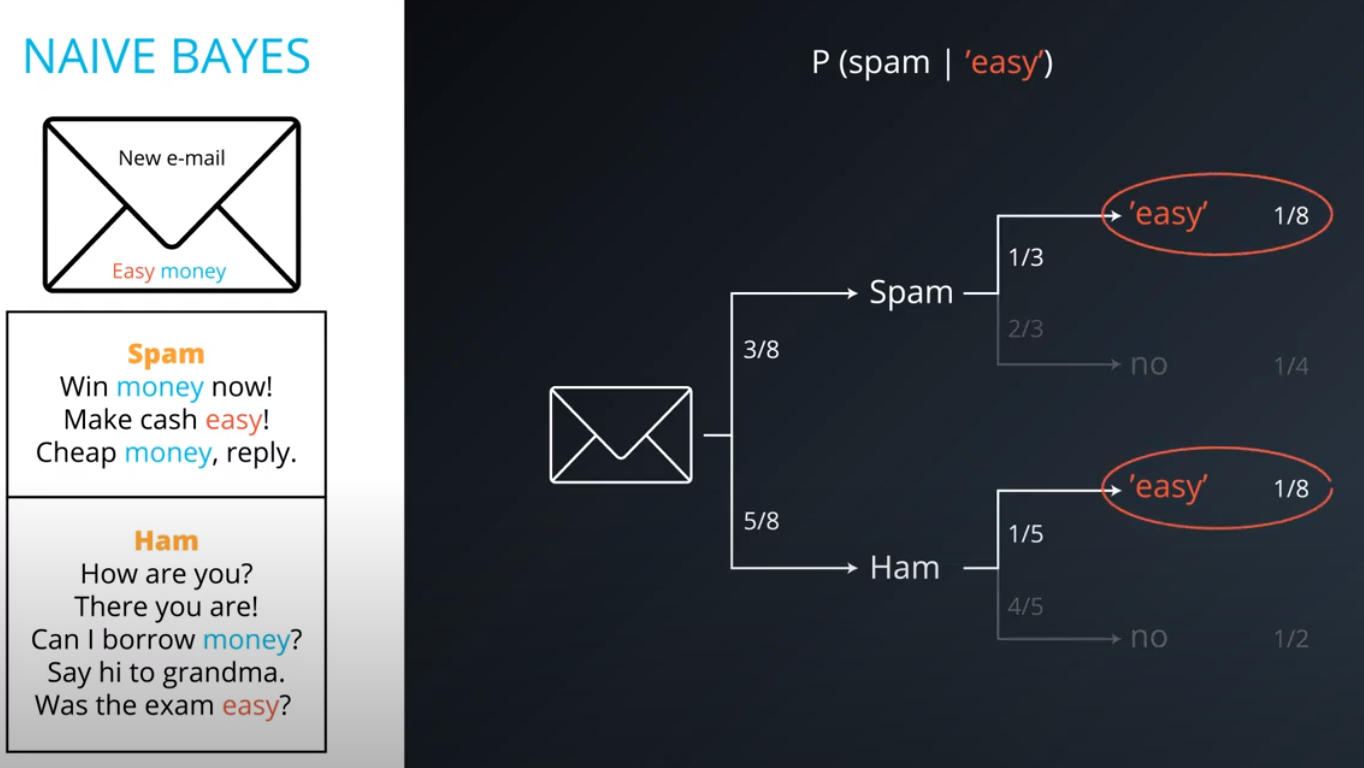
-
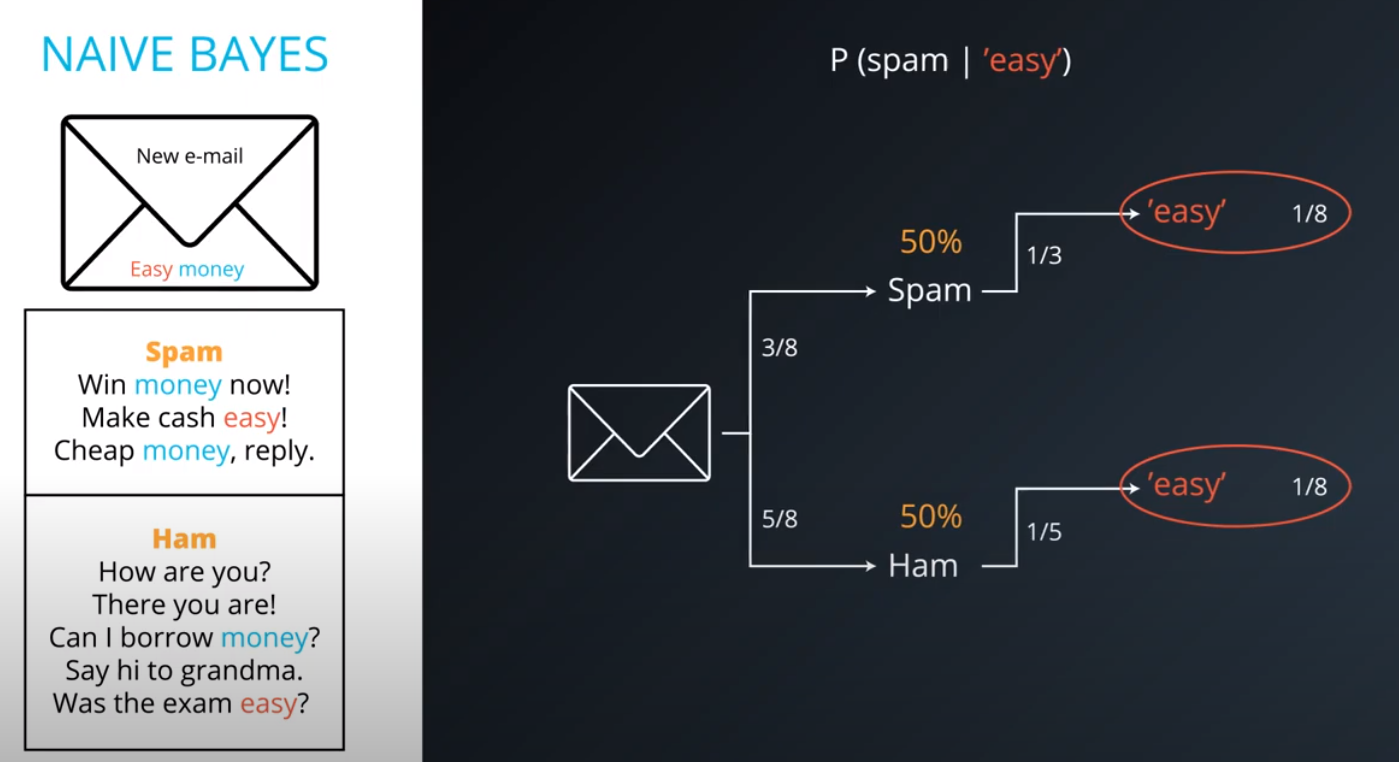
-
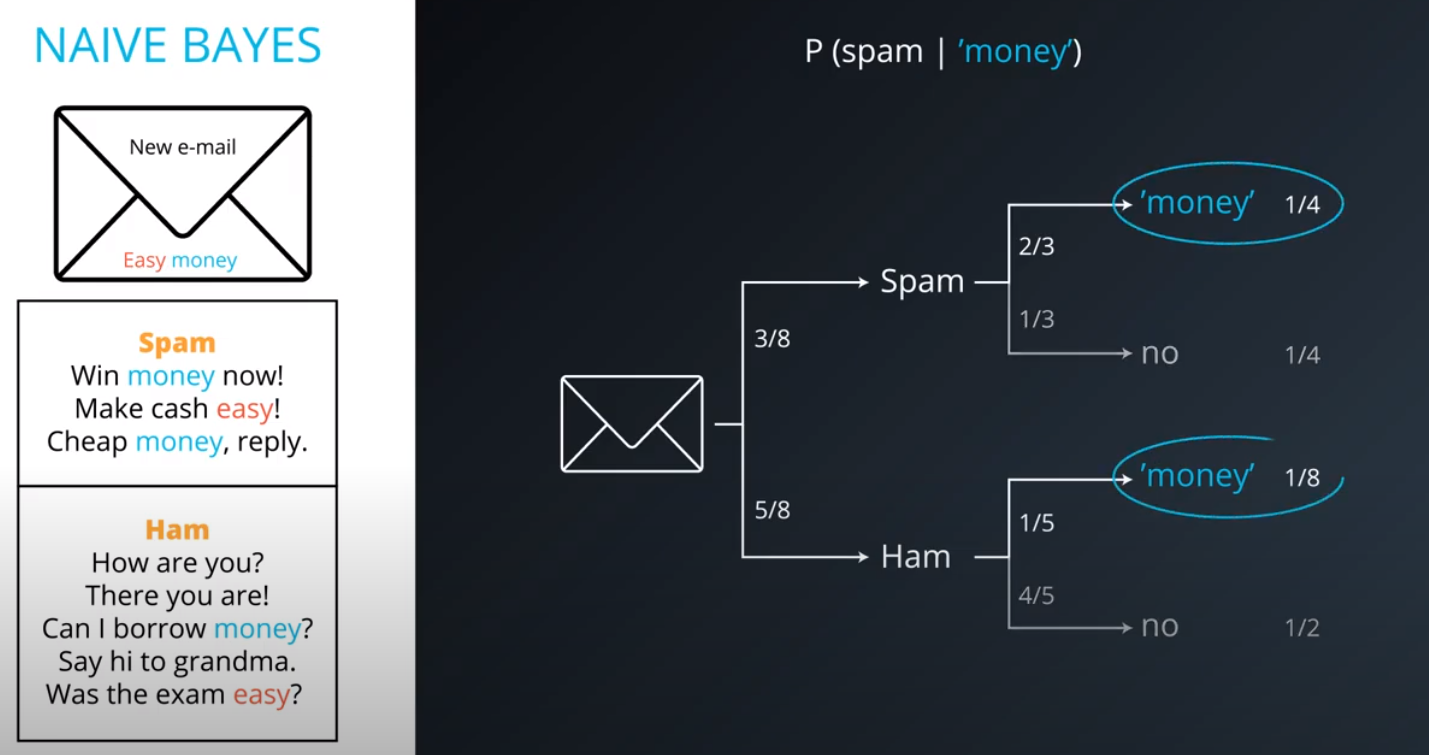
-
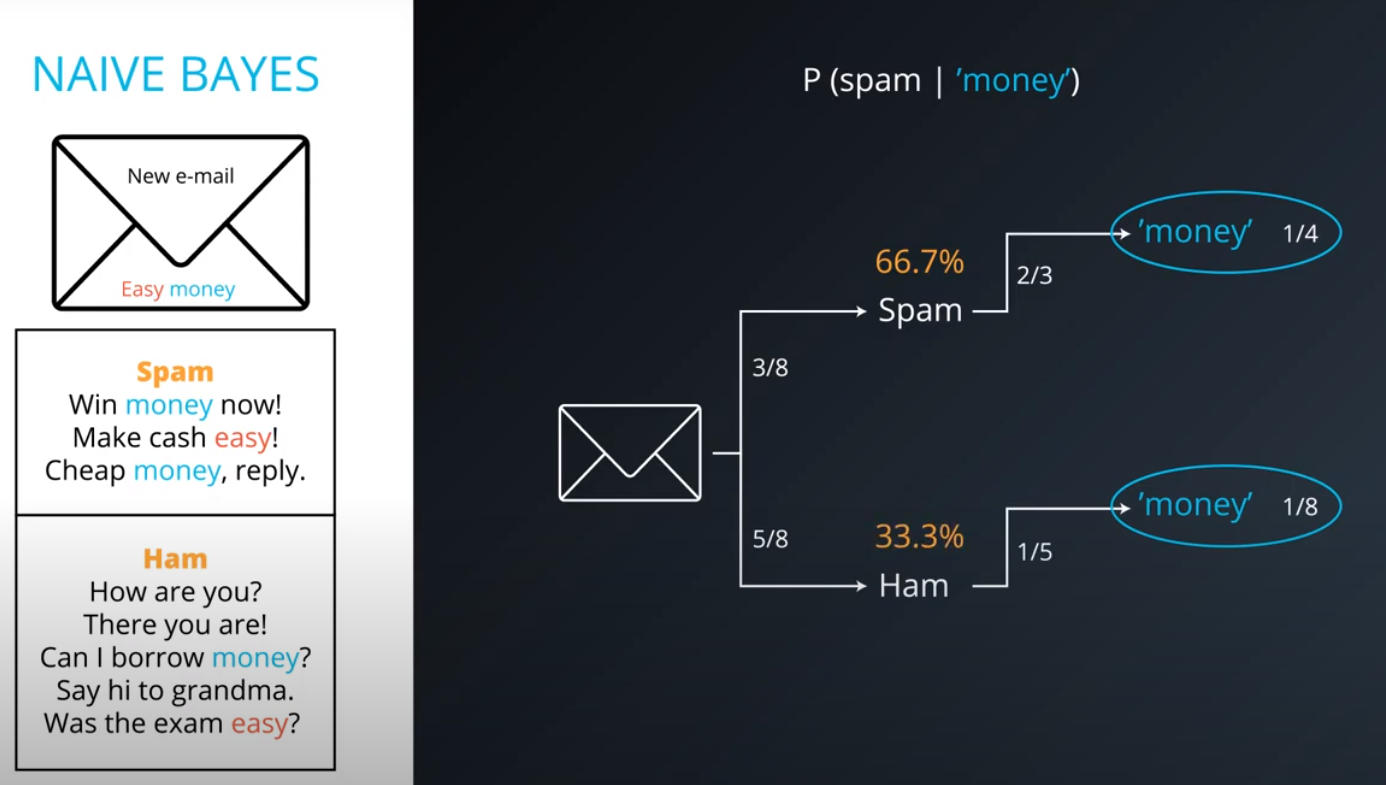
- This are the posteriors
-

- The "naive" in "Naive Bayes" comes from an assumption that events wont be dependent. An example of dependent events is if
P(A)is the probability of being hot, andP(B)is the probability of being cold.
- The "naive" in "Naive Bayes" comes from an assumption that events wont be dependent. An example of dependent events is if
-

-

-

-

- This values are not the actual probabilities, they are proportional do the actual probabilities
-
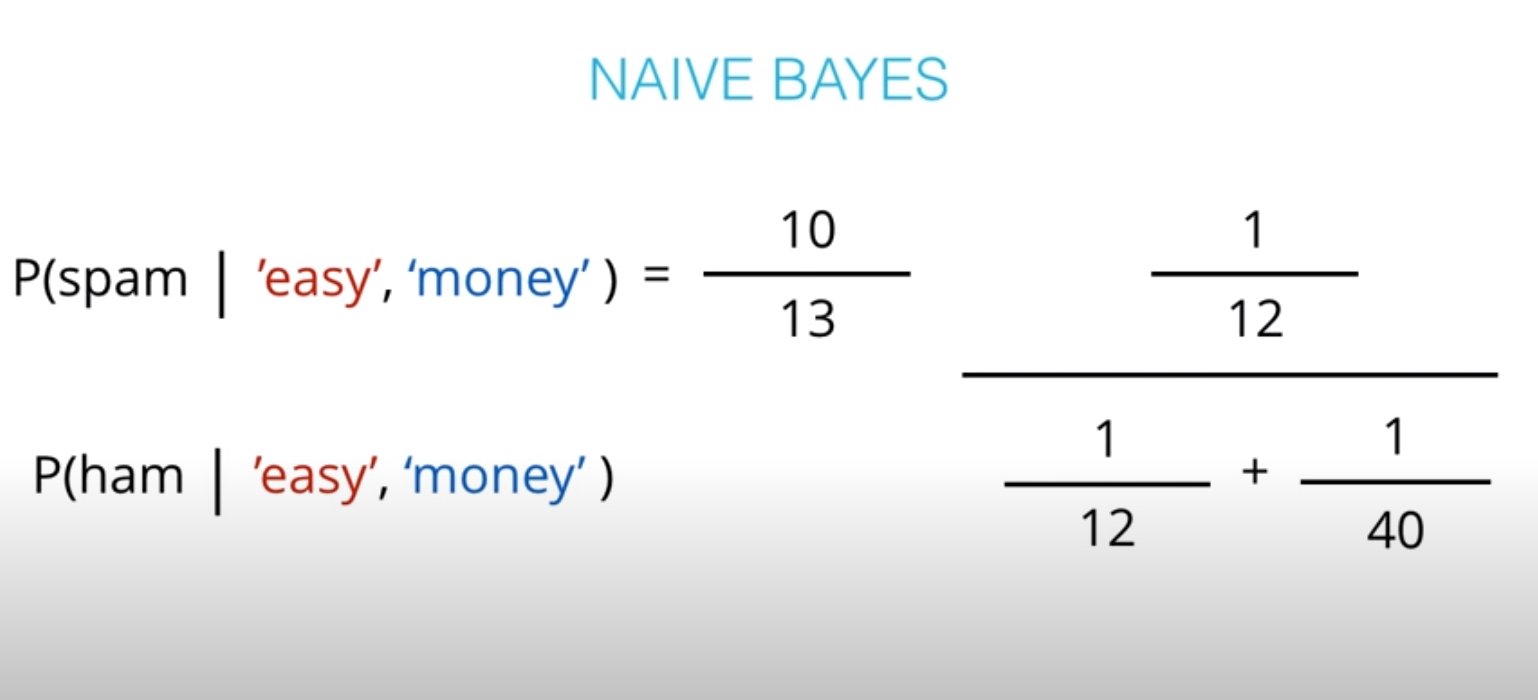
-
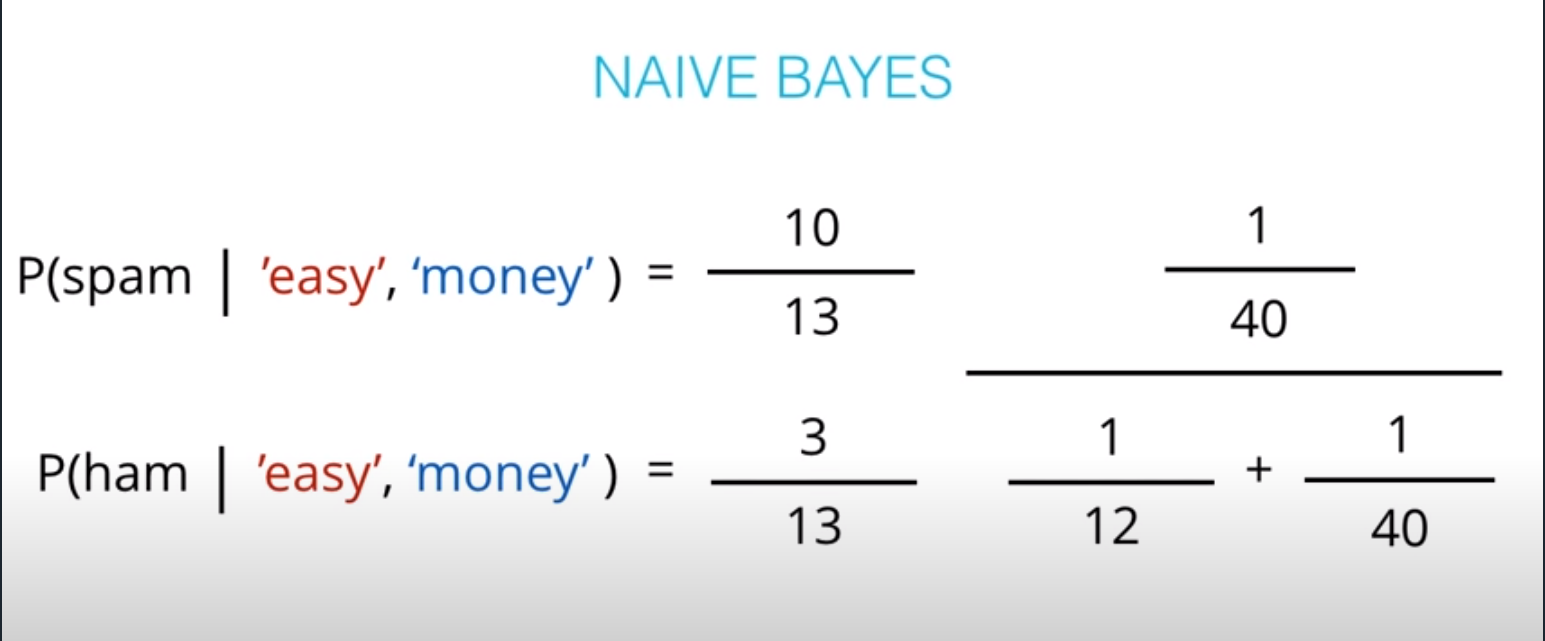
-

-
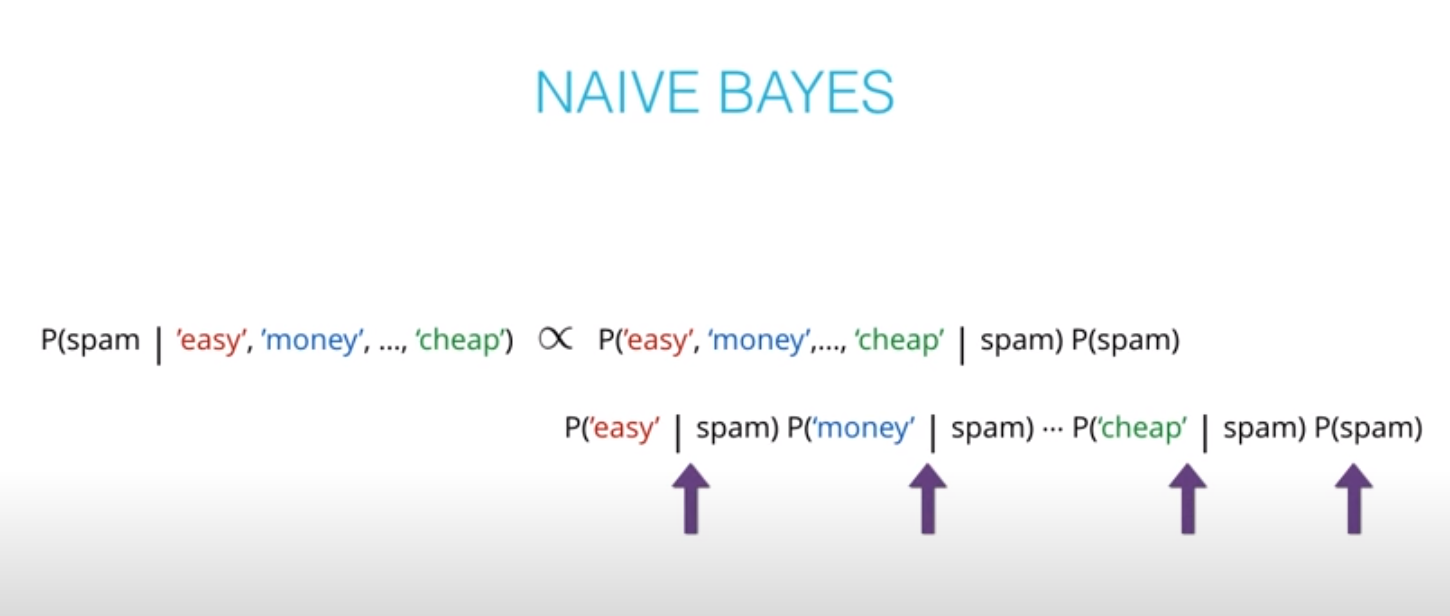
-
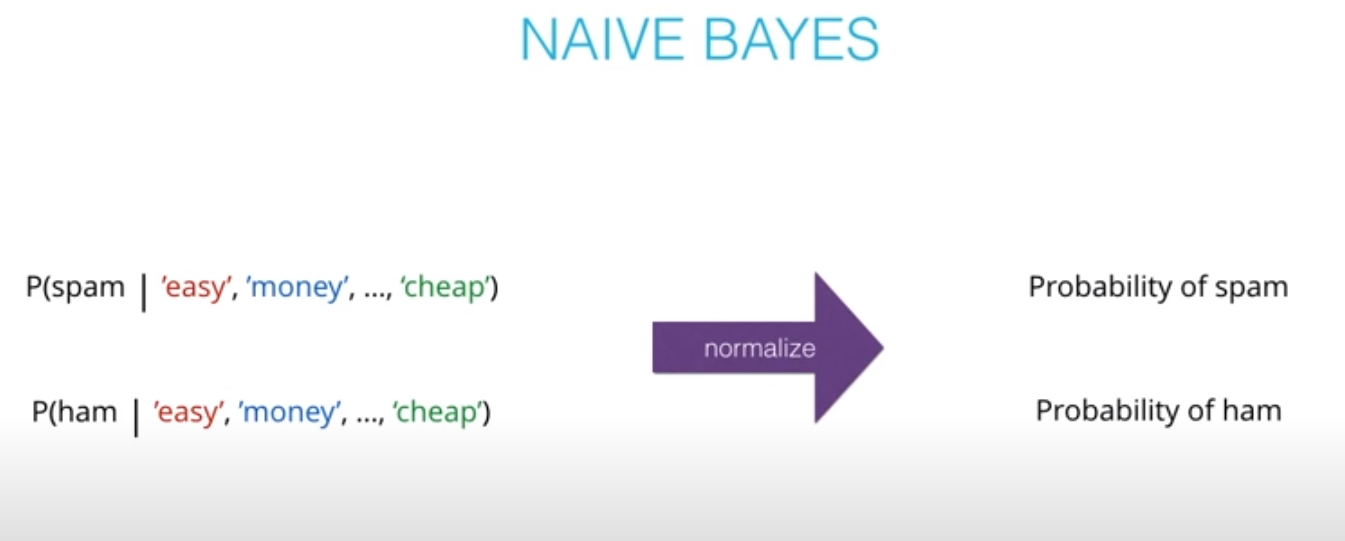
-
Practice Project: Building a spam classifier Introduction
-
Check the
naive_bayes_labfor more examples -
One of the major advantages that Naive Bayes has over other classification algorithms its the ability to handle an extremely large number of features. In our case, each word is treated as a feature and there are thousands of different words. Also, it performs well even with the presence of irrelevant features and is relatively unaffected by them. The other major advantage is its relative simplicity. Naive Bayes' works well right out of the box and tuning it's parameters is rarely ever necessary, except usually in cases where the distribution of the data is known. It rarely ever overfits the data. Another important advantage is that its model training and prediction times are very fast for the amount of data it can handle. All in all, Naive Bayes' really is a gem of an algorithm!
-



























-
Support Vector Machines (SVMs)
-

-

-
Let's recall something we've seen before: The perceptron algorithm. Before, we saw it as a trick in which we started with a random line, and iterated on a step in order to slowly walk the line towards the misclassified points, so we can classify them correctly. However, we can also see this algorithm as an algorithm which minimizes an error function. Here's the way to do this:
-
-
Now with SVM
-
We add a line to separate the points, and two extra lines in parallel to it.
-

- We don't want anything between those two lines. Those points should be consider bad classifications
-

- Now we have error that don't start from the central line, but from the parallel lines (different from the perceptron)
-

-

-

-
The margin is the difference between the two lines
-
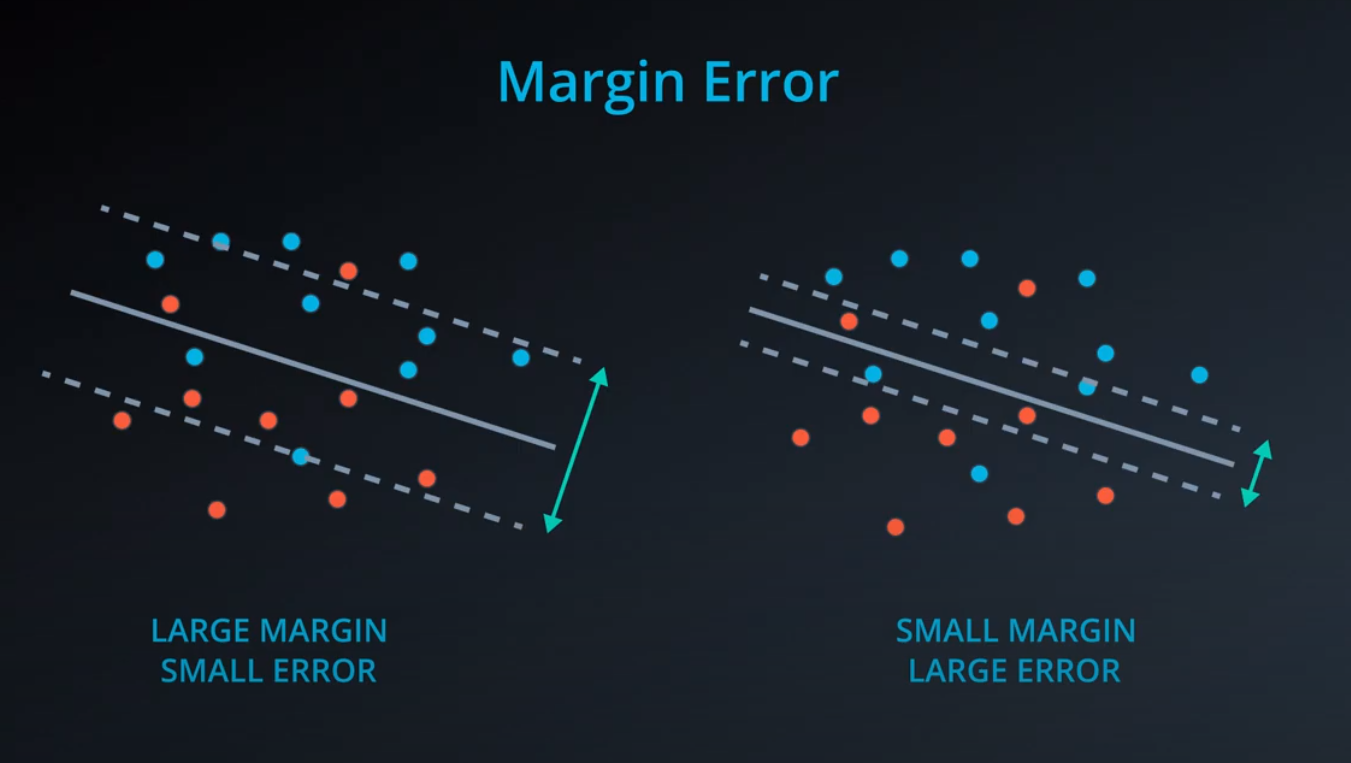
-
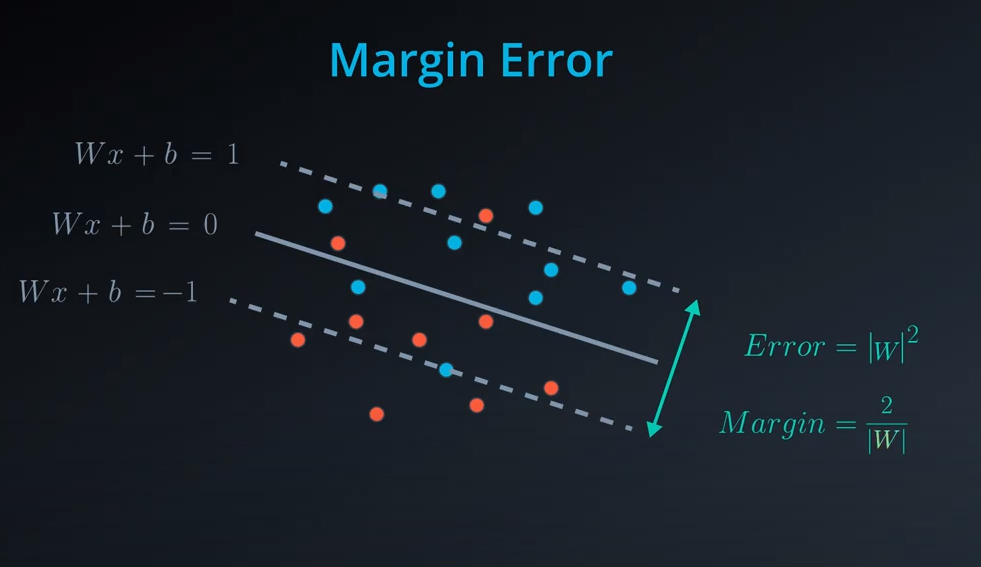
-

- Norm of
|W|is the square of 25 which is 5
- Norm of
-

-
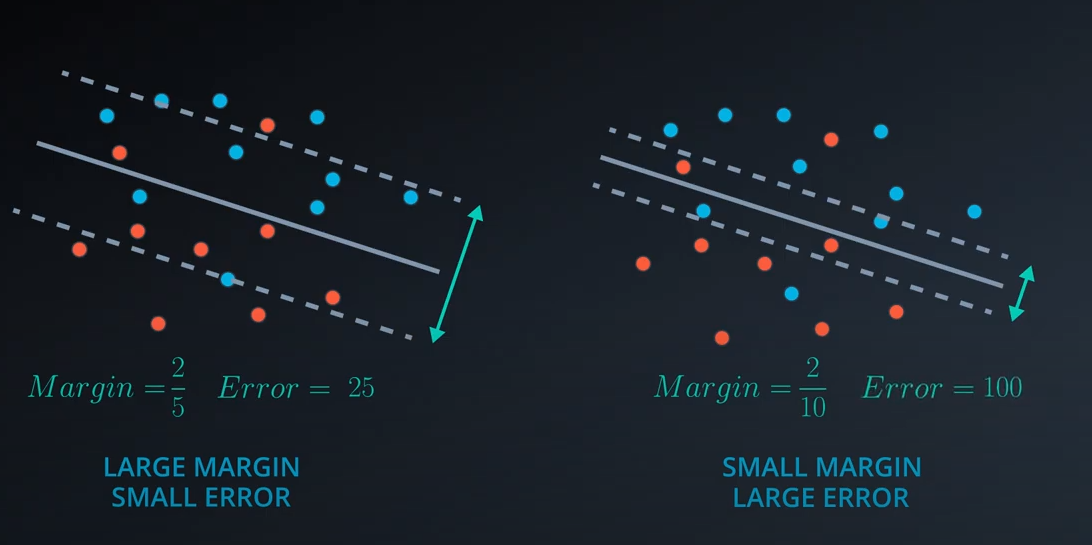
-

-
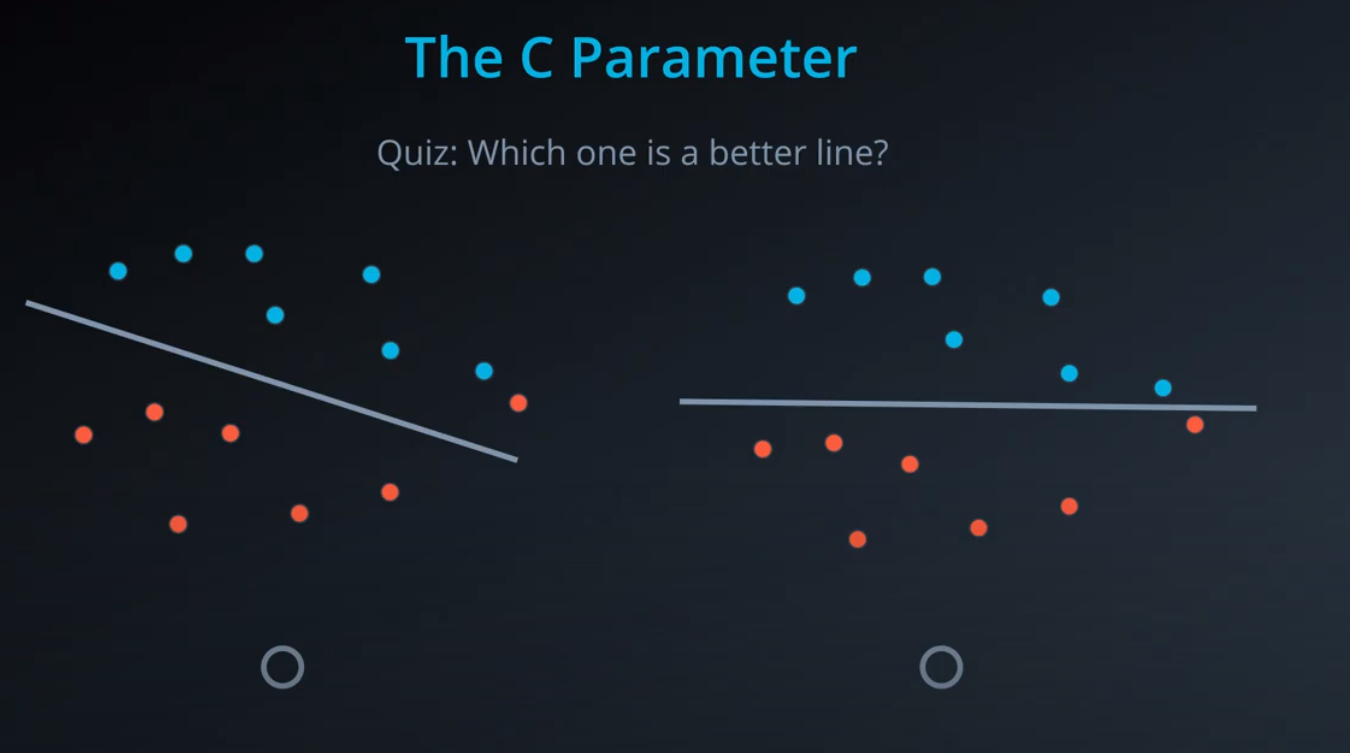
-

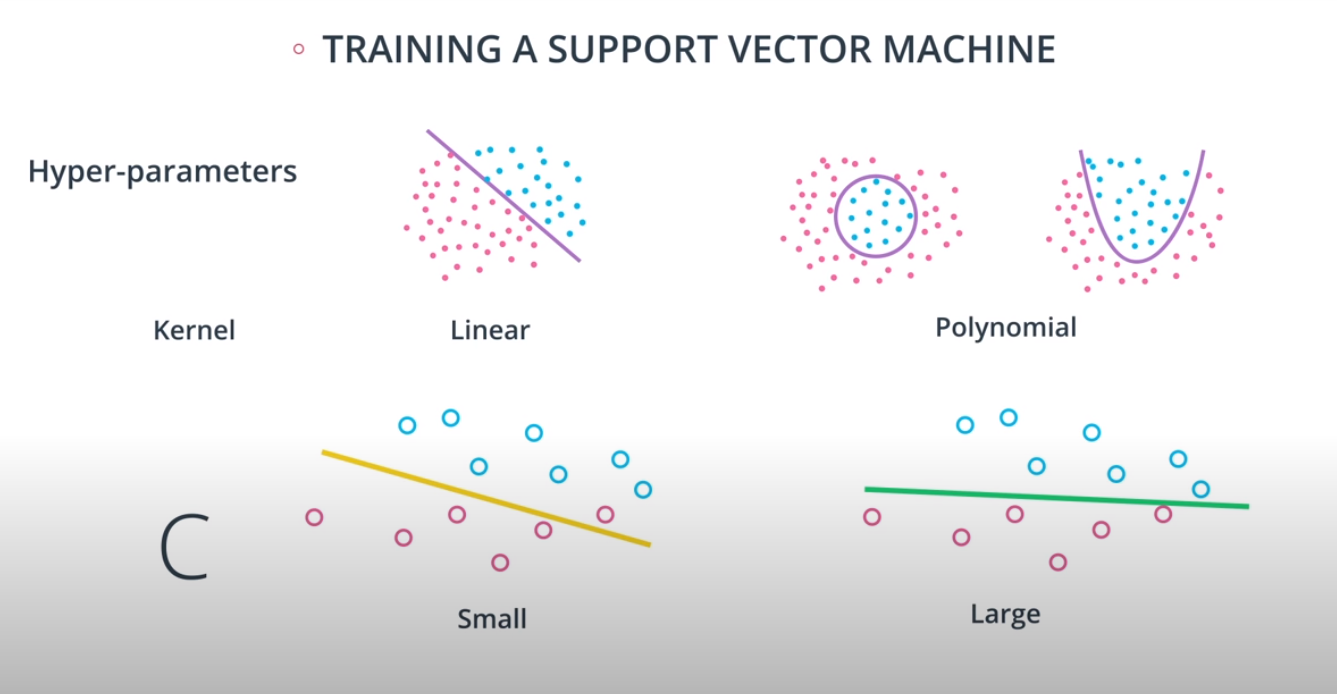
- The C parameter will help us understand if we should focus more on correctly classifying our points, or focus on finding a large margin.
-
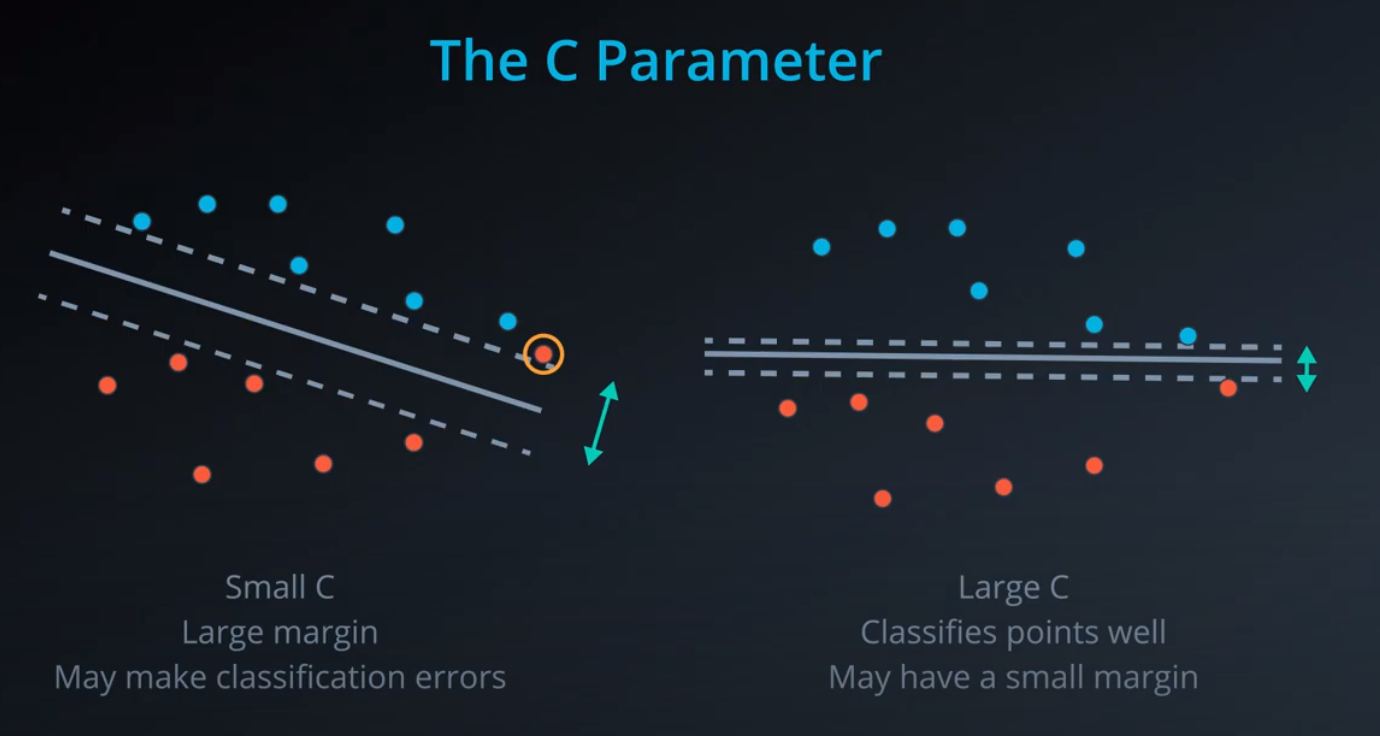
- C is a hyperparameter, and we may use grid search to find the best possible one
-

-
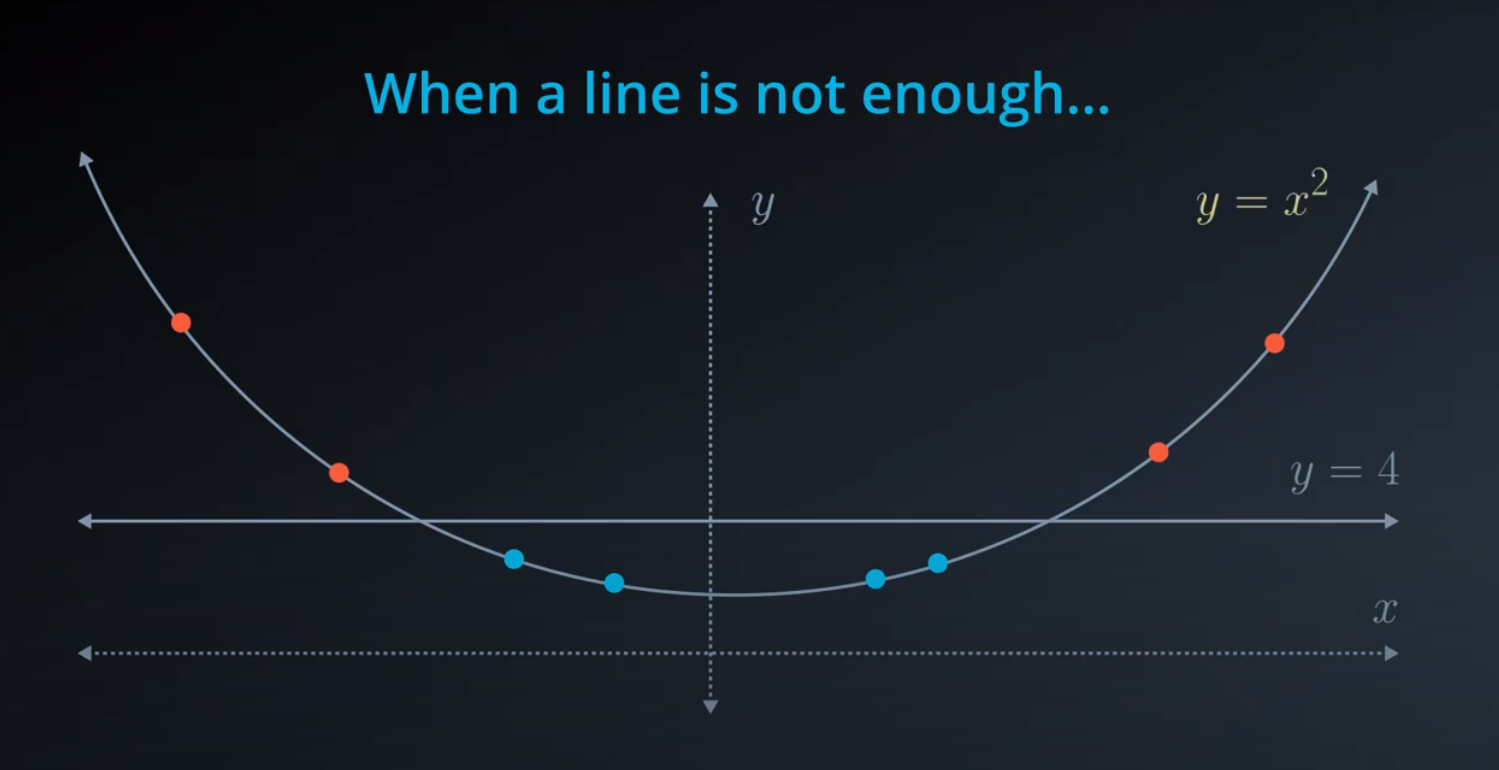
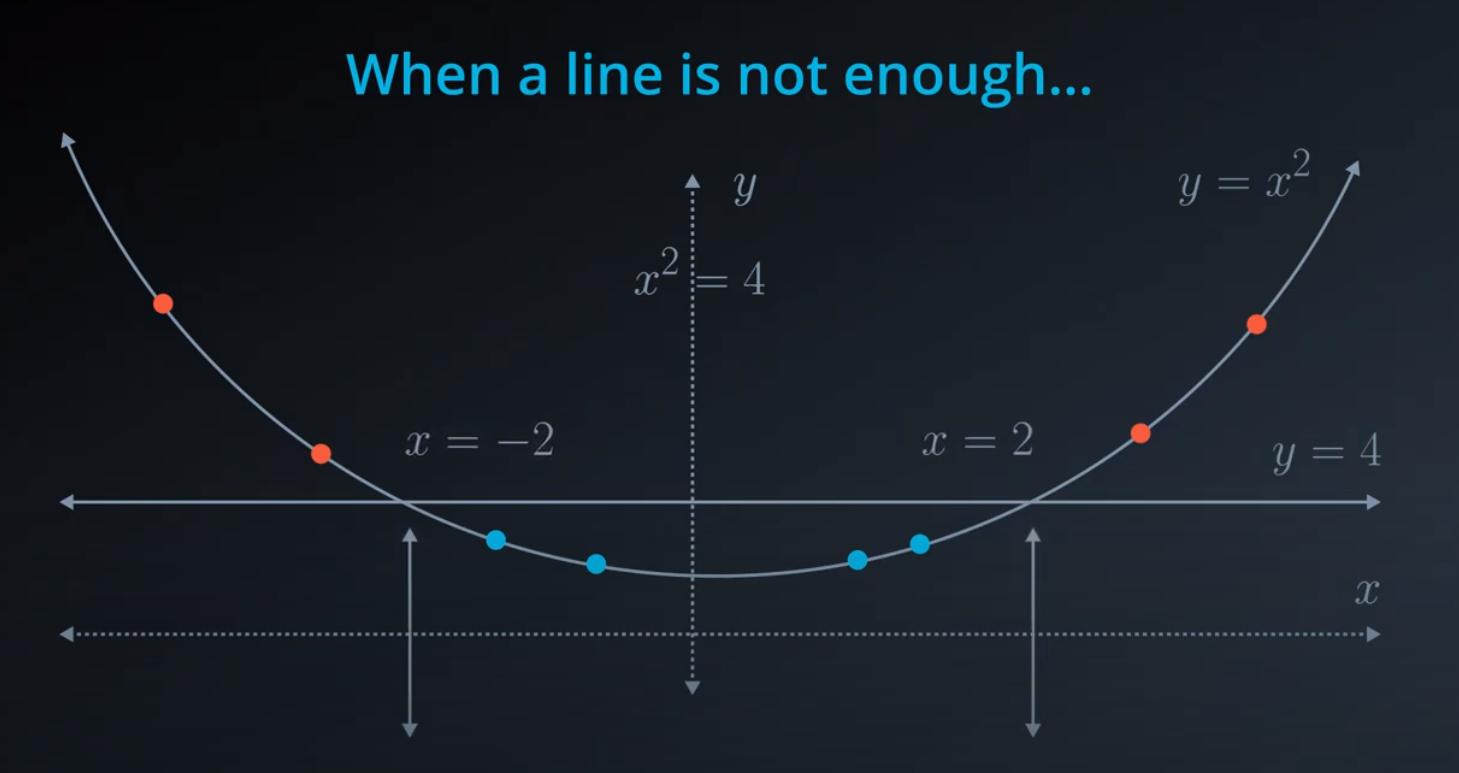
-
-

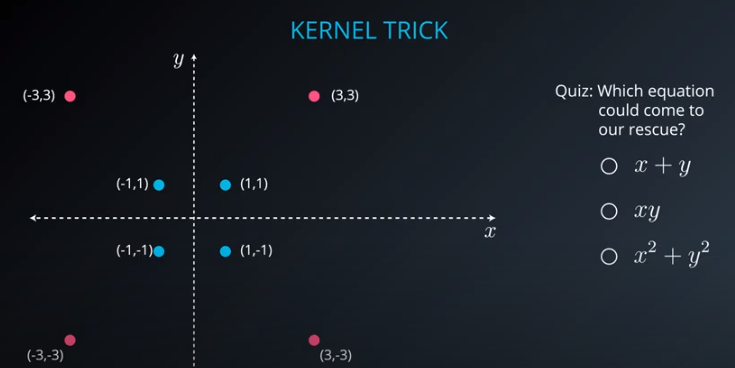
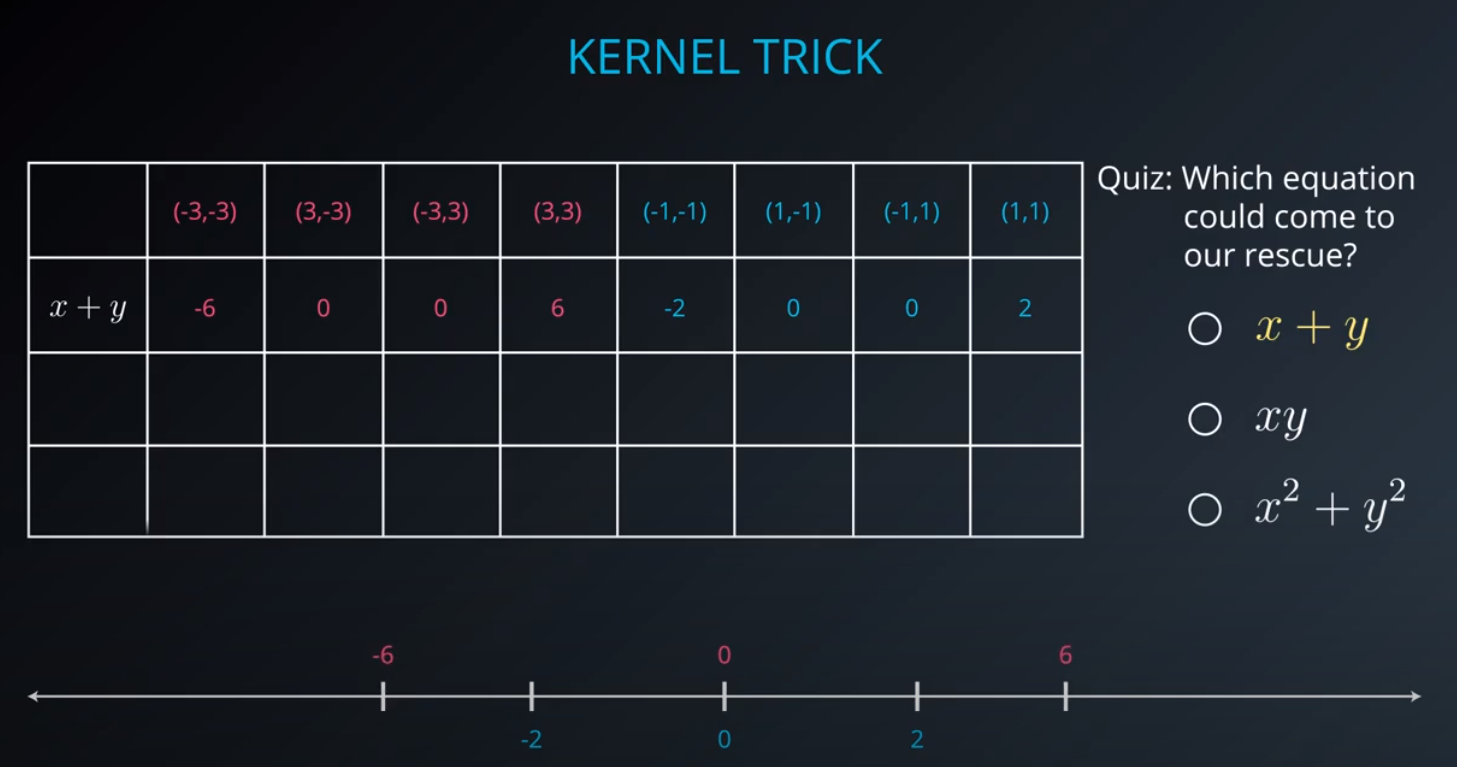
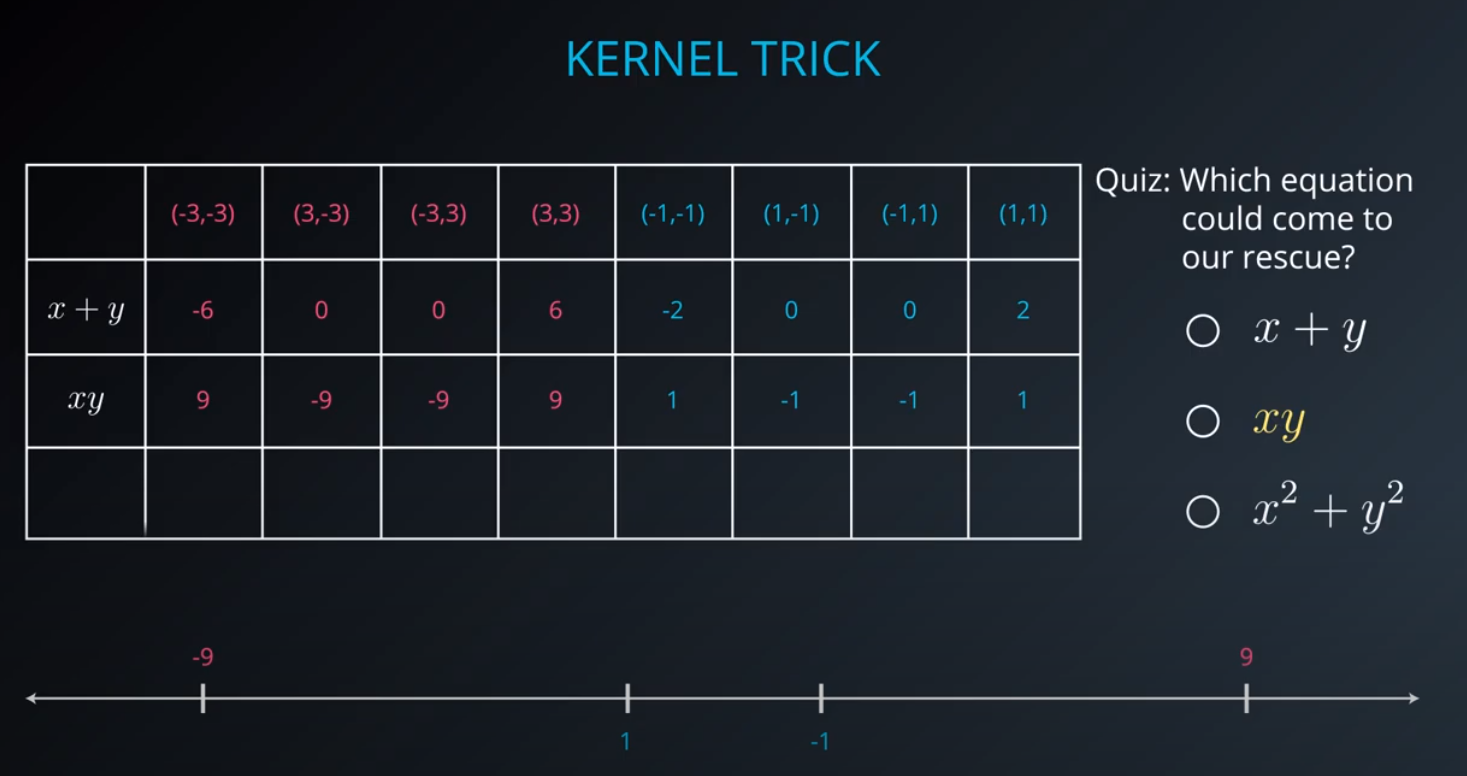
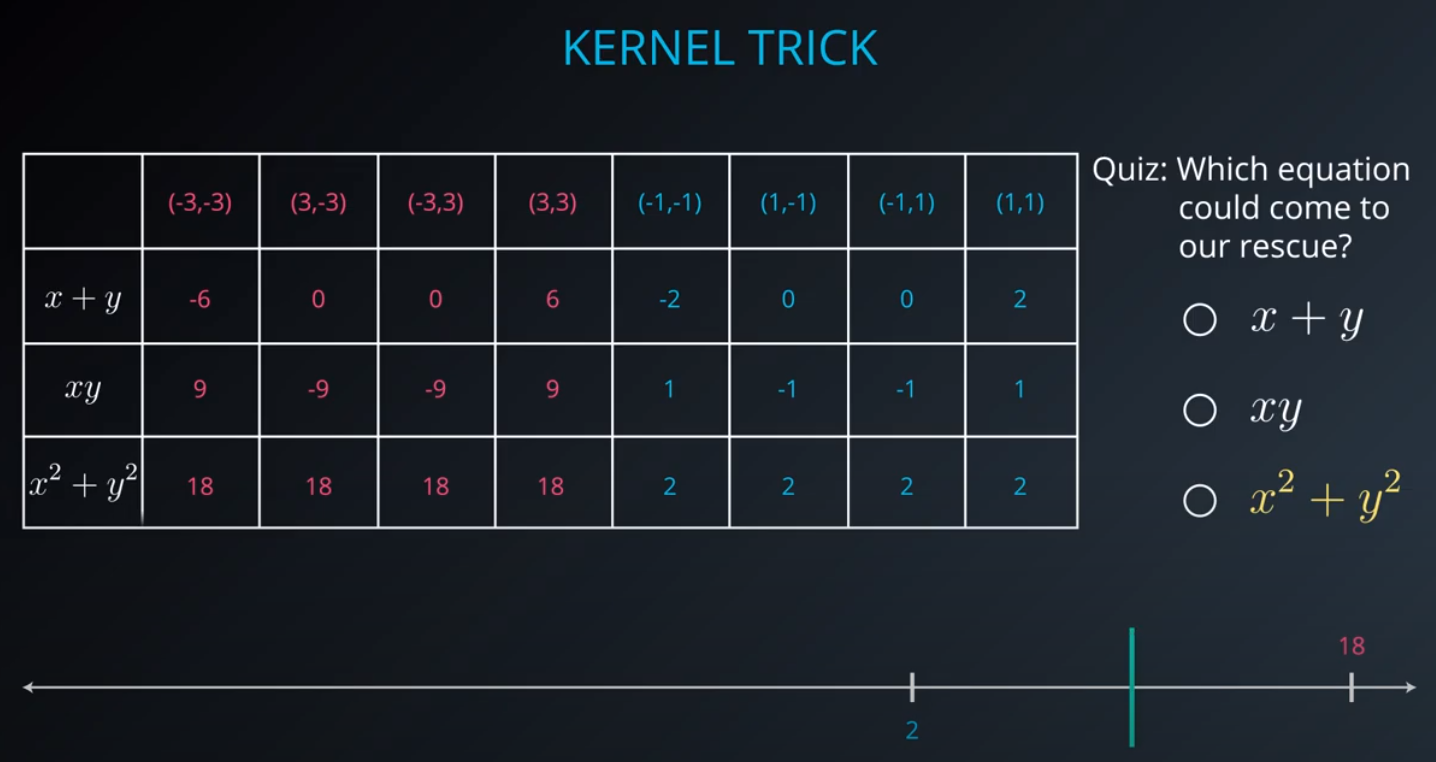
- The kernel trick is used when we can't just draw a line to separate a dataset. That way we create a
yaxis and bring the data up by using a functiony = x^2
- The kernel trick is used when we can't just draw a line to separate a dataset. That way we create a
-
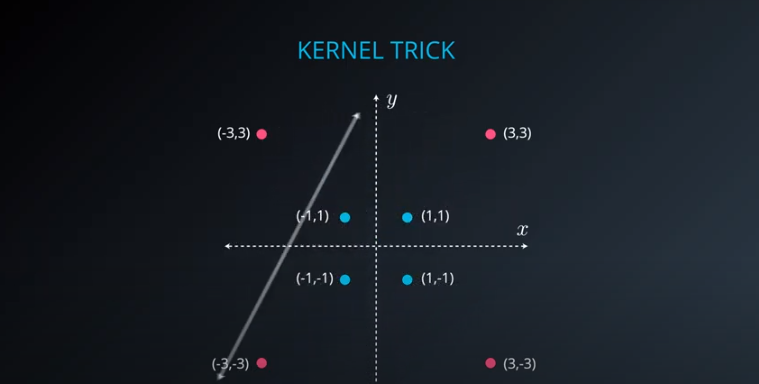
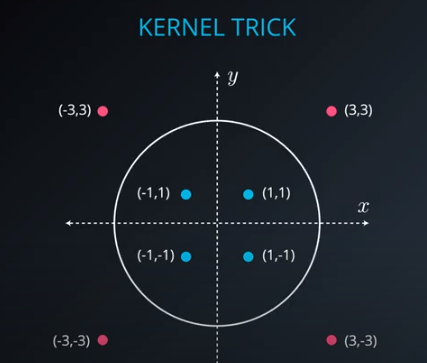
-
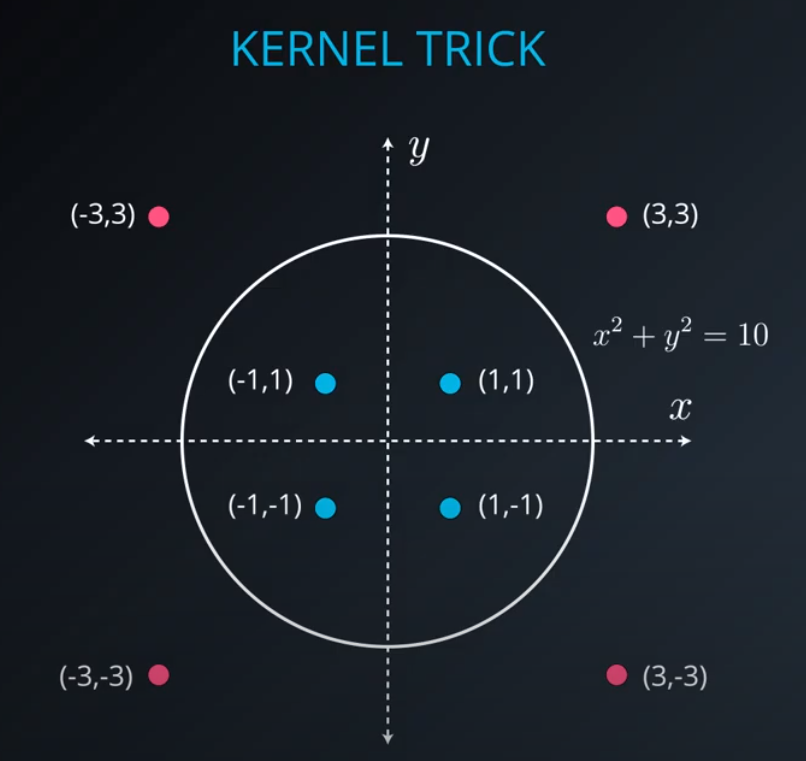
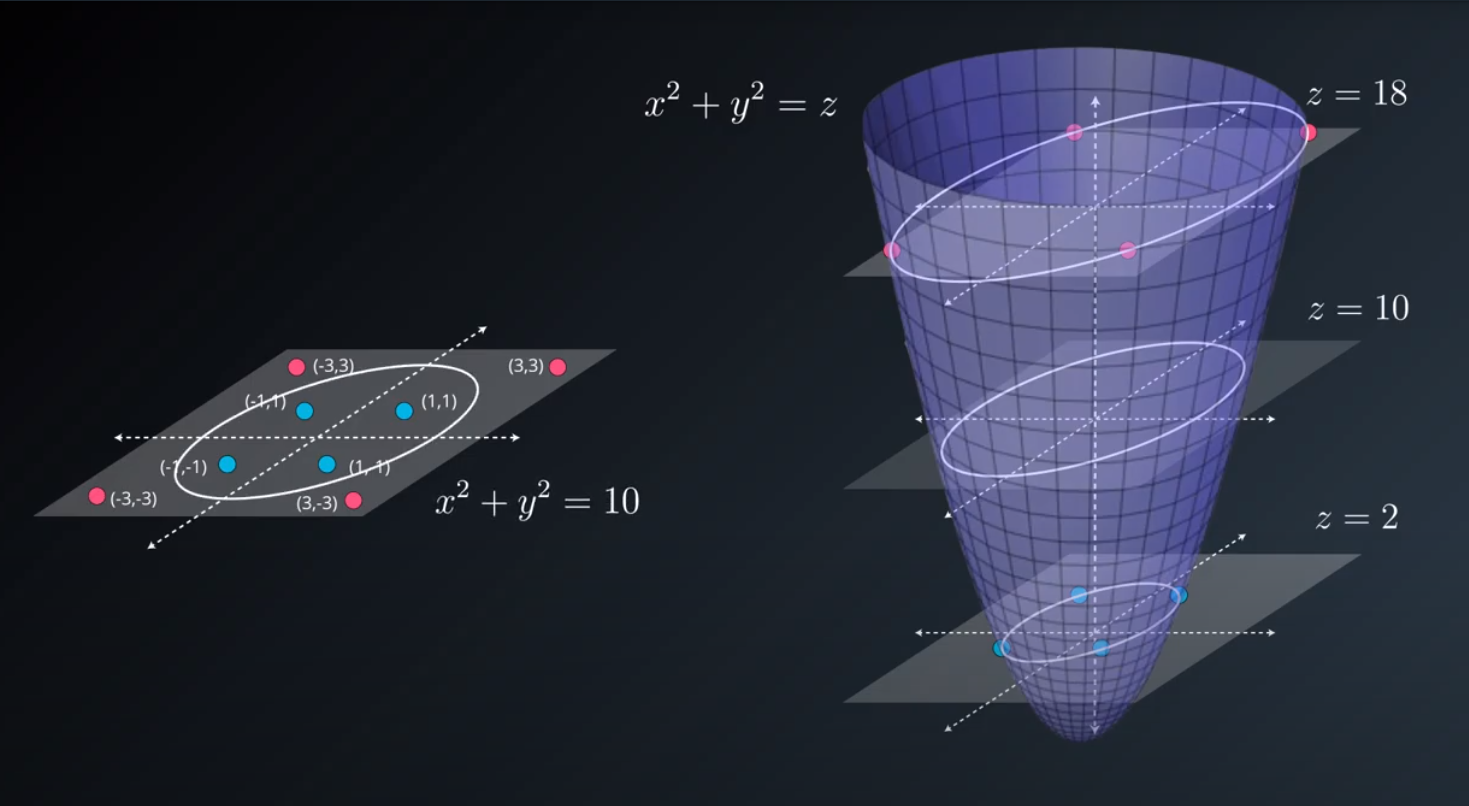
No line can separate those points so we need a bit something more complicated (kernel). One solution is to think of a circular boundary, another one is to think in many dimensions
-
For the circle we stop using a liner equation and we start using a high polynomial equation
-
-
-
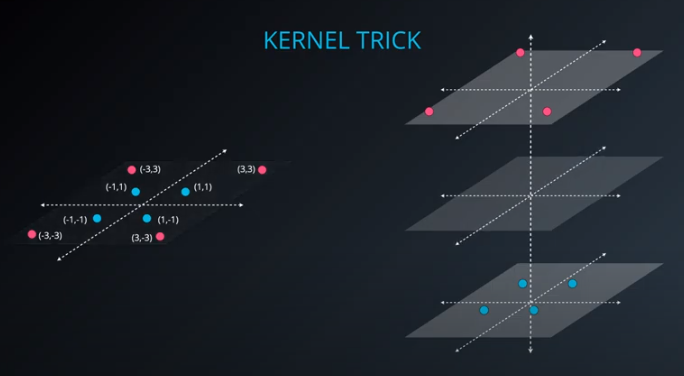
- We separate the data into 2 layers with one in the middle to divide it.
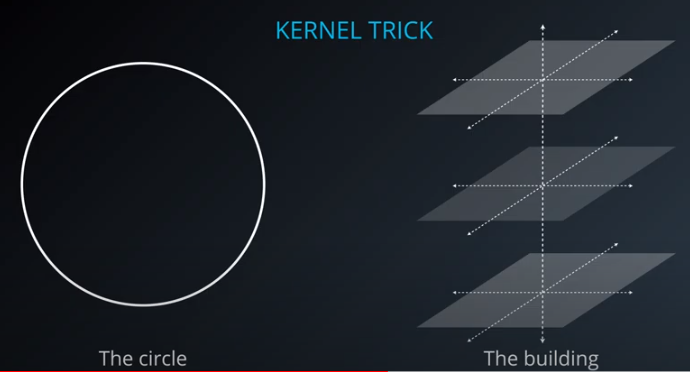
-
- They are both the same method, both the kernel method
-
- We are talking here about a polynomial kernel
-
- No clear cut in this example
-
-
-

-
-
-

- We lift the data in higher dimensions in order to find a nice cut for the dataset
-
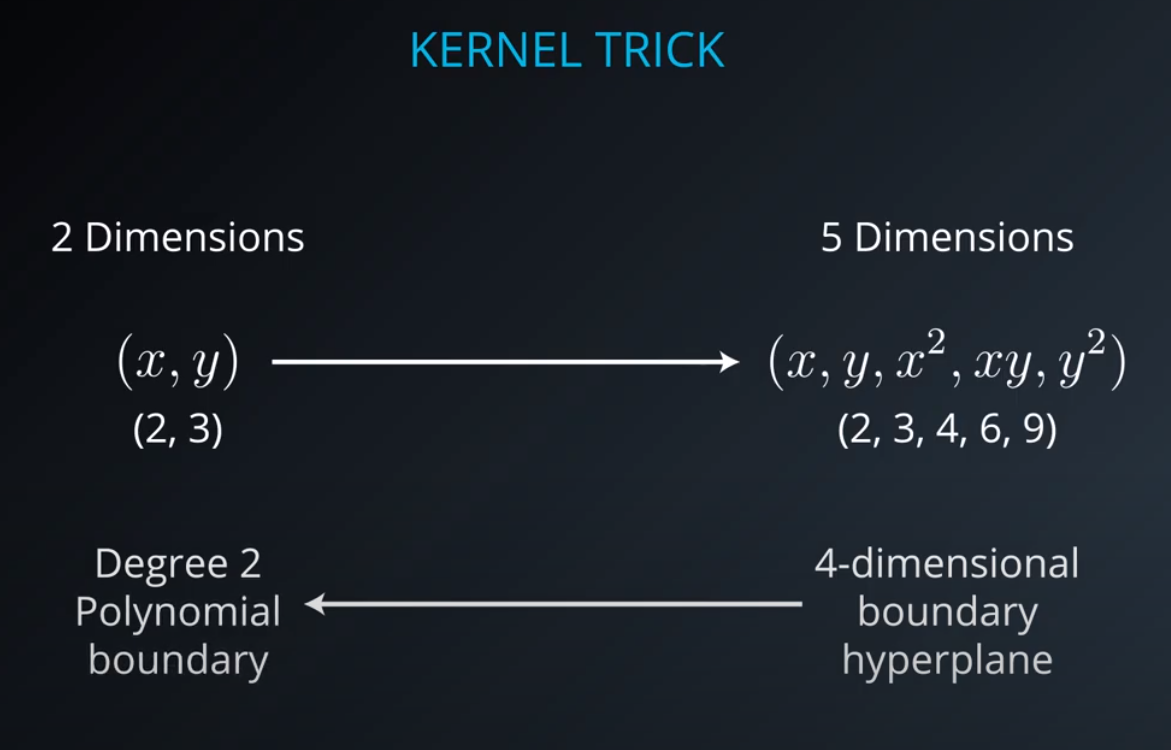
-
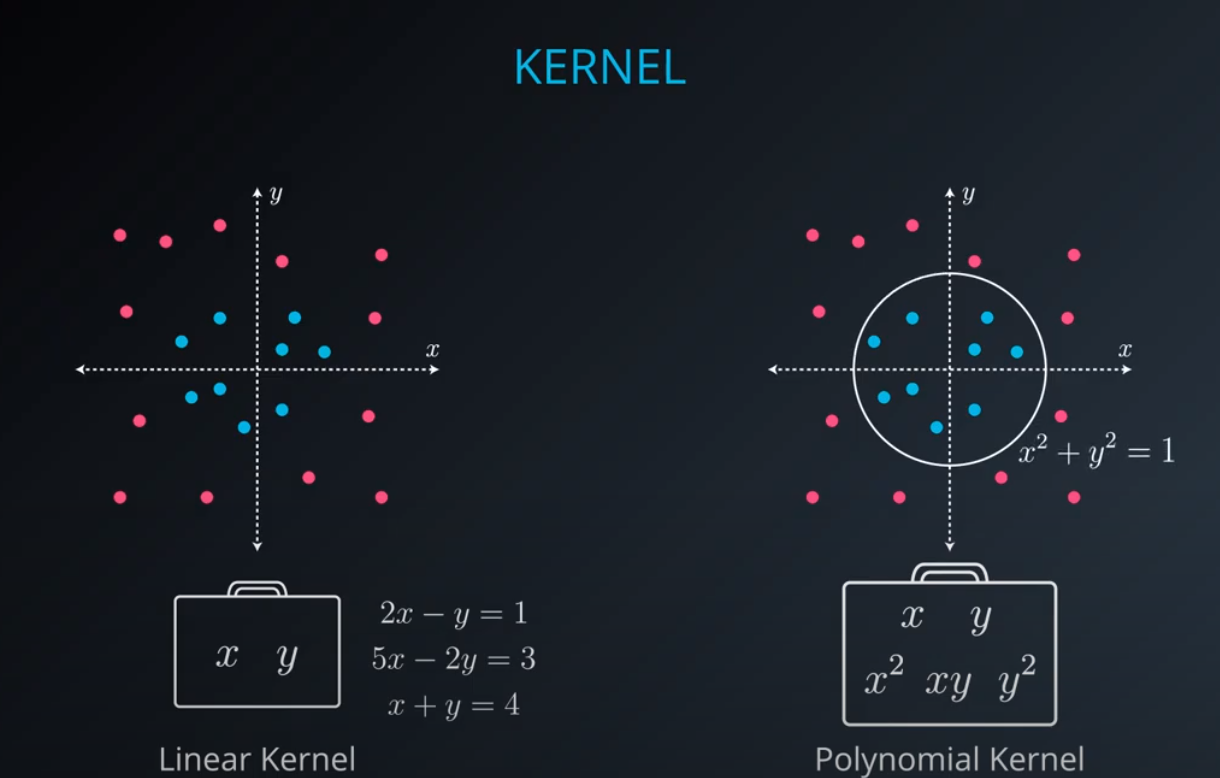
-
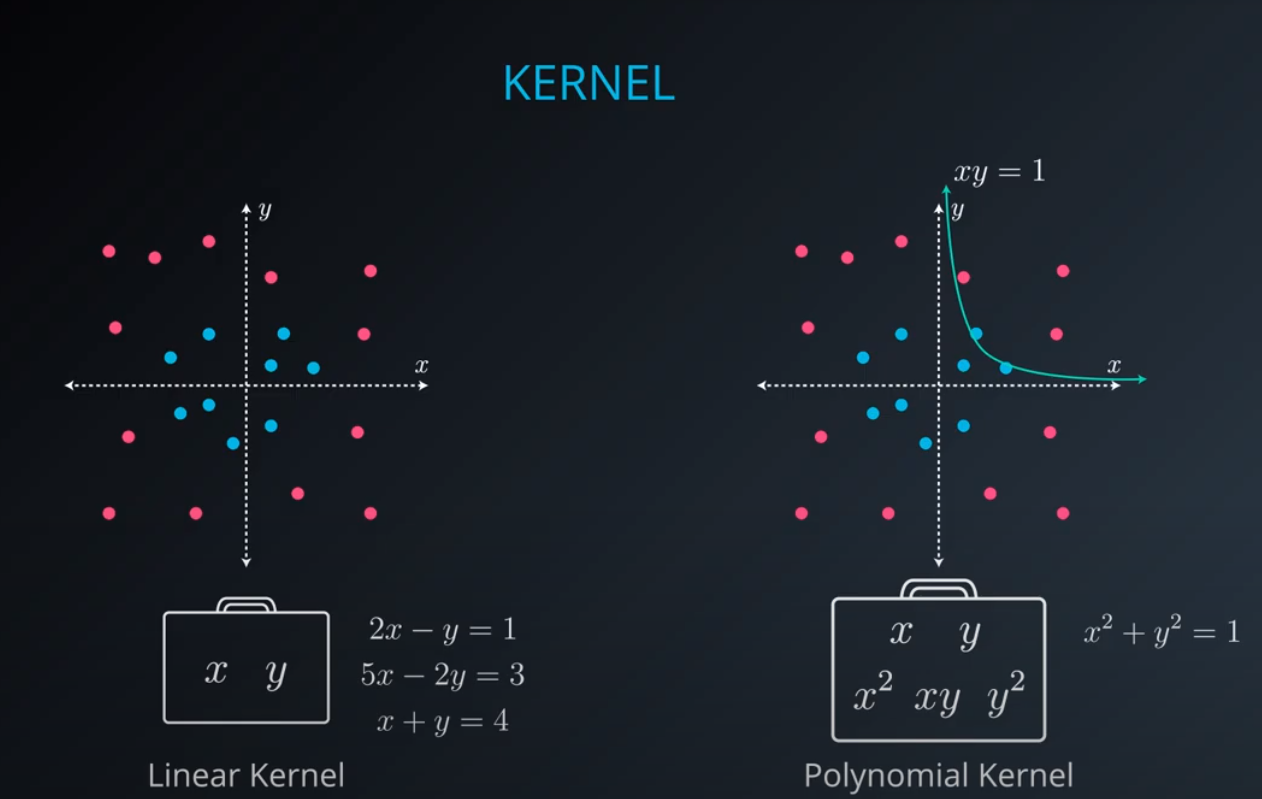
-
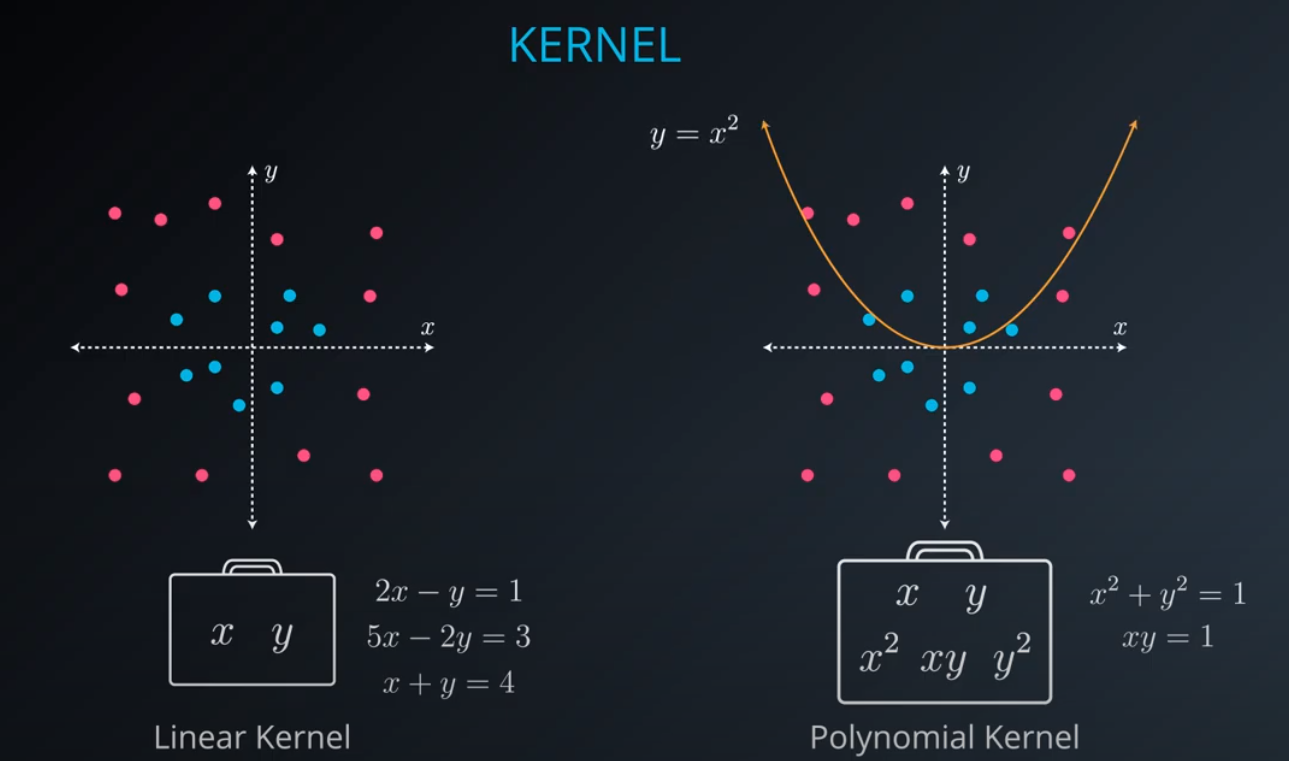
-
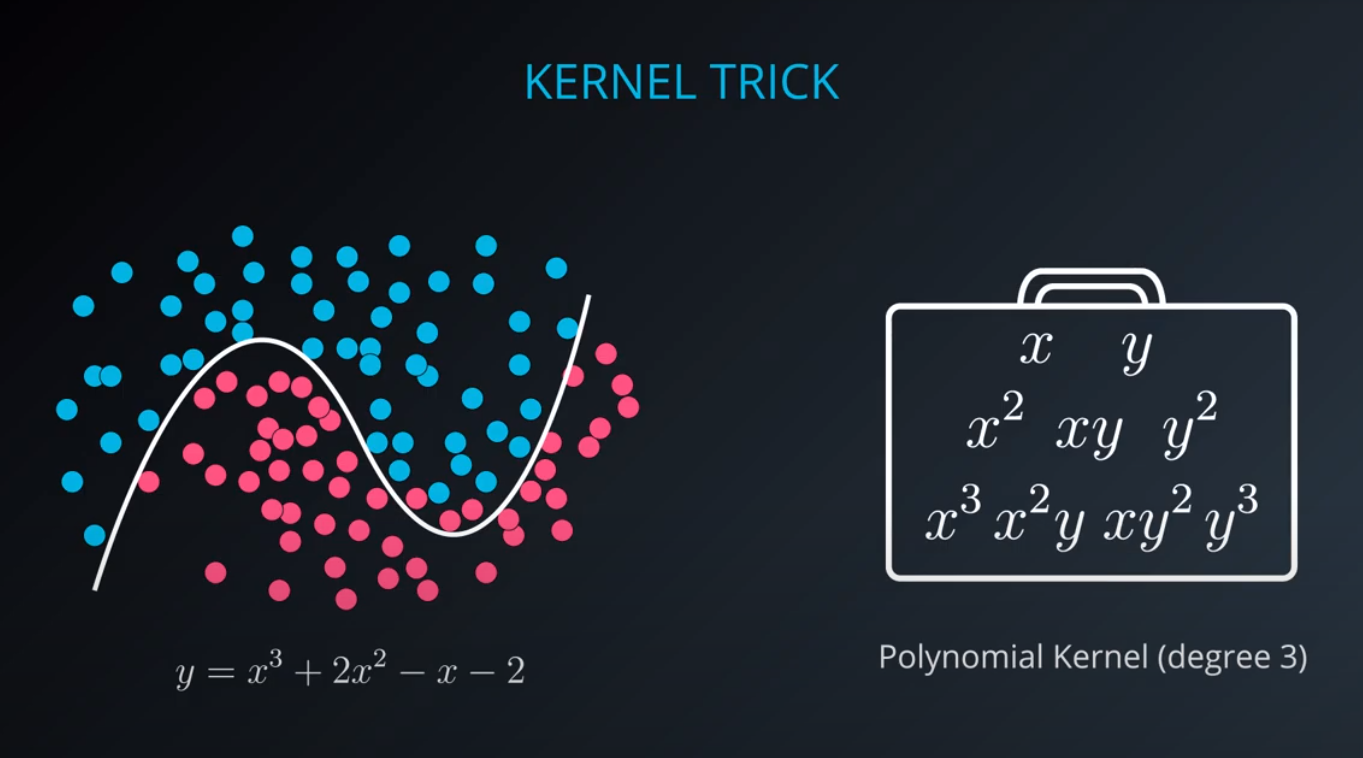
- The degree of a polynomial kernel is a hyperparameter that we can train to find the best possible model
-
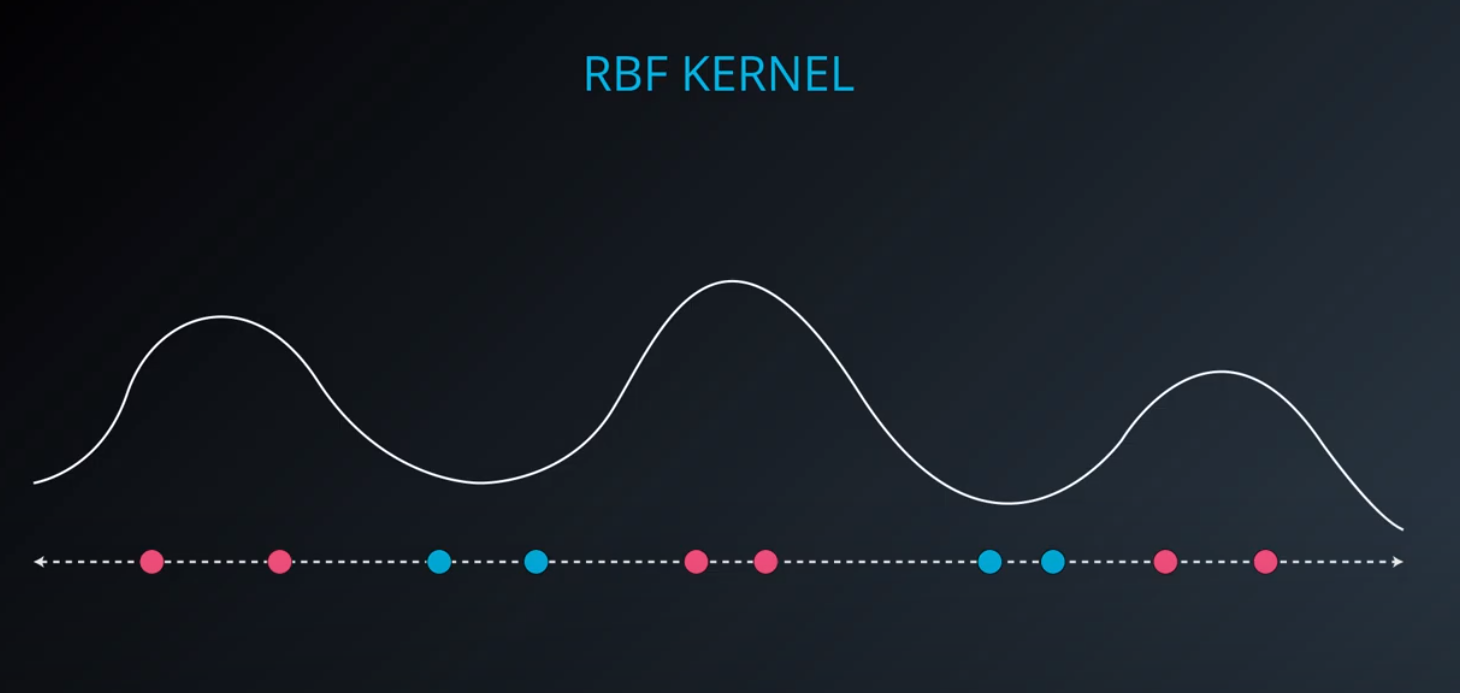
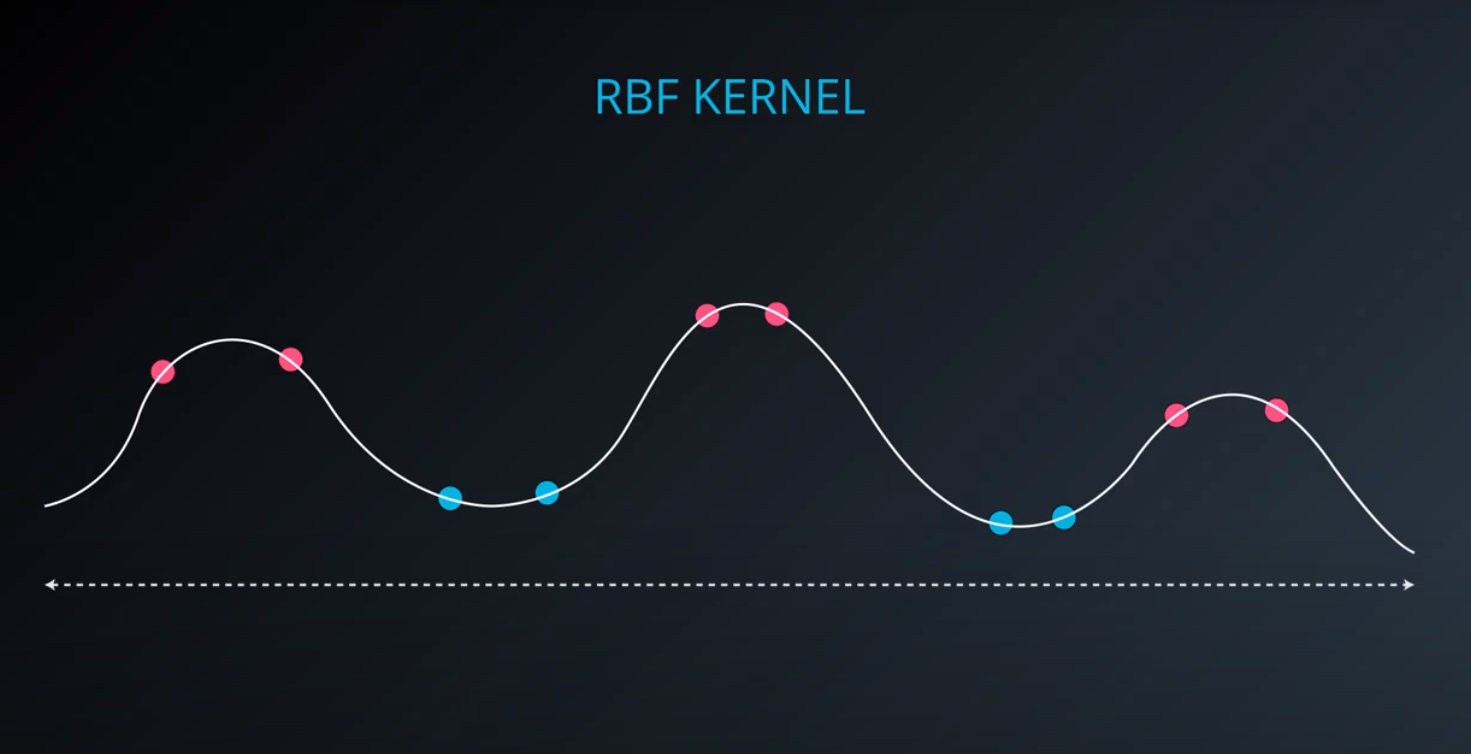
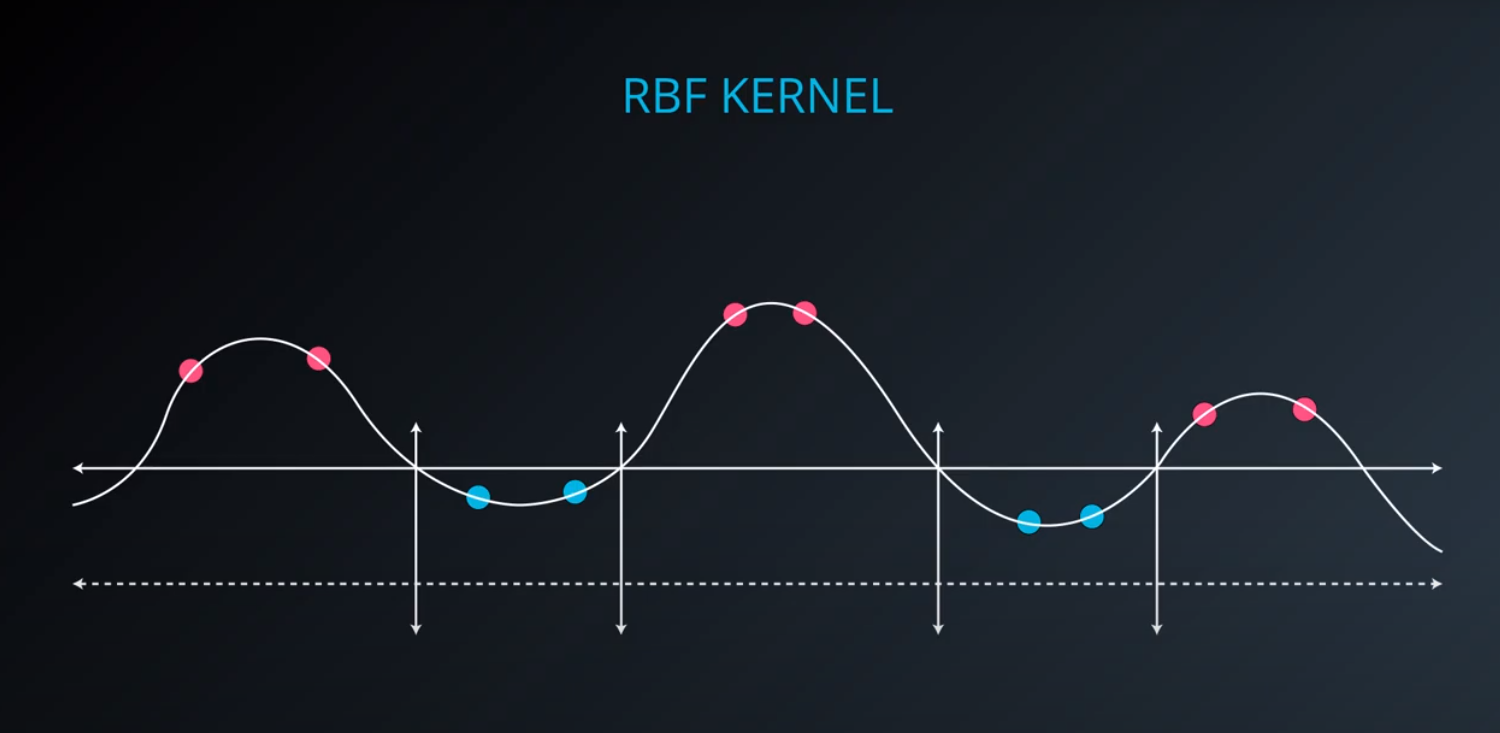
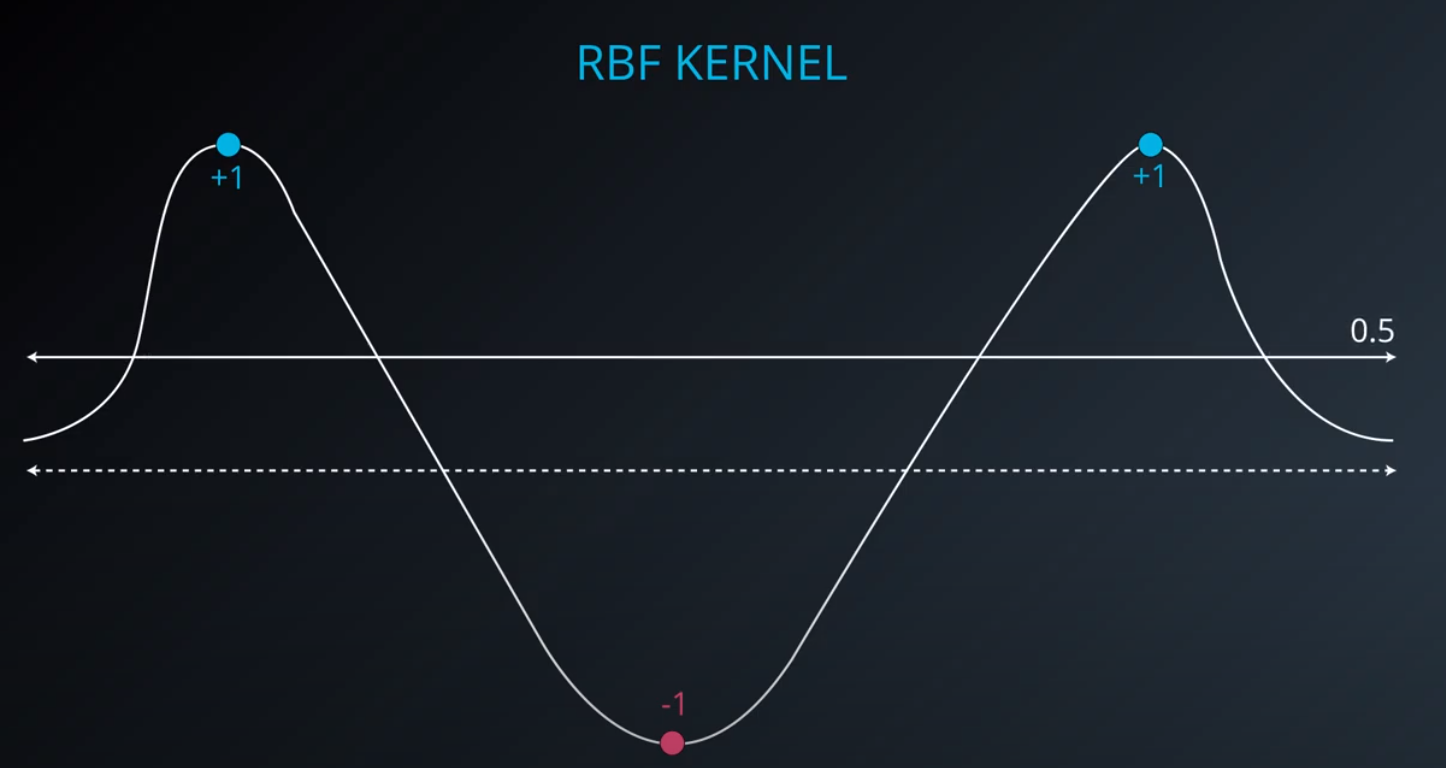
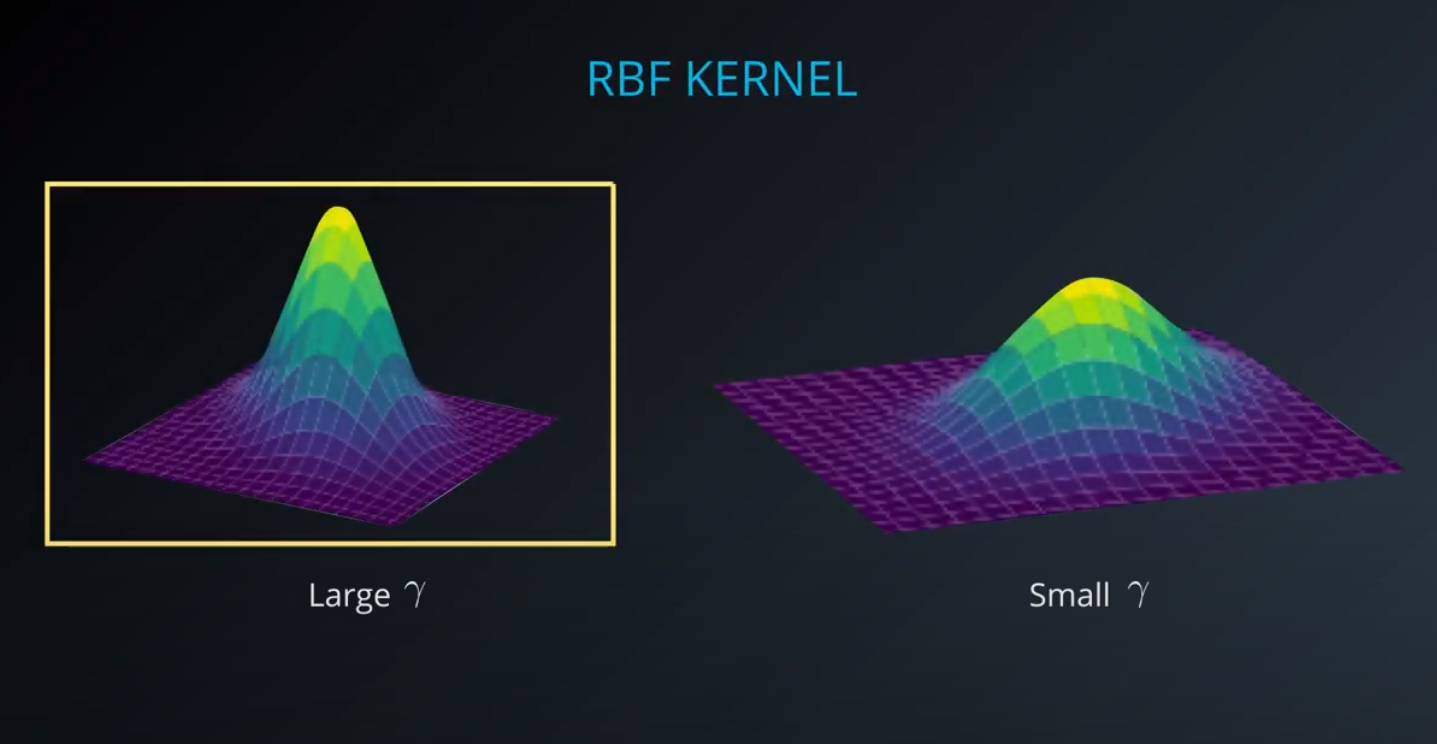
RBF (Radio Bases Functions) Kernel
-
-
-
-
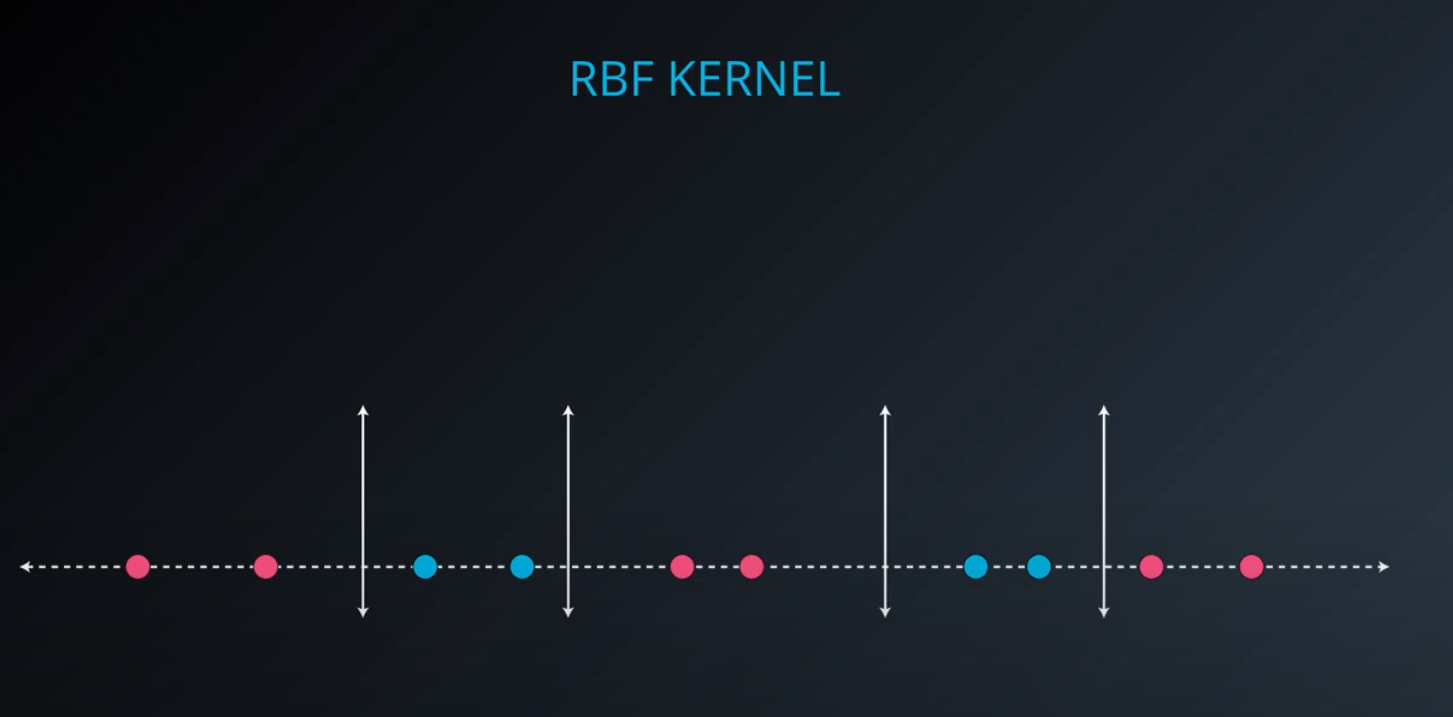
-
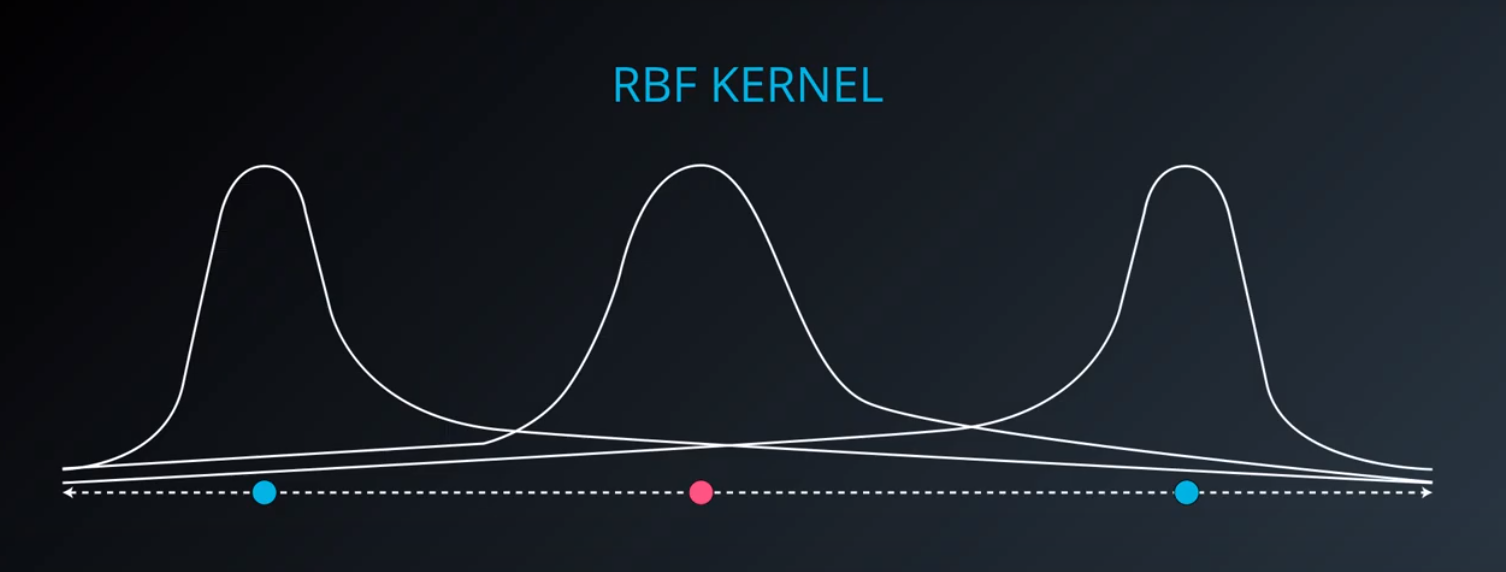
- Lets build a mountain on top of every point (that is RBF)
-
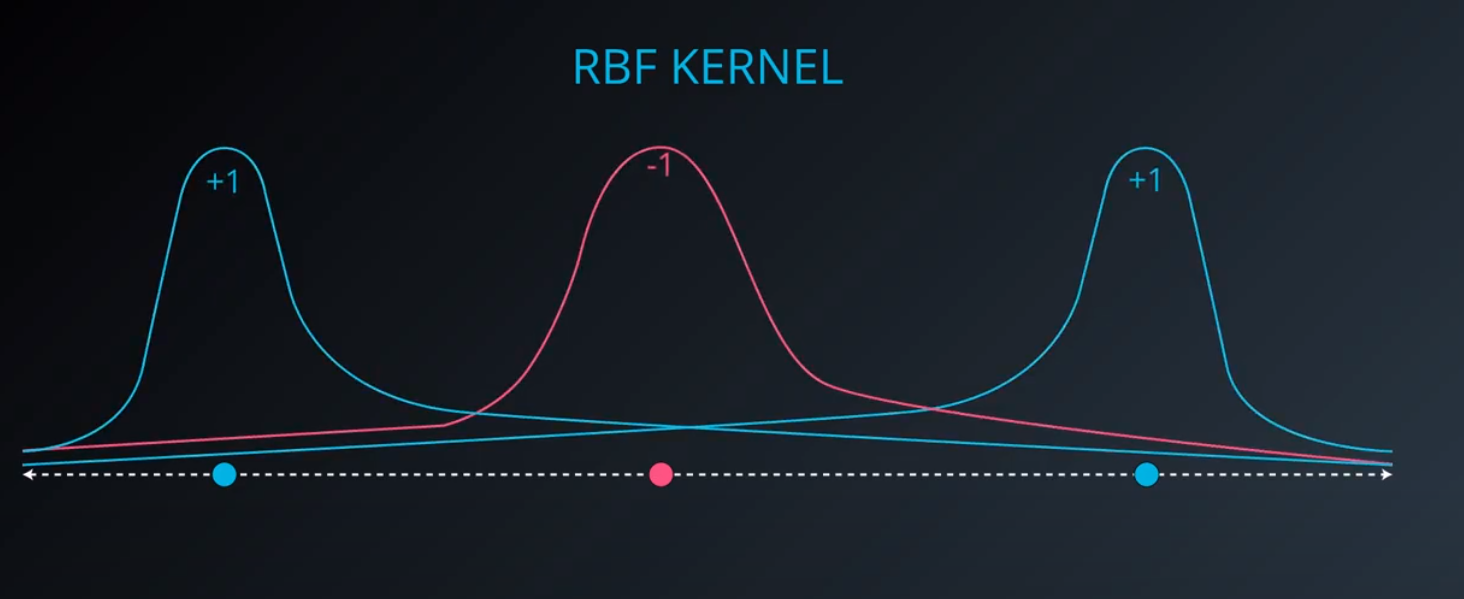
- We first flip by multiplying the values by +1 and -1
-
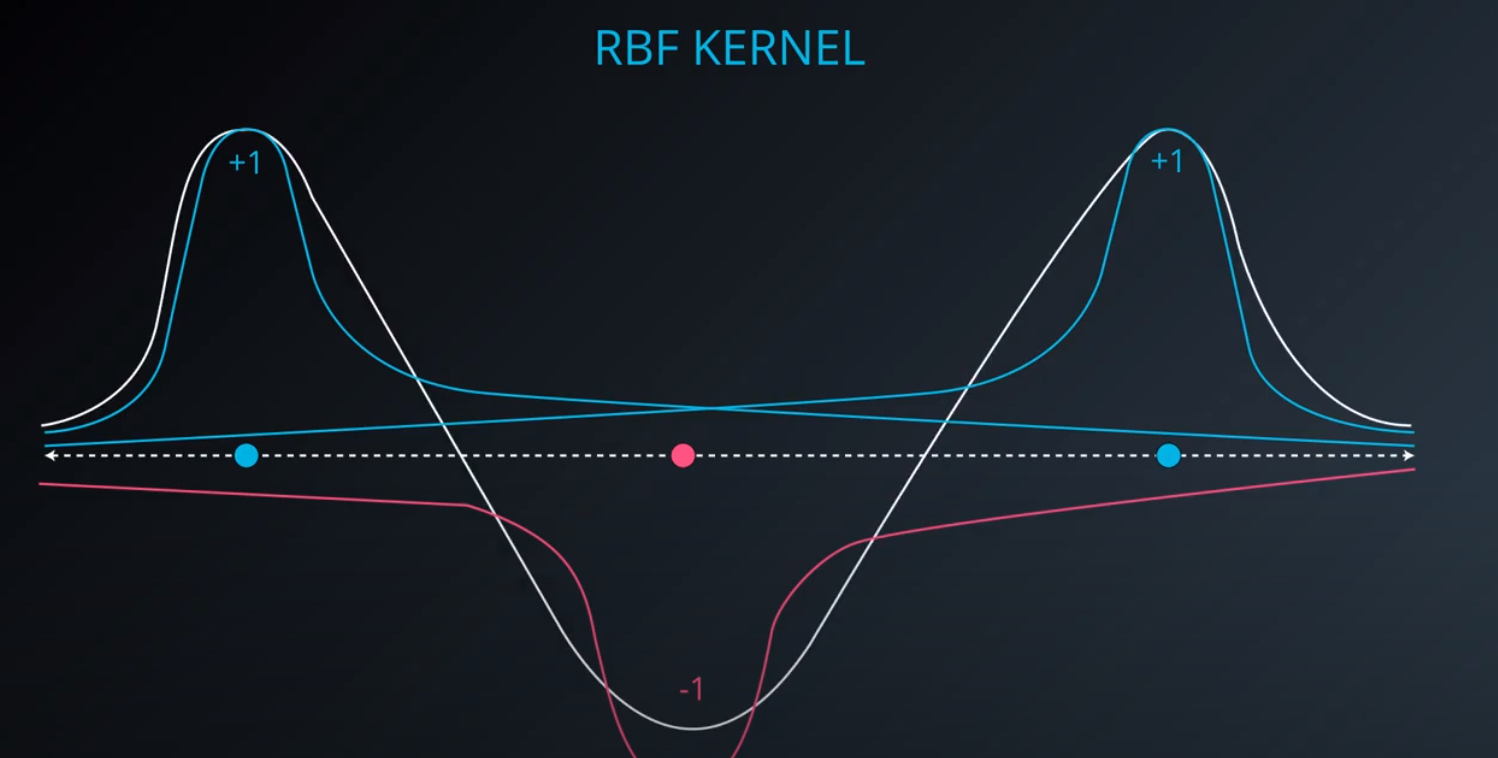
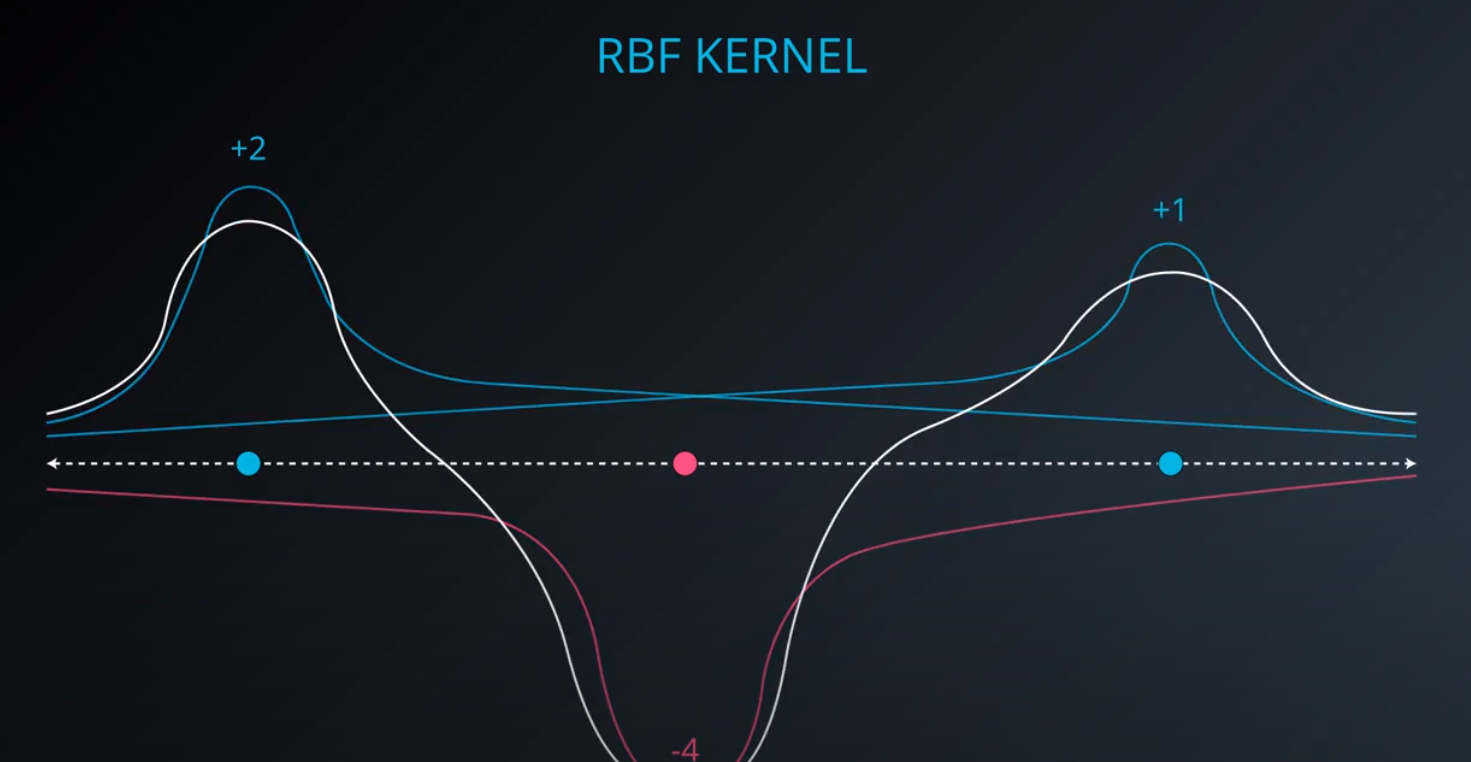
- If we add them we get the following function
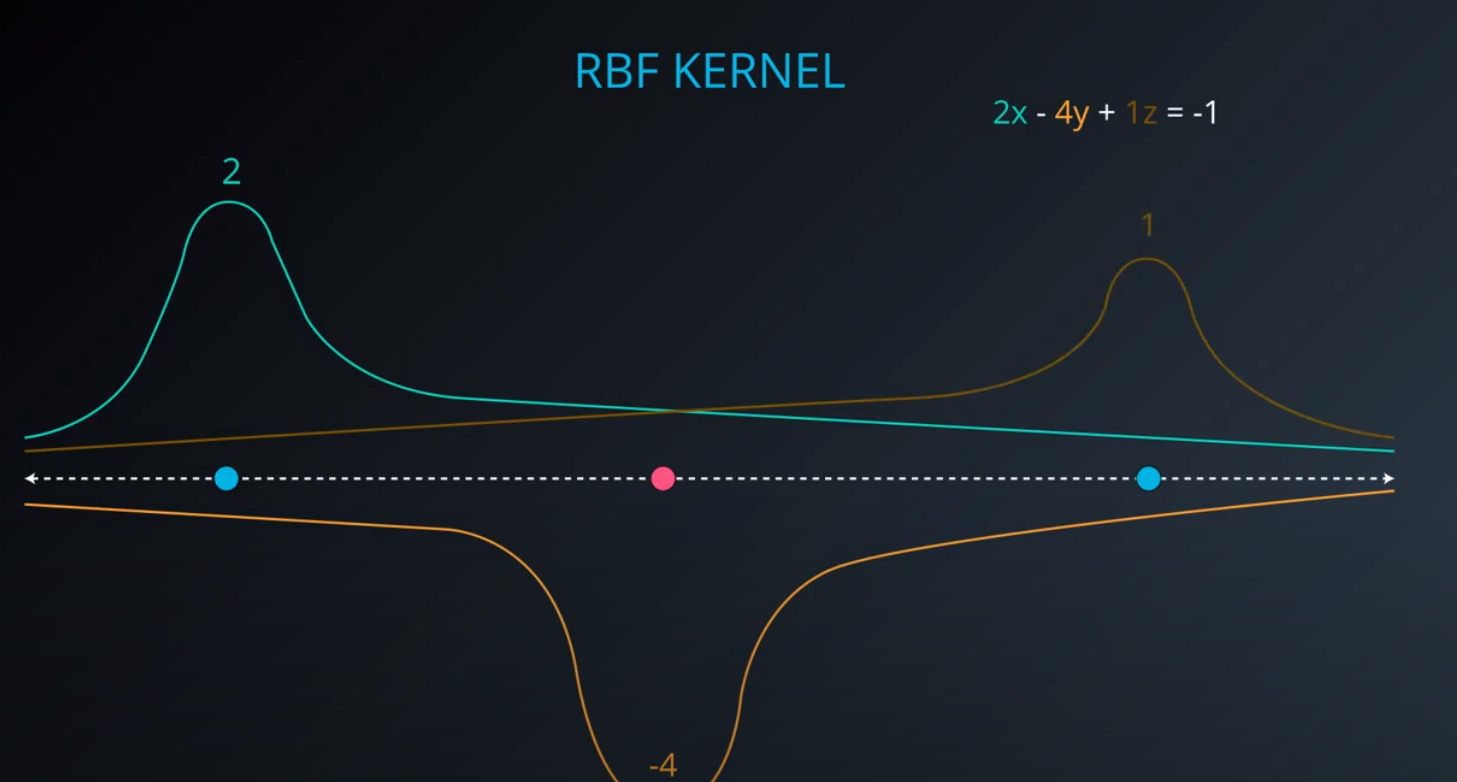
-
-
-
-
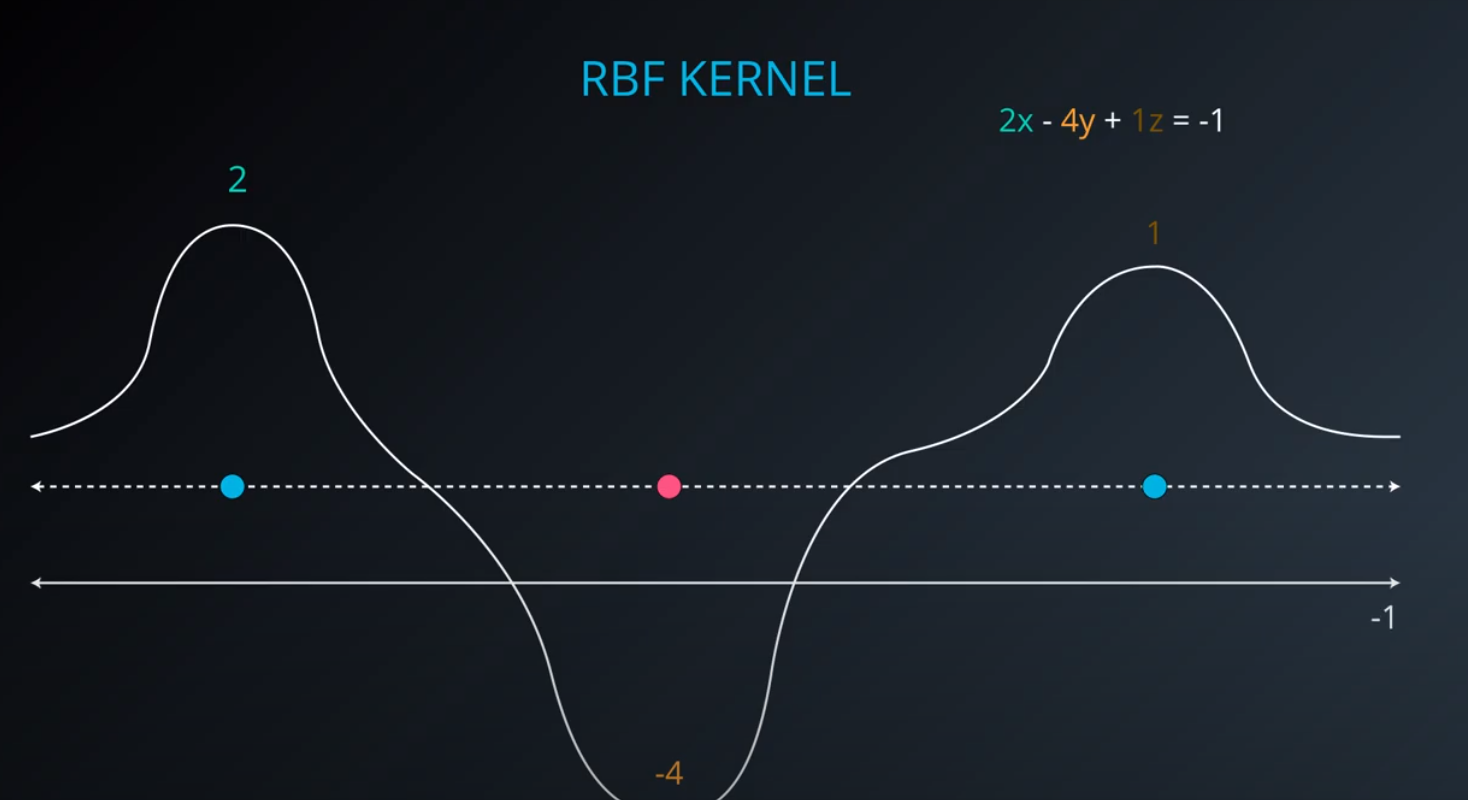
-
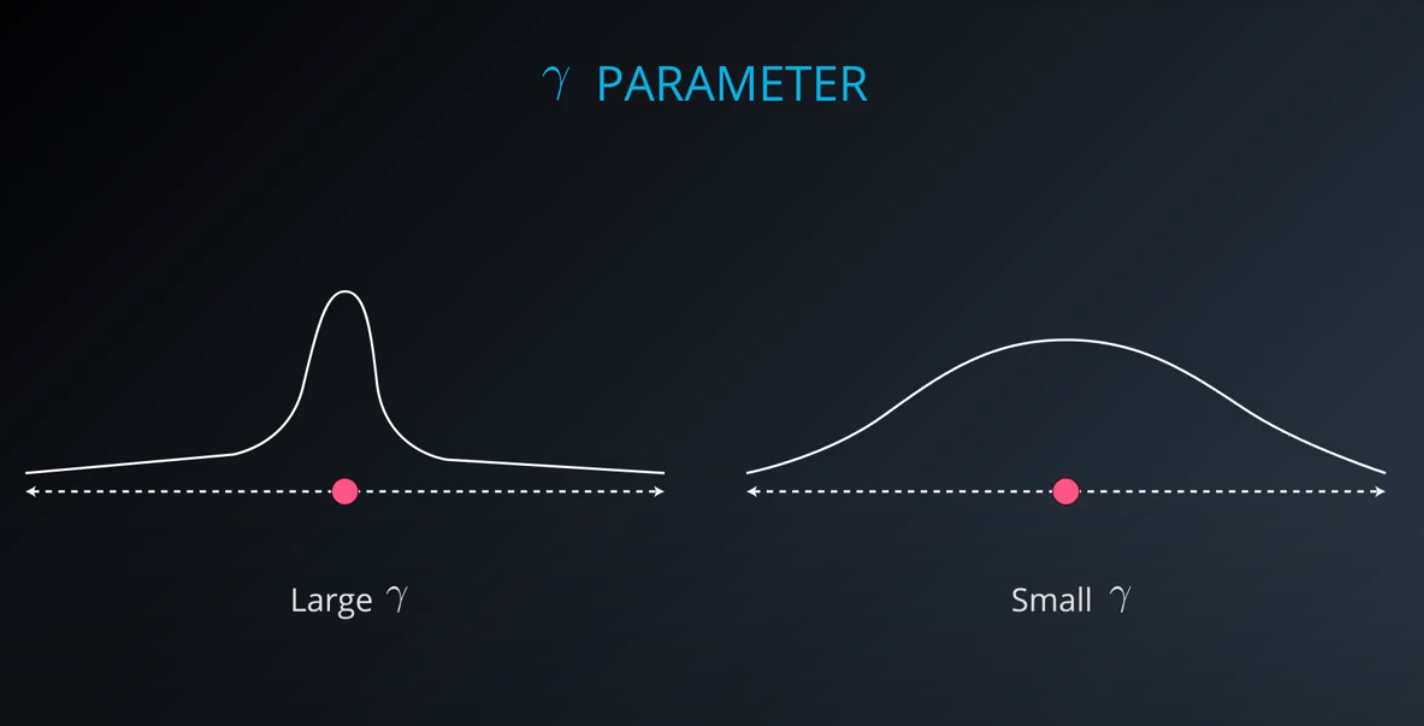
- The gamma parameter is a hyperparameter tunned during training
-
-
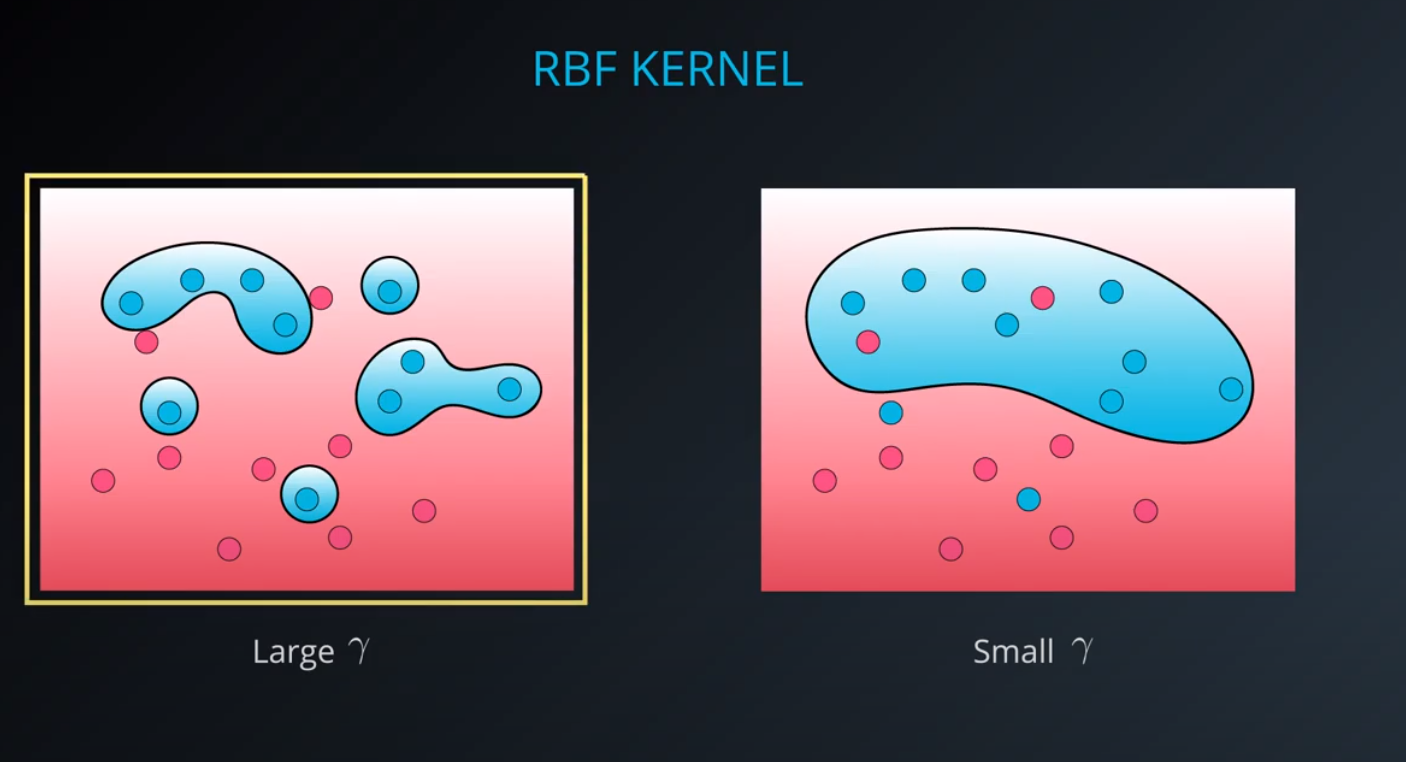
- Small values of gamma under fit, large values over fit
-
The major practical difference between a (kernel) perceptron and SVM is that perceptrons can be trained online (i.e. their weights can be updated as new examples arrive one at a time) whereas SVMs cannot be. See this question for information on whether SVMs can be trained online. So, even though a SVM is usually a better classifier, perceptrons can still be useful because they are cheap and easy to re-train in a situation in which fresh training data is constantly arriving.
-
-
Support Vector Machines in sklearn
-
In this section, you'll use support vector machines to fit a given sample dataset.
-
Before you do that, let's go over the tools required to build this model.
-
For your support vector machine model, you'll be using scikit-learn's SVC class. This class provides the functions to define and fit the model to your data.
-
from sklearn.svm import SVC model = SVC() model.fit(x_values, y_values)
-
In the example above, the model variable is a support vector machine model that has been fitted to the data x_values and y_values. Fitting the model means finding the best boundary that fits the training data. Let's make two predictions using the model's predict() function.
-
print(model.predict([ [0.2, 0.8], [0.5, 0.4] ])) [[ 0., 1.]]
-
The model returned an array of predictions, one prediction for each input array. The first input, [0.2, 0.8], got a prediction of 0.. The second input, [0.5, 0.4], got a prediction of 1..
-
Hyperparameters
-
When we define the model, we can specify the hyperparameters. As we've seen in this section, the most common ones are
-
C: The C parameter. -
kernel: The kernel. The most common ones are 'linear', 'poly', and 'rbf'. -
degree: If the kernel is polynomial, this is the maximum degree of the monomials in the kernel. -
gamma: If the kernel is rbf, this is the gamma parameter. -
For example, here we define a model with a polynomial kernel of degree 4, and a C parameter of 0.1.
-
model = SVC(kernel='poly', degree=4, C=0.1)
-
-
# Import statements from sklearn.svm import SVC from sklearn.metrics import accuracy_score import pandas as pd import numpy as np # Read the data. data = np.asarray(pd.read_csv('data.csv', header=None)) # Assign the features to the variable X, and the labels to the variable y. X = data[:,0:2] y = data[:,2] # TODO: Create the model and assign it to the variable model. # Find the right parameters for this model to achieve 100% accuracy on the dataset. model = SVC(kernel='rbf', gamma=27) # TODO: Fit the model. model.fit(X,y) # TODO: Make predictions. Store them in the variable y_pred. y_pred = model.predict(X) # TODO: Calculate the accuracy and assign it to the variable acc. acc = accuracy_score(y, y_pred)
-
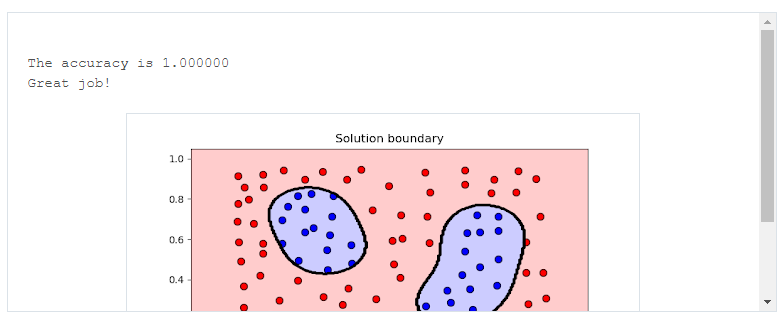
-
Recap
-
Maximum Margin Classifier
-
When your data can be completely separated, the linear version of SVMs attempts to maximize the distance from the linear boundary to the closest points (called the support vectors). For this reason, we saw that in the picture below, the boundary on the left is better than the one on the right.
-

-
-
Classification with Inseparable Classes
-
Unfortunately, data in the real world is rarely completely separable as shown in the above images. For this reason, we introduced a new hyper-parameter called
C. The C hyper-parameter determines how flexible we are willing to be with the points that fall on the wrong side of our dividing boundary. The value of C ranges between 0 and infinity. When C is large, you are forcing your boundary to have fewer errors than when it is a small value. -
Note: when C is too large for a particular set of data, you might not get convergence at all because your data cannot be separated with the small number of errors allotted with such a large value of C.
-
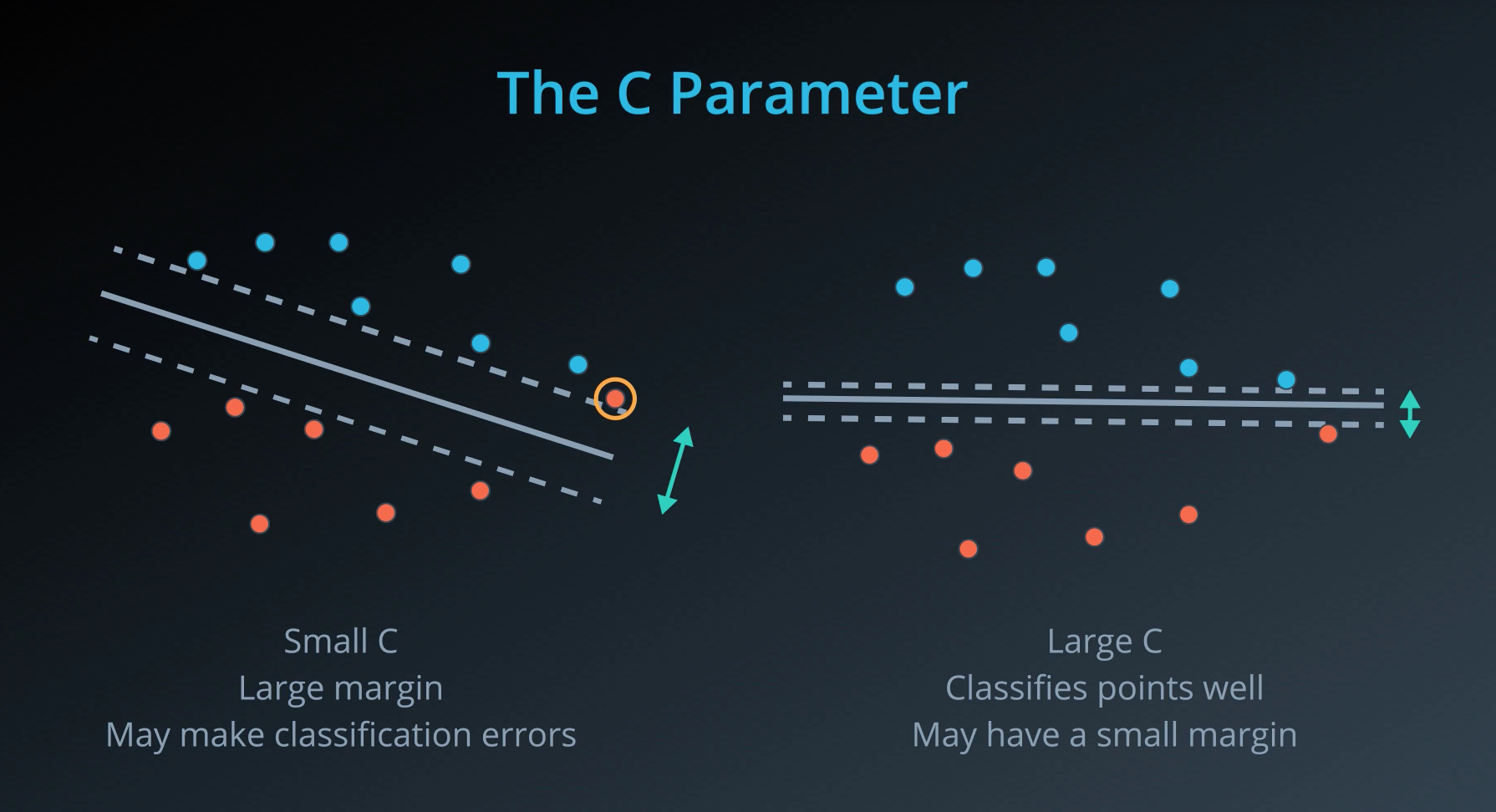
-
-
Kernels
-
Finally, we looked at what makes SVMs truly powerful, kernels. Kernels in SVMs allow us the ability to separate data when the boundary between them is nonlinear. Specifically, you saw two types of kernels:
- polynomial
- rbf
-
By far the most popular kernel is the rbf kernel (which stands for radial basis function). The rbf kernel allows you the opportunity to classify points that seem hard to separate in any space. This is a density based approach that looks at the closeness of points to one another. This introduces another hyper-parameter gamma. When gamma is large, the outcome is similar to having a large value of C, that is your algorithm will attempt to classify every point correctly. Alternatively, small values of gamma will try to cluster in a more general way that will make more mistakes, but may perform better when it sees new data.
-
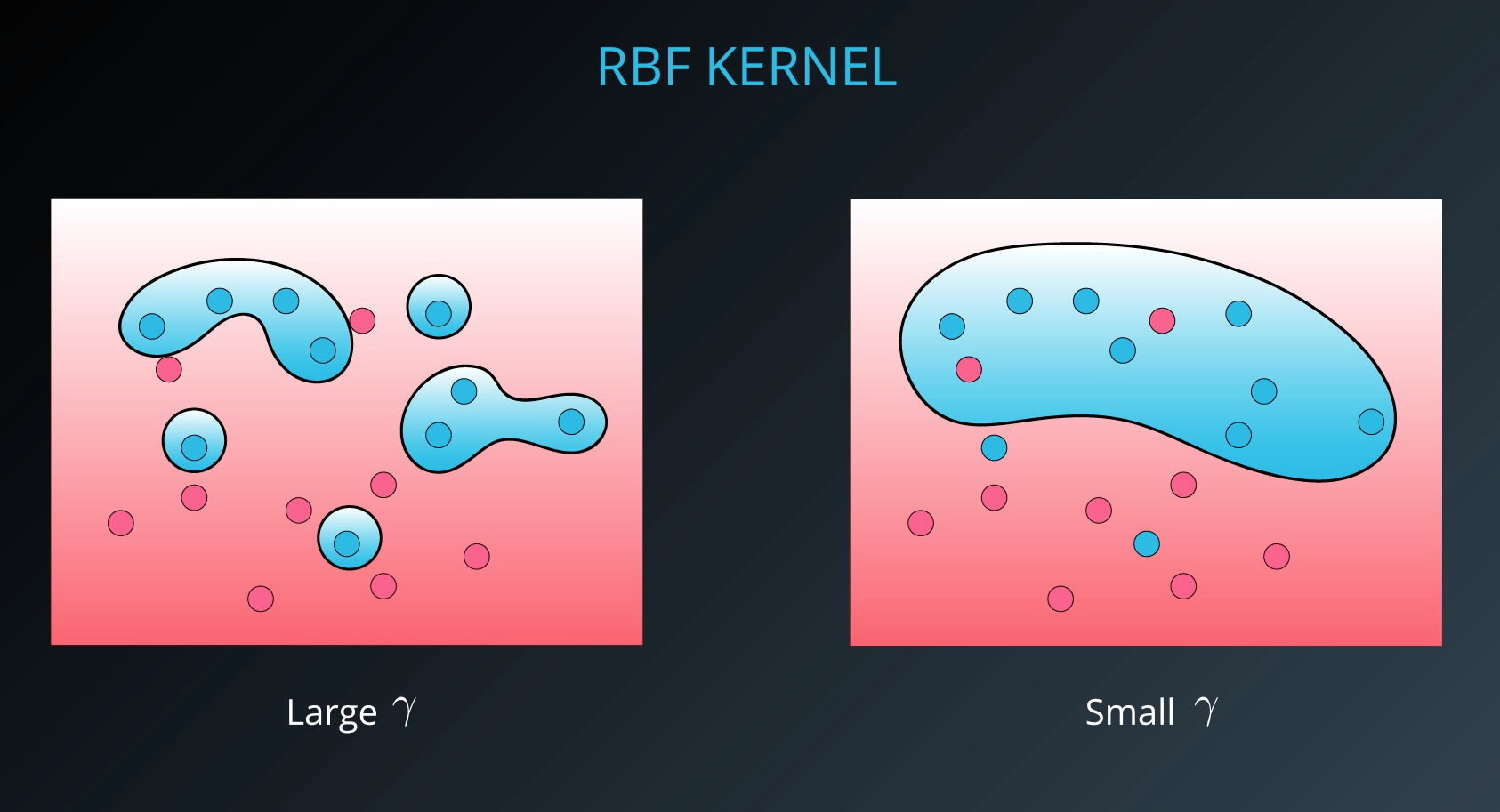
-
-
-
-


























































-
Ensemble Methods
-
Join models to get a better model
-
Bagging
- Short for Bootstrap aggregating
- We ask for each of the models to be evaluated separately, and we combine their values after (average, etc..)
-
Boosting
- This method will push each models strength (not only aggregating results). On that note, which model may have a strength depending on the problem in question
-
We will call the models alone the "weak learners" and the master model the "strong learner"
-
This whole lesson (on ensembles) is about how we can combine (or ensemble) the models you have already seen in a way that makes the combination of these models better at predicting than the individual models.
-
Commonly the "weak" learners you use are decision trees. In fact the default for most ensemble methods is a decision tree in sklearn. However, you can change this value to any of the models you have seen so far.
-
Why Would We Want to Ensemble Learners Together?
-
There are two competing variables in finding a well fitting machine learning model: Bias and Variance. It is common in interviews for you to be asked about this topic and how it pertains to different modeling techniques. As a first pass, the wikipedia is quite useful. However, I will give you my perspective and examples:
-
Bias: When a model has high bias, this means that means it doesn't do a good job of bending to the data. An example of an algorithm that usually has high bias is linear regression. Even with completely different datasets, we end up with the same line fit to the data. When models have high bias, this is bad.
-
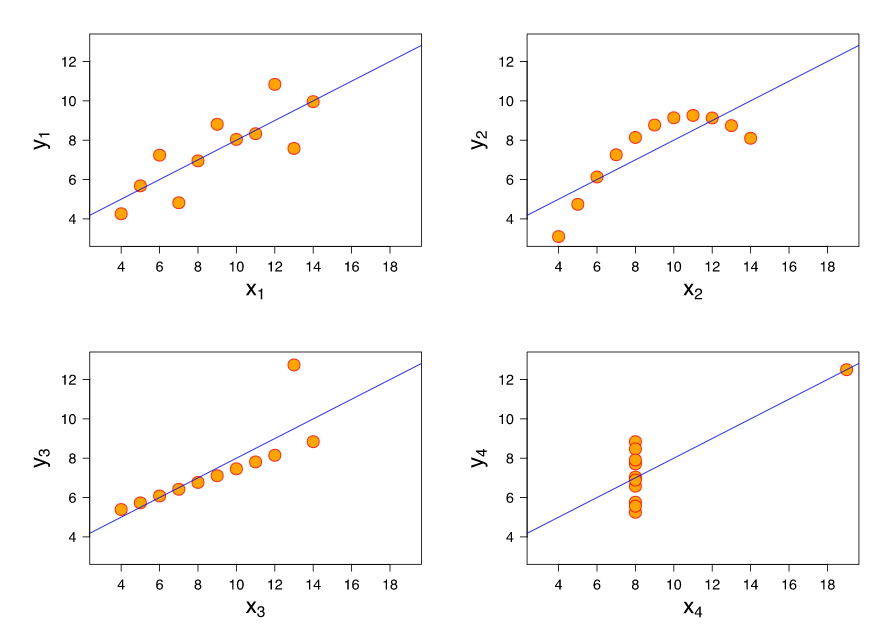
-
Variance: When a model has high variance, this means that it changes drastically to meet the needs of every point in our dataset. Linear models like the one above has low variance, but high bias. An example of an algorithm that tends to have high variance and low bias is a decision tree (especially decision trees with no early stopping parameters). A decision tree, as a high variance algorithm, will attempt to split every point into its own branch if possible. This is a trait of high variance, low bias algorithms - they are extremely flexible to fit exactly whatever data they see.
-

-
By combining algorithms, we can often build models that perform better by meeting in the middle in terms of bias and variance. There are some other tactics that are used to combine algorithms in ways that help them perform better as well. These ideas are based on minimizing bias and variance based on mathematical theories, like the central limit theorem.
-
-
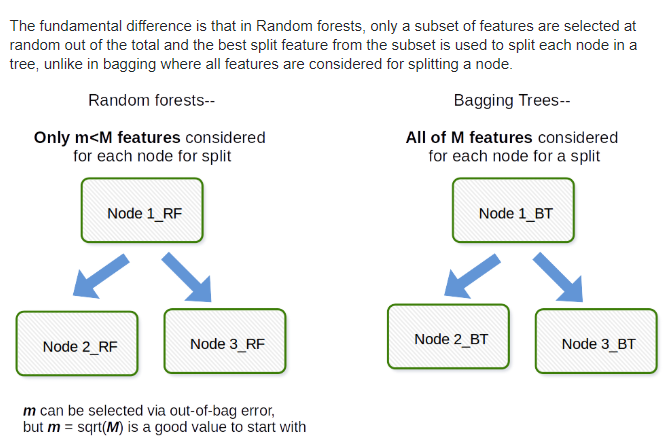
Introducing Randomness Into Ensembles
-
Another method that is used to improve ensemble methods is to introduce randomness into high variance algorithms before they are ensembled together. The introduction of randomness combats the tendency of these algorithms to overfit (or fit directly to the data available). There are two main ways that randomness is introduced:
-
Bootstrap the data - that is, sampling the data with replacement and fitting your algorithm to the sampled data.
-
Subset the features - in each split of a decision tree or with each algorithm used in an ensemble, only a subset of the total possible features are used.
-
-
In fact, these are the two random components used in the next algorithm you are going to see called random forests.
-
-
Random Forest
-
- Decision Tress tend to overfit a lot
-
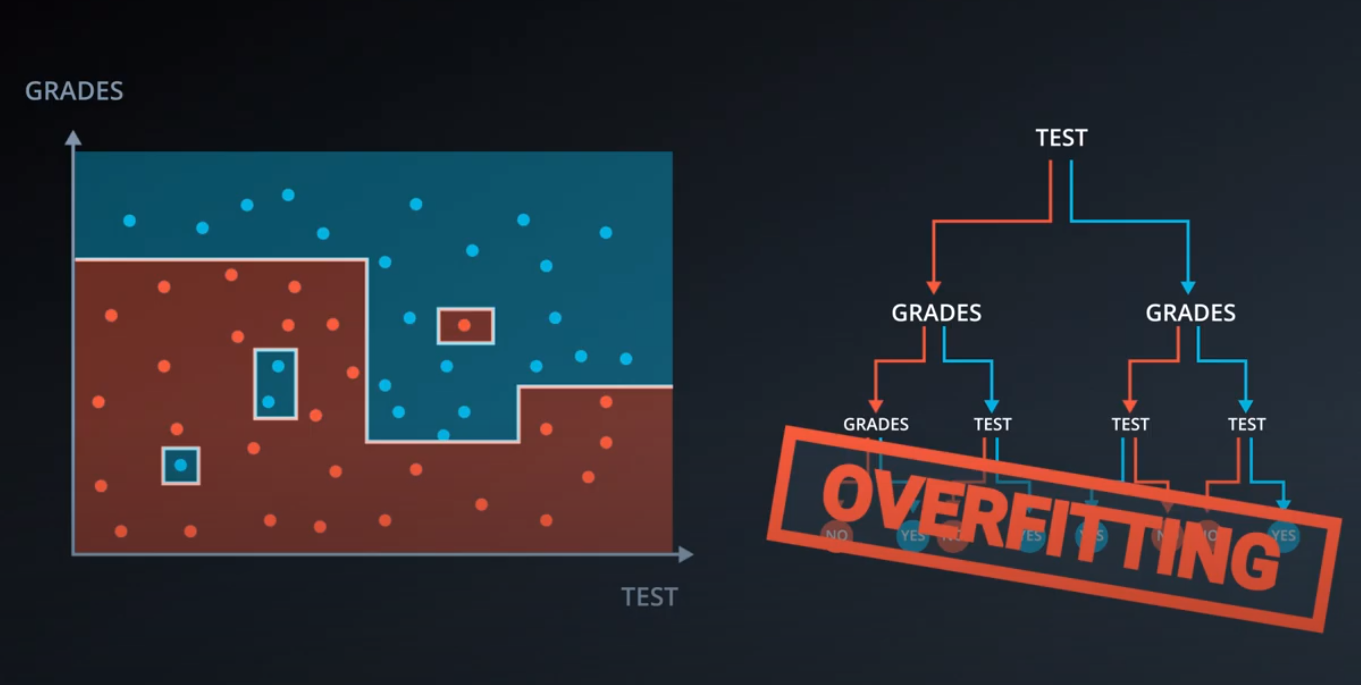
-
-
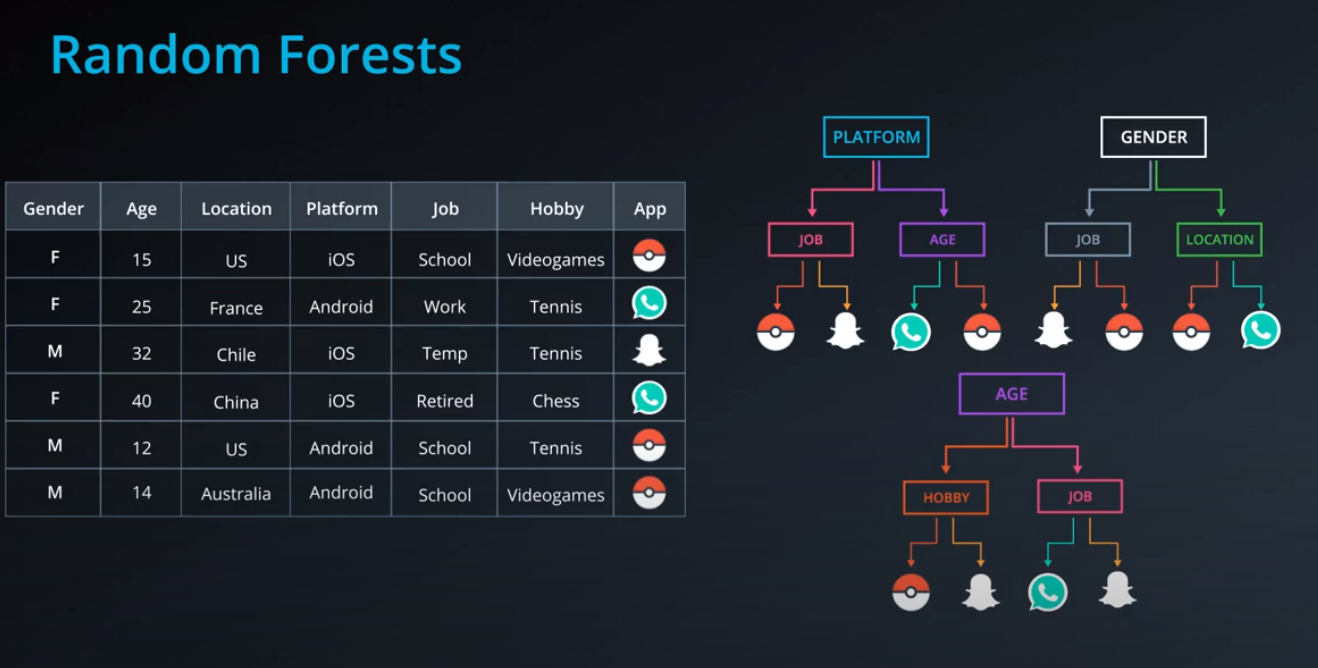
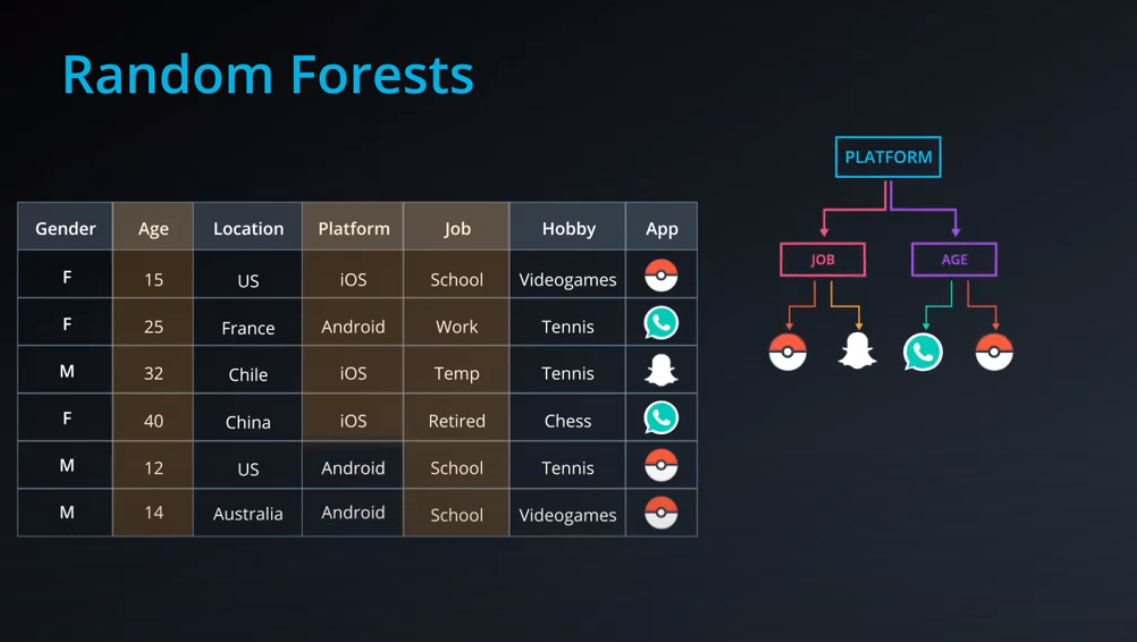
- Build many decision trees based on different features
-
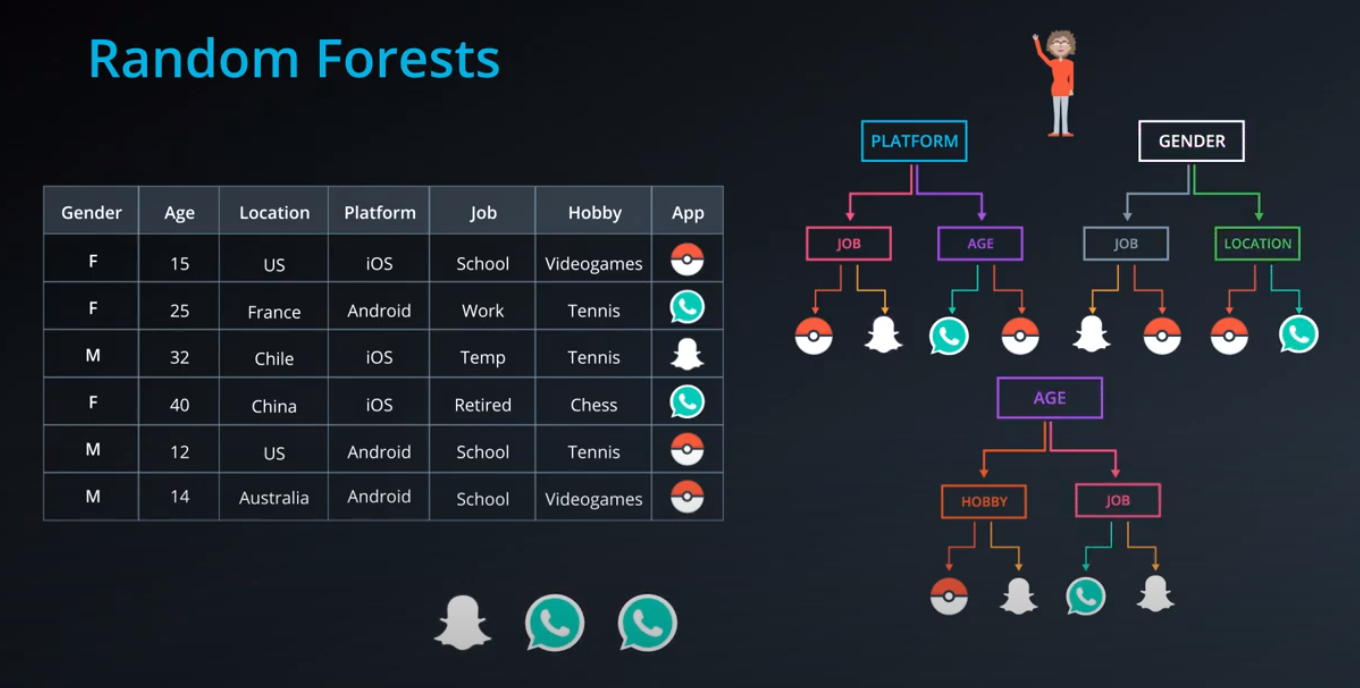
- Now, lets run a data point against all trees and vote. The most frequent output wins. The ensemble of trees will recommend whatsapp in this case
-
-
Bagging
-
A set of "weak" learners combined
-
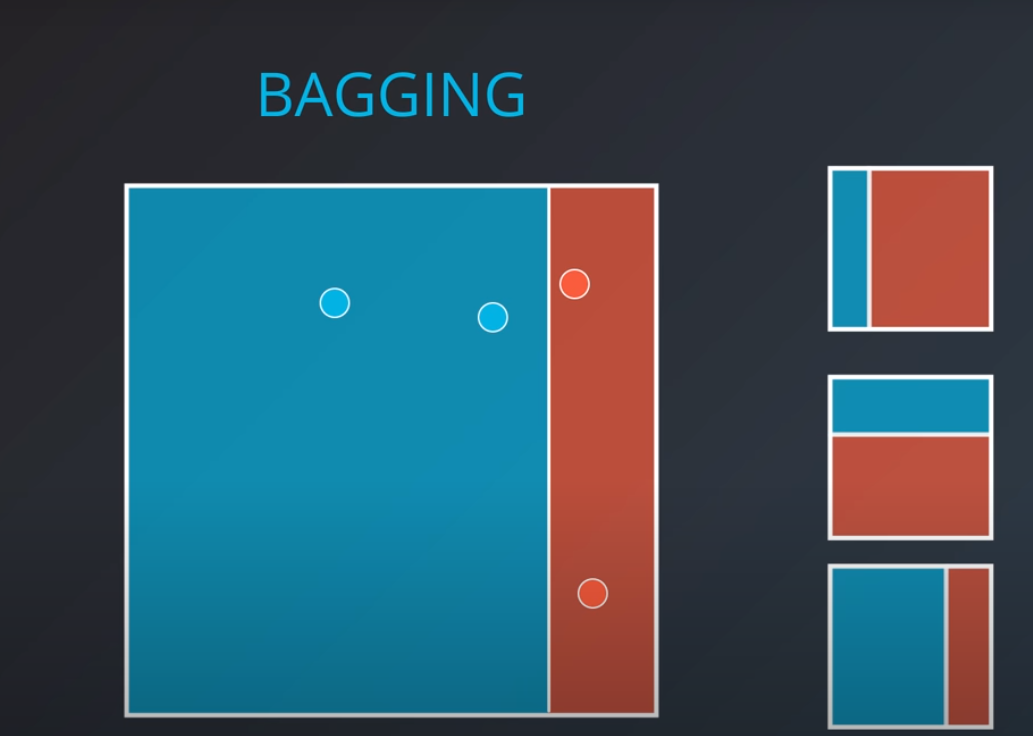
-
We generate a weak learner based on a random subset of data. After that we do voting
-
-
Adaboost
-
In this model one weak learner learns from another
-
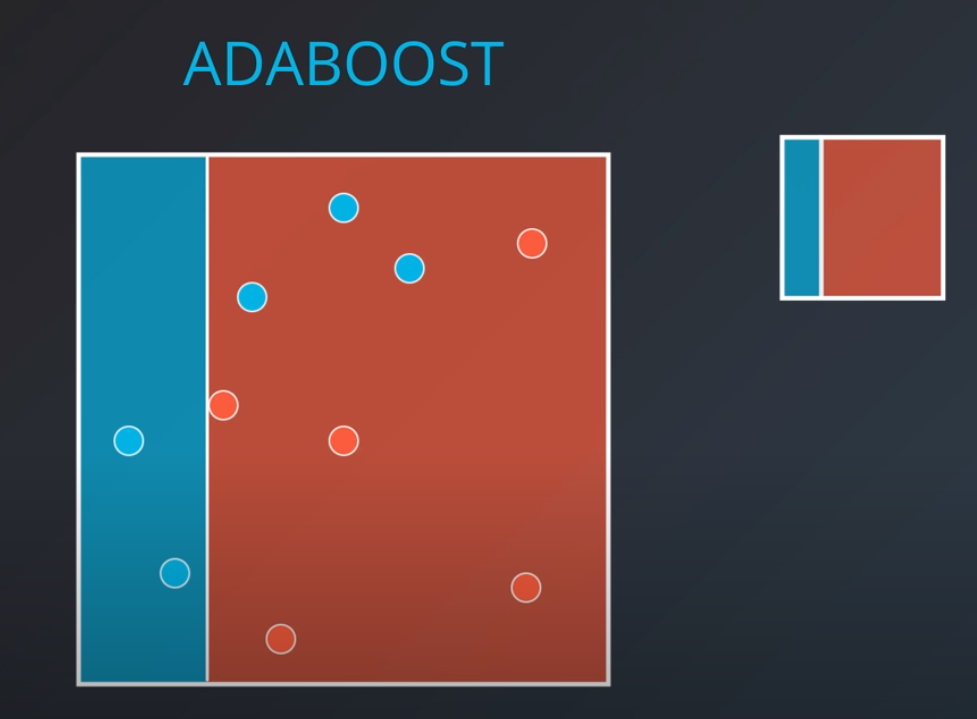
- We first generate a weak learner
-
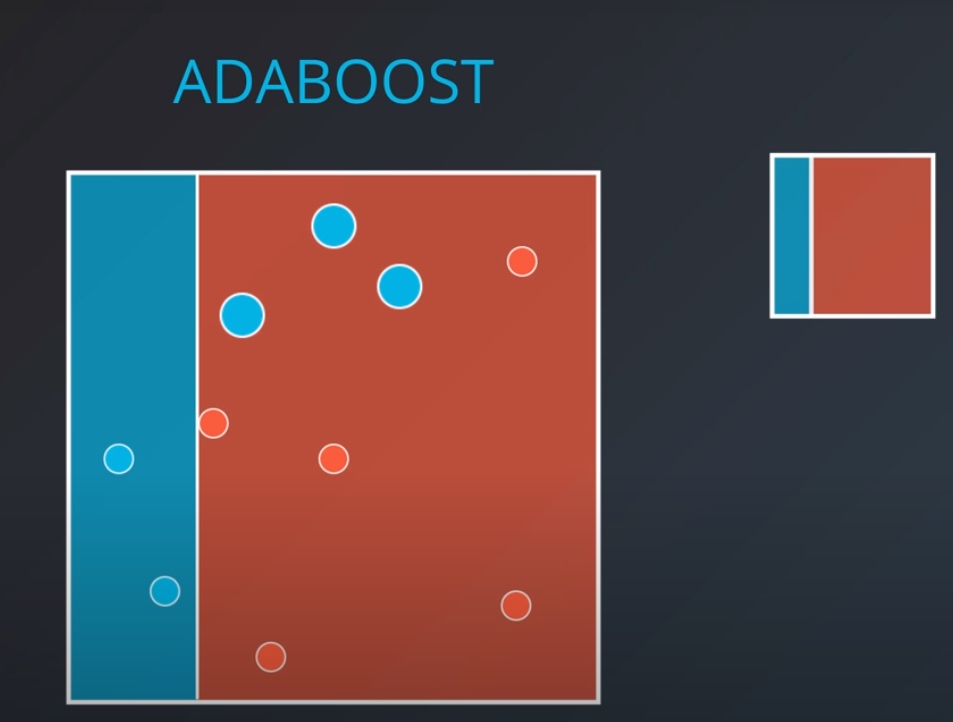
- The second weak learner will get the miss-classified points from the first one and make them "bigger / more valuable". In other words, we will punish the model more if it misses these points
-
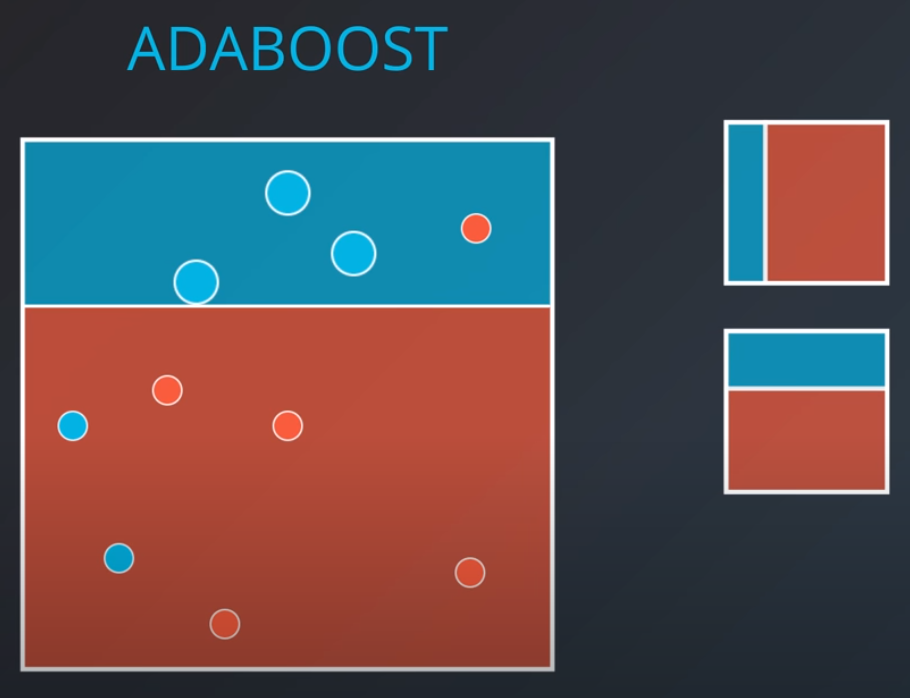
-
-

- With some voting we will get a model like this
-
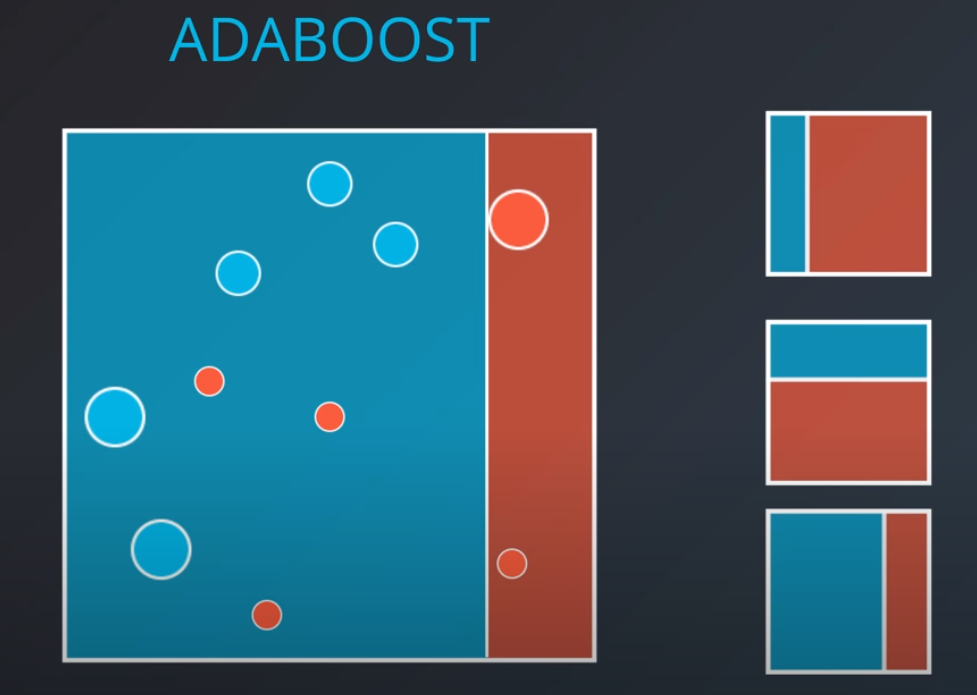
Weighting the Data
-
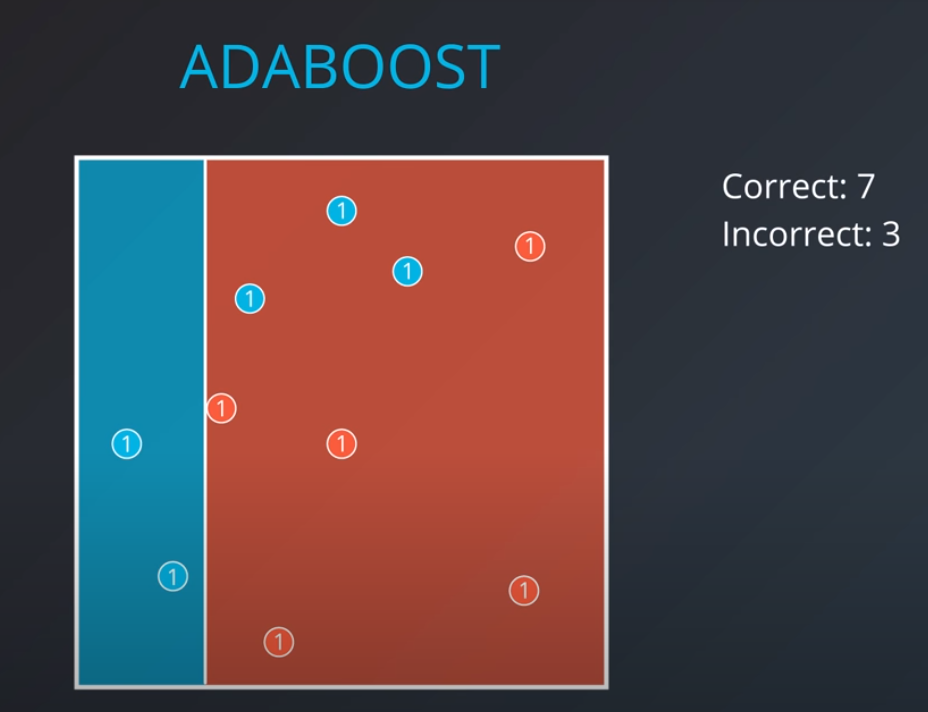
We first generate an initial model
-
- If we get the three incorrectly classified blue points and weight them by a factor of 7 correct over 3 incorrect that will give us 2.33
-
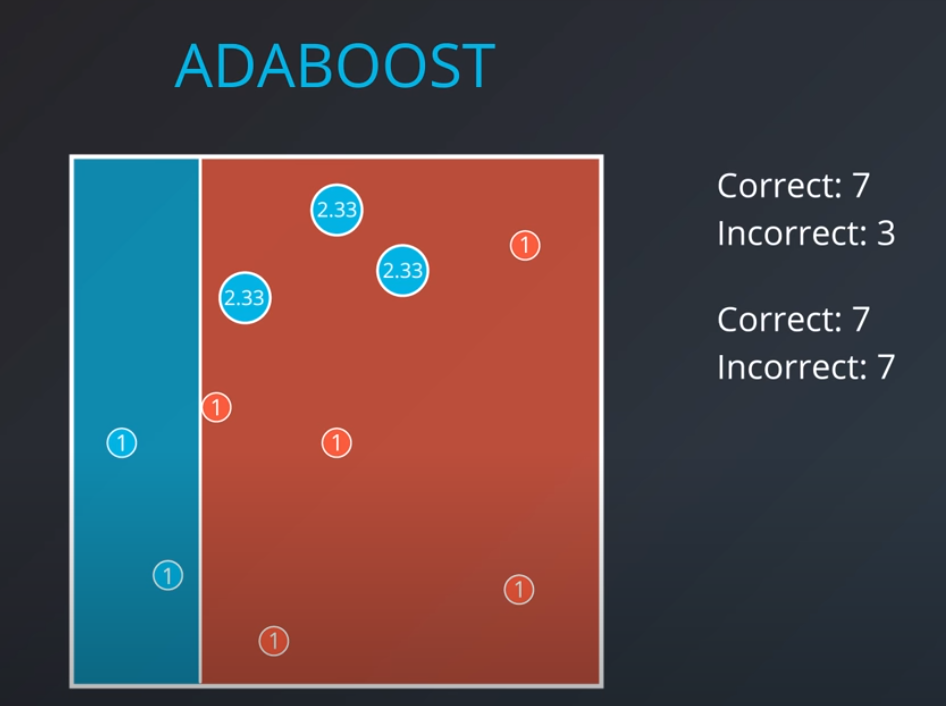
- 2.33 * 3 = 7 (now we have 7 incorrect points in terms of weights)
-
The second model tries to fit our new weighted data best
-
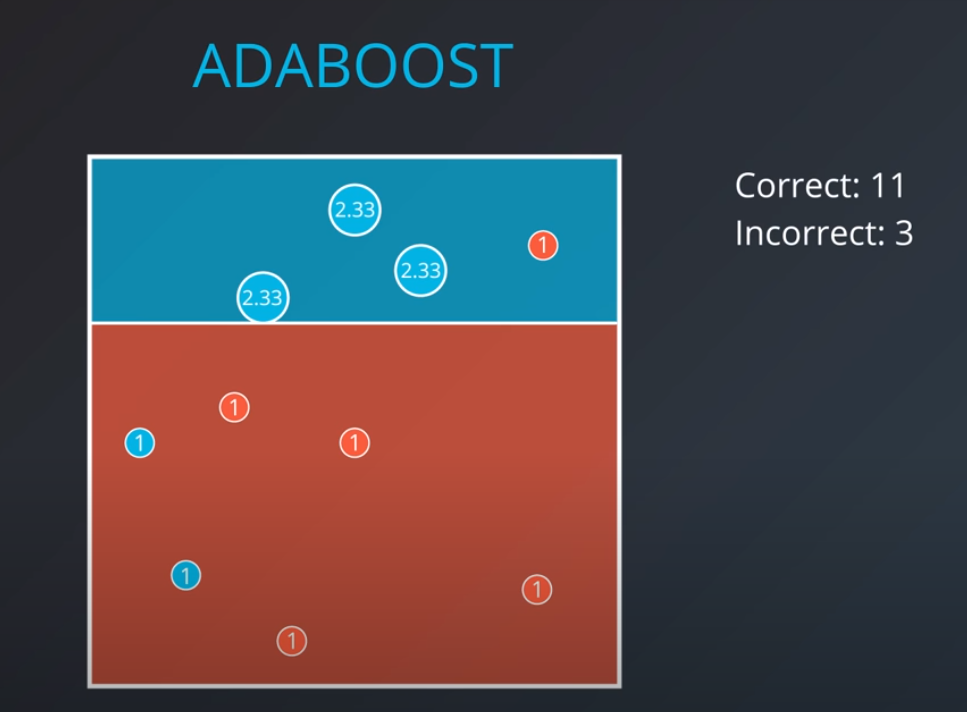
- Based on this new model we generate new weights. In this case 11 corrects (4 reds and 6.99 blues) / 3 incorrect (2 blue and 1 red) = 3.66
-
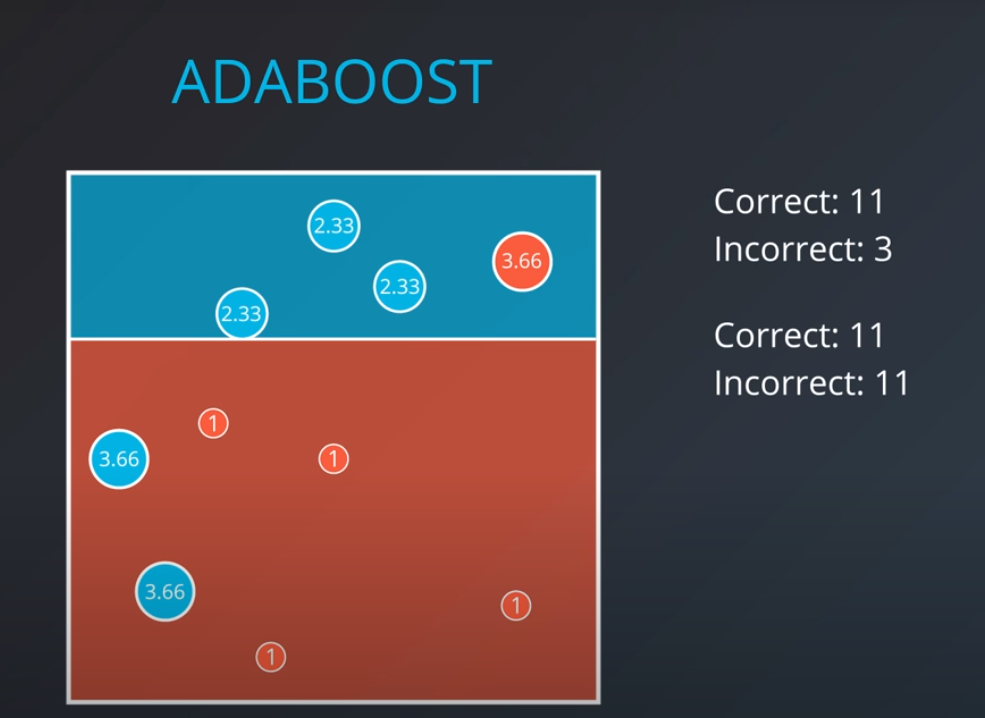
-

- We can build as many "weak" models as we want with this technic.
-
In order to combine models we will actually weight them based on how well they are doing.
-

-
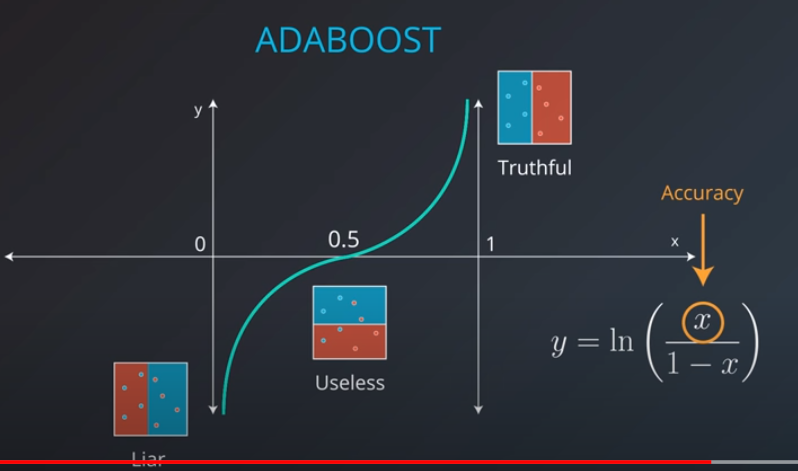
-

-
The original paper - A link to the original paper on boosting by Yoav Freund and Robert E. Schapire.
-
An explanation about why boosting is so important - A great article on boosting by a Kaggle master, Ben Gorman.
-
A useful Quora post - A number of useful explanations about boosting.
-

-
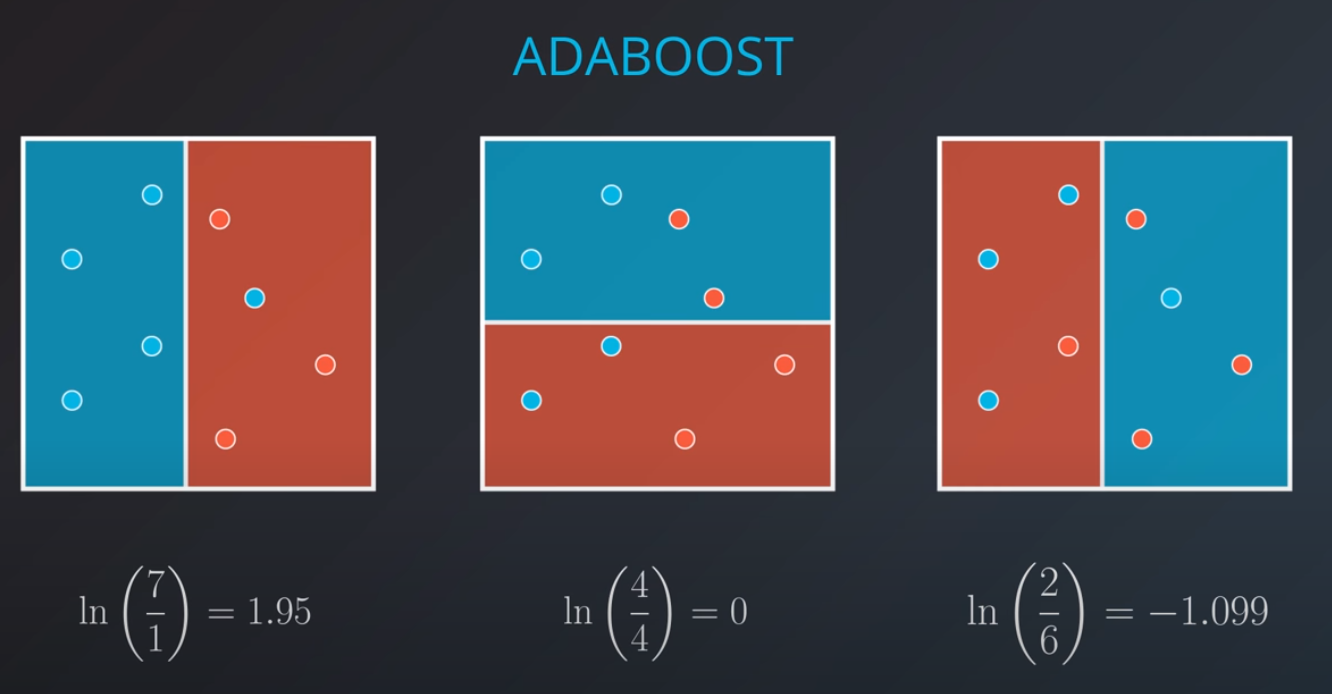
-
The first model has 7 points (red and blue) classified correctly, and 1 classified incorrectly (blue)
-
We will listen to the first model (really precise), and the last one. However, for the last one we will do the opposite of whatever it recommends since its recommendations are all wrong
-
-
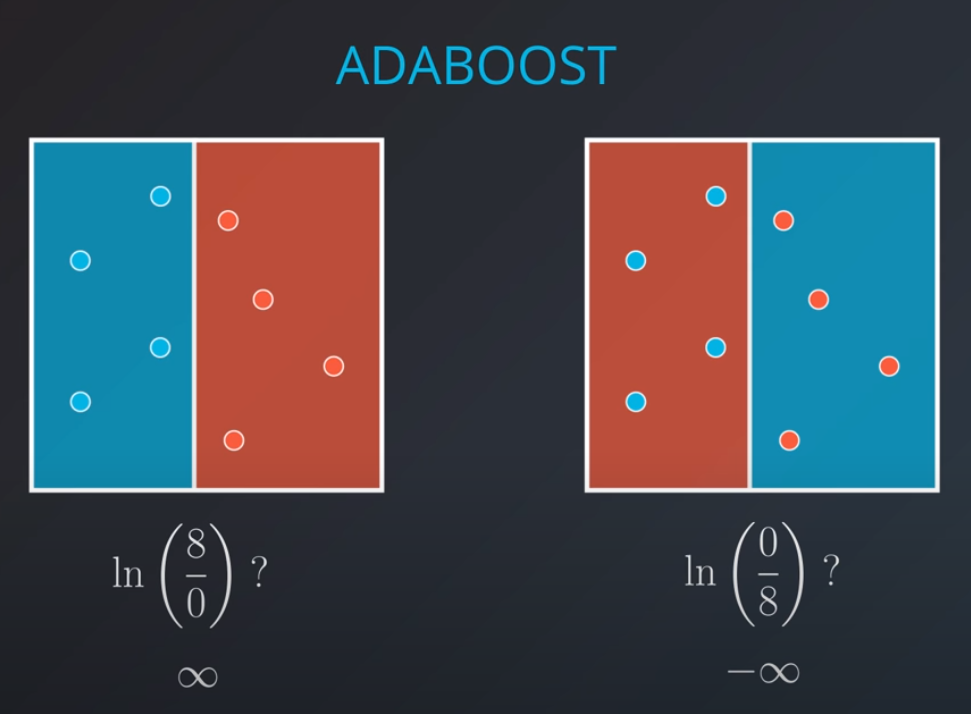
-
Now we can calculate the weights of each model
-

-

-

-
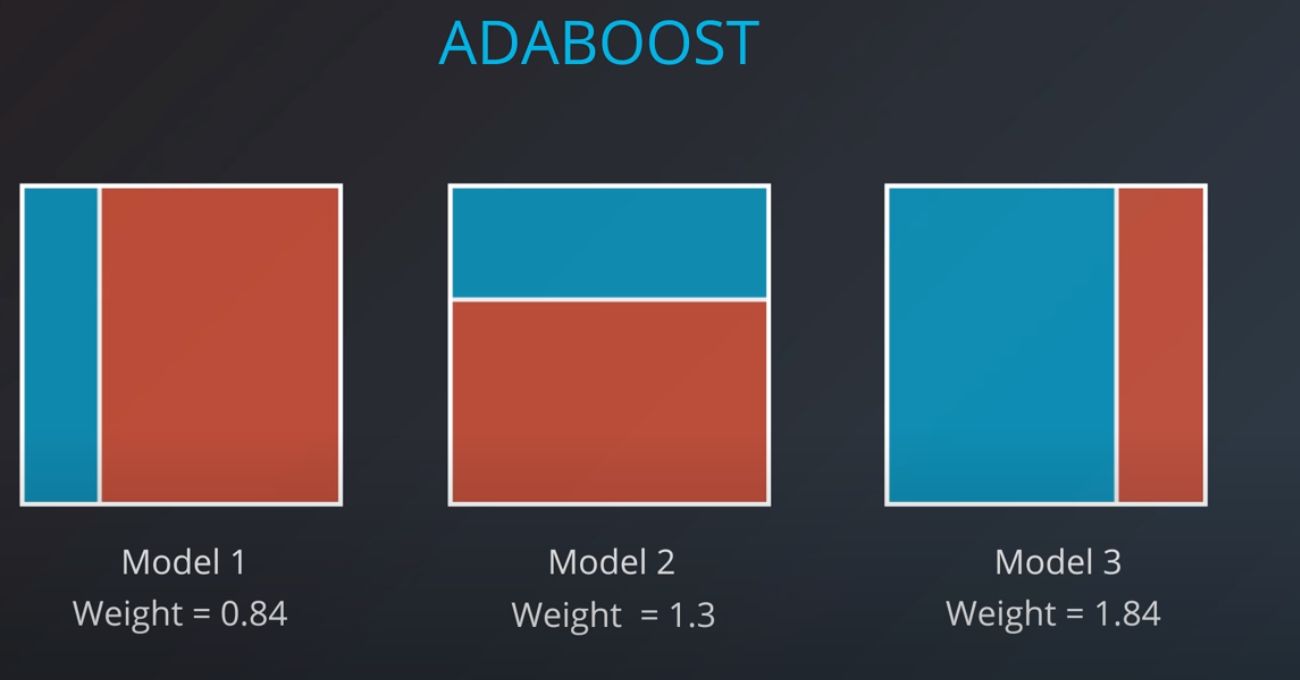
-

-
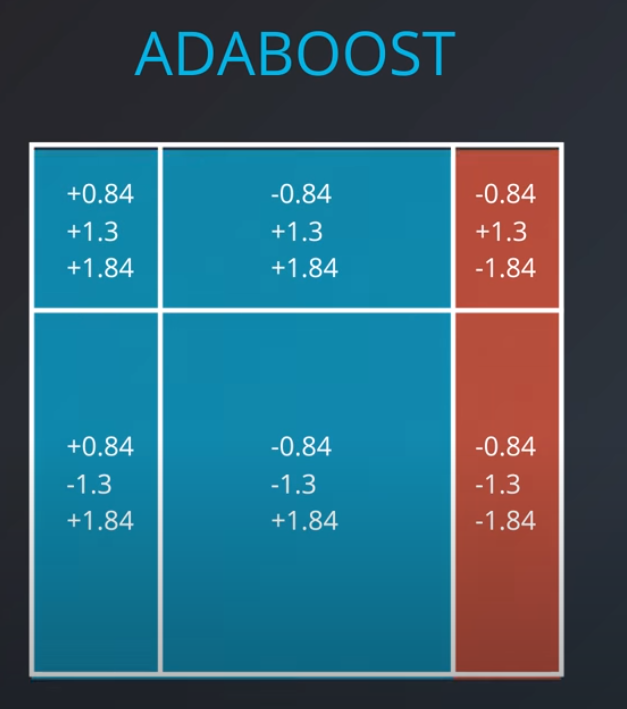
- We aggregate the weak learners by adding their values to each region, and we calculate the sums which gives us this values.
-

-
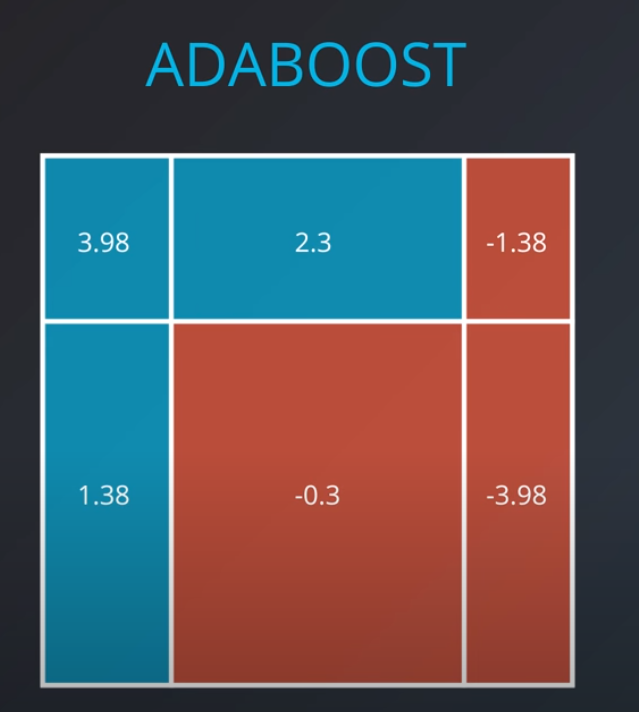
-

-
-
-
AdaBoost in sklearn
-
Building an AdaBoost model in sklearn is no different than building any other model. You can use scikit-learn's AdaBoostClassifier class. This class provides the functions to define and fit the model to your data.
-
from sklearn.ensemble import AdaBoostClassifier model = AdaBoostClassifier() model.fit(x_train, y_train) model.predict(x_test)
-
In the example above, the model variable is a decision tree model that has been fitted to the data
x_trainandy_train. The functions fit and predict work exactly as before. -
Hyperparameters
-
When we define the model, we can specify the hyperparameters. In practice, the most common ones are
-
base_estimator: The model utilized for the weak learners (Warning: Don't forget to import the model that you decide to use for the weak learner).
-
n_estimators: The maximum number of weak learners used.
-
For example, here we define a model which uses decision trees of max_depth 2 as the weak learners, and it allows a maximum of 4 of them.
-
-
from sklearn.tree import DecisionTreeClassifier model = AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth=2), n_estimators = 4)
-
-
-
Gradient boosting is a machine learning technique for regression and classification problems, which produces a model in the form of an ensemble of weak prediction models, typically decision trees. It builds the model in a stage-wise fashion like other boosting methods do, and it generalizes them by allowing optimization of an arbitrary differentiable loss function.
-
New to XGBoost
-
Gradient boosting involves three main steps. The first step that is required is that a loss function be optimized. The loss function must be differentiable. A loss function measures how well a machine learning model fits the data of a certain phenomenon. Different loss function may be used depending on the type of problem. Different loss function can be used on speech or image recognition, predicting the price of real estate, and describing user behavior on a web site. The loss function depends on the type of problem. For example, regression may use a squared error and classification may use logarithmic loss.
-
The second step is the use of a weak learner. In gradient boosters, the weak learner is a decision tree. Specifically regression trees are used that output real values for splits and whose output can be added together, allowing subsequent models outputs to be added to correct the residuals in the predictions of the previous iteration. The algorithms for classification problems and for regression problems use a different algorithm, however, they both use the same approach for splitting the data into groups. That approach is regression decision trees. Even classification problems use regression decision trees. In regression decision trees, the final answer is a range of real numbers, this makes it’s relatively simple to split the data based on the remaining error at each step. Steps are taken to ensure the weak learner remain weak yet is still constructed in a greedy fashion. It is common to constrain the weak learners in sundry ways. Often, weak learners can be constrained using a maximum number of layers, nodes, splits or leaf nodes.
-
The third step is combing many weak learners in an additive fashion. Decision trees are added one at a time. A gradient descent procedure is used to minimize the loss when adding trees. That’s the gradient part of gradient boosters. Gradient descent optimization in the machine learning world is typically used to find the parameters associated with a single model that optimizes some loss function. In contrast, gradient boosters are meta-models consisting of multiple weak models whose output is added together to get an overall prediction. The gradient descent optimization occurs on the output of the model and not the parameters of the weak models.
-
Let’s look at this process pictorially. Below we can see that gradient boosting adds sub-models incrementally to minimize a loss function. Earlier we said that gradient boosting involved three main steps. In our example below the weak learner being used is a decision tree. Secondly, the trees are added sequentially. Lastly, the error of the model is being reduced.
-
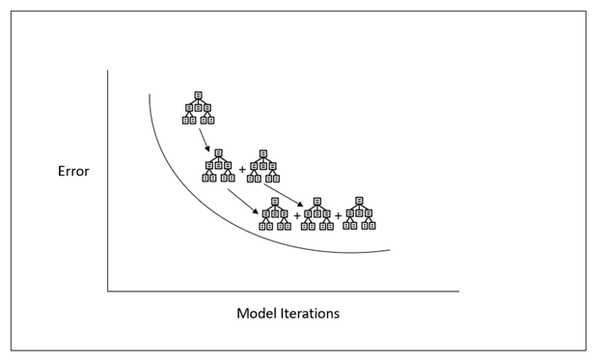
-
Recap
-
In this lesson, you learned about a number of techniques used in ensemble methods. Before looking at the techniques, you saw that there are two variables with tradeoffs Bias and Variance.
-
High Bias, Low Variance models tend to underfit data, as they are not flexible. Linear models fall into this category of models.
-
High Variance, Low Bias models tend to overfit data, as they are too flexible. Decision trees fall into this category of models.
-
Ensemble Models
-
In order to find a way to optimize for both variance and bias, we have ensemble methods. Ensemble methods have become some of the most popular methods used to compete in competitions on Kaggle and used in industry across applications.
-
There were two randomization techniques you saw to combat overfitting:
-
Bootstrap the data - that is, sampling the data with replacement and fitting your algorithm and fitting your algorithm to the sampled data.
-
Subset the features - in each split of a decision tree or with each algorithm used an ensemble only a subset of the total possible features are used.
-
-
-
Techniques
-
You saw a number of ensemble methods in this lesson including:
-
BaggingClassifier
-
RandomForestClassifier
-
AdaBoostClassifier
-
Another really useful guide for ensemble methods can be found in the documentation here. These methods can also all be extended to regression problems, not just classification.
-
-
-



































-
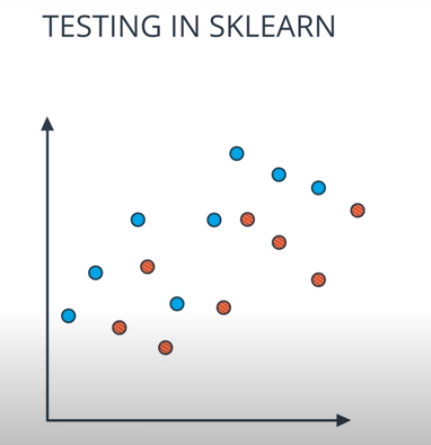
Model Evaluation Metrics
-
How well is my model doing?
-
Classification
-
-
-
-
# Import statements from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score import pandas as pd import numpy as np # Import the train test split # http://scikit-learn.org/0.16/modules/generated/sklearn.cross_validation.train_test_split.html from sklearn.cross_validation import train_test_split # Read the data. data = np.asarray(pd.read_csv('data.csv', header=None)) # Assign the features to the variable X, and the labels to the variable y. X = data[:,0:2] y = data[:,2] # Use train test split to split your data # Use a test size of 25% and a random state of 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42) # TODO: Create the decision tree model and assign it to the variable model. model = DecisionTreeClassifier() # TODO: Fit the model to the training data. model.fit(X_train,y_train) # TODO: Make predictions on the test data y_pred = model.predict(X_test) # TODO: Calculate the accuracy and assign it to the variable acc. on the test data acc = accuracy_score(y_test, y_pred)
-
Confusion Matrix
-
-
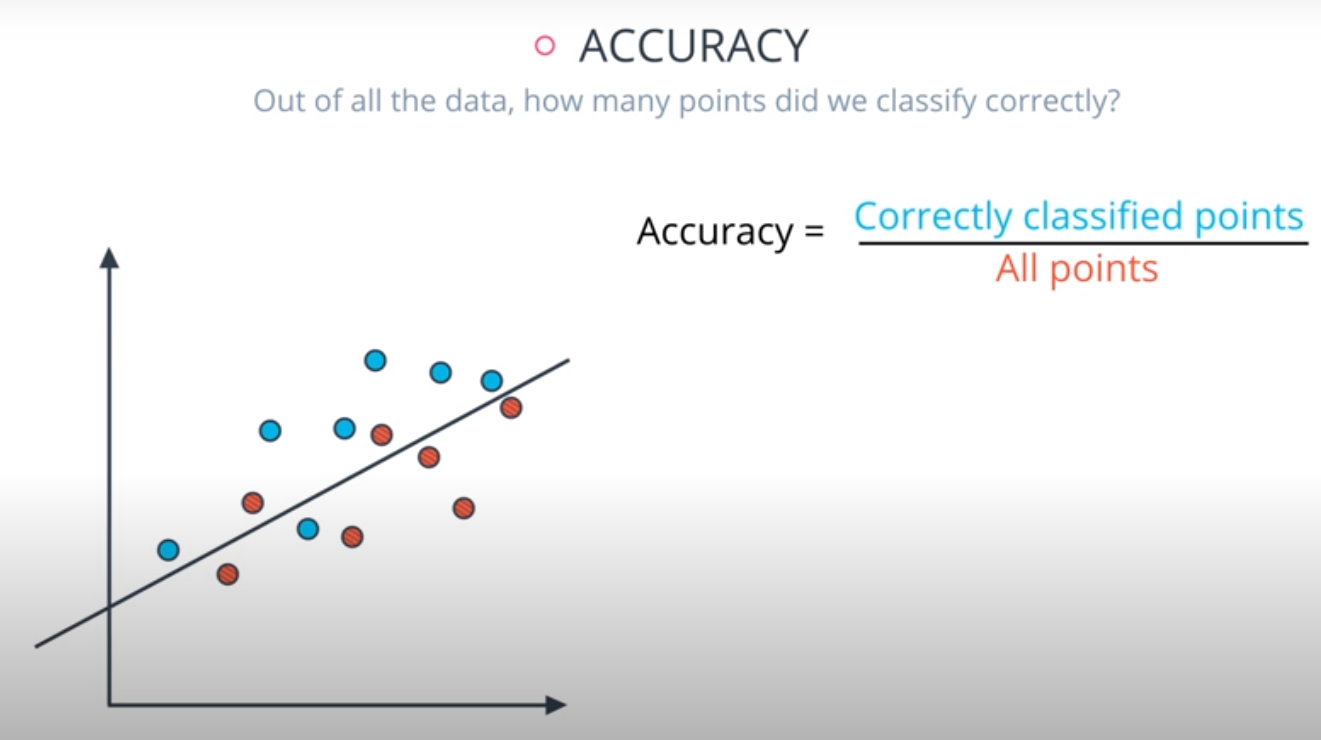
Accuracy
-

-

-
-
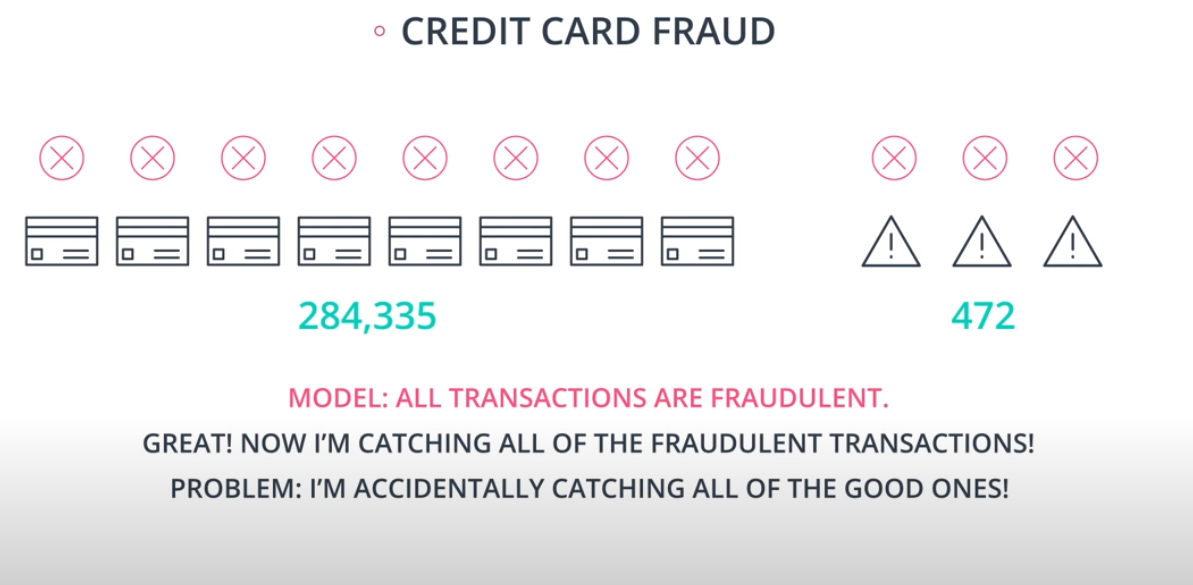
When accuracy wont work
-

- If the model does not catch any of the bad transactions, but only the good ones it does not matter.
-
-
-
-
Precision and Recall
-

-
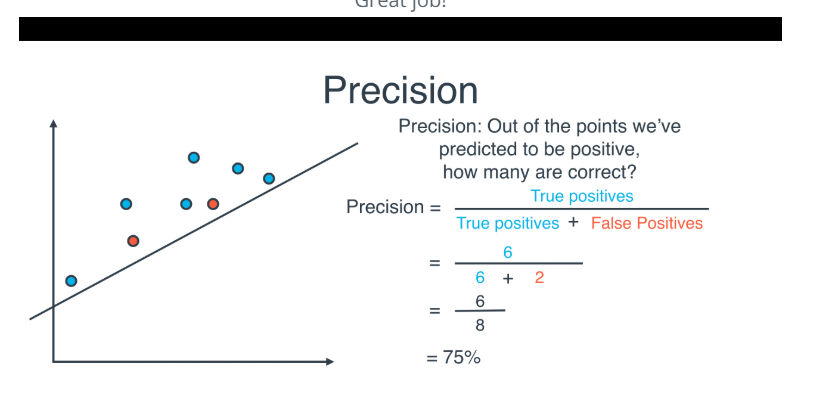
Precision
-

-
Of all the points predicted to be positive, how many of them are actually positive.
-

-
True Positive / True Positive + False Positive
-
In this case it is ok to have low precision since what we want to guarantee is that a sick patient DOES NOT get classified as healthy
-
-
-
-
-
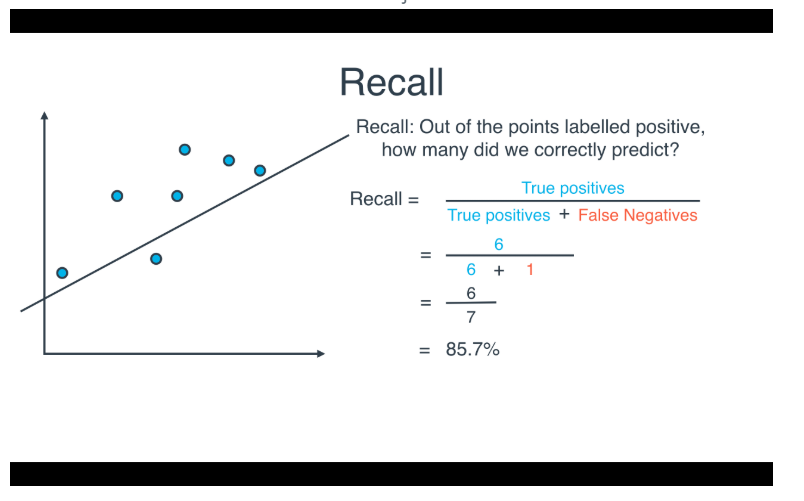
Recall
-

- True Positive / True Positive + False Negative
-
-
-
-
F1 Score
-
Carrying precision and recall all over is kind of inconvenient. How do we combine those two scores into one?
-

-

- Average between precision and recall is not good, does not tell us much
-

-
Harmonic Mean
-
It is always less than the arithmetic mean
-

-
F1 Score is the harmonic mean of precision and recall together
-
-
-
-
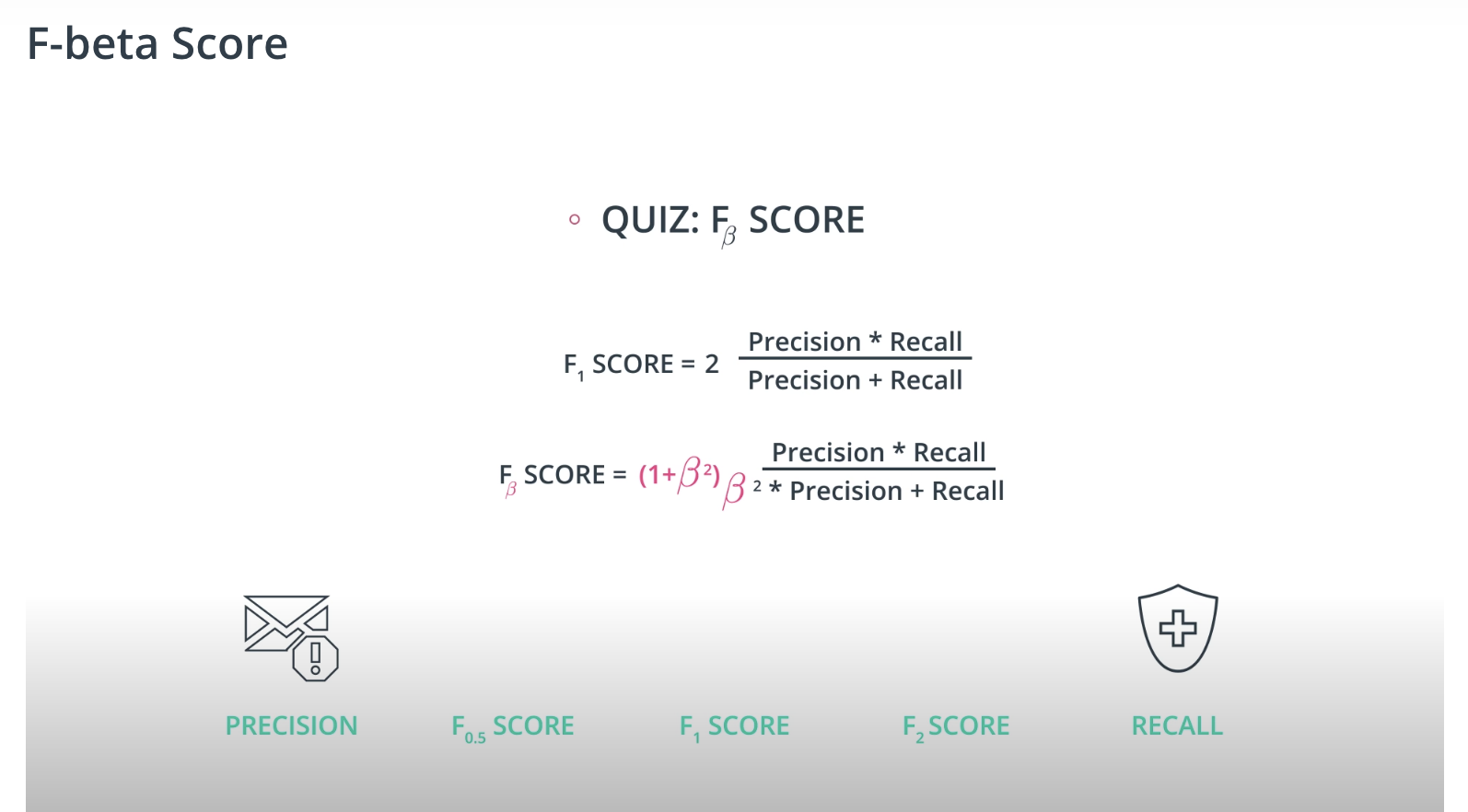
F-beta Score
-
If F1 score is right in the middle, F-beta score will be either near precision or near recall.
-
Larger beta = near to recall
-
Smaller beta = near to precision
-
-
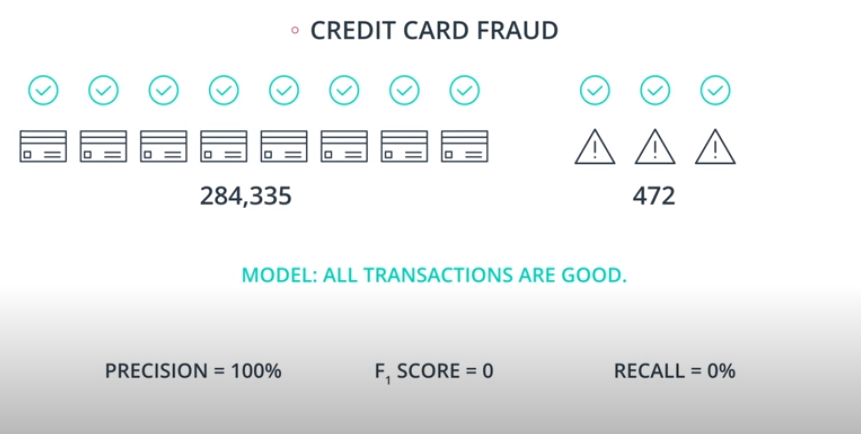
An example of F-beta calibration is the credit card use case. If we use Recall we guarantee that we catch all fraudulent transactions. However, it will probably send incorrect notifications to clients that don't have any fraudulent transactions. That way we need to find a value of
betathat evaluates if the model is covering a good number of fradulante cases without sending too many incorrect notification to "green" clients. -

-
-
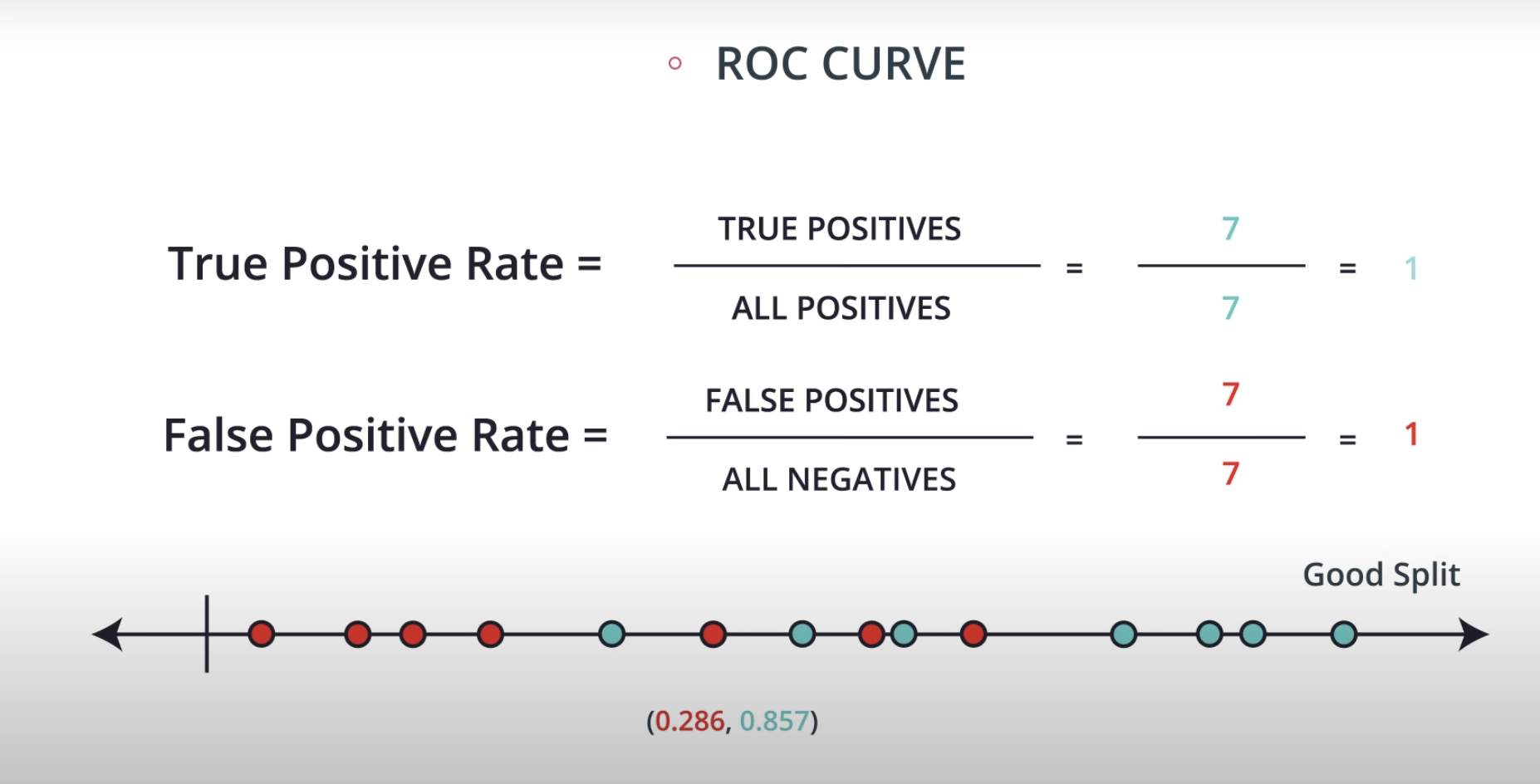
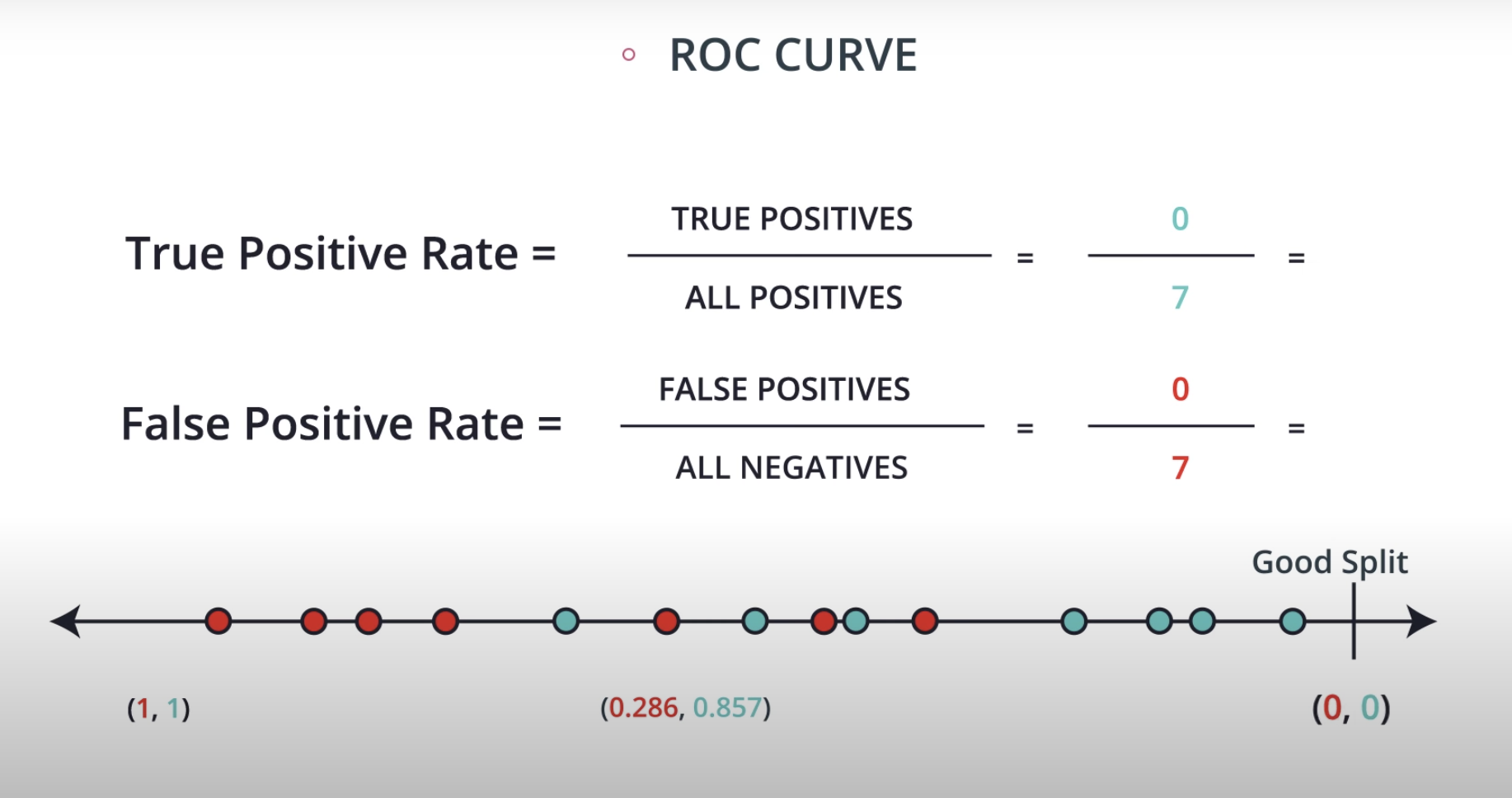
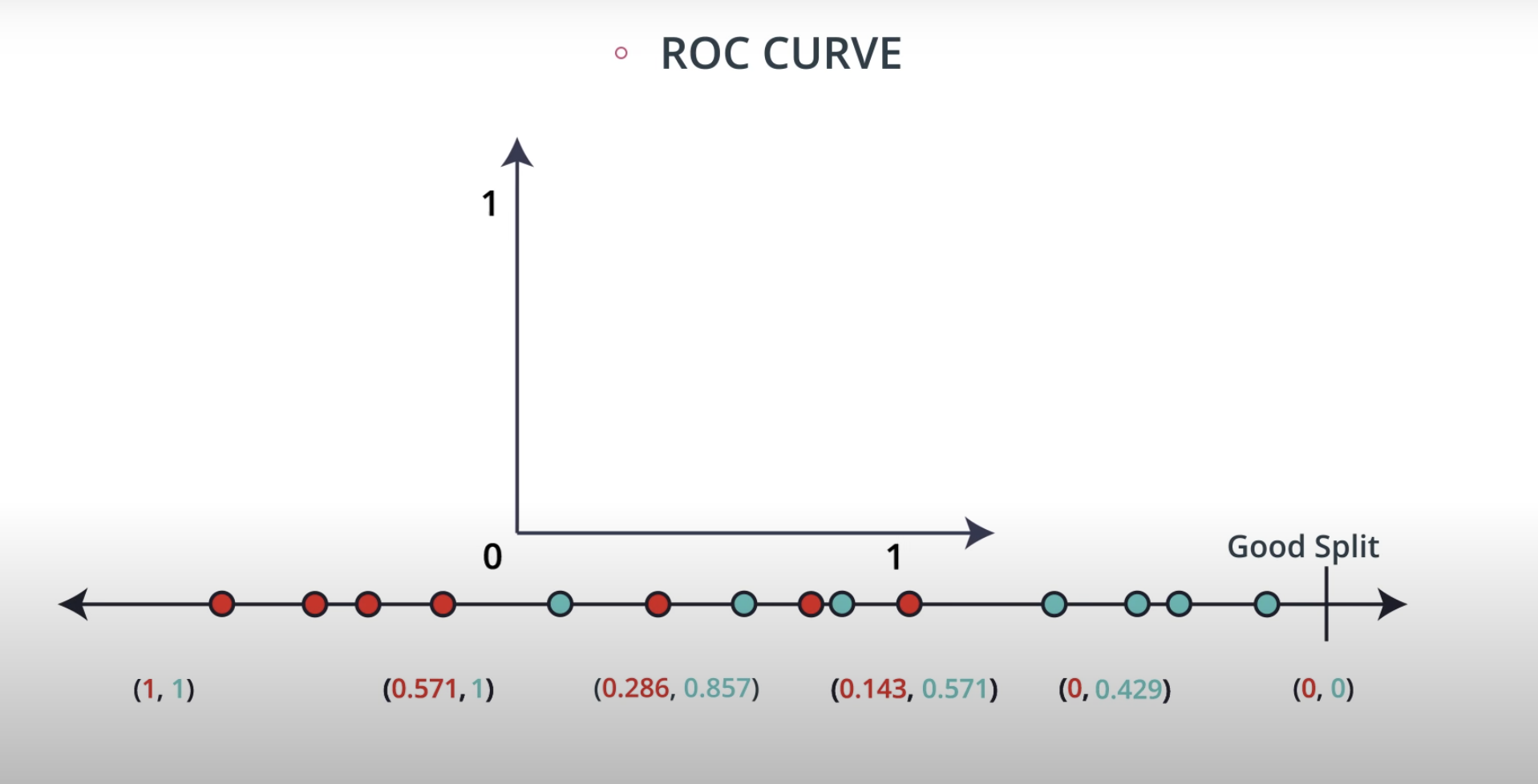
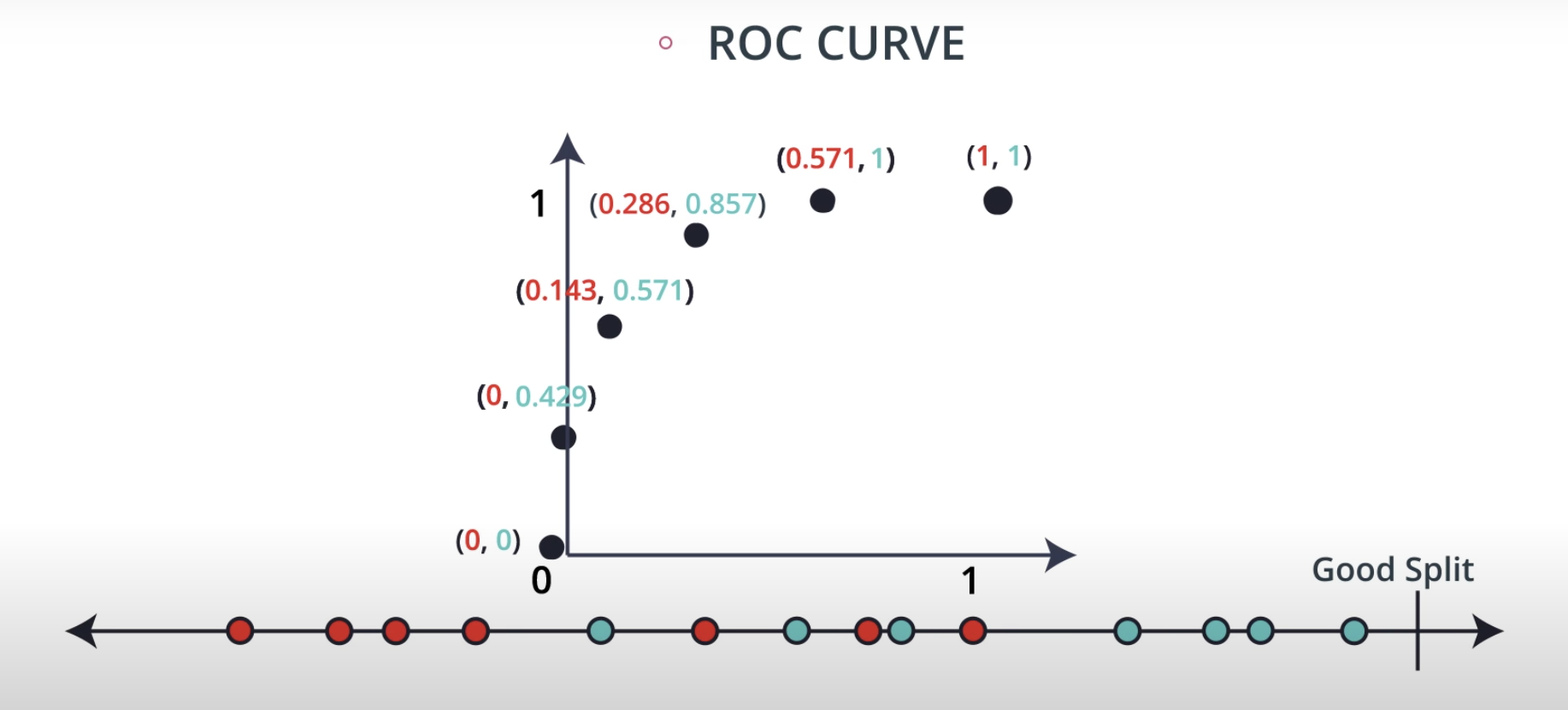
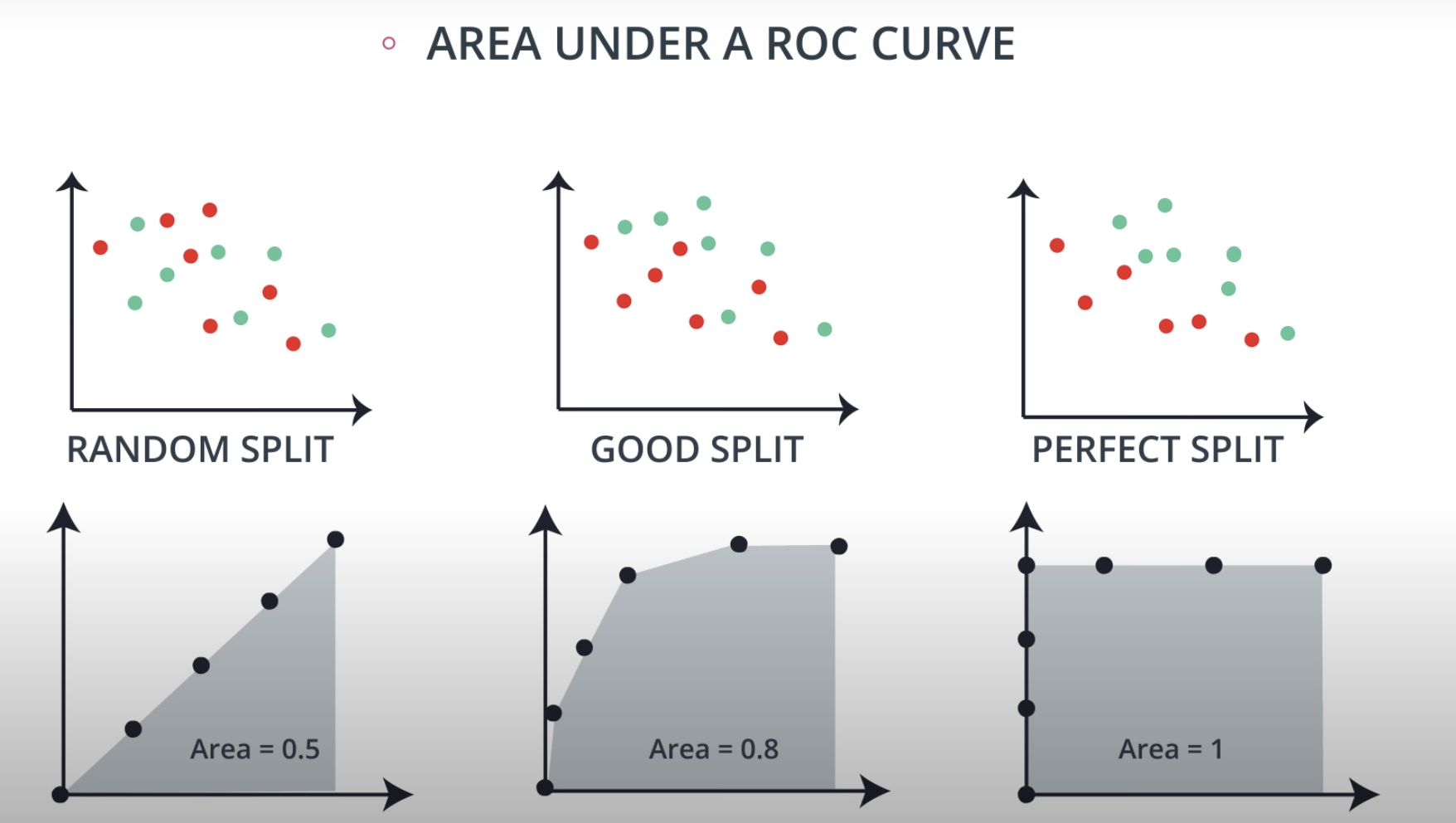
ROC (Receiver Operating Characteristics) Curve
-
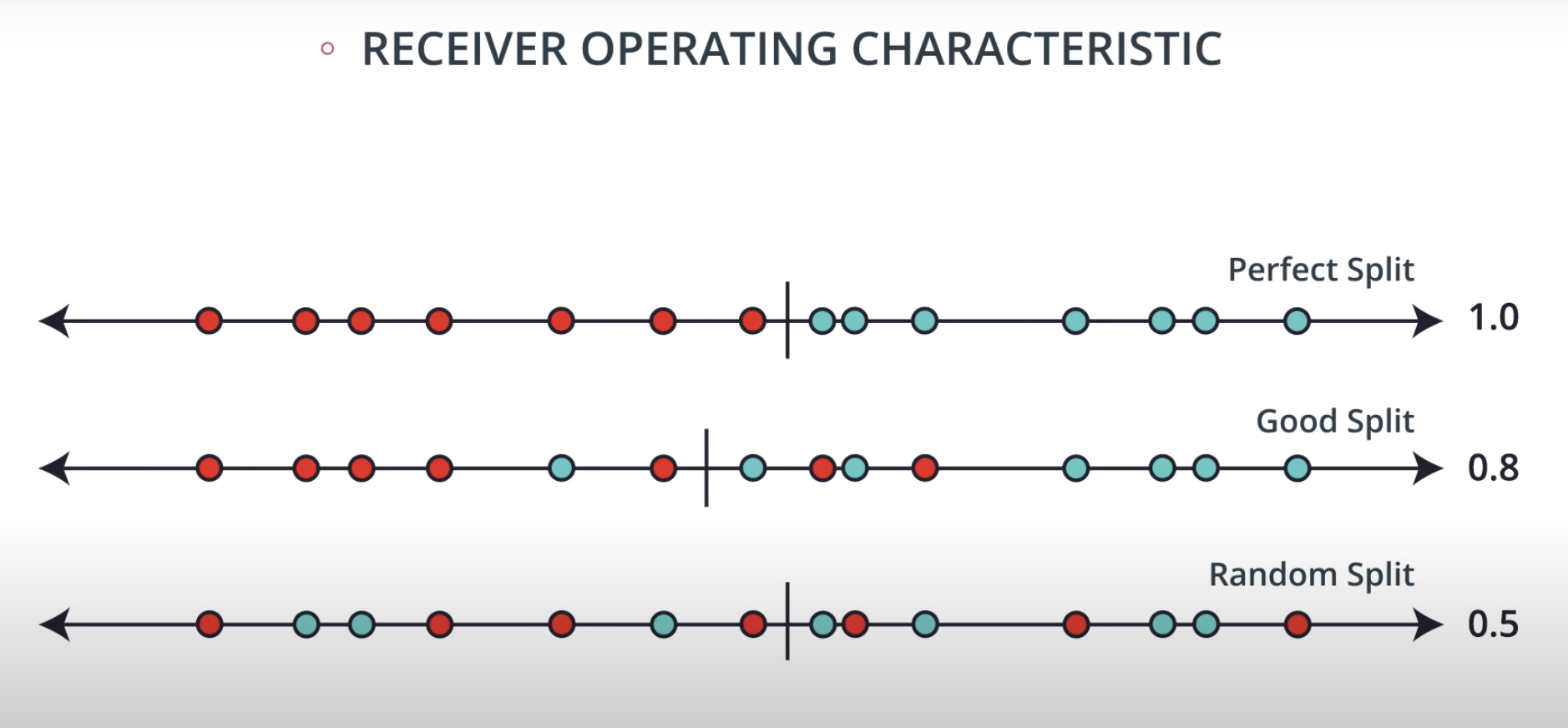
-
On the right of the line we have positives, and the left contain negatives
-
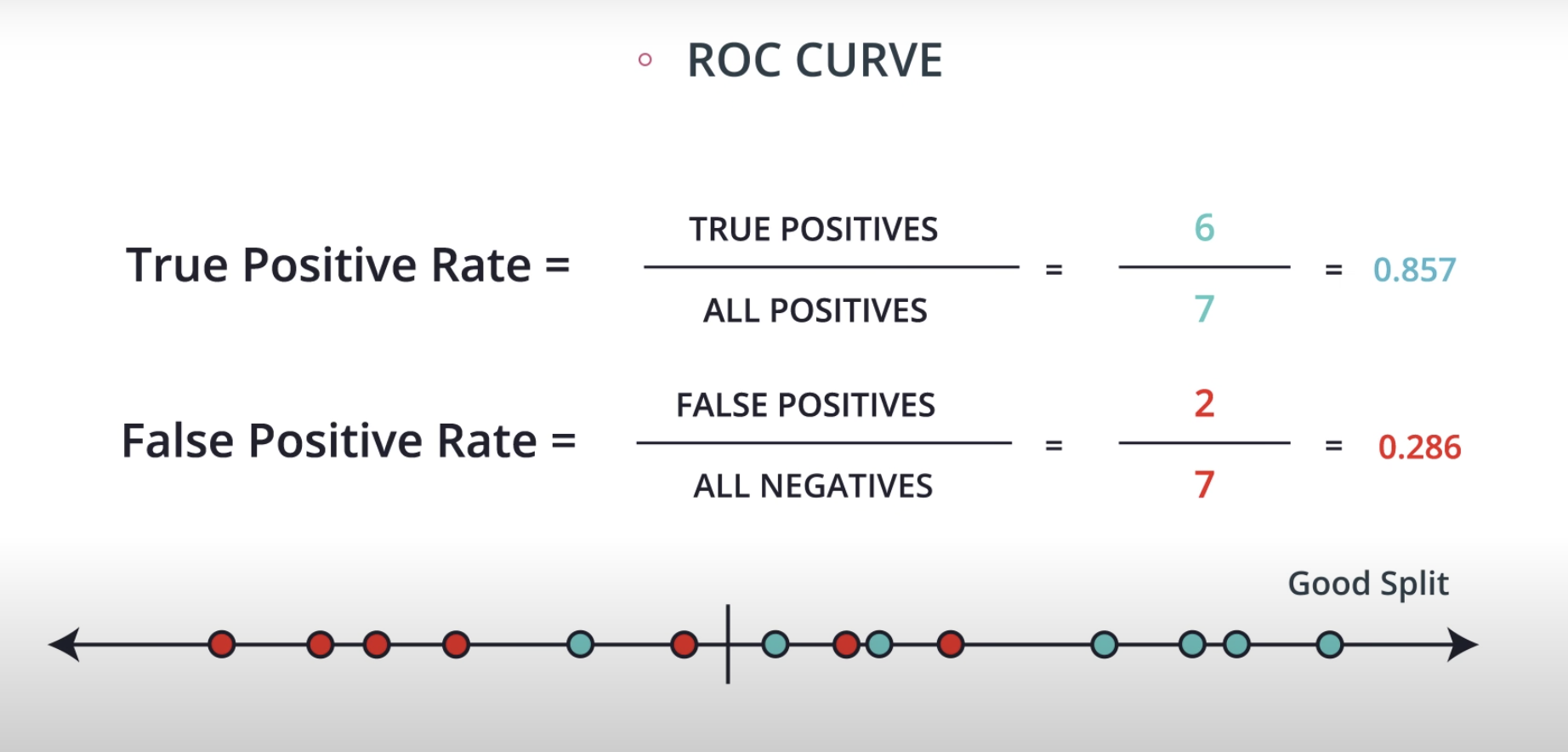
-
-
-
-
-
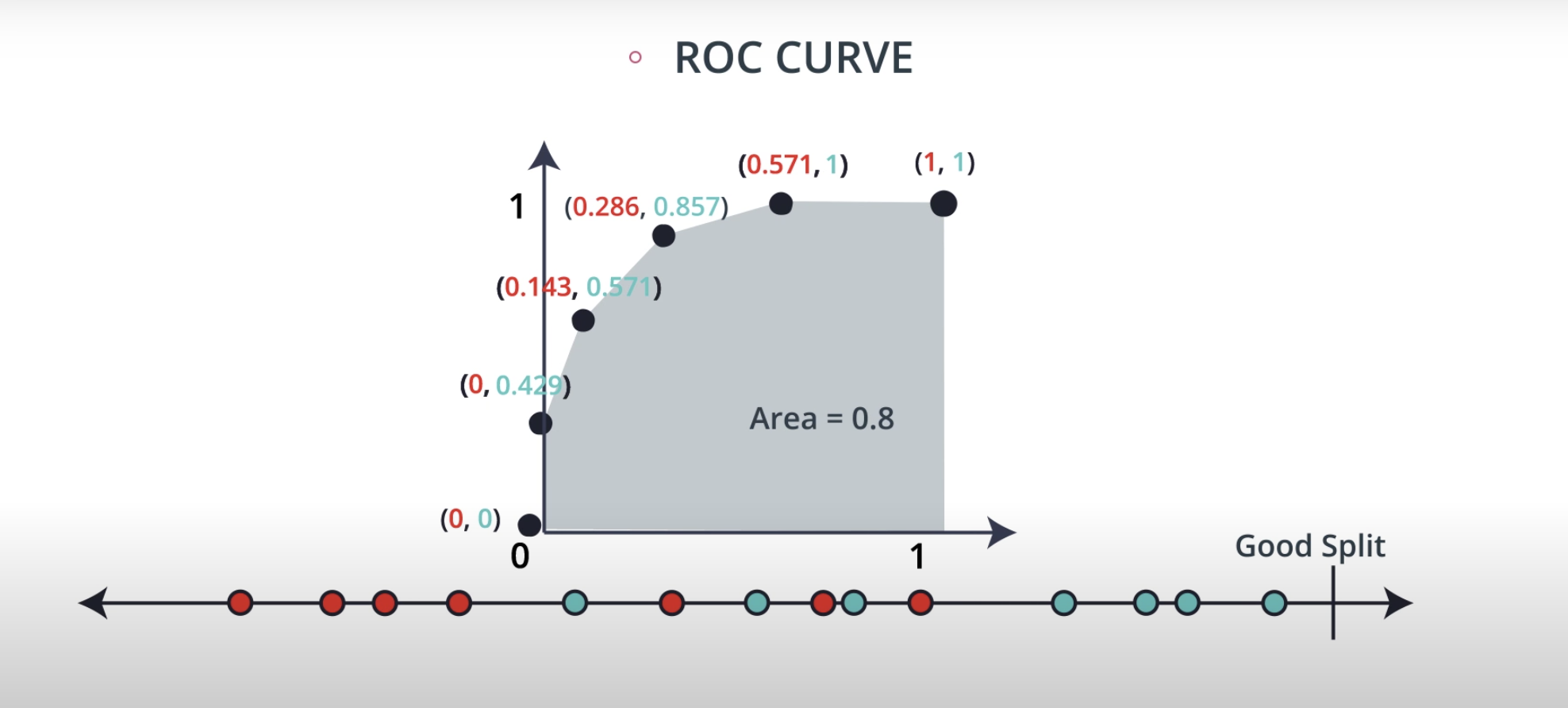
-
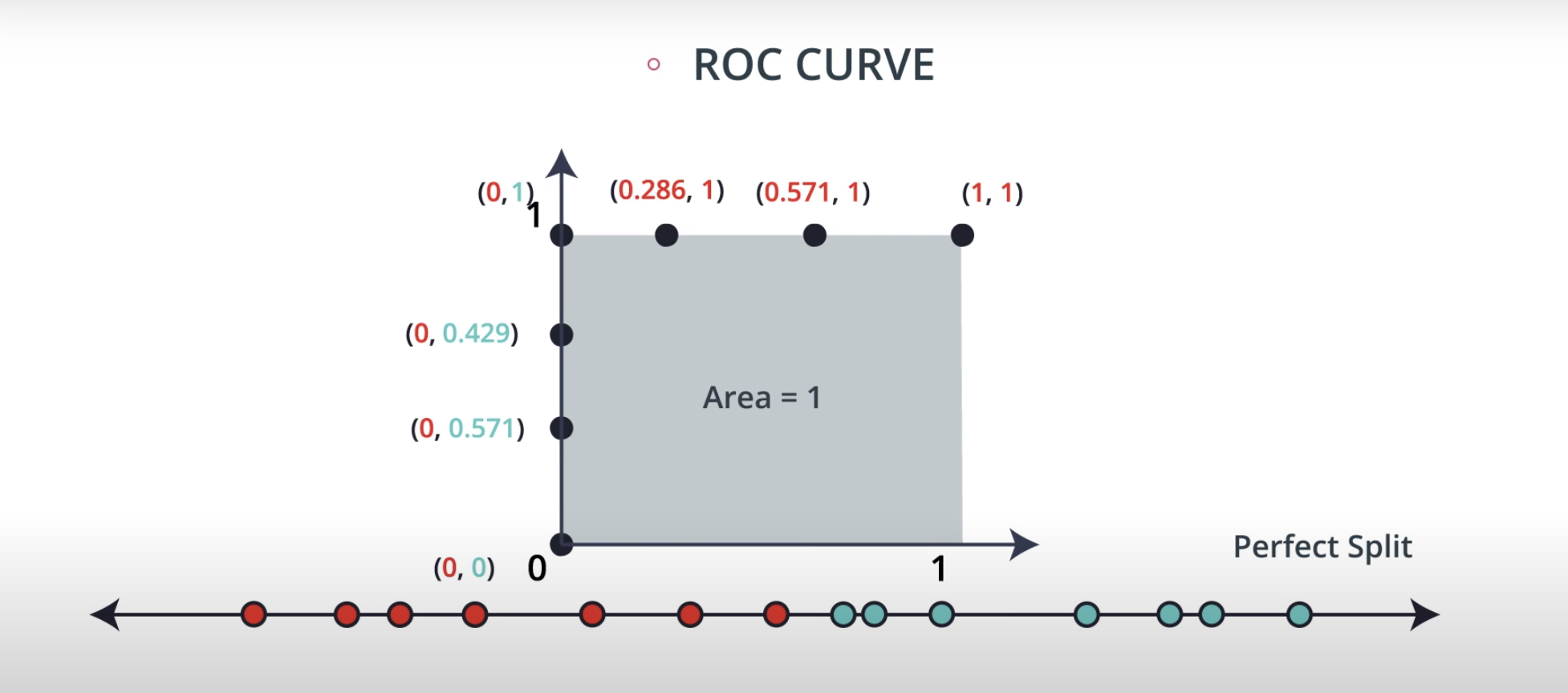
- The "perfect split"
(0,1)when ploted in a graph generates an area of 1
- The "perfect split"
-
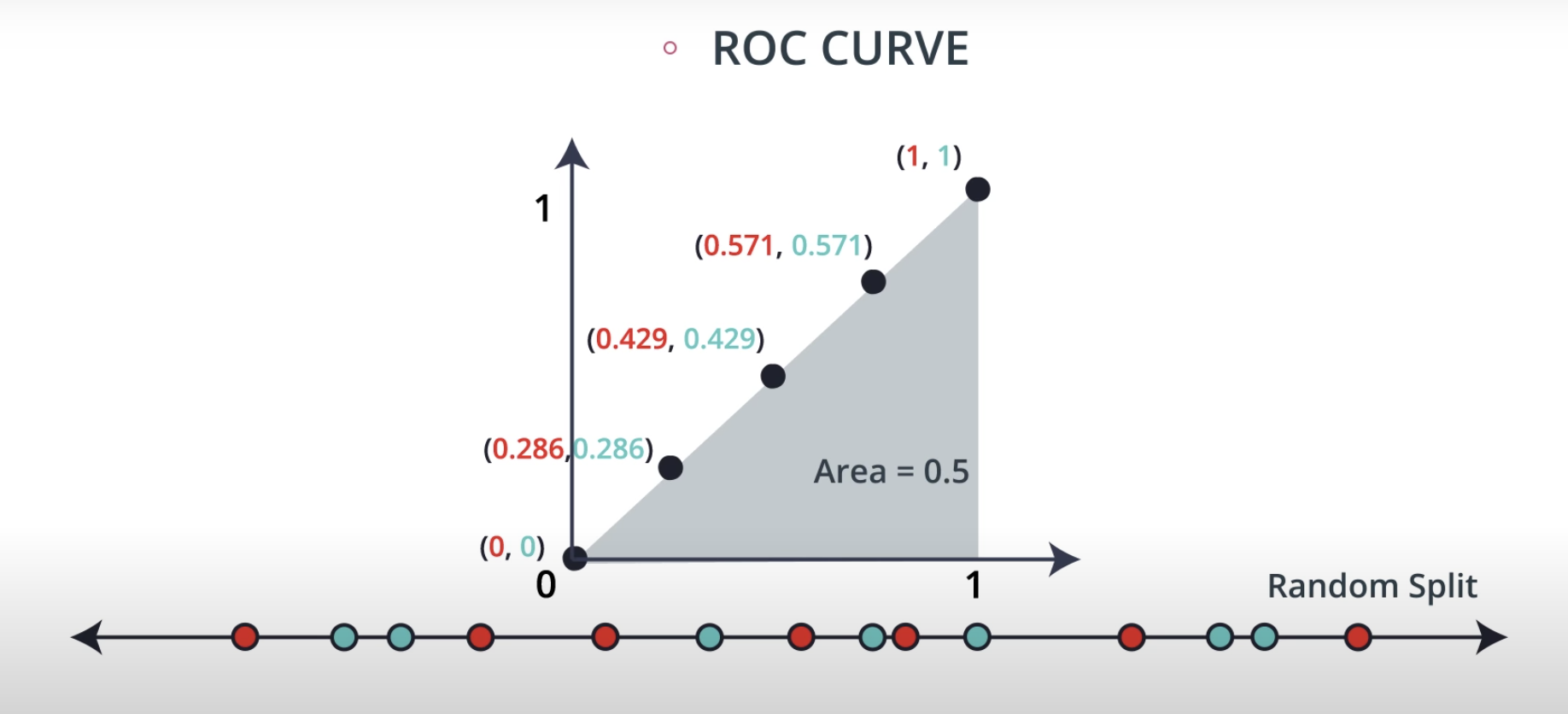
- If the model is random the area is about
0.5
- If the model is random the area is about
-
-
-
-
Regression
-
Mean Absolute Error
-
Mean Squared Error
-
R2 Score
-
We get the error from the linear regression model and divide by the simple model, then we subtract by 1
-
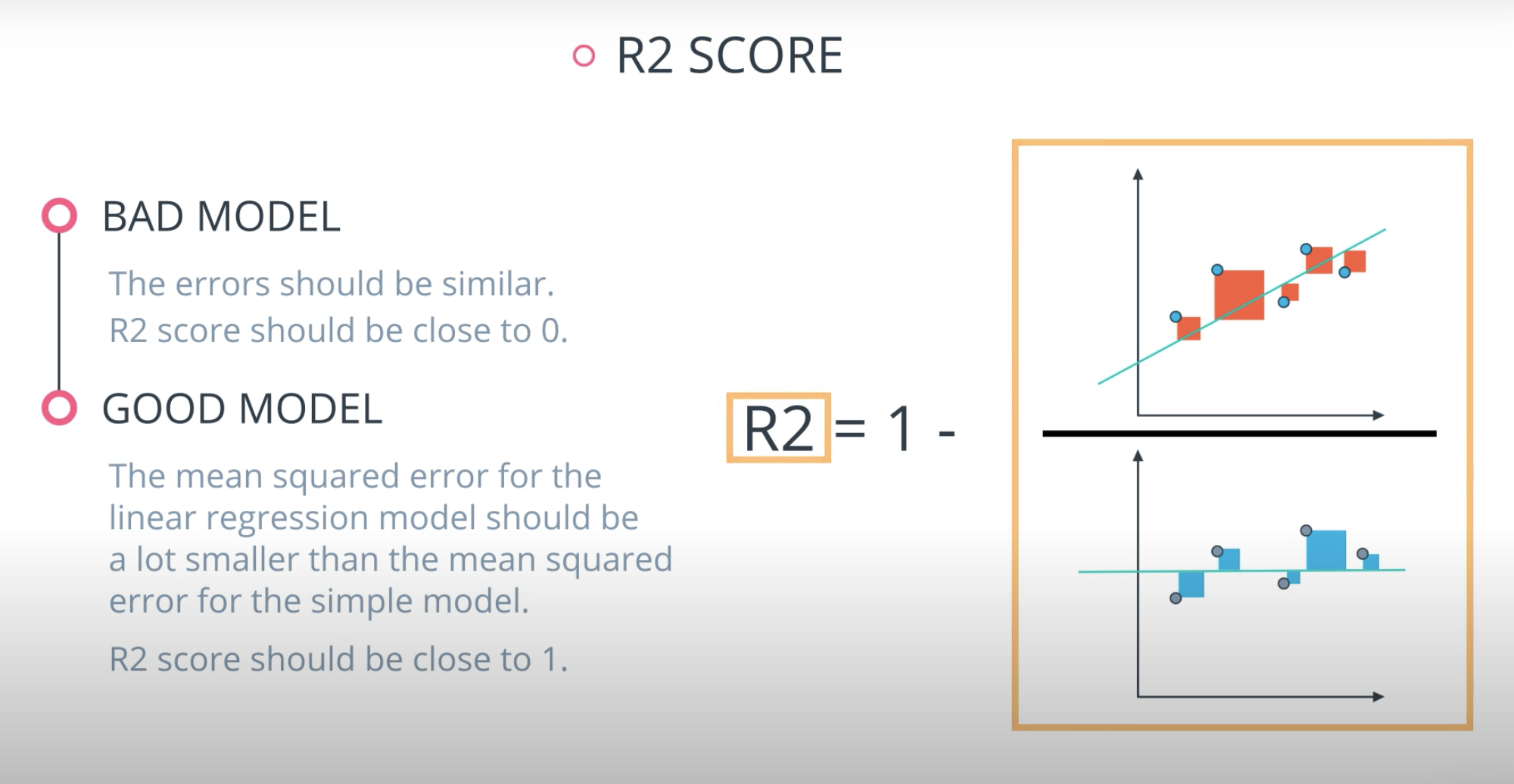
-
If the R2 score is close to 1 the model is good, if it is close to 0 the model is not much better than guessing the average of the value of the points.
-

-
-
-
Recap
In this lesson, you got a glimpse at the ways that we can measure how well our models are performing.
-
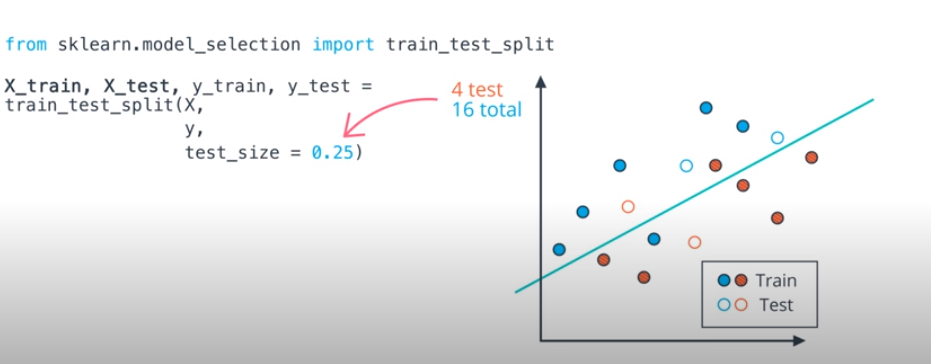
Training & Testing Data
- First, it is important to always split your data into training and testing. Then you will measure how well your model performs on the test set of data after being fit training data.
-
Classification Measures
-
If you are fitting your model to predict categorical data (spam not spam), there are different measures to understand how well your model is performing than if you are predicting numeric values (the price of a home).
-
As we look at classification metrics, note that the wikipedia page on this topic is wonderful, but also a bit daunting. I frequently use it to remember which metric does what.
-
Specifically, you saw how to calculate:
-
Accuracy
-
Accuracy is often used to compare models, as it tells us the proportion of observations we correctly labeled.
-
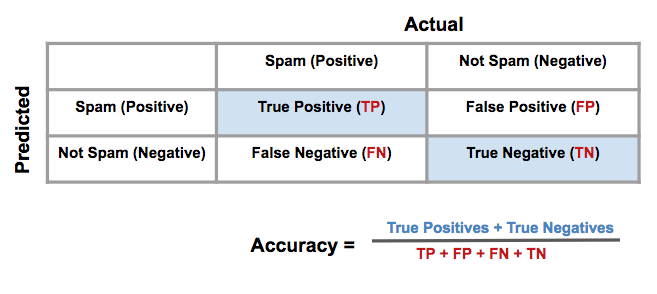
-
Often accuracy is not the only metric you should be optimizing on. This is especially the case when you have class imbalance in your data. Optimizing on only accuracy can be misleading in how well your model is truly performing. With that in mind, you saw some additional metrics.
-
-
Precision
-
Precision focuses on the predicted "positive" values in your dataset. By optimizing based on precision values, you are determining if you are doing a good job of predicting the positive values, as compared to predicting negative values as positive.
-

-
-
Recall
- Recall focuses on the actual "positive" values in your dataset. By optimizing based on recall values, you are determining if you are doing a good job of predicting the positive values without regard of how you are doing on the actual negative values. If you want to perform something similar to recall on the actual 'negative' values, this is called specificity (TN / (TN + FP)).
-
F-Beta Score
-
In order to look at a combination of metrics at the same time, there are some common techniques like the F-Beta Score (where the F1 score is frequently used), as well as the ROC and AUC. You can see that the β parameter controls the degree to which precision is weighed into the F score, which allows precision and recall to be considered simultaneously. The most common value for beta is 1, as this is where you are finding the harmonic average between precision and recall.
-
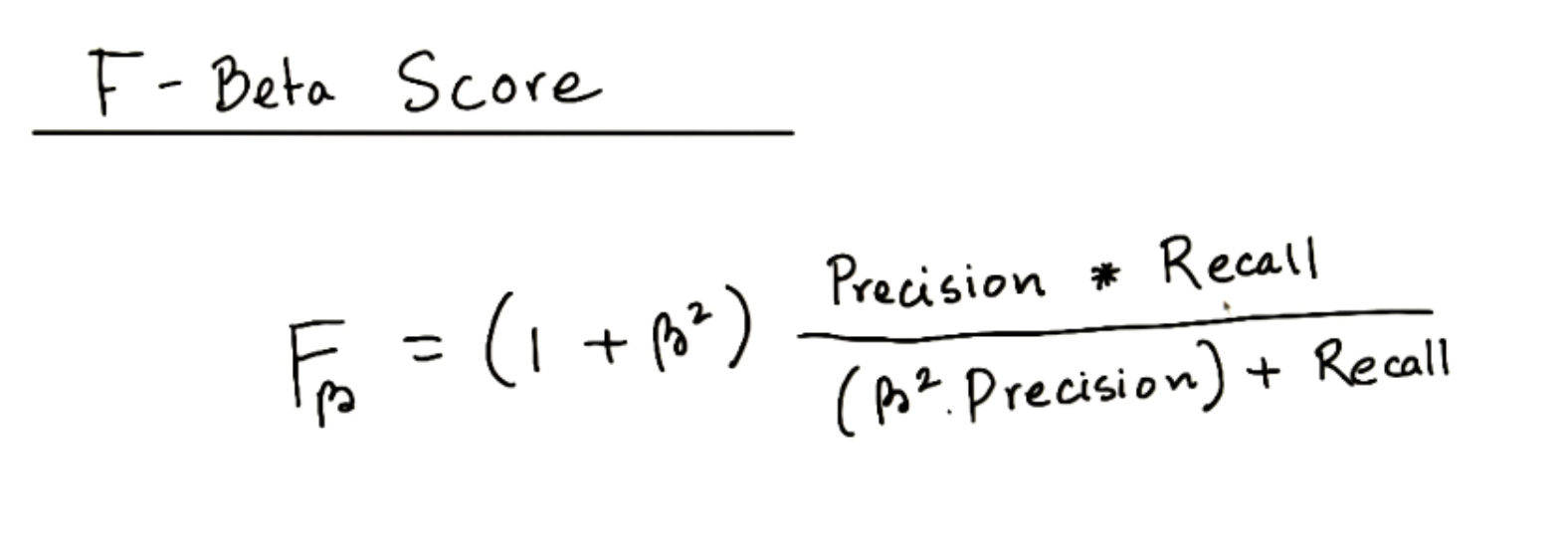
-
-
ROC Curve & AUC (area under the curve)
-
By finding different thresholds for our classification metrics, we can measure the area under the curve (where the curve is known as a ROC curve). Similar to each of the other metrics above, when the AUC is higher (closer to 1), this suggests that our model performance is better than when our metric is close to 0.
-
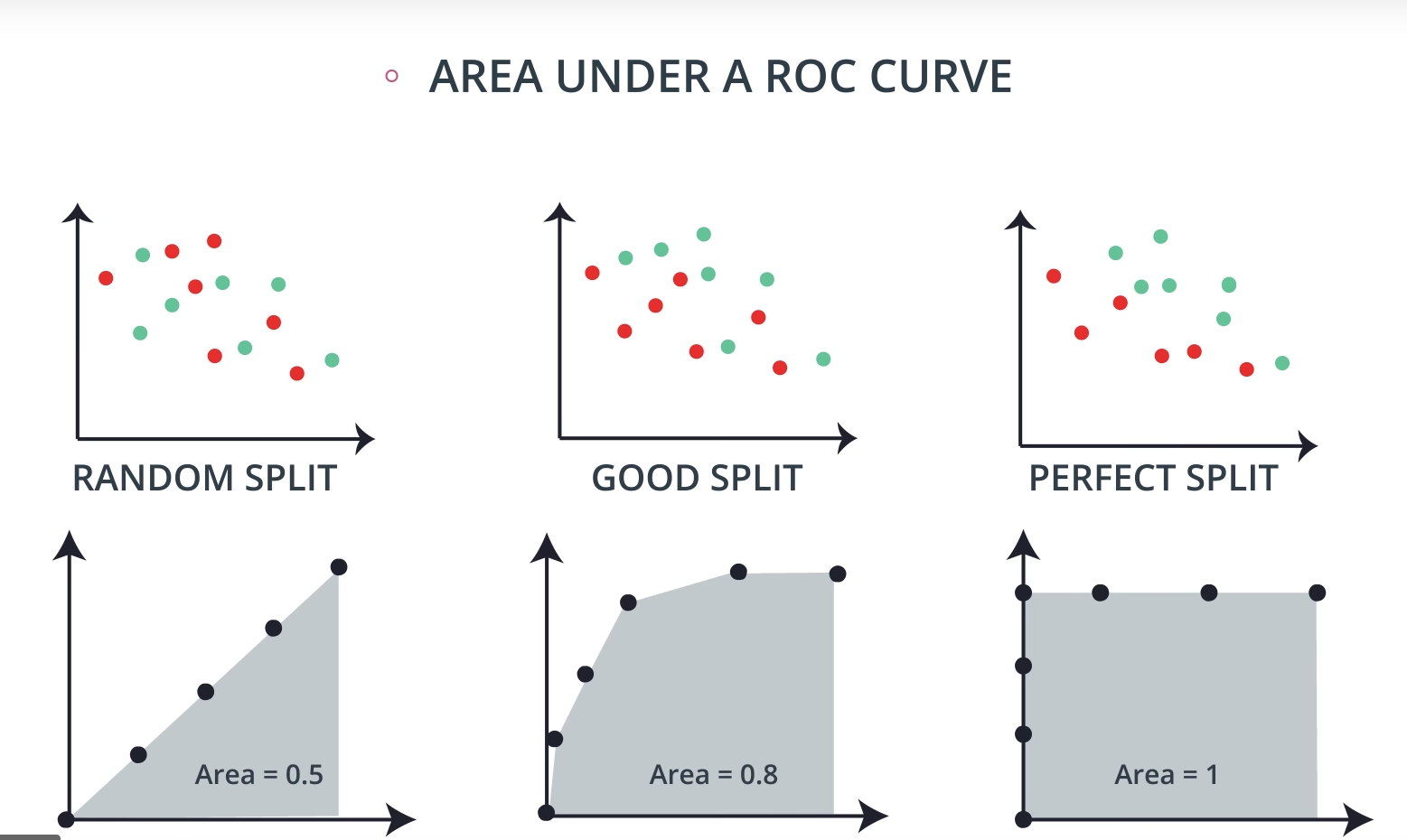
-
You may end up choosing to optimize on any of these measures. I commonly end up using AUC or an F1 score in practice. However, there are always reason to choose one measure over another depending on your situation.
-
-
-
Regression Measures
-
You want to measure how well your algorithms are performing on predicting numeric values? In these cases, there are three main metrics that are frequently used. mean absolute error, mean squared error, and r2 values.
-
As an important note, optimizing on the mean absolute error may lead to a different 'best model' than if you optimize on the mean squared error. However, optimizing on the mean squared error will always lead to the same 'best' model as if you were to optimize on the r2 value.
-
Again, if you choose a model with the best r2 value (the highest), it will also be the model that has the lowest (MSE). Choosing one versus another is based on which one you feel most comfortable explaining to someone else.
-
Mean Absolute Error (MAE)
-
The first metric you saw was the mean absolute error. This is a useful metric to optimize on when the value you are trying to predict follows a skewed distribution. Optimizing on an absolute value is particularly helpful in these cases because outliers will not influence models attempting to optimize on this metric as much as if you use the mean squared error. The optimal value for this technique is the median value. When you optimize for the R2 value of the mean squared error, the optimal value is actually the mean.
-

-
-
Mean-Squared Error (MSE)
-
The mean squared error is by far the most used metric for optimization in regression problems. Similar to with MAE, you want to find a model that minimizes this value. This metric can be greatly impacted by skewed distributions and outliers. When a model is considered optimal via MAE, but not for MSE, it is useful to keep this in mind. In many cases, it is easier to actually optimize on MSE, as the a quadratic term is differentiable. However, an absolute value is not differentiable. This factor makes this metric better for gradient based optimization algorithms.
-

-
-
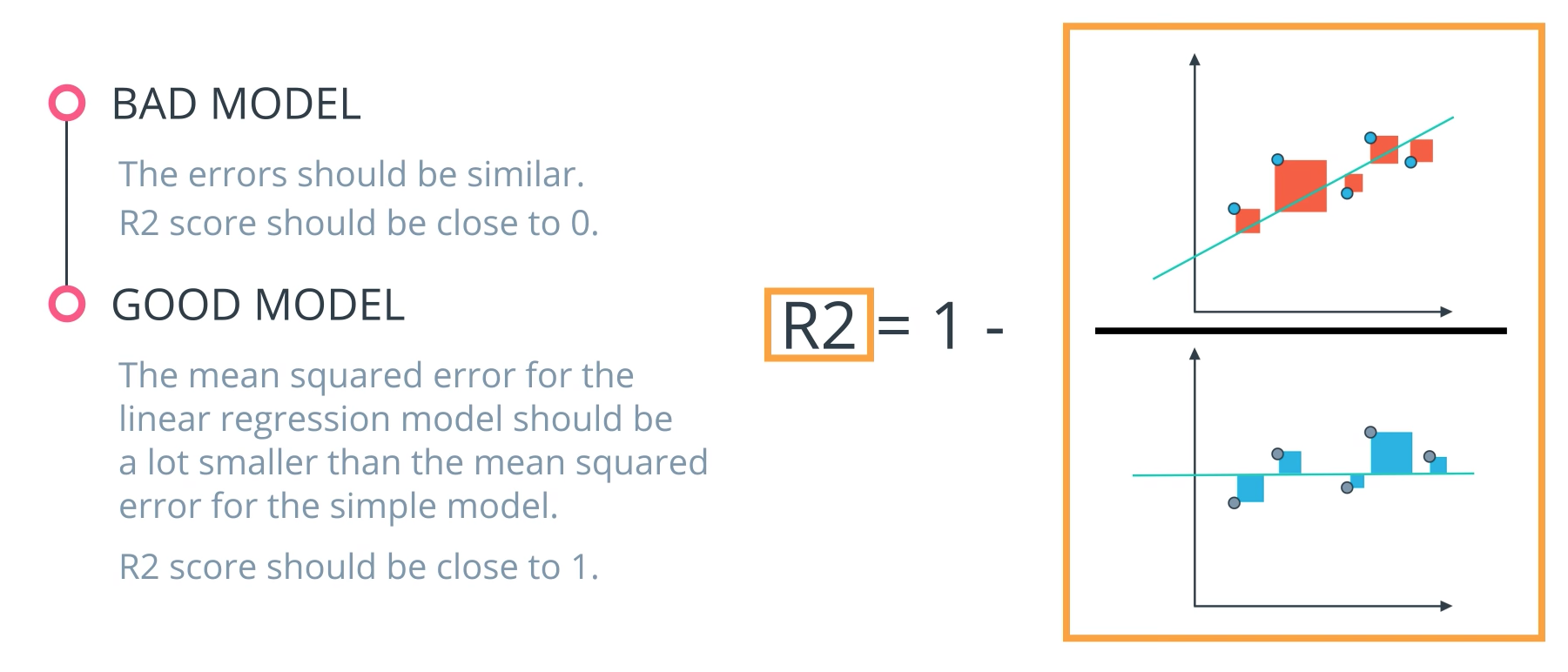
R2 Score
-
Finally, the r2 value is another common metric when looking at regression values. Optimizing a model to have the lowest MSE will also optimize a model to have the the highest R2 value. This is a convenient feature of this metric. The R2 value is frequently interpreted as the 'amount of variability' captured by a model. Therefore, you can think of MSE, as the average amount you miss by across all the points, and the R2 value as the amount of the variability in the points that you capture with a model.
-
-
-
-
-













































-
Training and Tuning
-

-

-
-
-
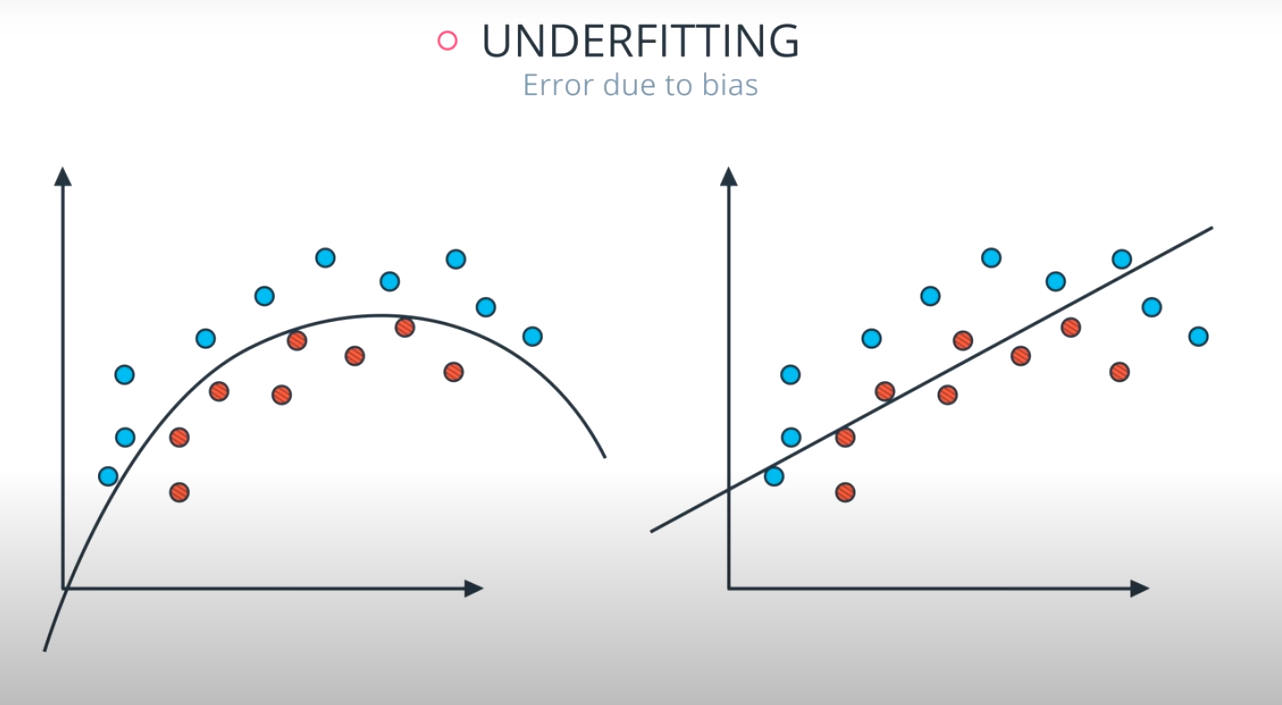
-
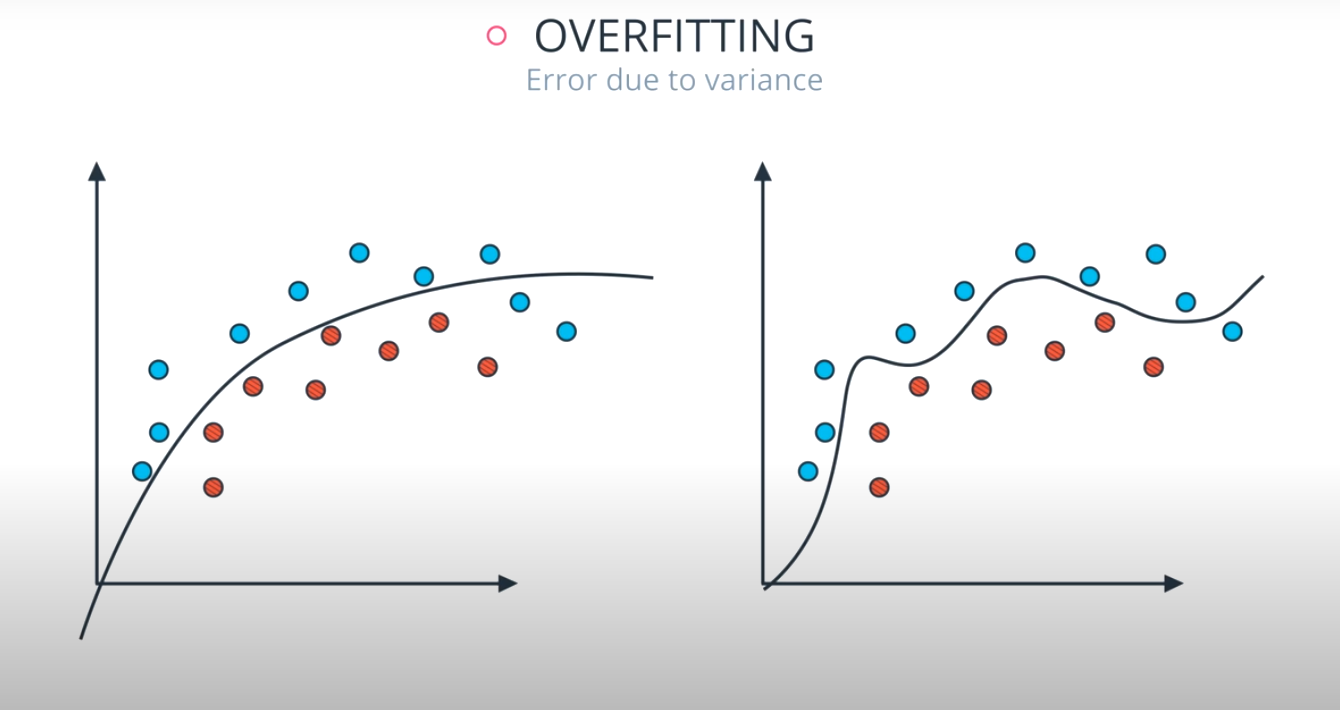
-
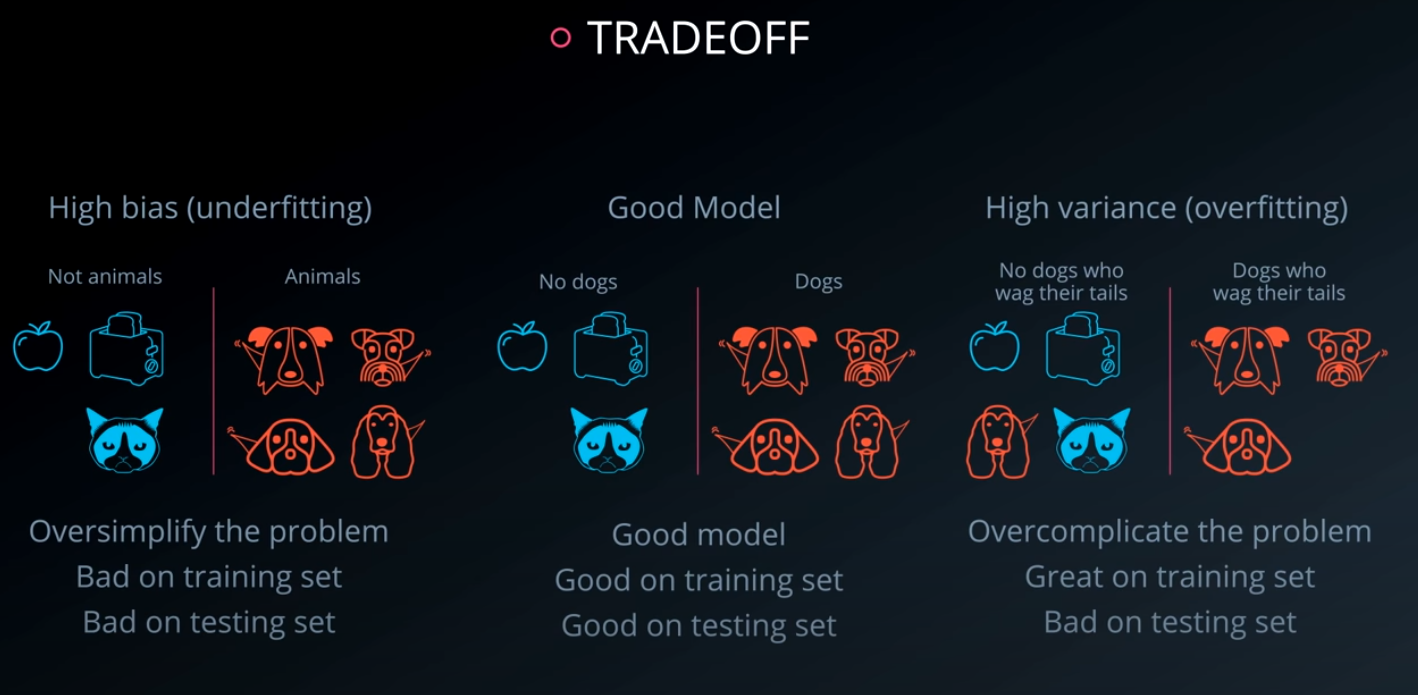
-
Model Complexity
-
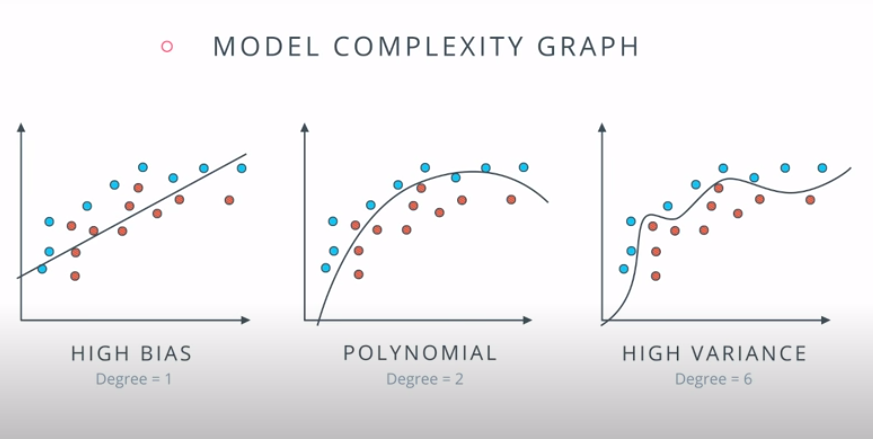
-
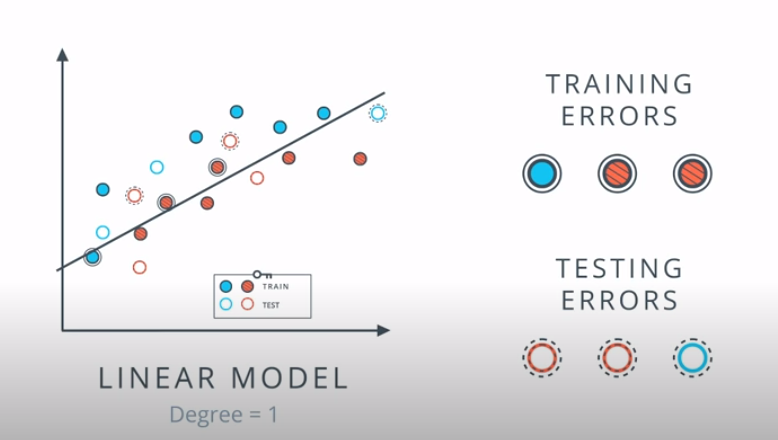
-
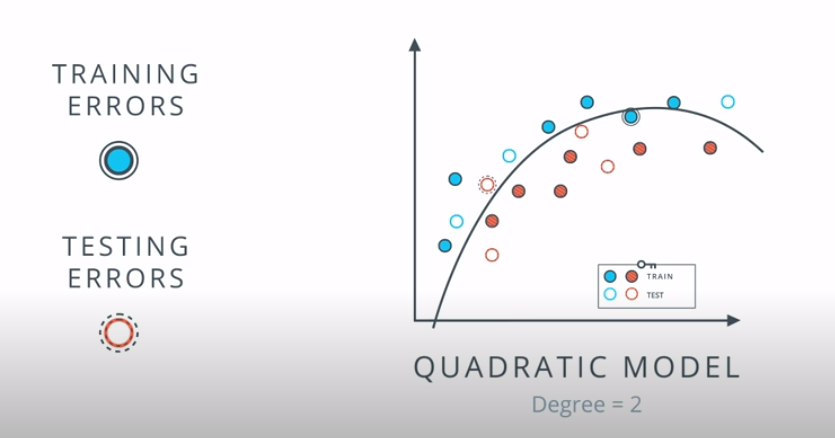
-
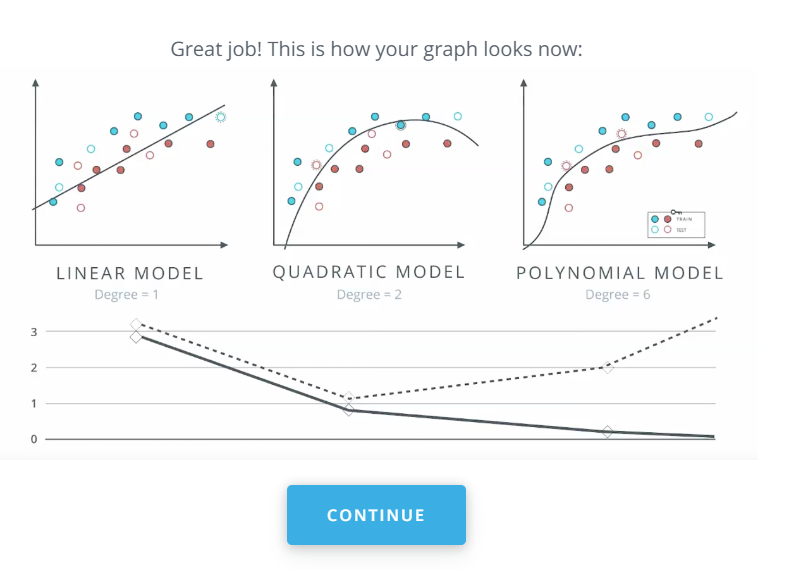
-
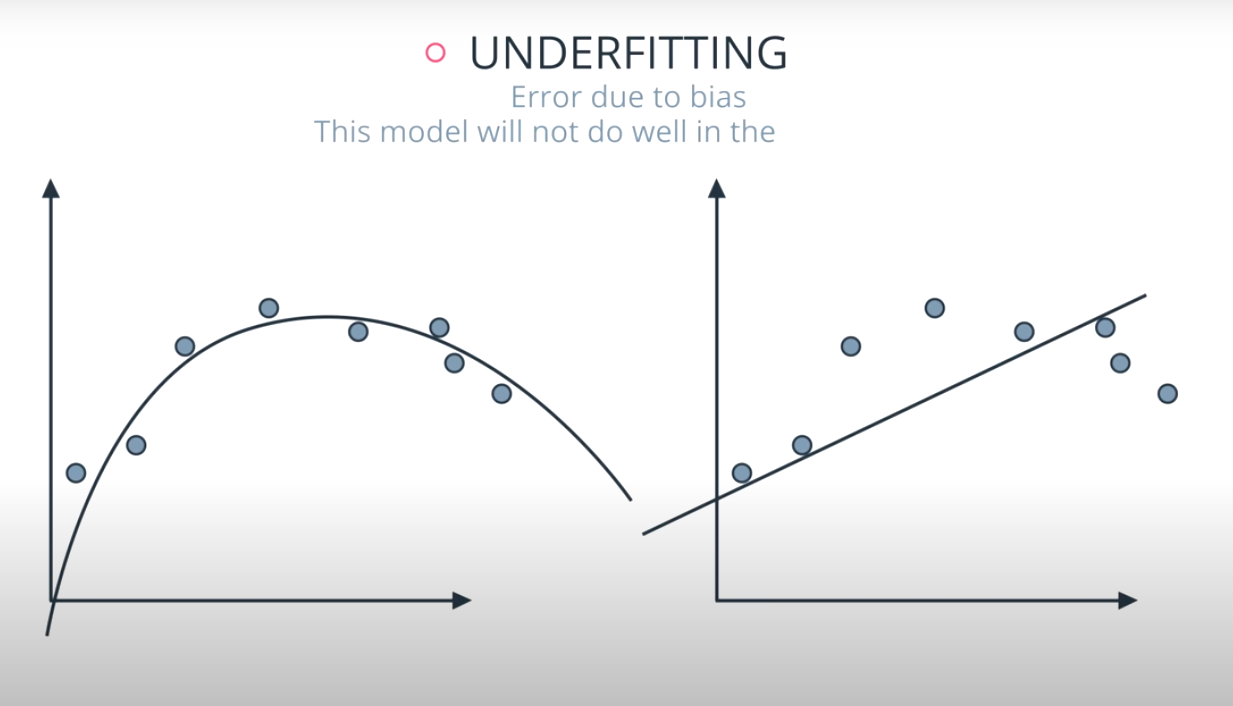
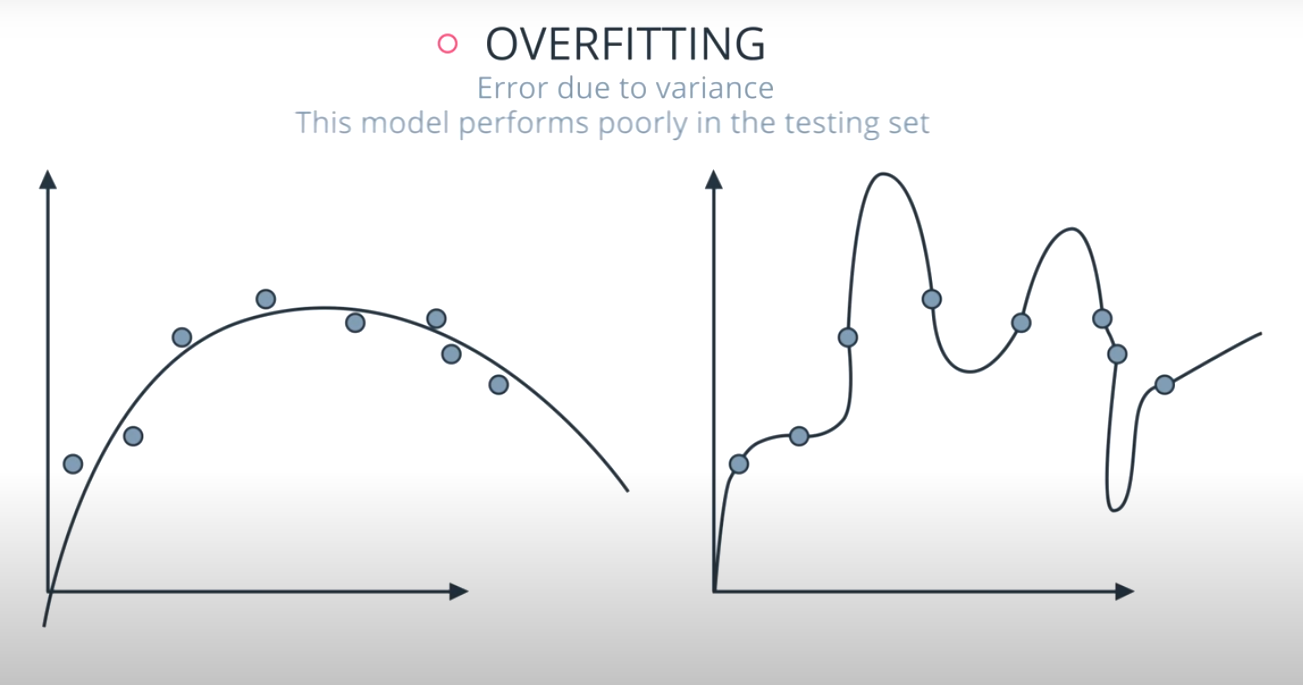
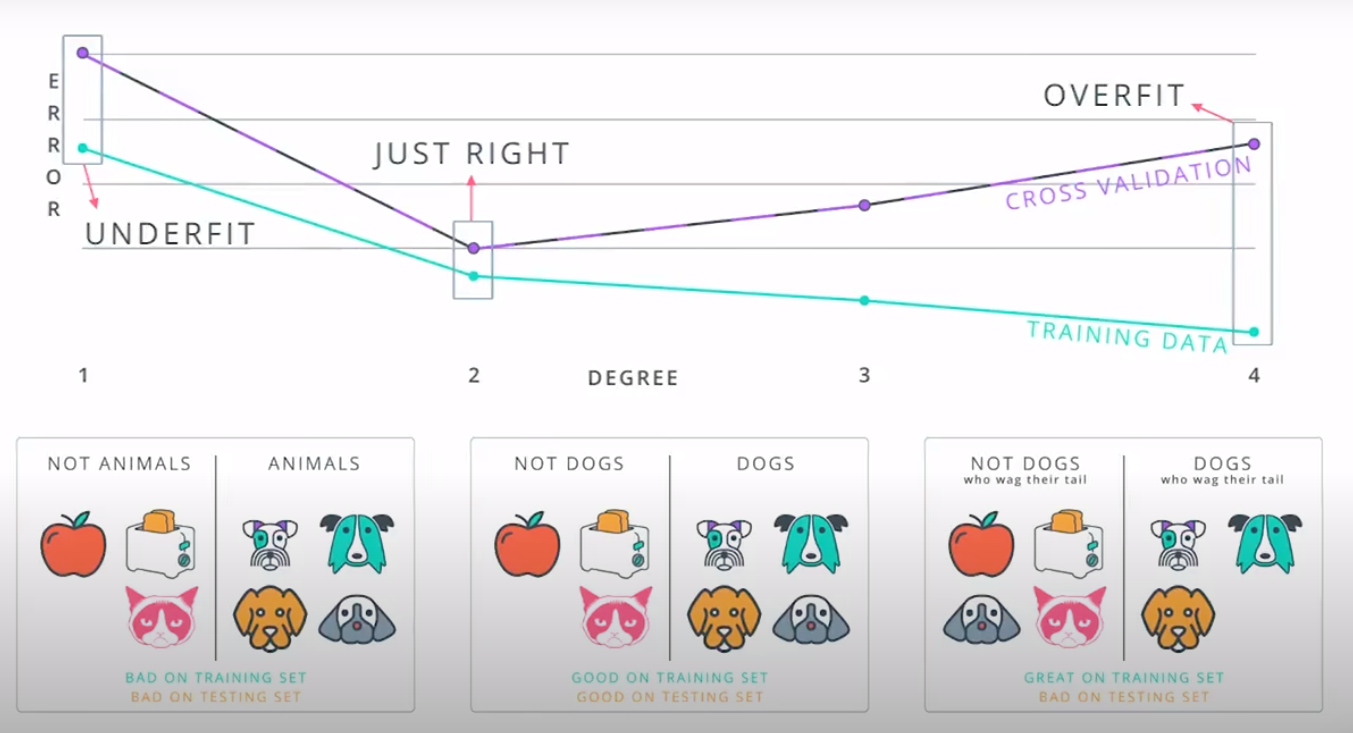
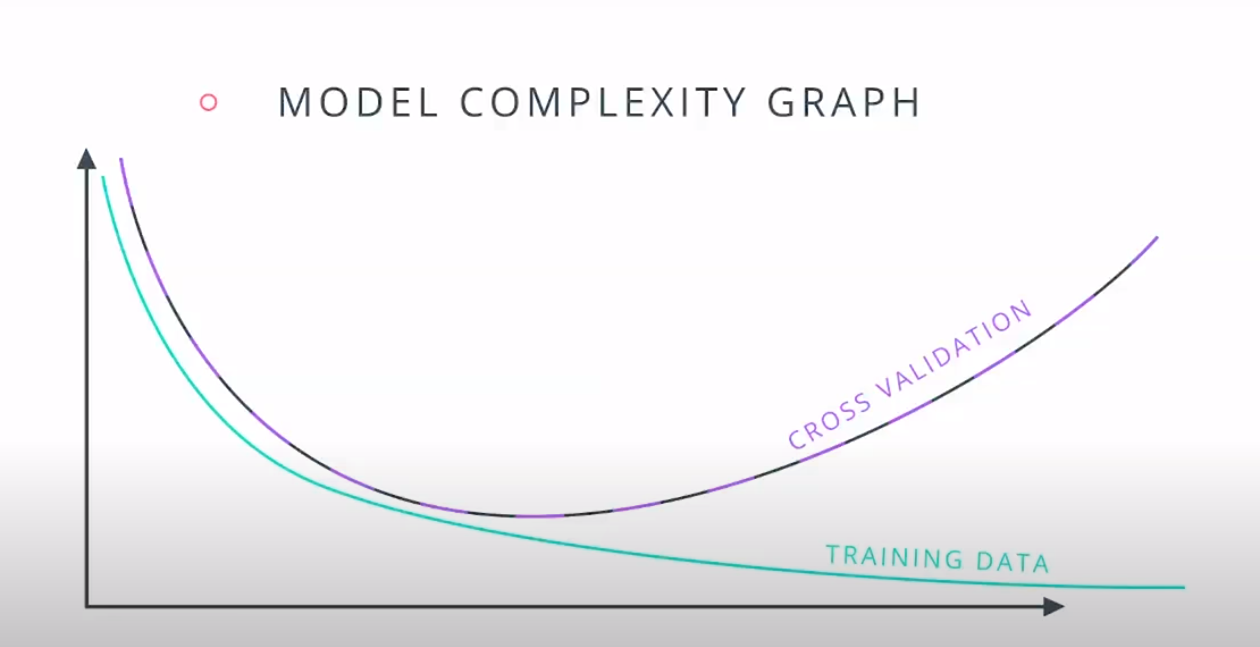
This is a model complexity graph
-
The model in the middle generalized better for both test and training data. The model on the left failed on both test and training (high bias - underfit), and the model on the right is working on the training data and failing on testing (high variance - overfiting)
-
-
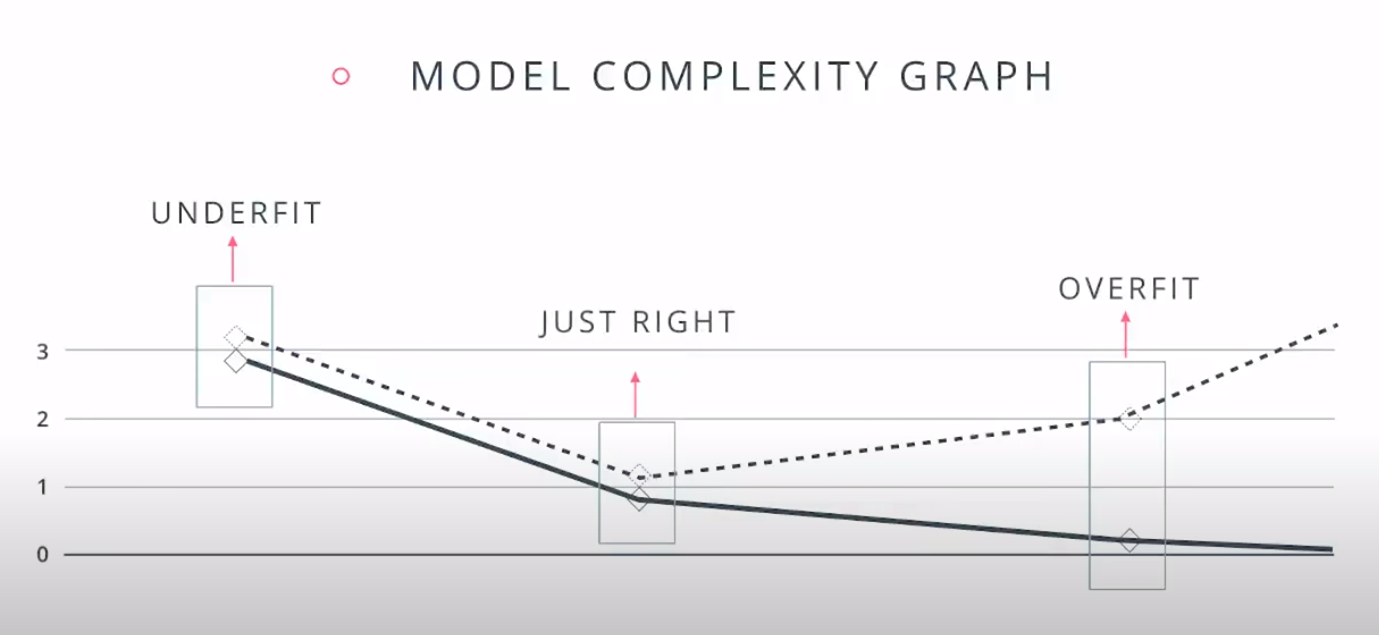
-
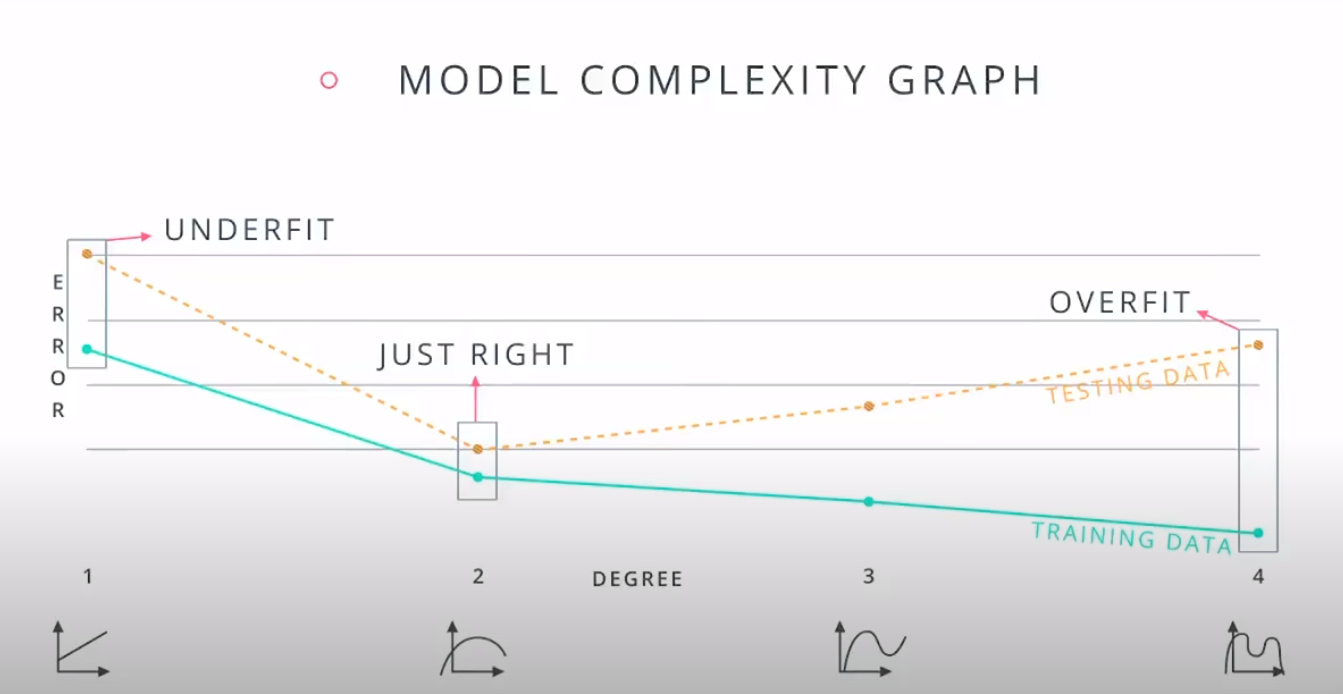
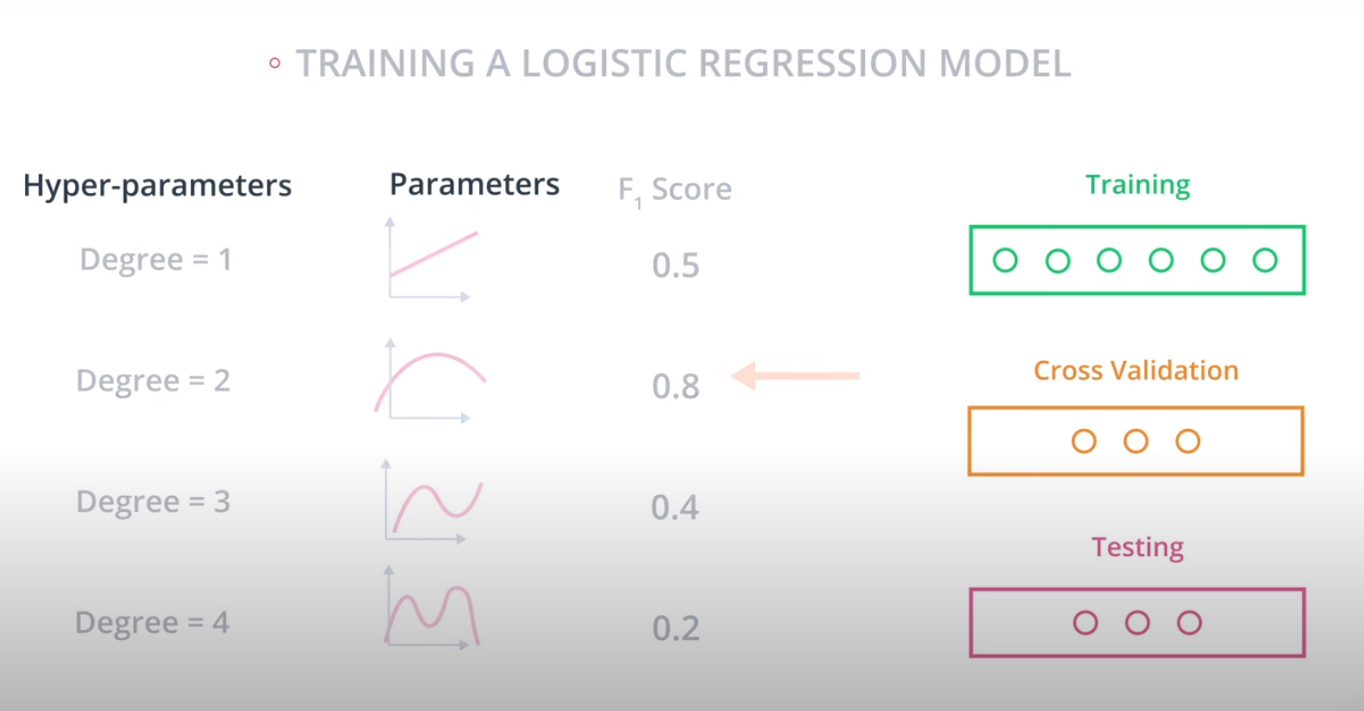
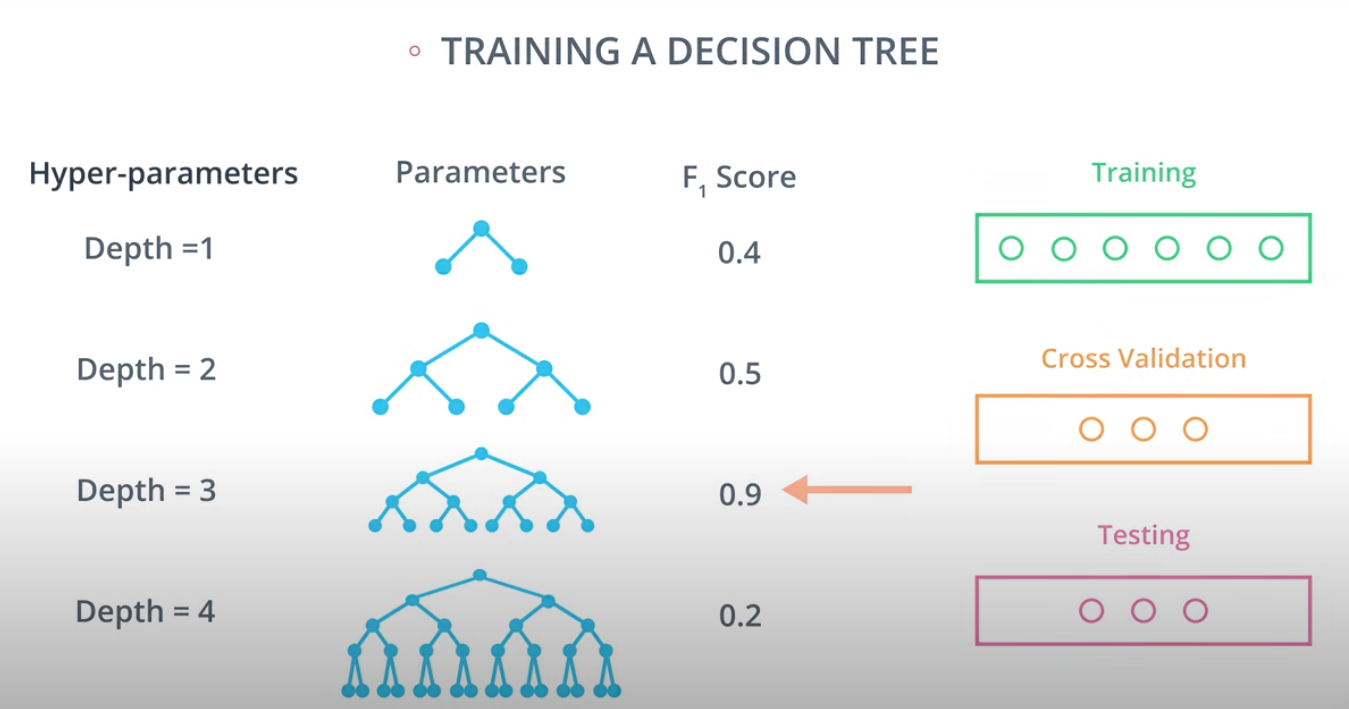
- A polynomial of degree 2 had the best result overall
-
-
Cross Validation
-
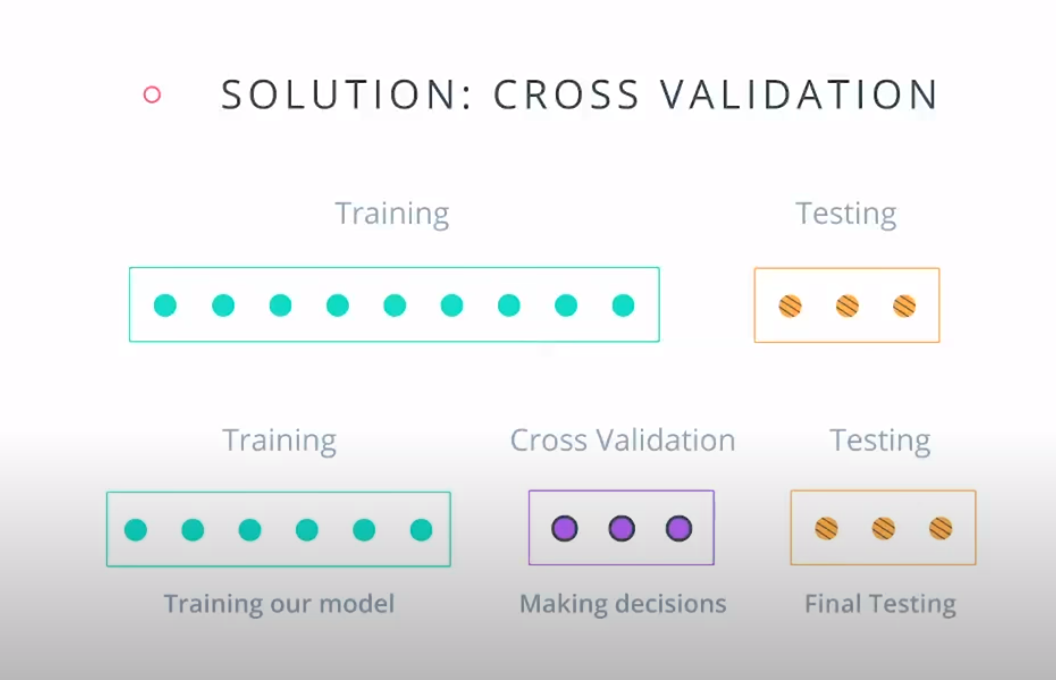
- The Cross Validation set (or just validation) will be used during training so we can adjust the degree of our polynomial during training.
-
-
-
-
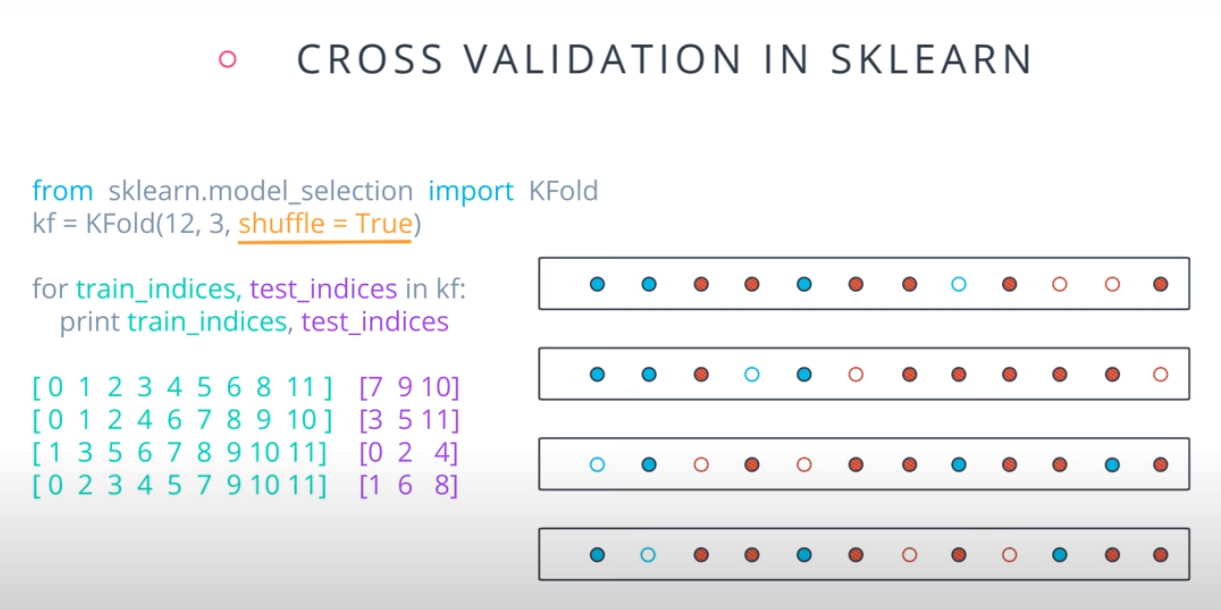
K-fold cross validation
-

- A way to use your training and test data more efficiently is to break it in K buckets. In this case we are breaking it into 4.
-

- Now we can train our model K times (4 in this case), each time using a different bucket as our testing set and the remaining point as the training set.
-
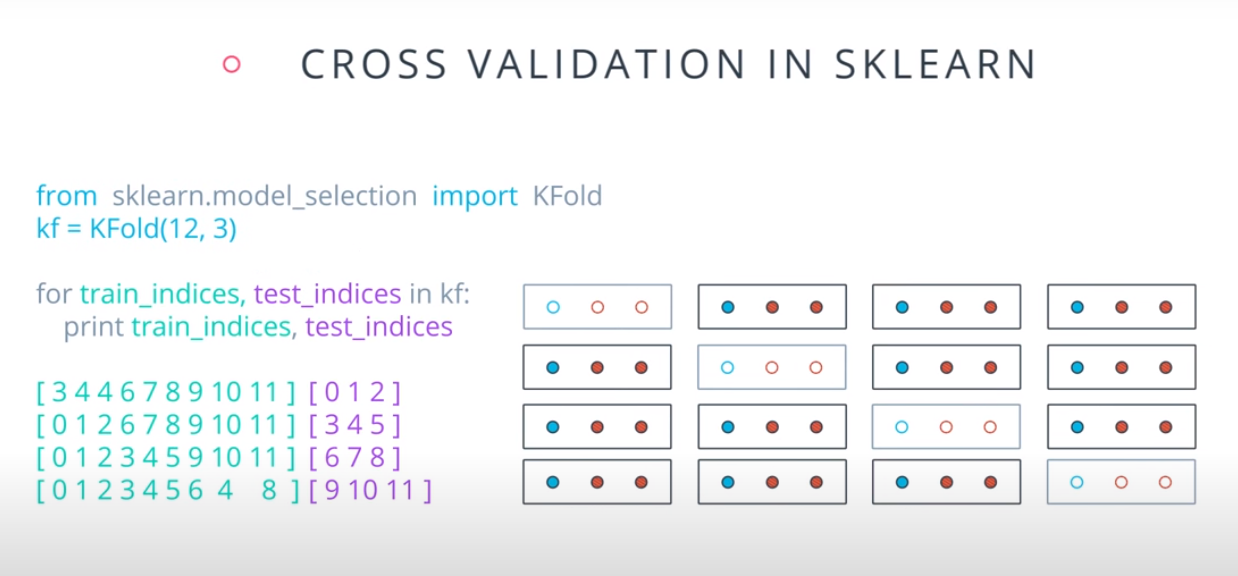
- Size of the data = 12
- Size of the testing set = 3
-

-
-
-
Learning Curves
-
-
Grid Search
-
-
-
-

-
Grid Search in sklearn
-
Grid Search in sklearn is very simple. We'll illustrate it with an example. Let's say we'd like to train a support vector machine, and we'd like to decide between the following parameters:
-
kernel: poly or rbf. -
C: 0.1, 1, or 10. -
from sklearn.model_selection import GridSearchCV parameters = {'kernel':['poly', 'rbf'],'C':[0.1, 1, 10]} from sklearn.metrics import make_scorer from sklearn.metrics import f1_score scorer = make_scorer(f1_score) # Create the object. grid_obj = GridSearchCV(clf, parameters, scoring=scorer) # Fit the data grid_fit = grid_obj.fit(X, y) best_clf = grid_fit.best_estimator_
-
Now you can use this estimator best_clf to make the predictions.
-
Check
grid_search_labfor a full example
-
-































- Check labs inside
tensorflow_lab
-
Before we get started, let's take a quick look at what will be covered in this course on unsupervised learning.
-
Unsupervised learning is all about understanding how to group our data when we either
-
1.Do not have a label to predict. An example of this is using an algorithm to look at brain scans to find areas that may raise concern. You don't have labels on the images to understand what areas might raise reason for concern, but you can understand which areas are most similar or different from one another. -
2.Are not trying to predict a label, but rather group our data together for some other reason! One example of this is when you have tons of data, and you would like to condense it down to a fewer number of features to be used. -
With that in mind, here are the topics for this lesson:
-
Clustering
- Clustering is one of the most popular unsupervised approaches. In a first look at clustering, you will gain an understanding of what clustering your data means. Then, you will see how the k-means algorithm works. You will put your skills to work to find groupings of similar movies!
-
Hierarchical and Density Based Clustering
- Another set of clustering algorithms takes an approach of using density based 'closeness' measures. At the end of the lesson, you will see how this can be used in traffic classification, as well as in anomaly detection (finding points that aren't like others in your dataset).
-
Gaussian Mixture Models and Cluster Validation
- To extend the density based approaches, you will get some practice with gaussian mixture models. This technique is not far from what you learned in the previous lesson, and it is the last of the clustering algorithms you will learn before moving to matrix decomposition methods.
-
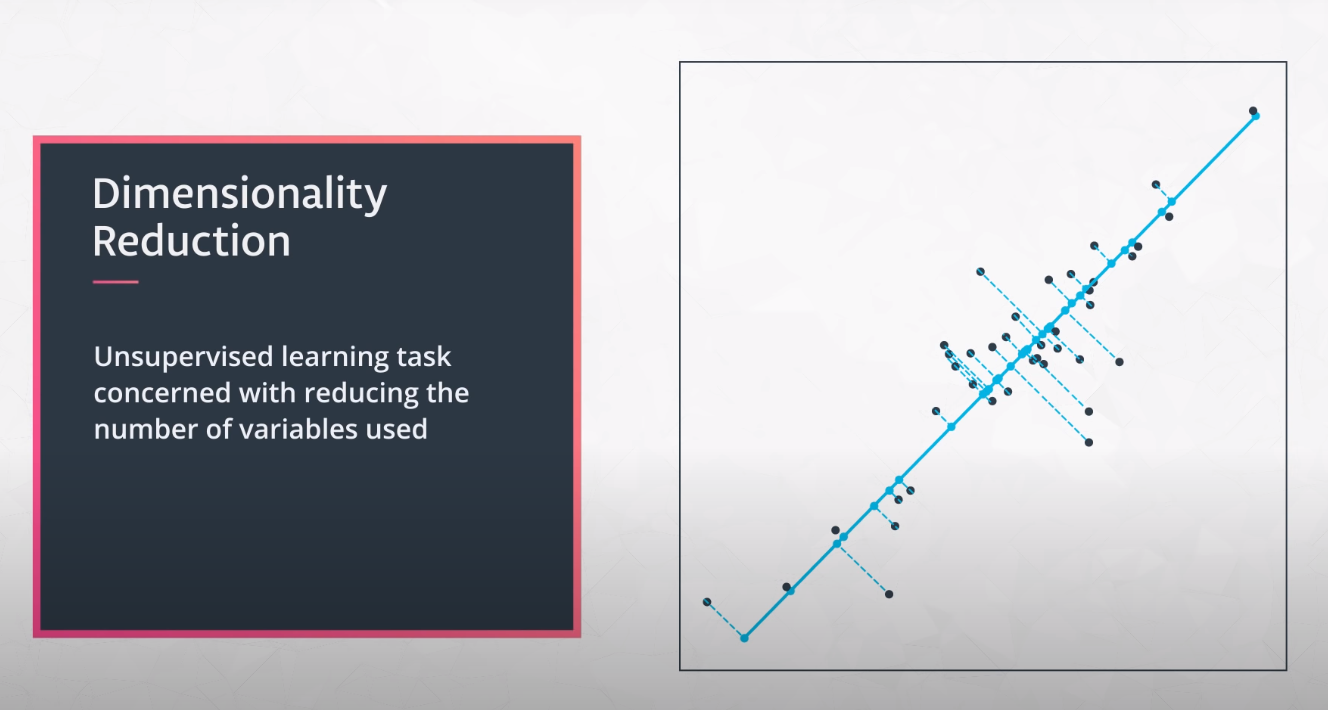
Principal Component Analysis
- Principal component analysis is one of the most popular decomposition methods available today. In this lesson, you will learn how matrix decomposition methods work conceptually. Then you will apply principal component analysis to images of handwritten digits to reduce the dimensionality of these images.
-
Random Projection and Independent Component Analysis
- Another way to decompose data is through independent component analysis. In this lesson, you will see how this method can pull apart audio related to a piano, cello, and television that has been overlaid in the same file.
-
-

-
-
k-Means use cases
-
Cluster books and authors that are similar, which helps identify anonymous authors
-
It is also used to cluster similar movies and music
-
Cluster customer behaviour. Recommend items based on customer habits
-
-
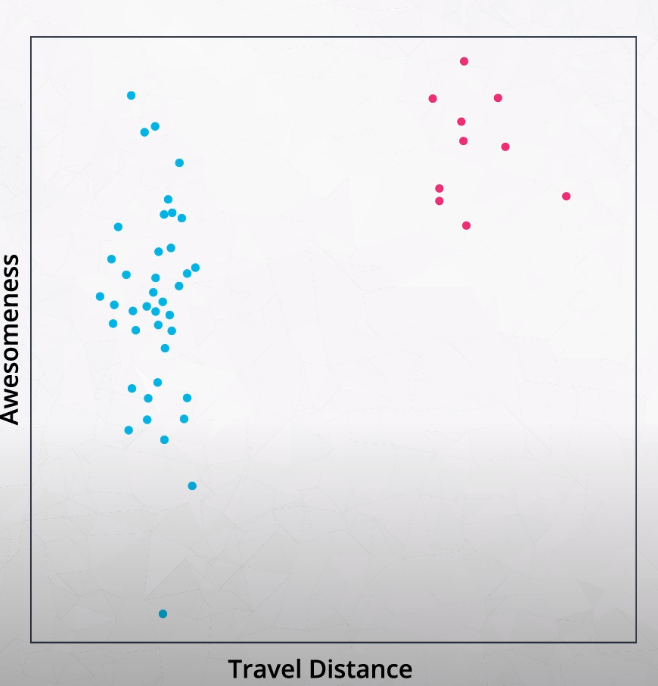
How it works: k-Means
-
In k-Means we group the points closes to one another together into k groups. In the case bellow k = 2 (one representing going to work, another representing going to parents house)
-
-
-
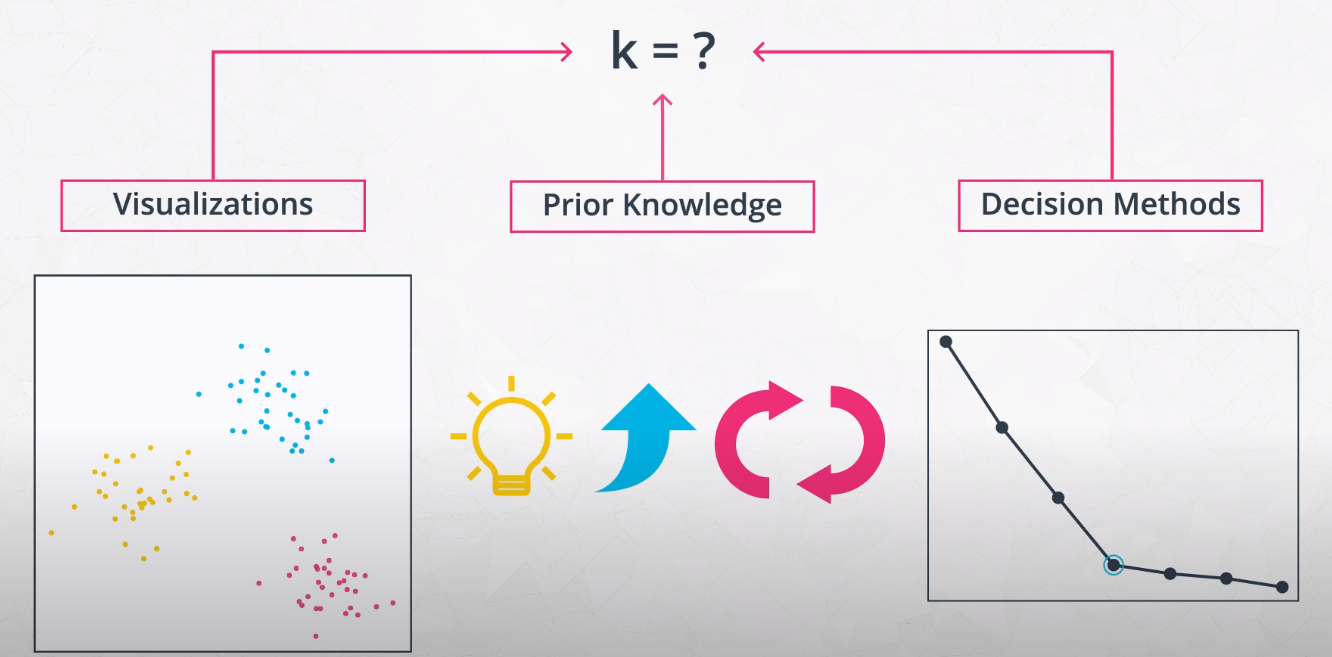
Elbow Method for Finding K
-
-
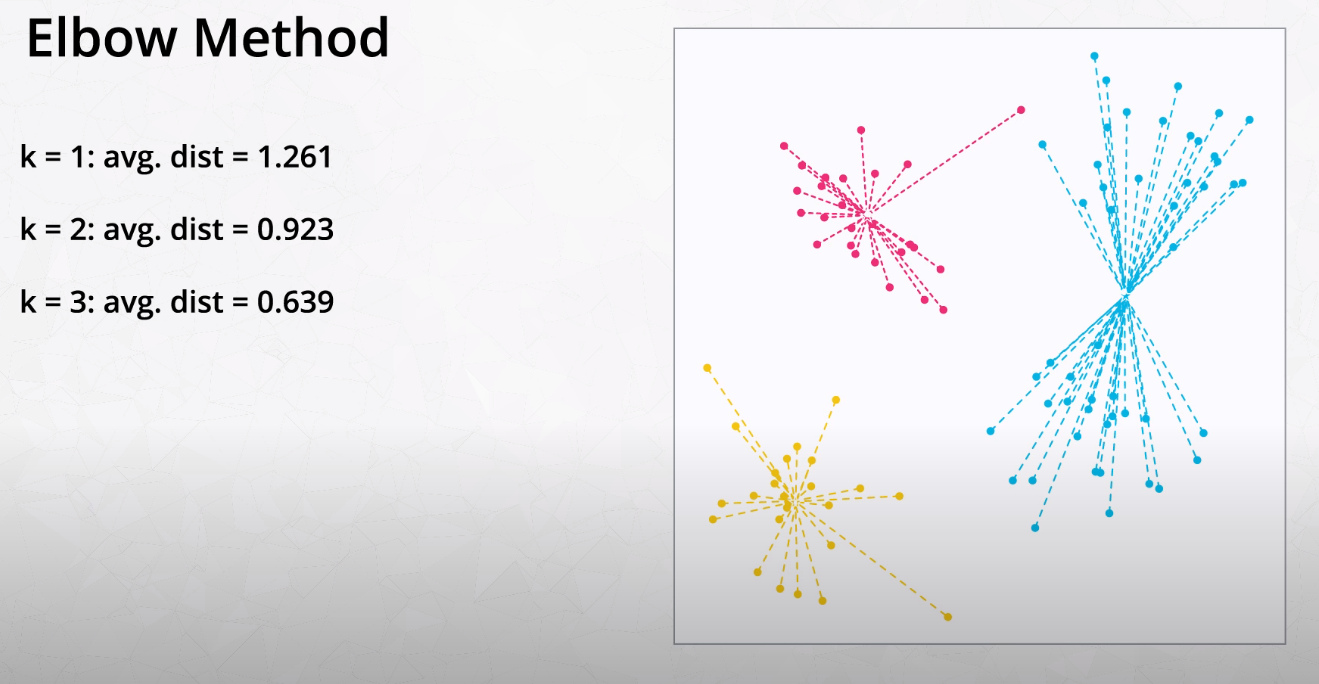
-
This method tries variations of K and measures the average distance of each point from the center point of the cluster.
-
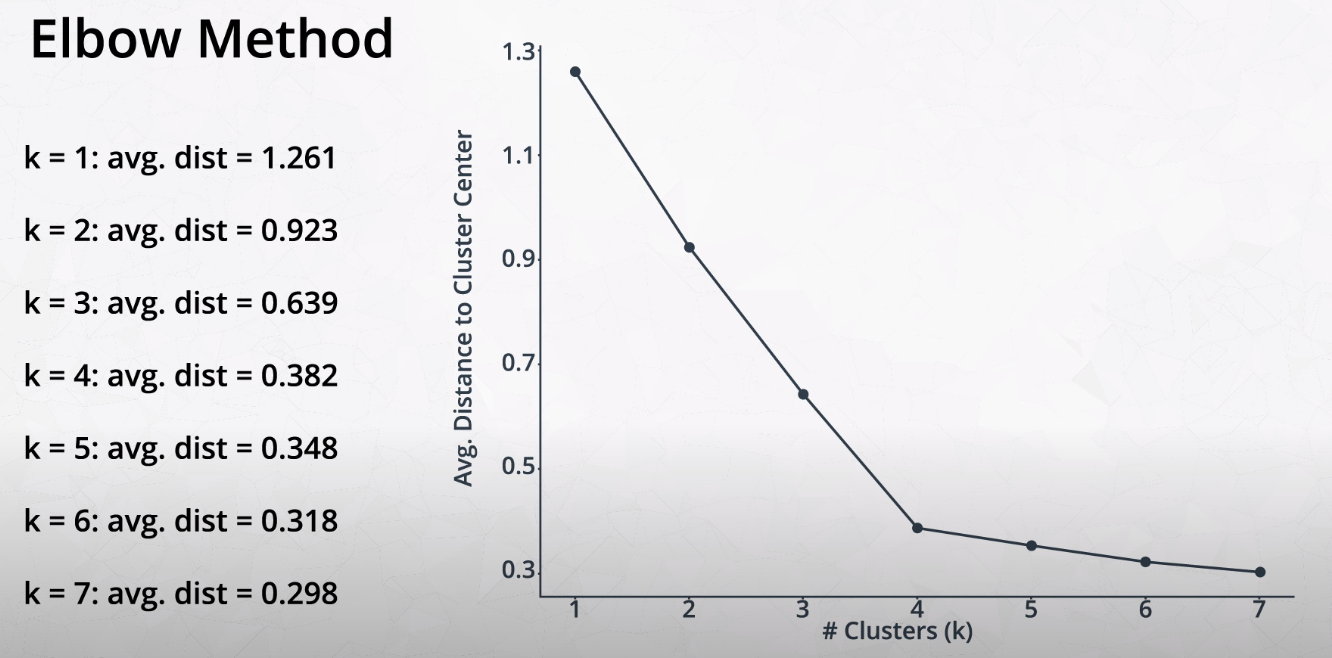
-
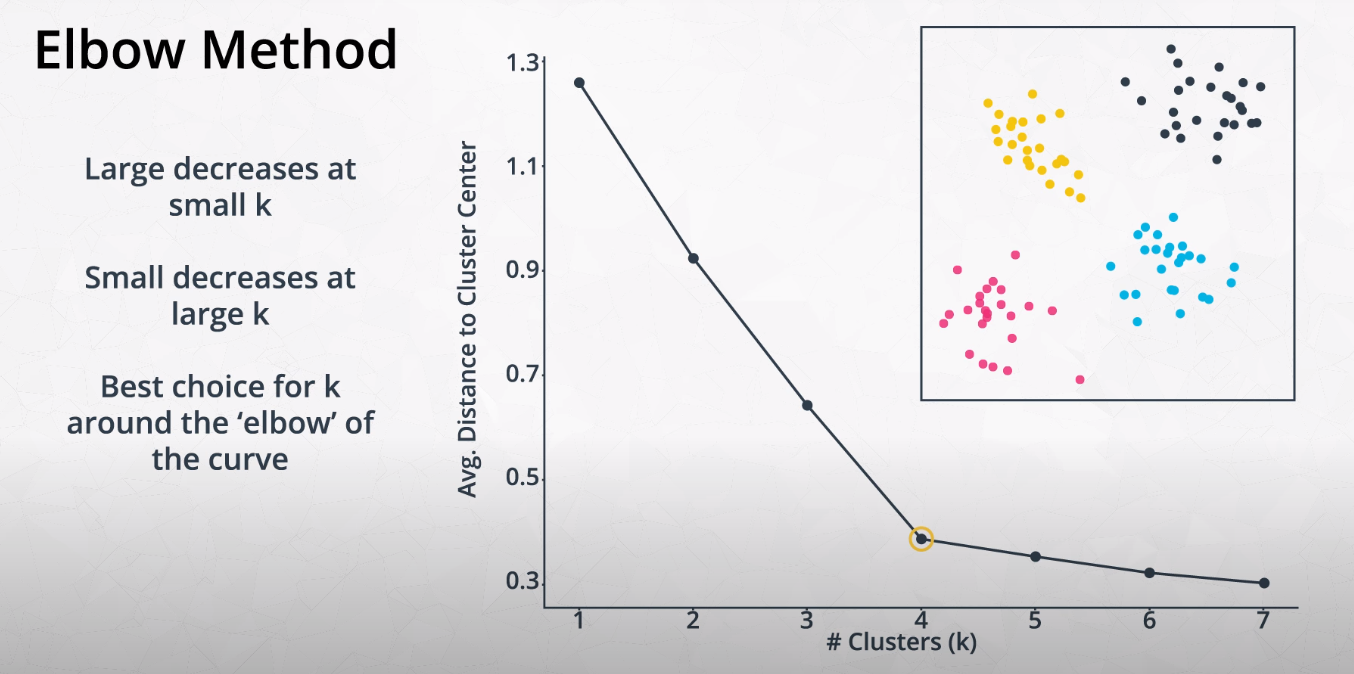
- We want to find the "Elbow" of the curve. This is the best K number of clusters.
-
Check the
Changing K - Solutionlab- Once you have fit a kmeans model to some data in sklearn, there is a score method, which takes the data. This score is an indication of how far the points are from the centroids.
-
-
How do we build an algorithm to determine where the clusters centers are?
-
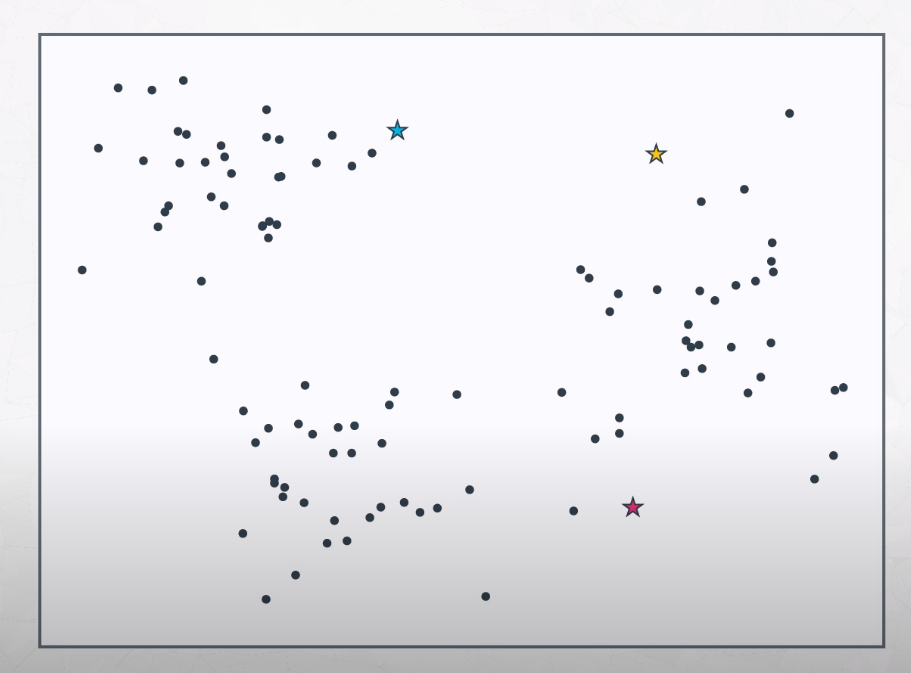
- We start K means by randomly placing K points to our plot. Those points are called centroids. Now we need to set each point of our dataset to the closest centroid.
-
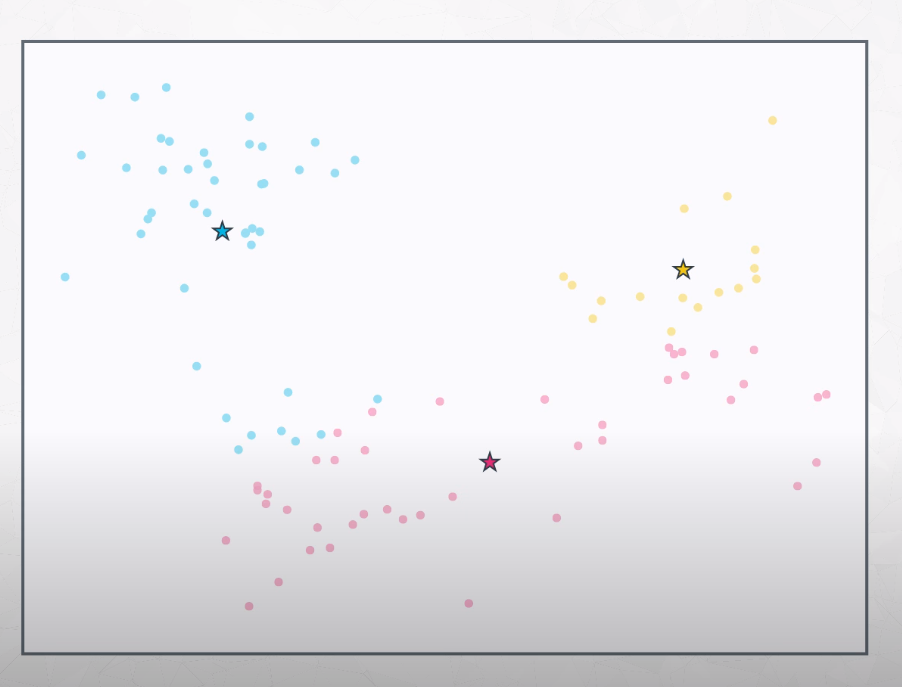
-
Now that we know which points belong to which group, we move the centroid to the center of this points.
-
After that, we recalculate (reassign) all points distance to the centroids.
-
-

-

- We should run K-means with different sets of centroids.
-

- The best grouping is the one if smallest average distance between the point and the centroid.
-
-
Feature scaling
-
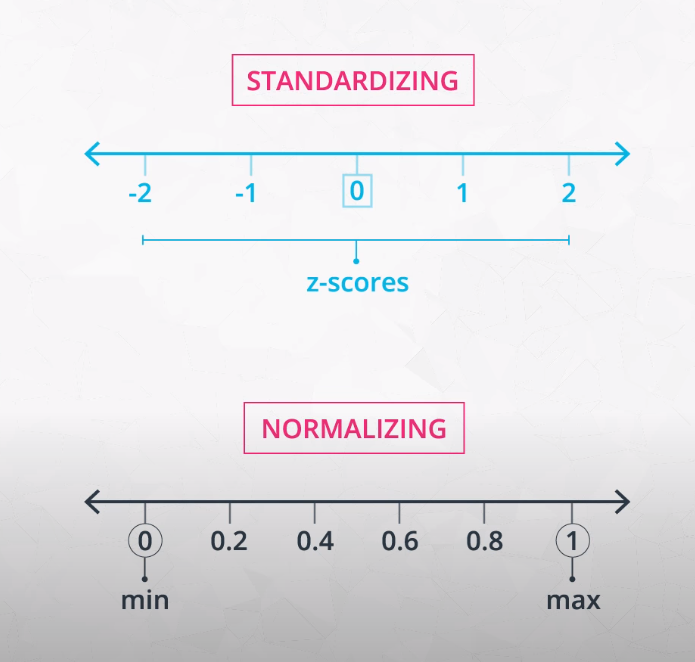
- We usually use standardizing with clustering algorithms, as well as with transformations like PCA and ICA.
-
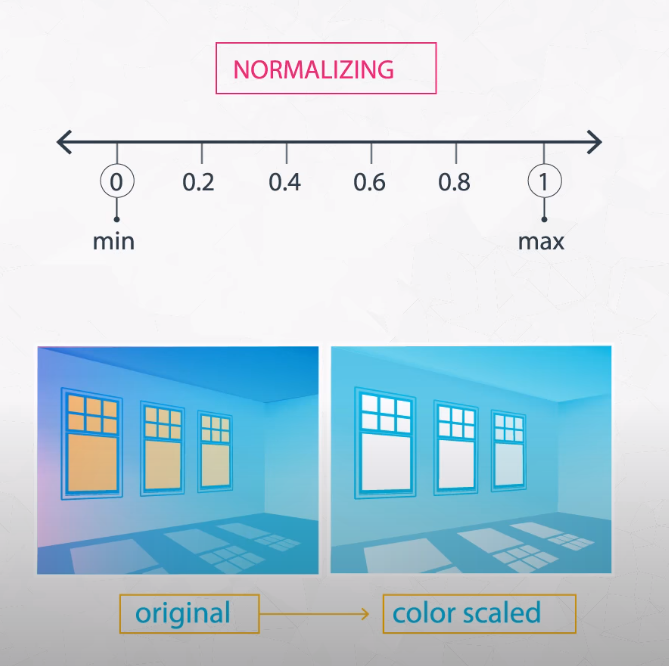
- We use normalizing when scaling the color of an image.
-
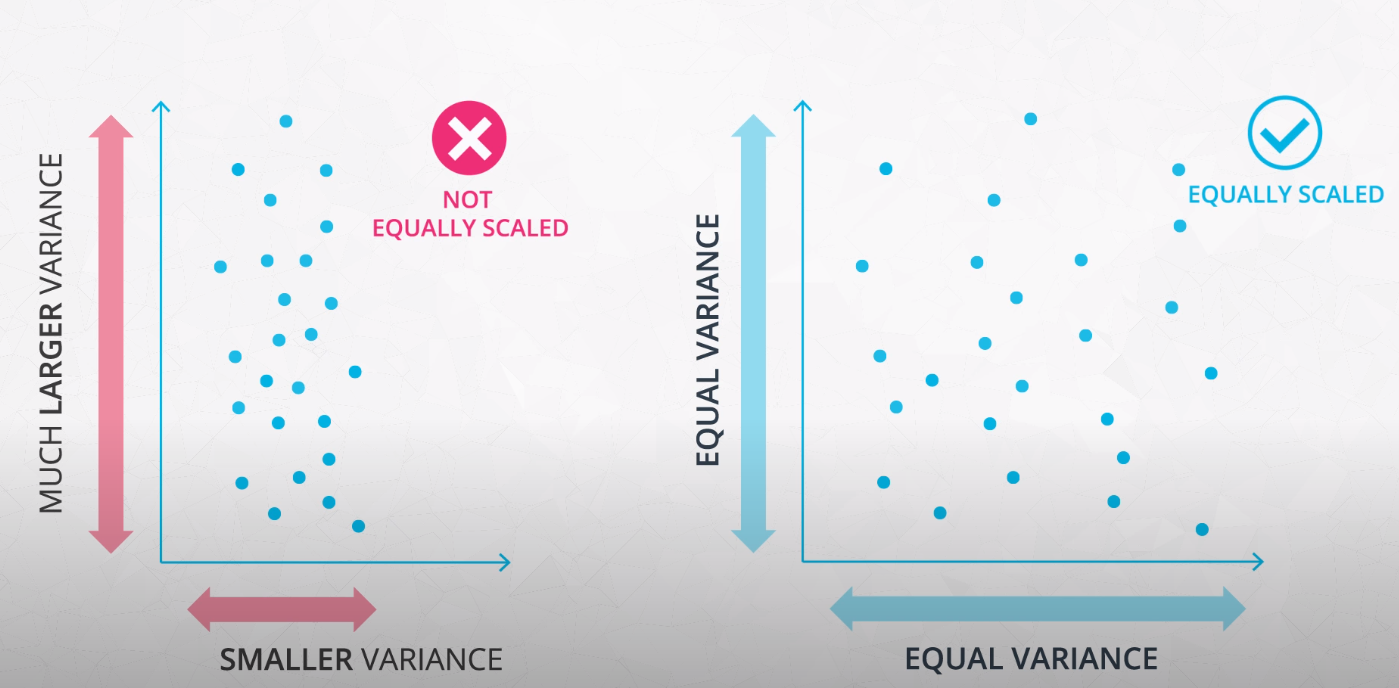
- If you do not scale your features, the features with much larger variance will dominate the importance in clustering. Even if it is just because of the choice of unity
-
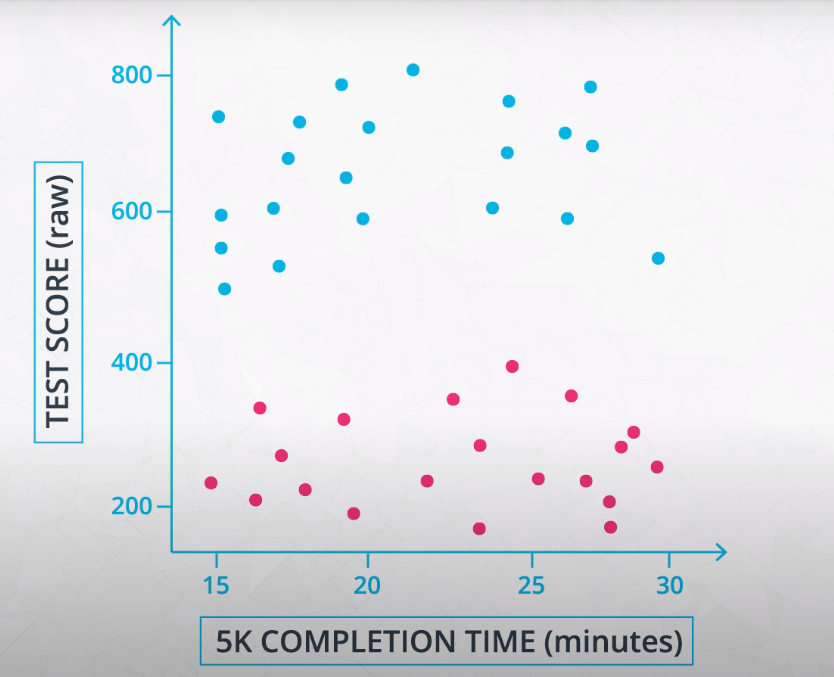
-
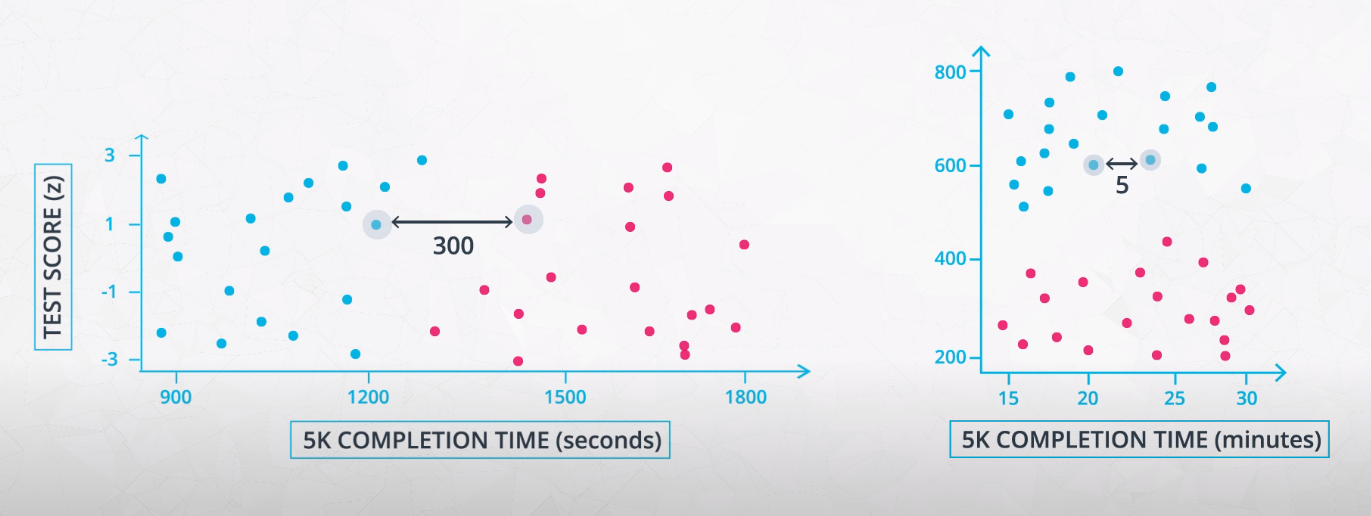
-
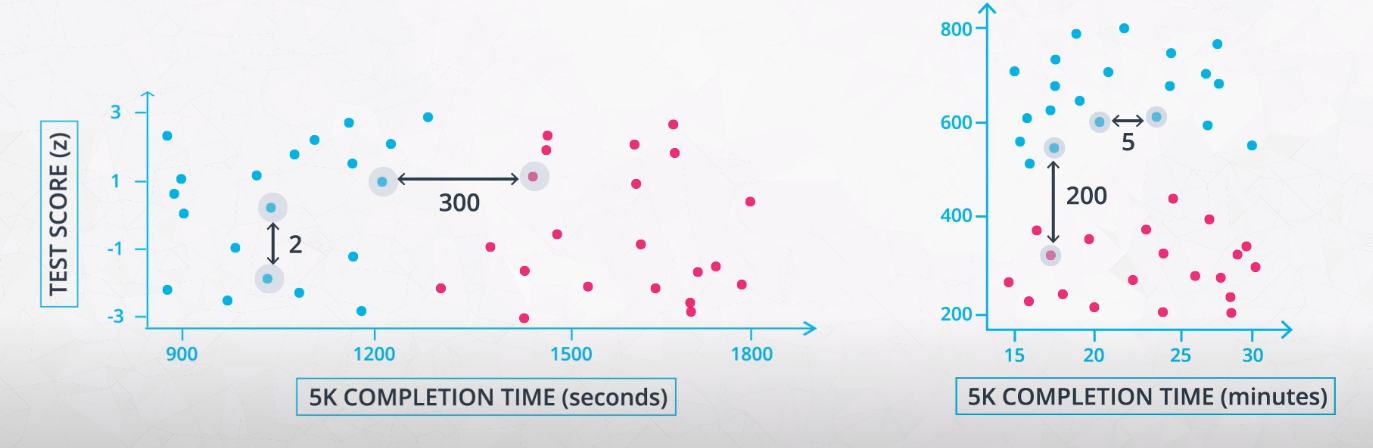
- This is an example of how feature scaling may change the final clusters determined by a model. For this reason, it is important to standardize your data before clustering
-
Check the clustering_lab folder for examples.
-
-
Recap
-
Clustering
-
You learned about clustering, a popular method for unsupervised machine learning. We looked at three ways to identify clusters in your dataset.
Visual Inspectionof your data.Pre-conceivedideas of the number of clusters.The elbow method, which compares the average distance of each point to the cluster center for different numbers of centers.
-
-
K-Means
-
You saw the k-means algorithm for clustering data, which has 3 steps:
-
Randomly place k-centroids amongst your data.
- Then repeat the following two steps until convergence (the centroids don't change):
-
Look at the distance from each centroid to each point. Assign each point to the closest centroid.
-
Move the centroid to the center of the points assigned to it.
-
-
-
Concerns with K-Means
- Finally, we discussed some concerns with the k-means algorithm. These concerns included:
- Concern: The random placement of the centroids may lead to non-optimal solutions.
- Solution: Run the algorithm multiple times and choose the centroids that create the smallest average distance of the points to the centroids.
- Concern: Depending on the scale of the features, you may end up with different groupings of your points.
- Solution: Scale the features using Standardizing, which will create features with mean 0 and standard deviation 1 before running the k-means algorithm.
-


















-
k-Means are great of cases like this:
-
Specially if you know the number of clusters before hand
-

-
-
What about a dataset like this:
-
Do you think K-means would be able to find those clusters?
-
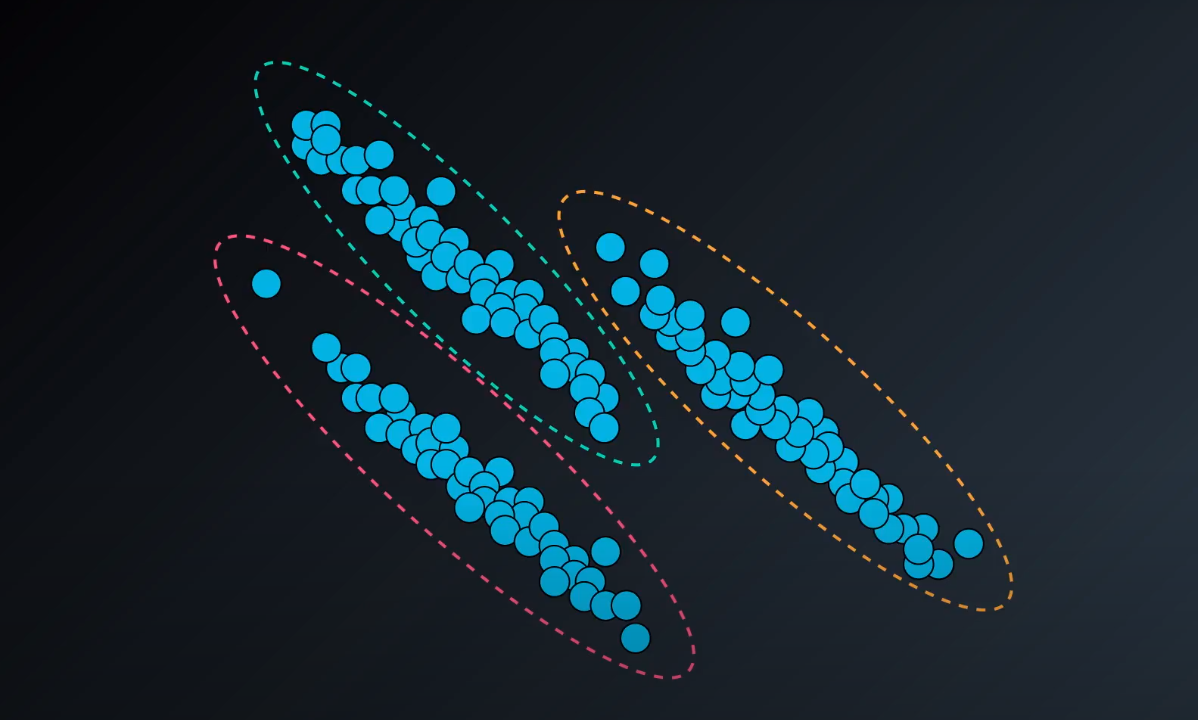
-
-

- K-means wouldn't be able to do that successfully
-
K-means tend to work well in spherical datasets
-

-
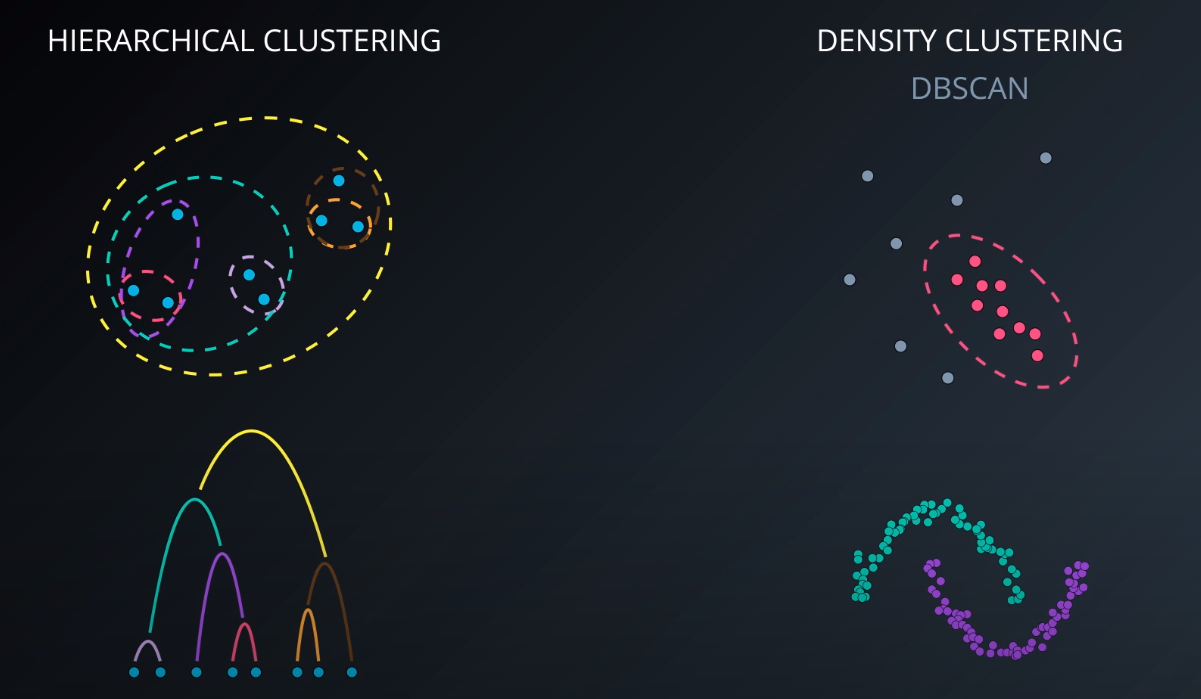
-
Hierarchical Clustering
-
Single-Link Clustering
-
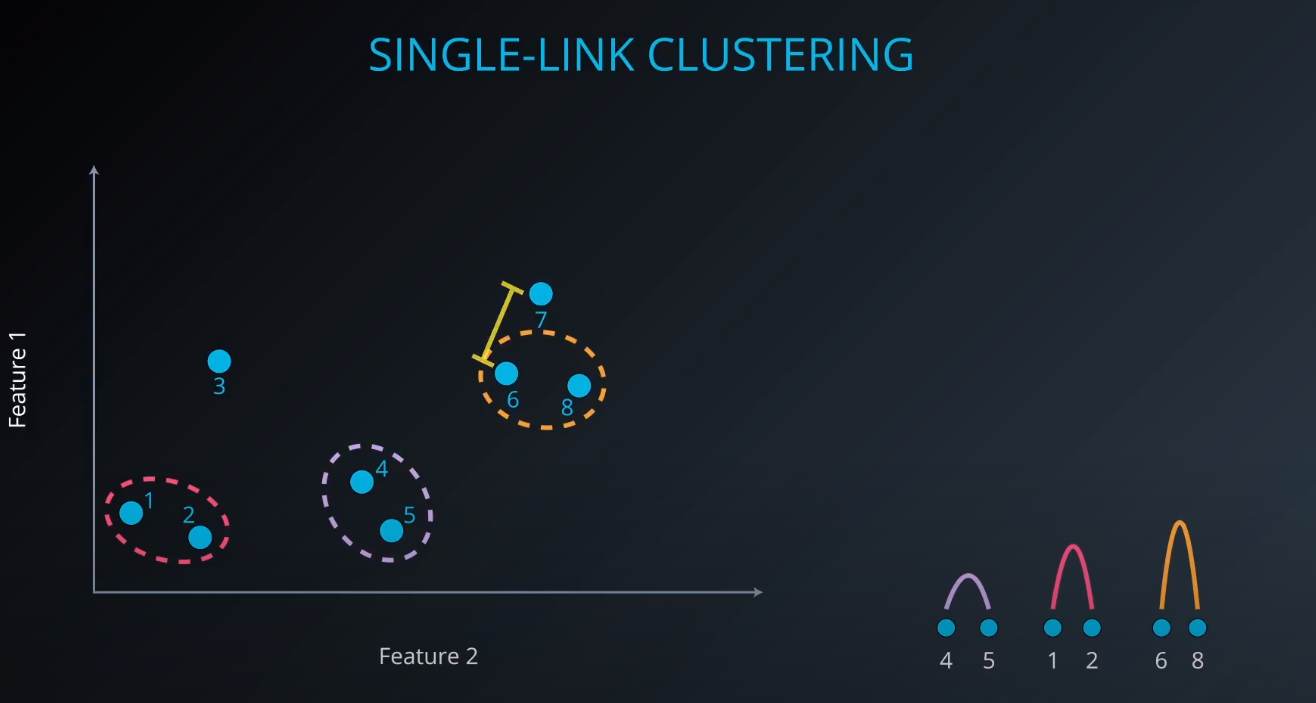
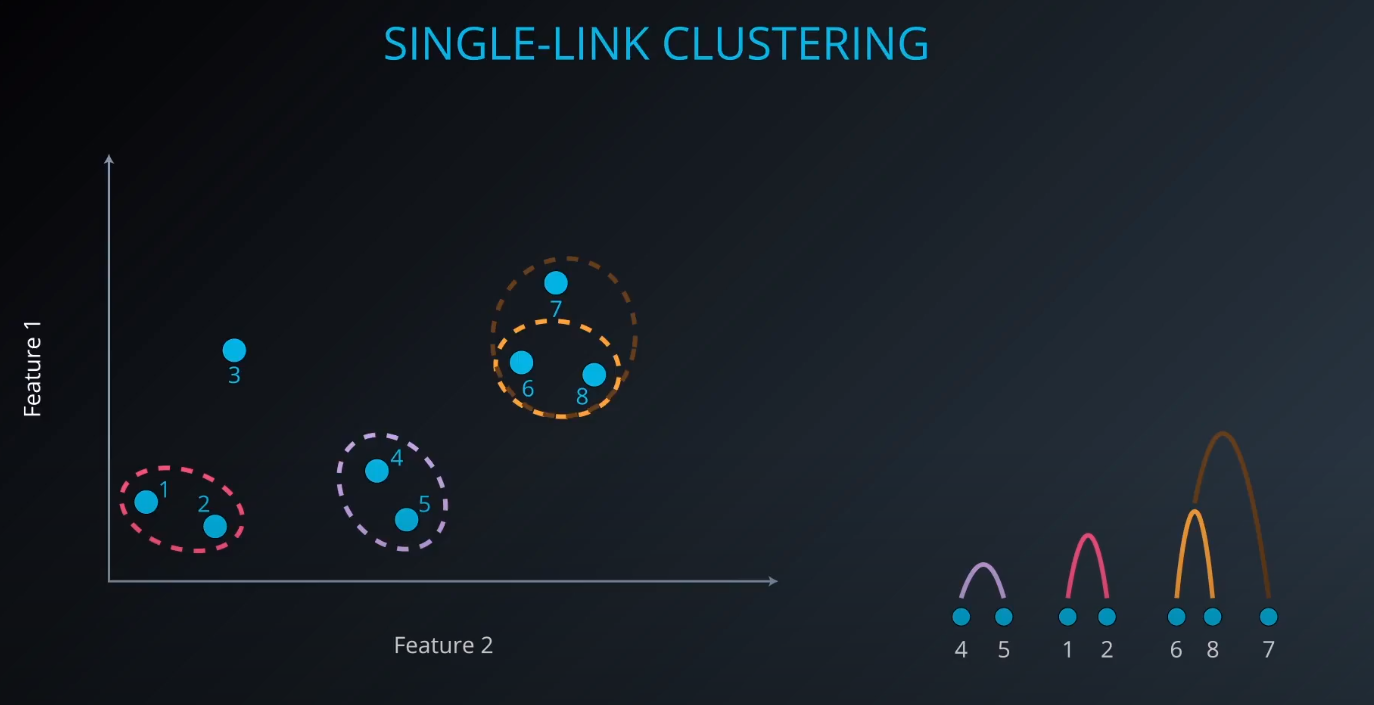
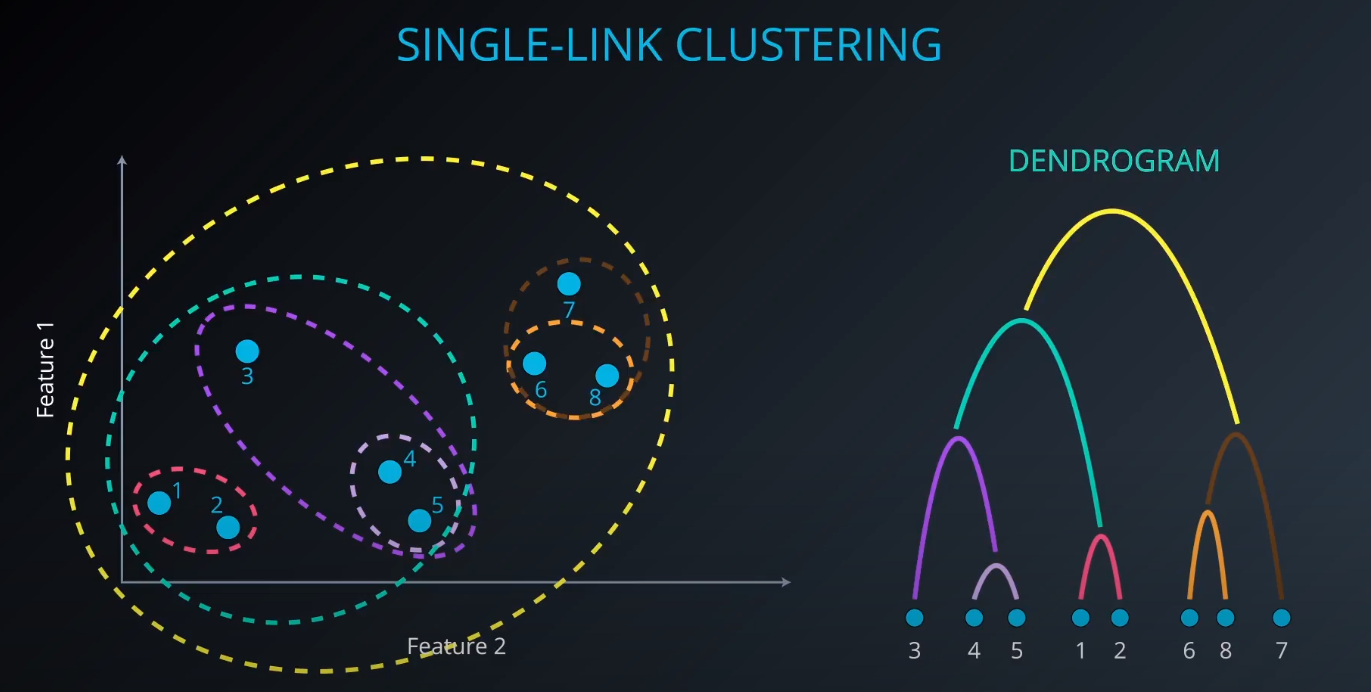
- We calculate the distance between clusters to form a bigger one (example: yellow). As we form a bigger cluster, we connect it with other ones. Example: cluster 6 and 8. We connect 6 to 7 since it is more near compared to 8 to 7.
-
-
-

-
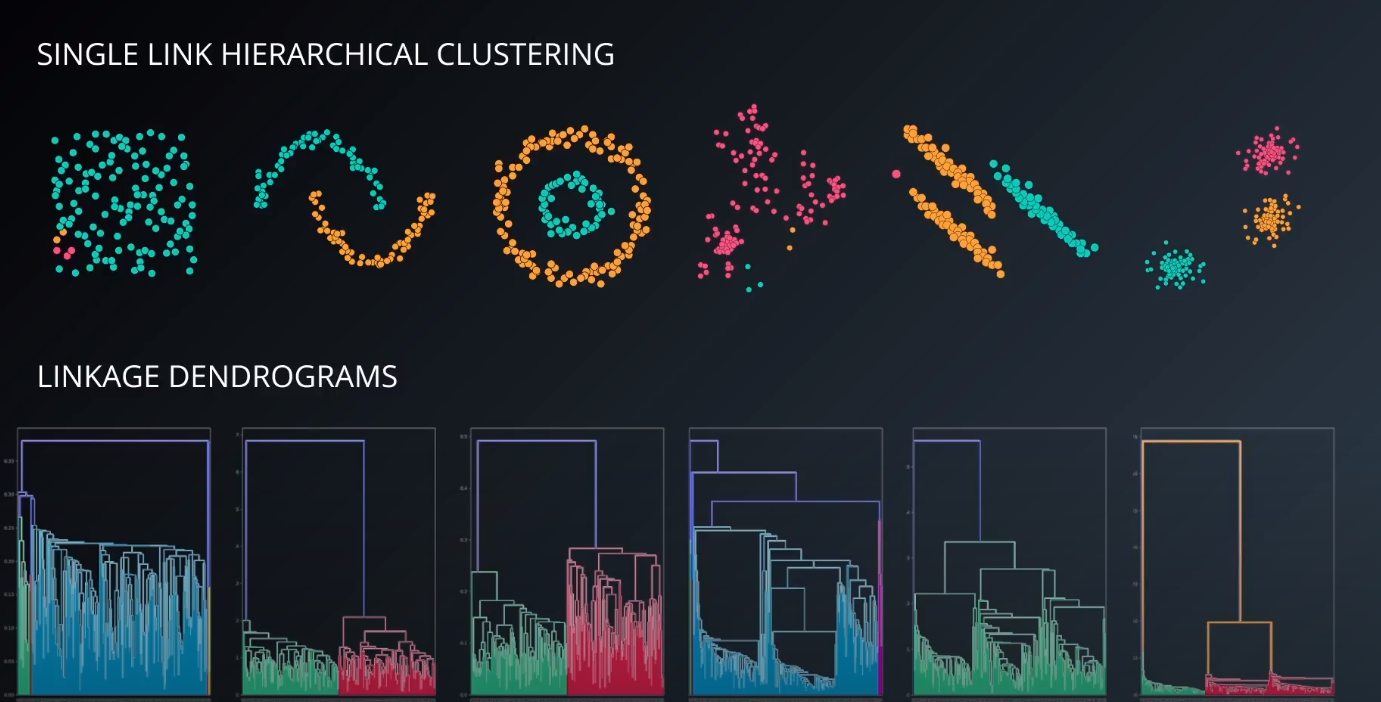
-
scikit-learndoest no include Single Link Clustering as a package, but it is inside the Agglomerative Clustering package. -
Complete Link Clustering
-
Different from Single Link, it looks for the furthest point between the clusters (not the closest).
-
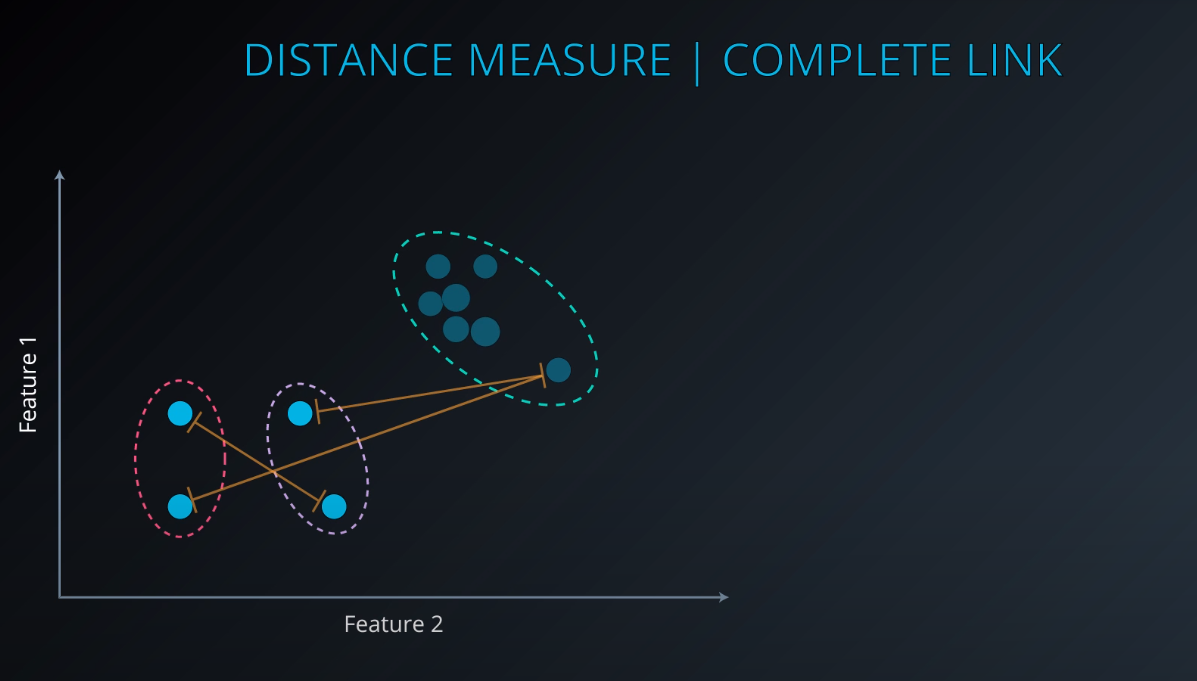
-
-
Average Link Clustering
-
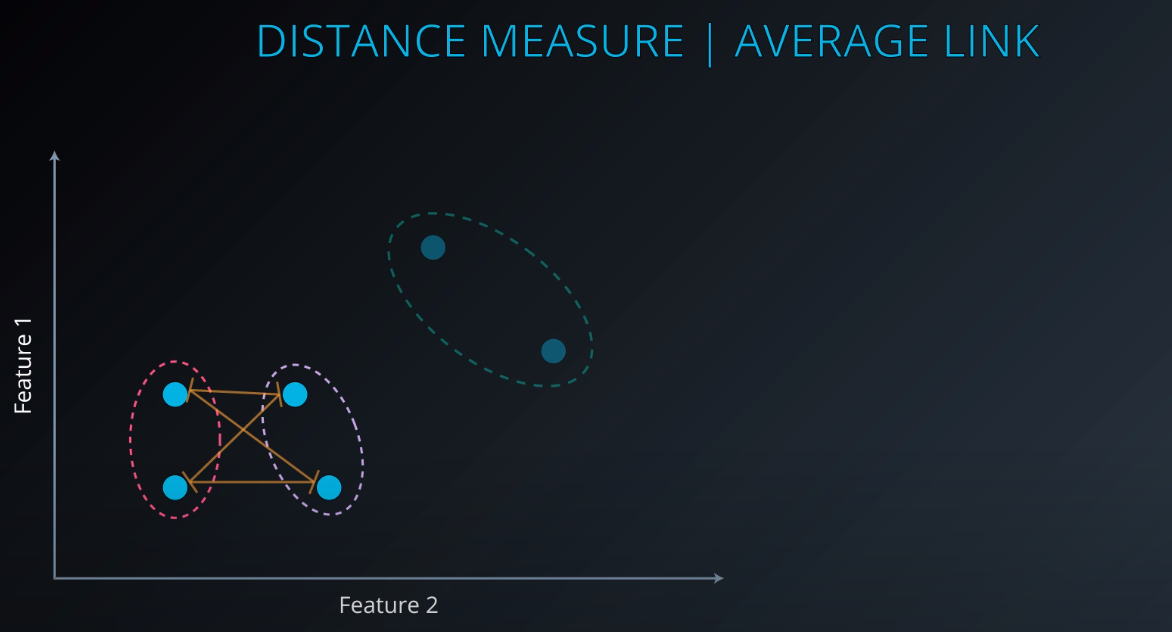
- Looks at the distance between all points in the two clusters. The average of all the points will determine the next cluster.
-
-
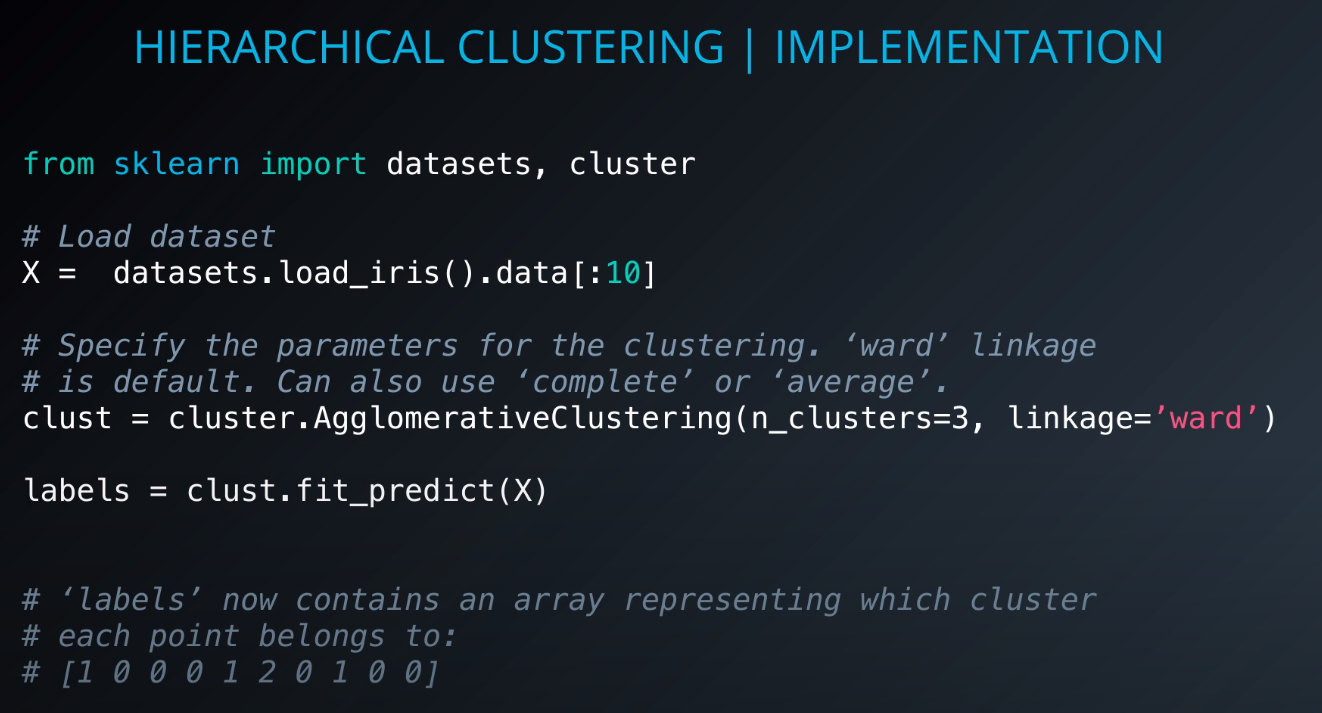
Ward's Method
-
Implementation
-
-
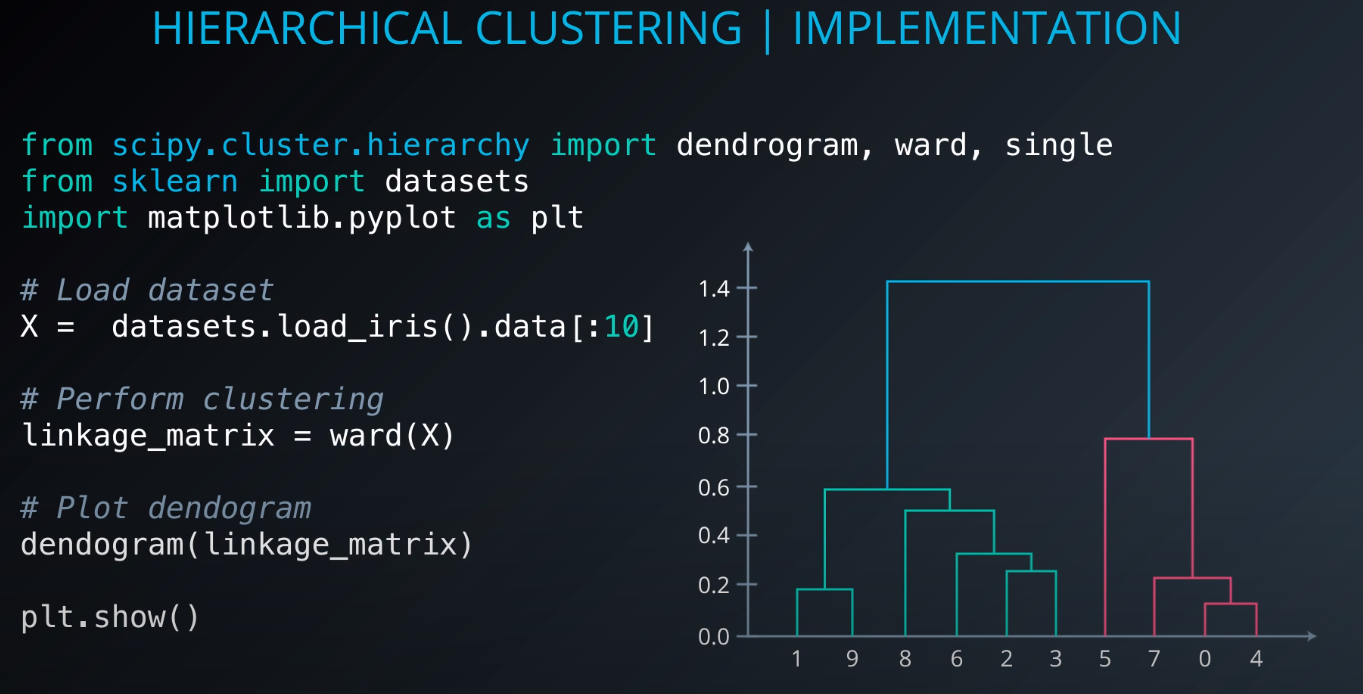
-
Hierarchical Clustering Lab [SOLUTION]
-
-
Hierarchical Clustering Overview
-
-
-
Density-Based Clustering | DBSCAN
-

- We define an Epsilon to determine the radius of search for a cluster based on a point.
-

- If no other point lives in that radius, we can define it as "noise"
-

- We also tell the algorithm the minimum number of points that form a cluster (example: min 5). If we cannot find MinPts in the Epsilon radius that gets considered as noise as well
-
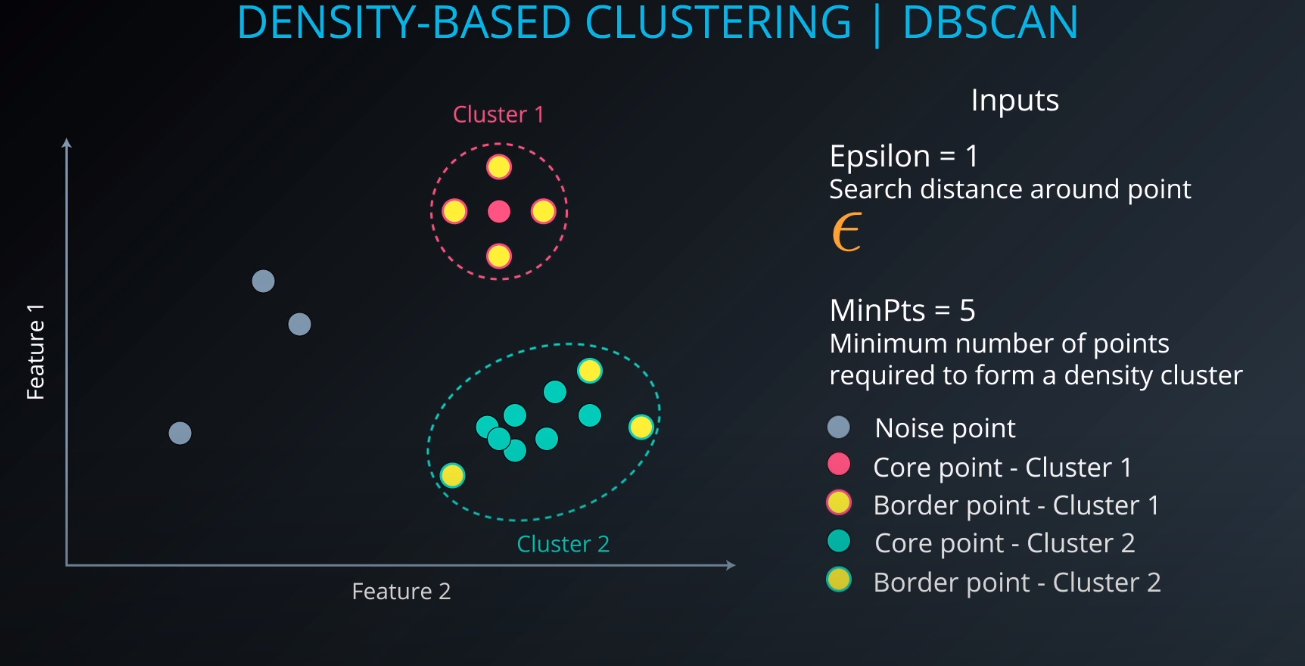
-

-
Implementation
-
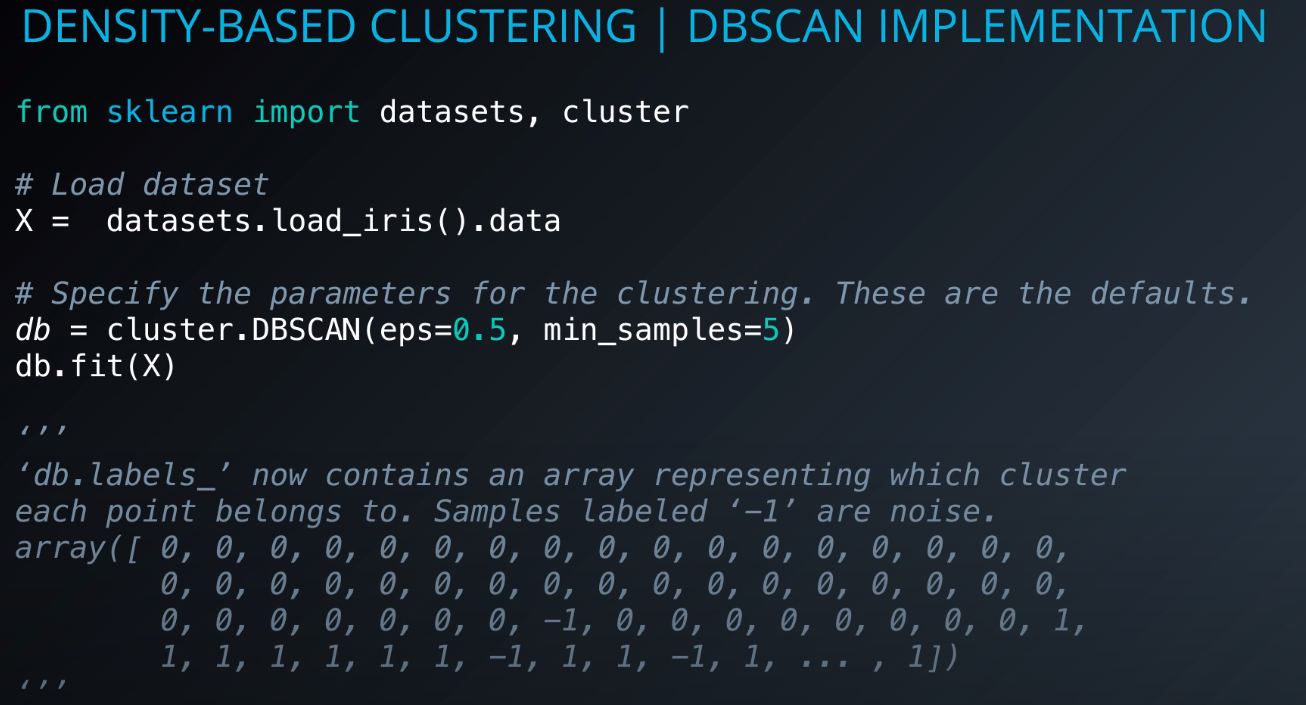
-
Check
DBSCAN Notebook [SOLUTION]lab
-
-

- For "Faces difficulty finding clusters of varying densities" we can use H-DBSCAN Hierarchical density based clustering
-
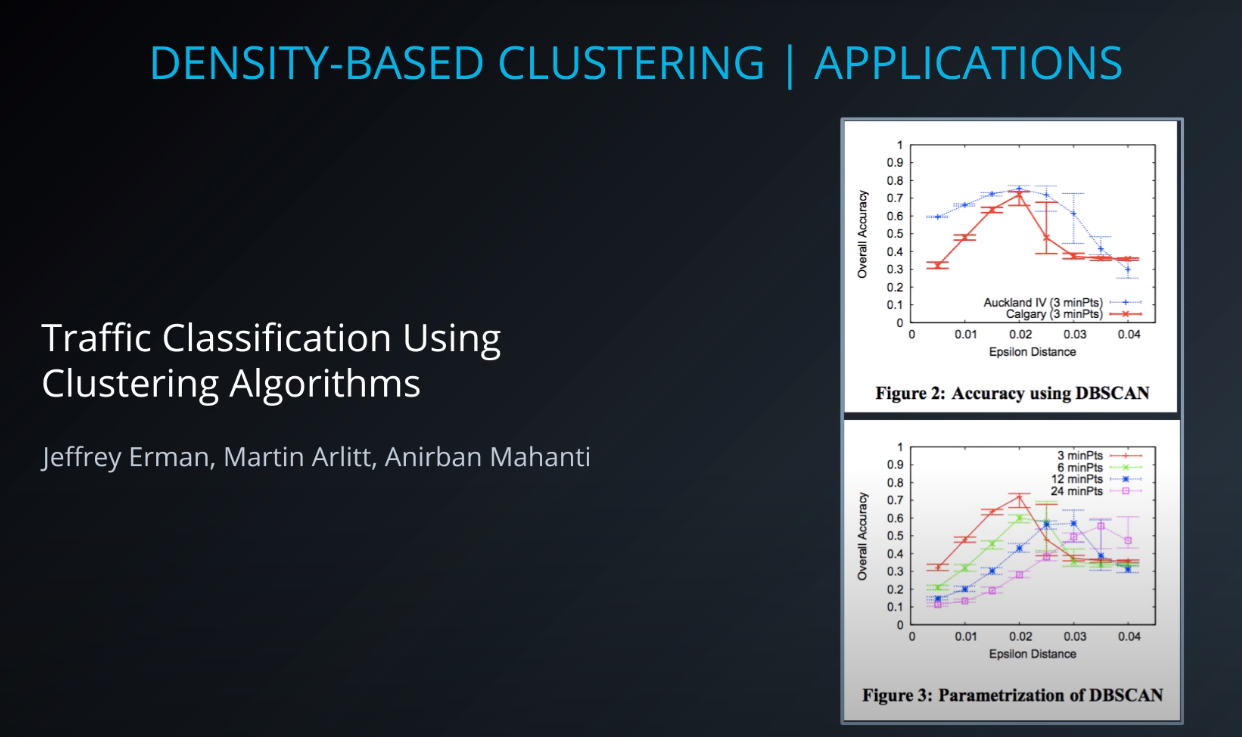
-

-




























-
Soft clustering algorithm
-
Every point in the dataset will belong to every cluster that we have with different levels of membership.
-

-
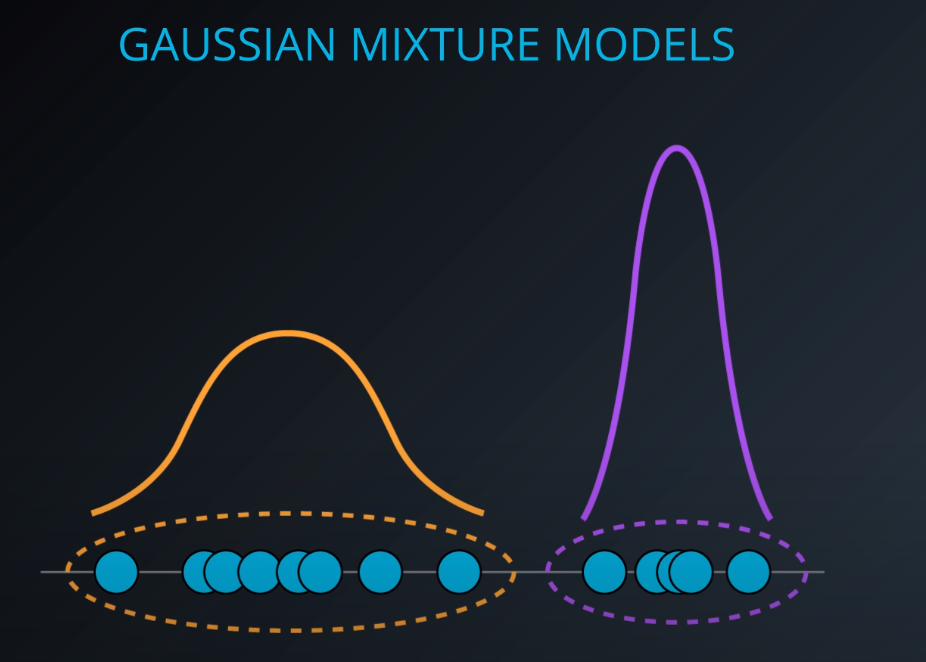
- You define the membership based on the gaussian distribution
-

-
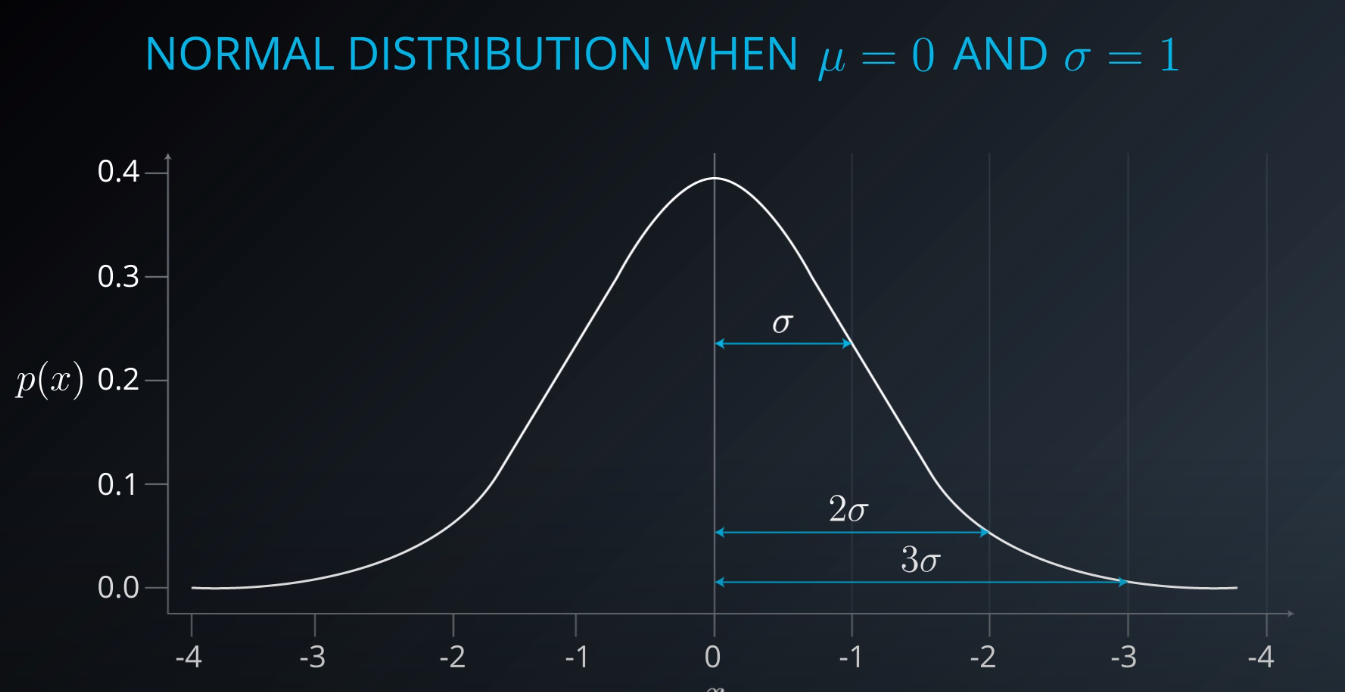
- This is a gaussian distribution
-
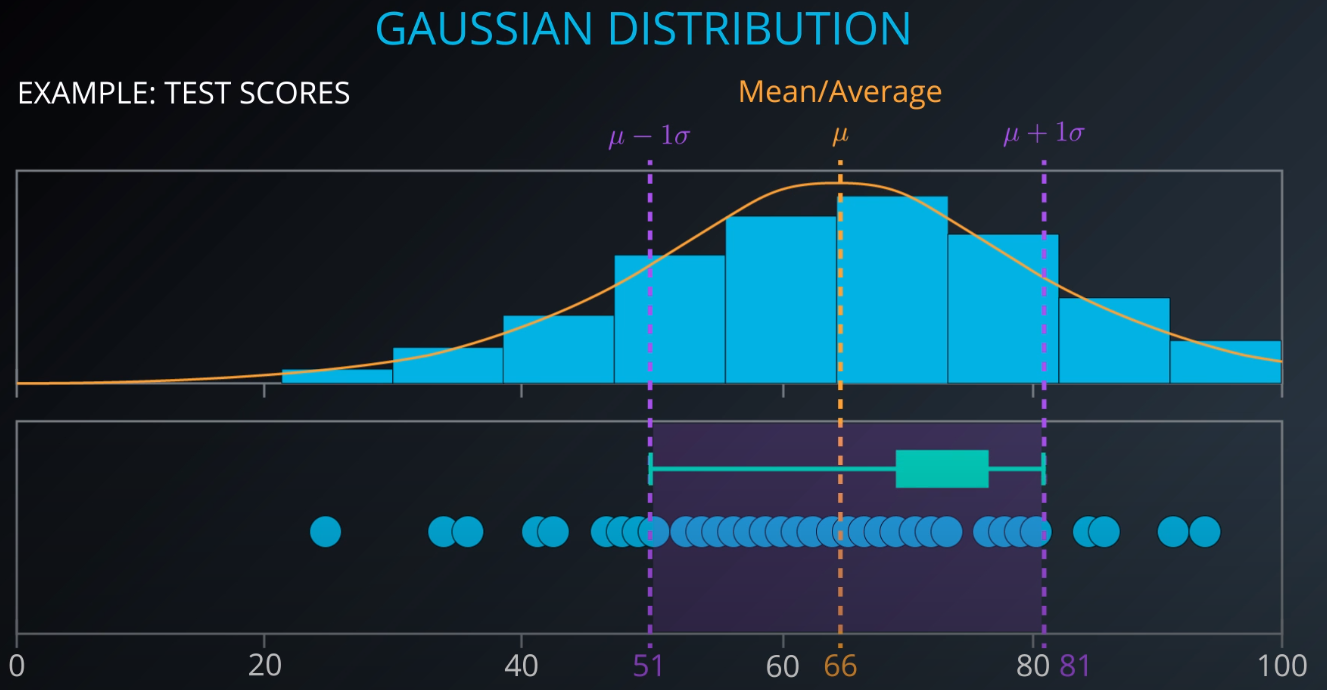
- The gaussian distribution has a mean/average (the middle), one mean minus standard deviation, and one mean plus standard deviation
-
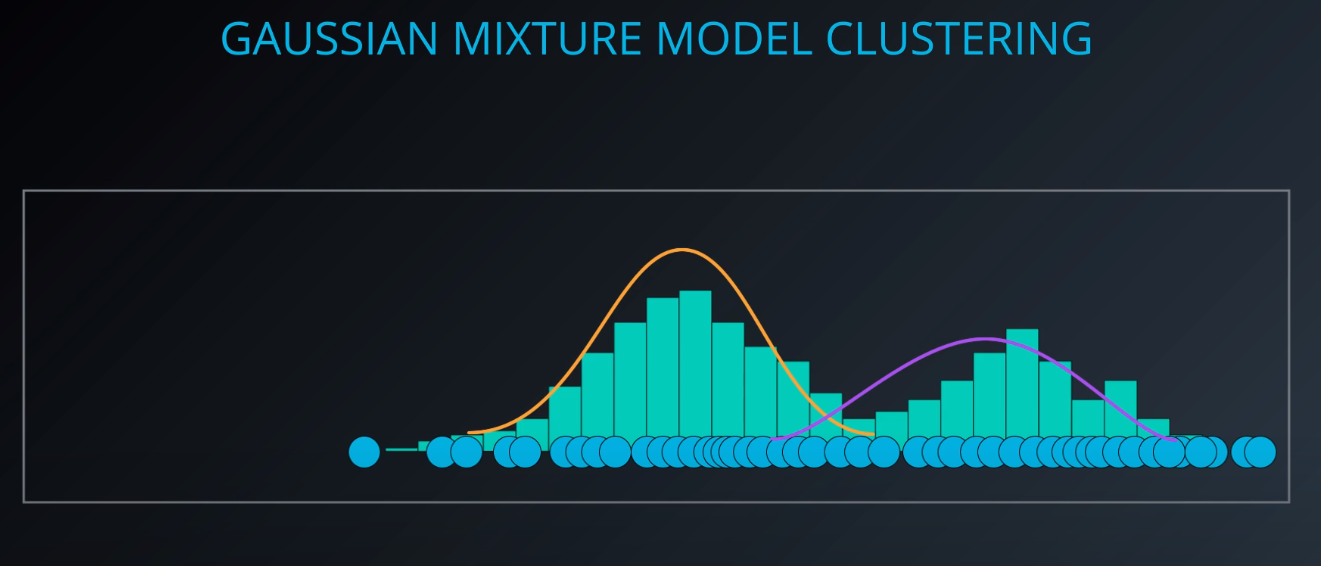
- This dataset has two gaussian distributions. A model that contains two gaussians. Each gaussian is a cluster
-
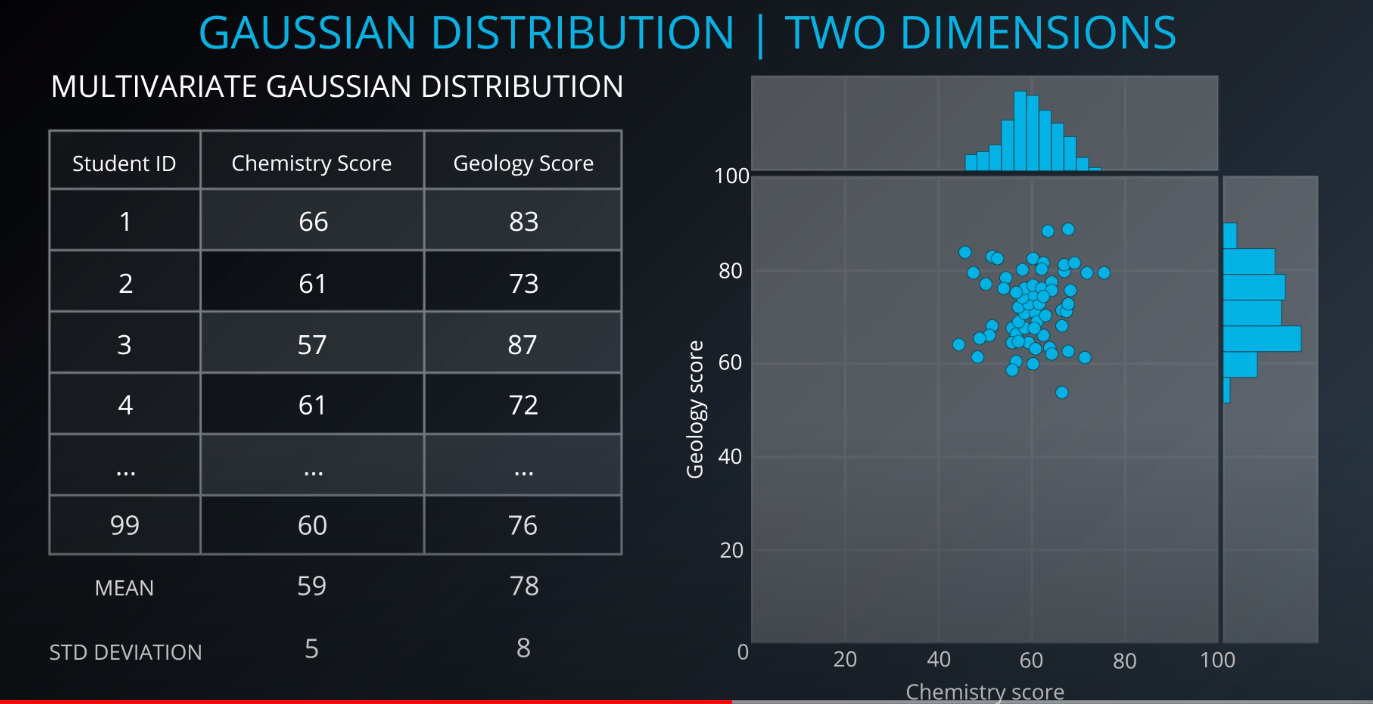
- Since we have more than one variable, this is a multivariate gaussian distribution
-
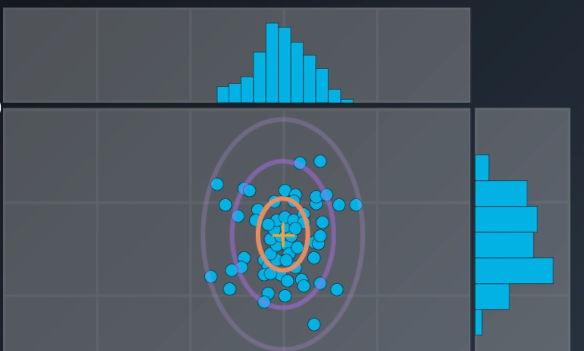
- The center is the mean, and the circle around it is the mean plus or minus the standard deviation
-
Gaussian Mixture Model Clustering
-

-
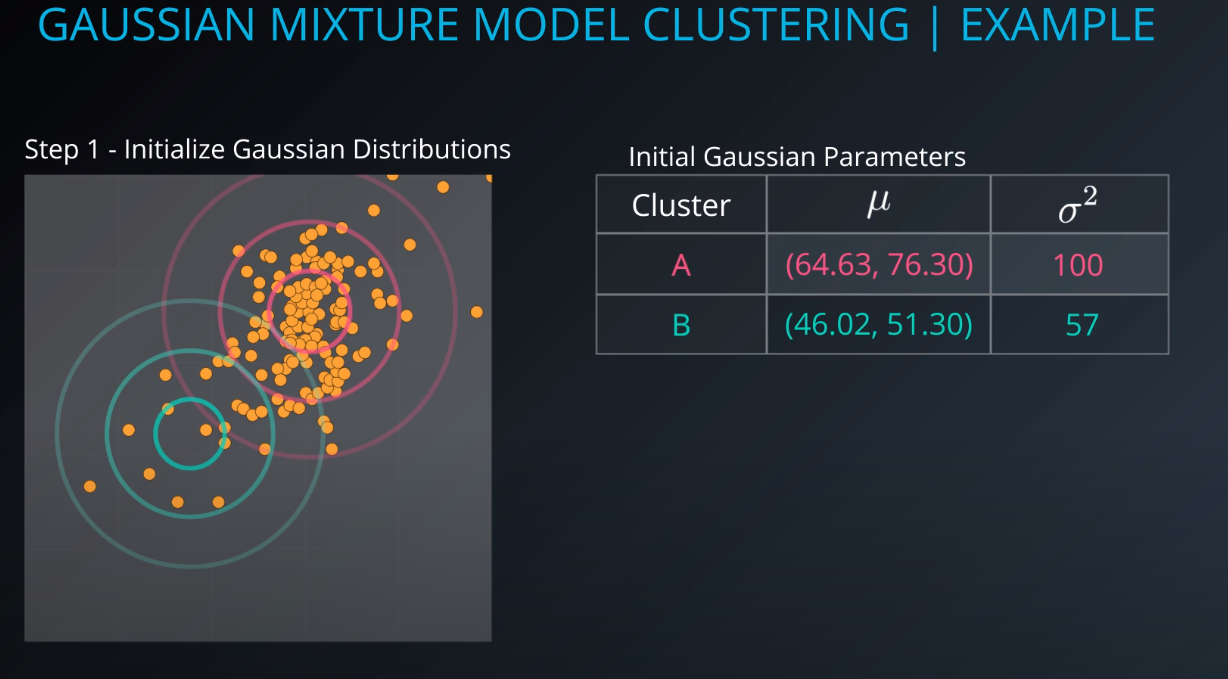
- We need to give a mean and a standard deviation for those K = 2 clusters.
- One way to do it is to set the values to the average and the mean of the entire dataset
- We could also run k-mean on the dataset, and use the clusters found by k-means to initialize the gaussian distribution
- For this example we will just make random points for the mean and the variance (standard deviation squared)
-

-
The membership of point 1 to cluster A will be calculated.
E[Z1A](1 is the point and A is the cluster, Z is a hidden/latent variable) -
We are 99.97 percent share that Point 1 is part of Cluster A
-
-

-
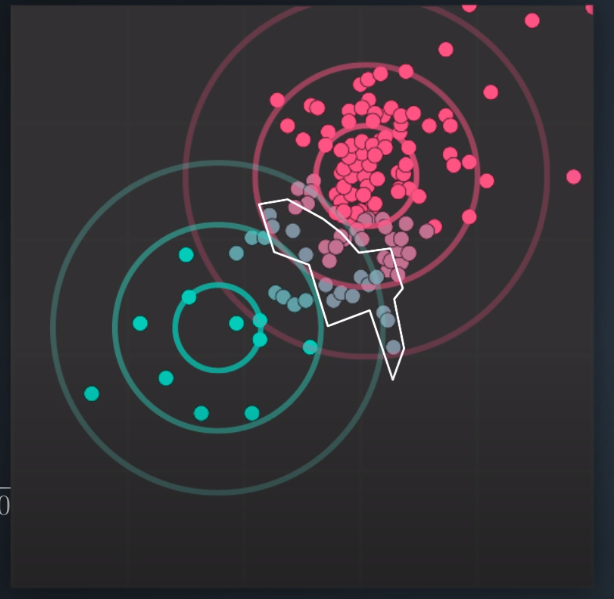
- The points in read have a strong membership with Cluster A, the points in green have a strong membership with Cluster B, and the gray points are half and half (50/50, 40/60)
-
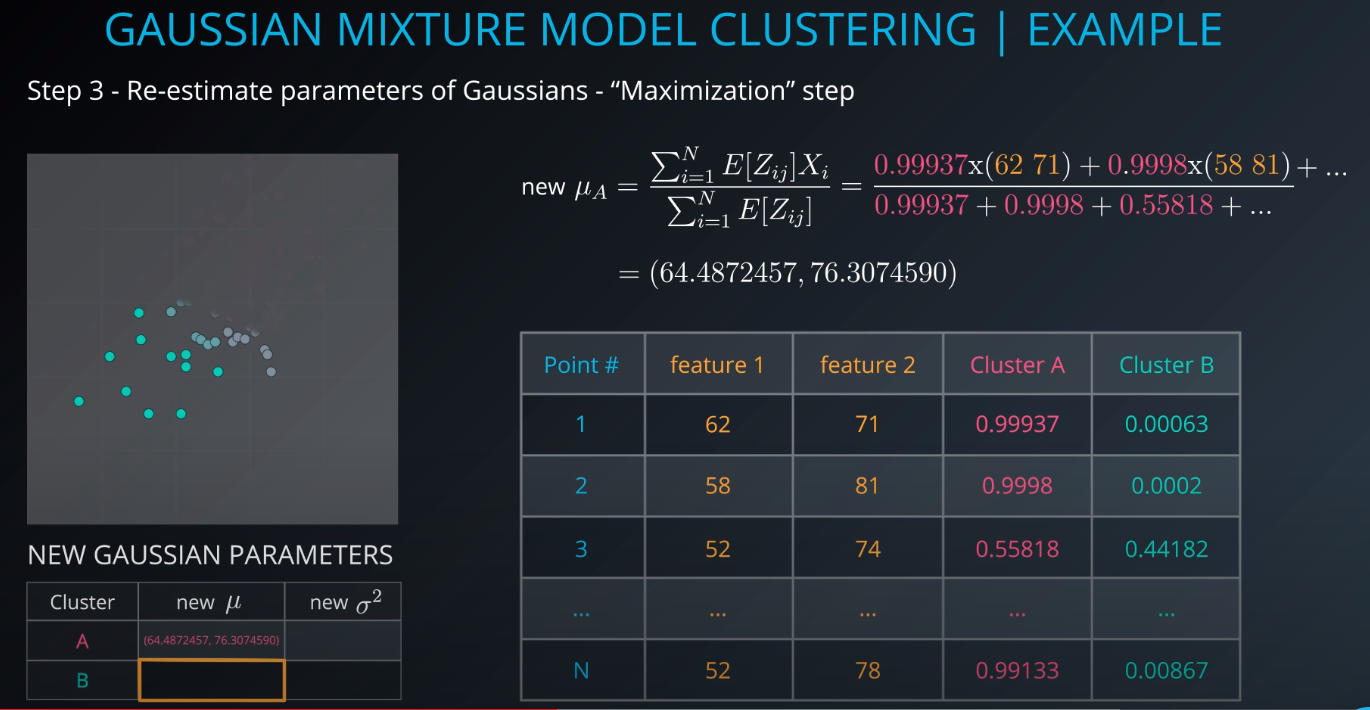
- The next step is to use the membership calculations as a new parameter for the gaussians. We use step 2 input and fill out this small table
-
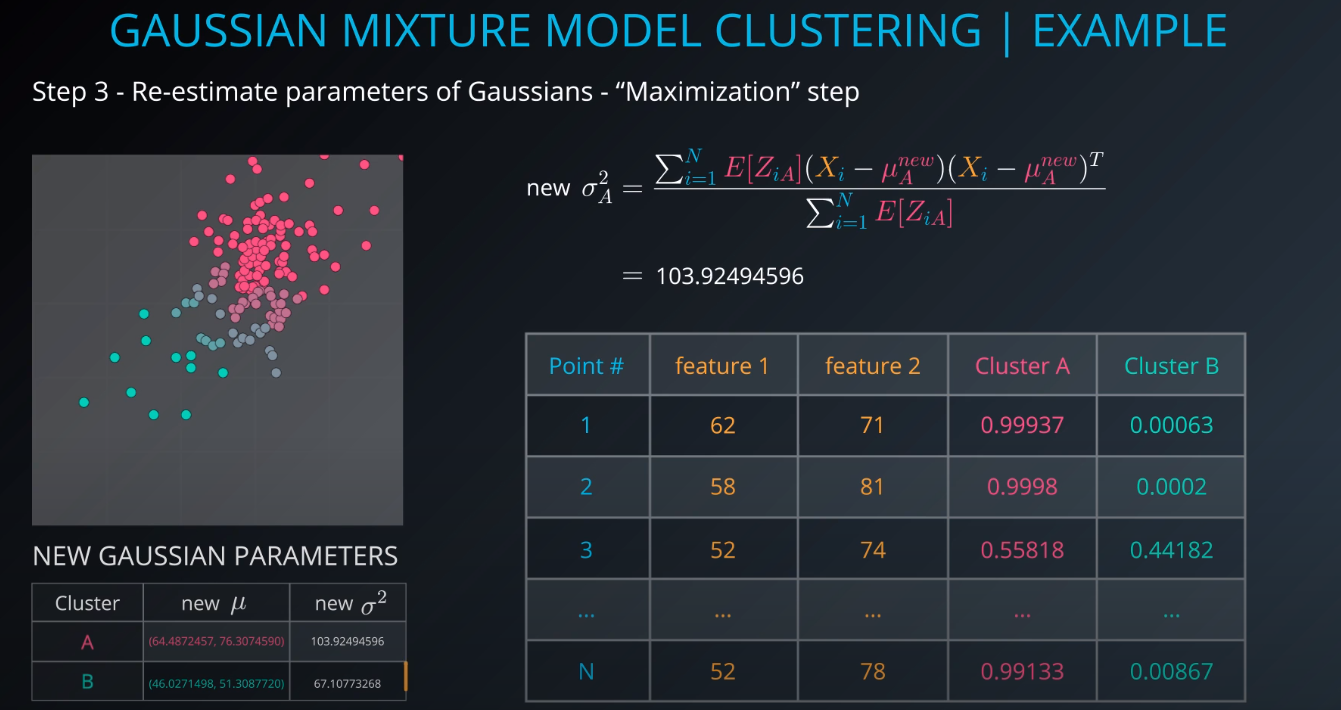
-

- The higher this number is, the more sure we are that the mixture model that we generated is responsible for creating the data / fits the dataset. We need to maximize this value
-
Implementation
-
Overview
-

- This clustering method is good for classifying documents, specially if a document is part of multiple topics or categories.
- A cluster can contain another cluster inside of it.
- Background subtraction
-
-

- The first square is a static image, and the second is a video stream. We can use the video stream to understand the pixels that are maintained as the video progresses. With that learning we can apply those pixels to the image on the top.
-
-
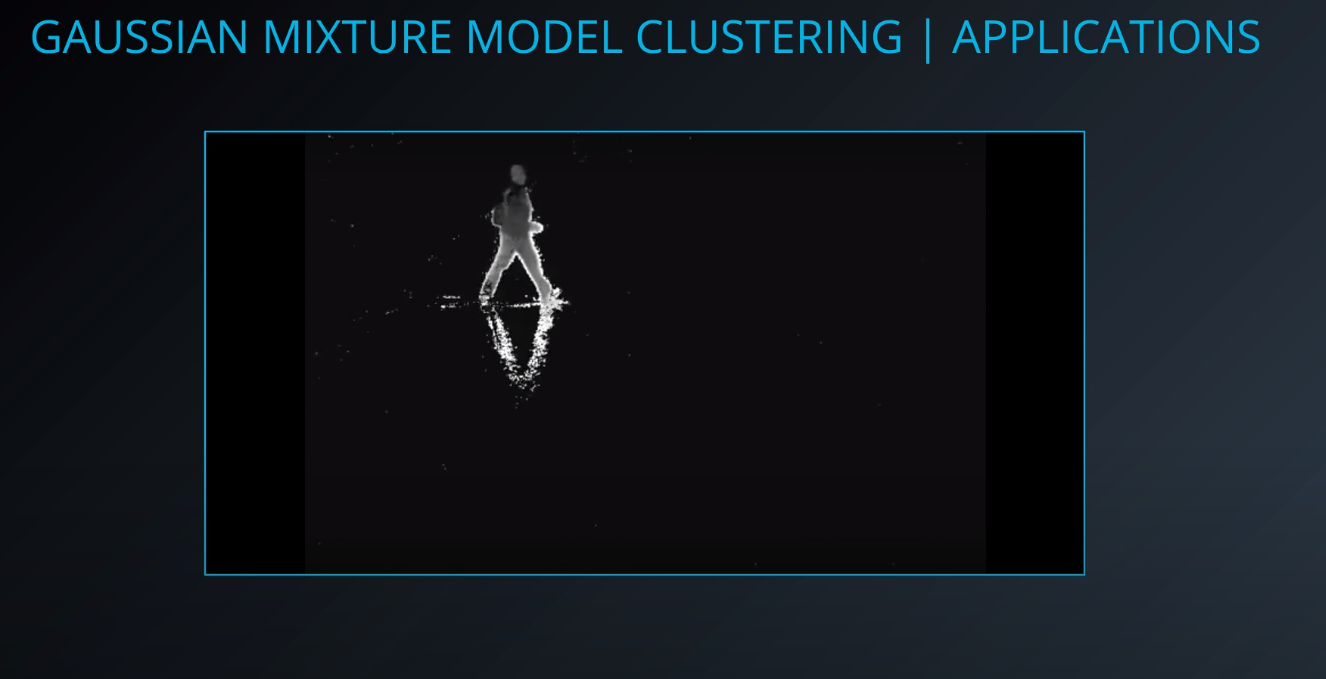
- We can subtract the background and get the moving objects from an image.
-
-
-
Cluster Analyses
-
The first step is feature selection. We don't wanna throw all our columns to the cluster algorithm
-
Feature extraction is transforming the data to generate novel features (PCA: principal component analyses)
-
We have been using euclidean distance to determine how close to points are, but we can chance that when we select our clustering algorithm.
-
Euclidean distance to determine how close two points are in a geometric sense
-
If your data is document or word embeddings your distance will be the cos distance
-
If your data is more of a gen expression type of data we would be using persons correlation
-
-
Cluster validation index
-
Cluster Validation
- The procedure of evaluating the results of a cluster objectively and quantitatively
-
Validation indices
-
External indices
-
This is the indice we use if the data was originally labelled
-
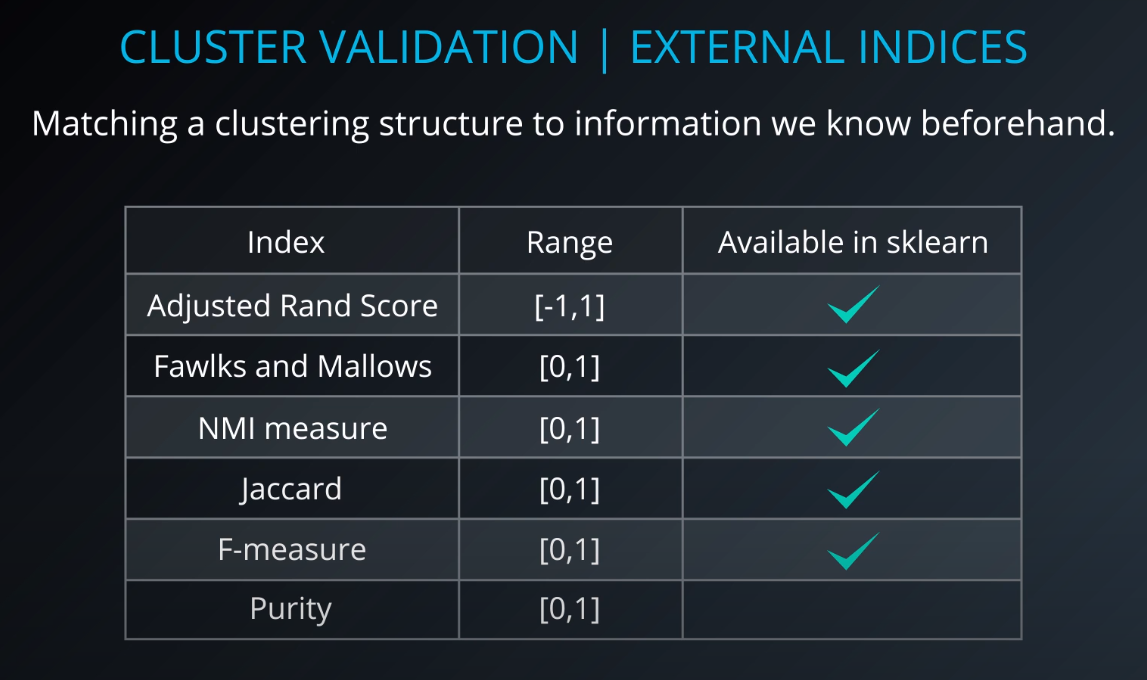
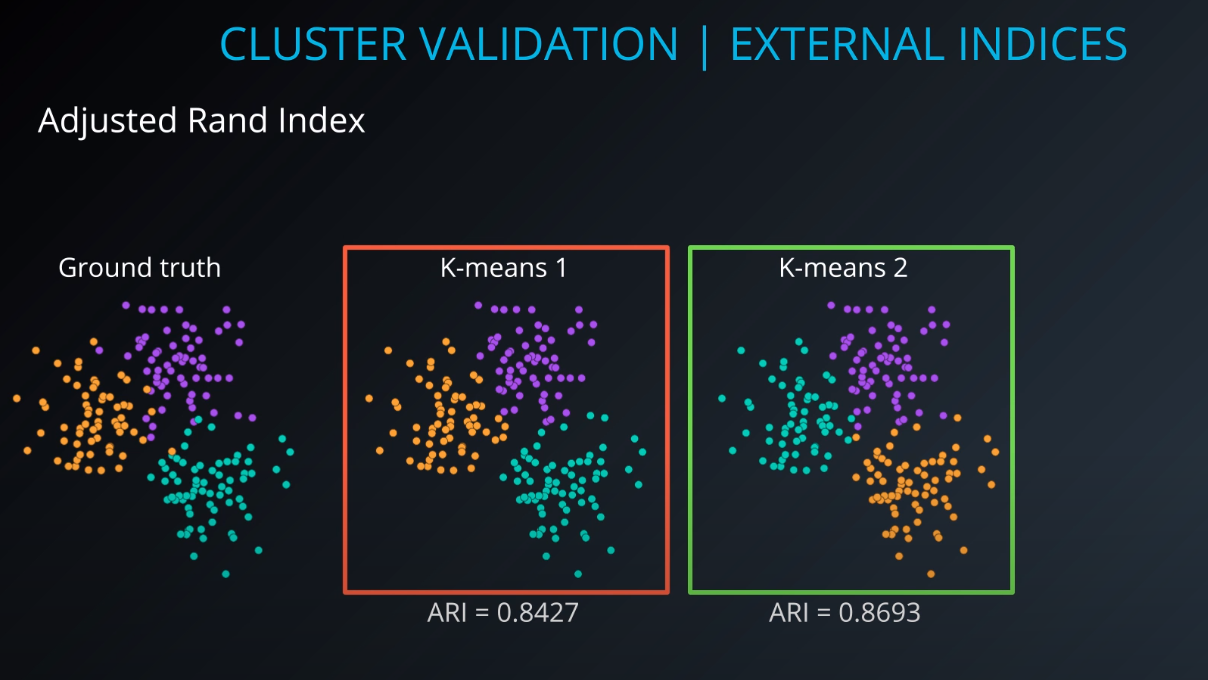
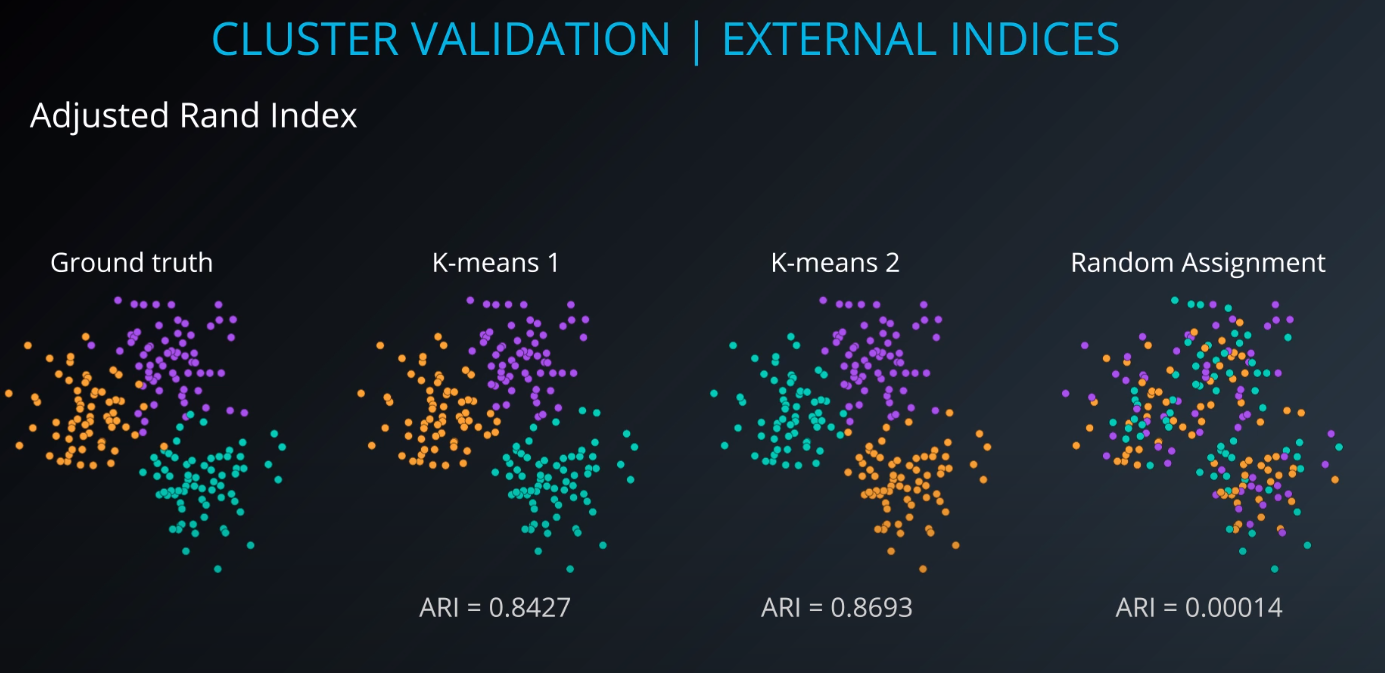
- Range = Score Range
- Original labels and the labels resulting from the clustering
-

-
-
-
-
Internal indices
-
If the data that we have is not labelled
-

-

-

-

-

-

-
For DBScan we should never use silhouette coefficient
-
DBCV should be used
-
-
-
Relative indices
- Which of two clustering structures is better in some sense
-
All of those indices check for compactness and separability of clusters
-

-
-
Check
GMM Clustering and Cluster Validation Lab [SOLUTION]for a full lab on cluster validation
-


































-
Here we will learn to transform data instead of clustering it.
-
The main ideas of PCA is to retain the informative parts of your data but with less of it.