A chatbot with minimal dependencies.
- This project demonstrates how to build a chatbot for small datasets with minimal dependencies.
- It is released with the dataset and web UI that power the chat for Scale Venture Partners.
- It can be easily (and freely) customized for any organization.
The chatbot implements a basic agent that integrates with a local vector database and OpenAI models.
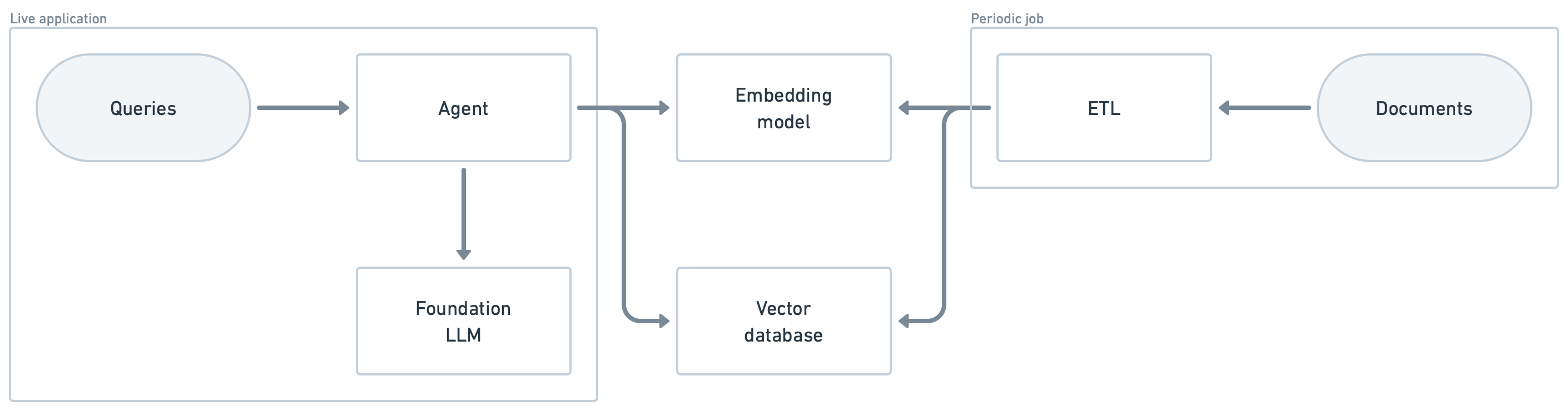
Read more about the background, architecture and learnings in the release announcement on our blog.
- Set your OpenAI API key in the
OPENAI_API_KEYenvironment variable:export OPENAI_API_KEY=your_openai_api_key - Clone the repository:
git clone https://github.com/jvrdnd/chatbot.git - Navigate to the repository:
cd chatbot - Start the chatbot:
docker compose up --build - Go to 127.0.0.1 in your browser
- Start asking questions!
- Set the
OPENAI_API_KEYenvironment variable to your OpenAI API key:export OPENAI_API_KEY=your_openai_api_key - Clone the repository:
git clone https://github.com/jvrdnd/chatbot.git - Navigate to the repository:
cd chatbot - Set the
INDEX_PATHenvironment variable to a directory in which you have write permissions:export INDEX_PATH=your_path - Install the dependencies:
pip install -r api/src/requirements.txt - Run the job that populates the vector database:
python job/src/main.py - Start the API:
uwsgi --http :9090 --wsgi-file api/src/app.py --gevent 100 - Open the file
ui/src/index.htmlin your browser - Start asking questions!
The documents that go into the vector database are generated from job/src/data.json following the job/src/schema.json specification. Customizing these files will enable the chatbot to answer questions about your data.
data.json and schema.json have matching top-level attributes which define document sections. For example, in the case of the Scale chatbot, the sections mirror those on our website because that is the source of our data.
Each section contains a list of documents, each of which is represented by a series of attributes captured in data.json. Using schema.json, this structured data is encoded into plain text documents that can be turned into embeddings. Each document is encoded as follows:
- The first line shows the name of the current section (specified in the
headingattribute of the schema), as well as the values of select attributes of the data (whose key is specified in thecontextattribute of the schema). - For every attribute that is not part of the context, a page is created. An optional descriptor for the page contents can be shown on the second line of the document if it is specifed in the
descriptorsattribute of the schema.
data.json and schema.json in this repository provide a comprehensive example of how to construct your own data files.
The web UI implements server-sent events (SSE) to support streaming responses from the LLM. It can be fully customized by making changes to the files in ui/src/.