Official code for our paper Video Background Music Generation with Controllable Music Transformer (ACM MM 2021 Best Paper Award)
[Paper] [Project Page] [Bibtex] [Colab Demo]
[2023.9] Check out our new ICCV23 paper for video background music generation. We provide a video and symbolic music dataset with rich annotations, an objective metric for video-music correspondence, and a benchmark model that utilizes music priors of chords, melody, and accompaniment along with video-music relations of semantic, color, and motion features.
[2022.5] We provide a colab notebook for demo! You can run inference code and generate a background music for your input video.
We address the unexplored task – video background music generation. We first establish three rhythmic relations between video and background music. We then propose a Controllable Music Transformer (CMT) to achieve local and global control of the music generation process. Our proposed method does not require paired video and music data for training while generates melodious and compatible music with the given video.
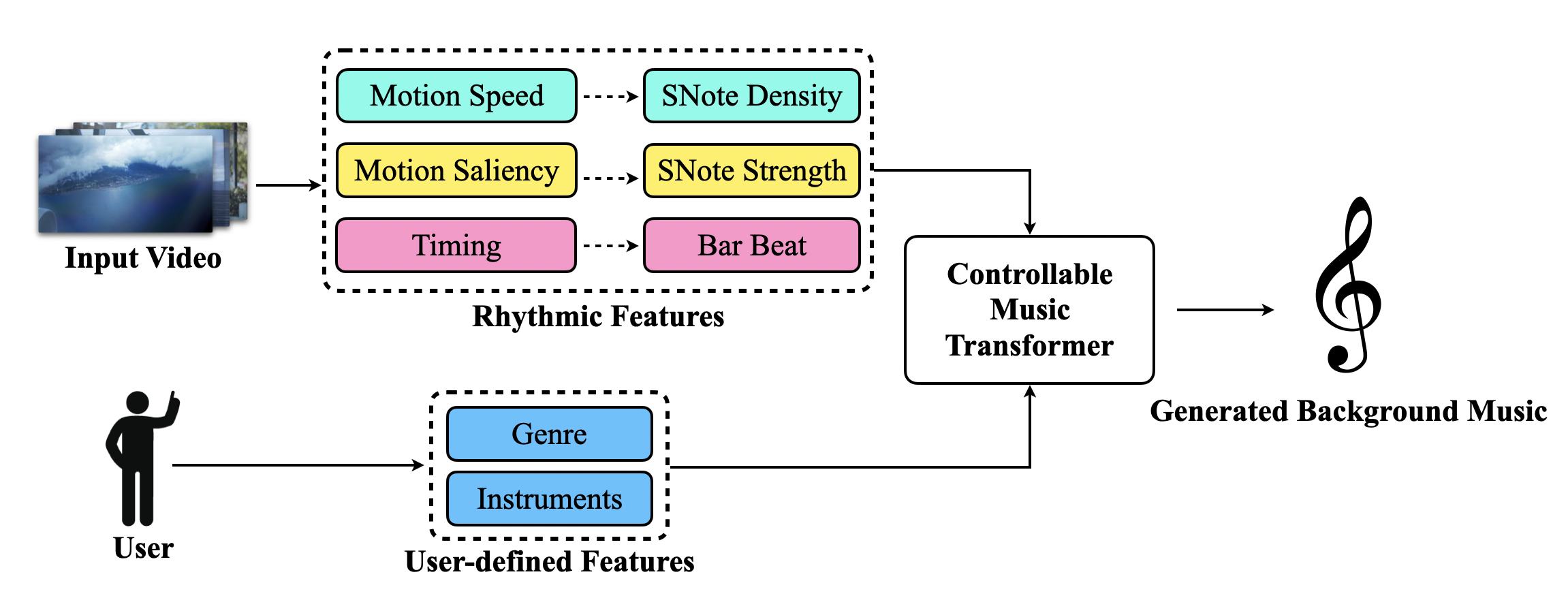
src/: code of the whole pipeline-
train.py: training script, take a npz as input music data to train the model -
model.py: code of the model -
gen_midi_conditional.py: inference script, take a npz (represents a video) as input to generate several songs -
midi2mp3.py: script of converting midi into mp3 -
src/video2npz/: convert video into npz by extracting motion saliency and motion speed
-
dataset/: processed dataset for training, in the format of npzlogs/: logs that automatically generate during training, can be used to track training processexp/: checkpoints, named after val loss (e.g.loss_8_params.pt)inference/: processed video for inference (.npz), and generated music(.mid)
-
Clone this repo
-
Download the processed training data
lpd_5_prcem_mix_v8_10000.npzfrom HERE and put it underdataset/ -
Download the pretrained model
loss_8_params.ptfrom HERE and put it underexp/ -
Install
ffmpeg=3.2.4 -
Install Python3 dependencies
pip install -r py3_requirements.txt- Choose the correct version of
torchandpytorch-fast-transformersbased on your CUDA version (see fast-transformers repo and this issue)
- Choose the correct version of
-
Install
visbeat3package:cd src/video2npz/visbeat3; python setup.py install -
(Optional) If you want to convert midi into mp3 with midi2audio:
-
A quick start by using the processed data
lpd_5_prcem_mix_v8_10000.npz(1~2 days on 8x 1080Ti GPUs):python train.py --name train_default -b 8 --gpus 0 1 2 3 4 5 6 7
-
(Optional) If you want to reproduce the whole process:
-
Download the lpd-5-cleansed dataset from HERE and put the extracted files under
dataset/lpd_5_cleansed/ -
Go to
src/and convert the pianoroll files (.npz) to midi files (~3 files / sec):python pianoroll2midi.py --in_dir ../dataset/lpd_5_cleansed/ --out_dir ../dataset/lpd_5_cleansed_midi/
-
Convert midi files to .npz files with our proposed representation (~5 files / sec):
python midi2numpy_mix.py --midi_dir ../dataset/lpd_5_cleansed_midi/ --out_name data.npz
-
Train the model (1~2 days on 8x 1080Ti GPUs):
python train.py --name train_exp --train_data ../dataset/data.npz -b 8 --gpus 0 1 2 3 4 5 6 7
-
Note: If you want to train with another MIDI dataset, please ensure that each track belongs to one of the five instruments (Drums, Piano, Guitar, Bass, or Strings) and is named exactly with its instrument. You can check this with Muspy:
import muspy
midi = muspy.read_midi('xxx.mid')
print([track.name for track in midi.tracks]) # Should be like ['Drums', 'Guitar', 'Bass', 'Strings']Inference requires one GPU. You can try our colab notebook to run inference.
It is recommended to use videos less than 2 minutes, otherwise it gets really slow
-
Resize the video into 360p
ffmpeg -i xxx.mp4 -strict -2 -vf scale=-1:360 test.mp4
-
Convert input video (MP4 format) into npz
cd src/video2npz sh video2npz.sh ../../videos/test.mp4 -
Run model to generate
.mid:python gen_midi_conditional.py -f "../inference/test.npz" -c "../exp/loss_8_params.pt" -n 5 # If using another training set, change `decoder_n_class` in `gen_midi_conditional` to the one in `train.py`
-
Convert midi into audio
-
Get tempo of the music:
-
# metadata.json is generated when running `video2npz.sh` with open("video2npz/metadata.json") as f: tempo = json.load(f)['tempo'] print("tempo:", tempo)
-
(A) Use GarageBand to convert midi into audio
- this is recommended since their soundfonts are better, and no need to install fluidsynth and soundfonts
- remember to set tempo
-
(B) Use midi2audio
# Make sure you have installed fluidsynth and downloaded soundfont python midi2mp3.py --input ../inference/get_0.mid --output ../inference/get_0.mp3
-
-
Combine original video and audio into video with BGM:
ffmpeg -i test.mp4 -i get_0.mp3 -c:v copy -c:a aac -strict experimental -map 0:v:0 -map 1:a:0 output.mp4 # test.mp4: input video # get_0.mp3: audio file generated in the previous step # output.mp4: output video with BGM
The matching method finds the five most matching music pieces from the music library for a given video.
python src/match.py inference/test.npz dataset/lpd_5_prcem_mix_v8_10000.npz@inproceedings{di2021video,
title={Video Background Music Generation with Controllable Music Transformer},
author={Di, Shangzhe and Jiang, Zeren and Liu, Si and Wang, Zhaokai and Zhu, Leyan and He, Zexin and Liu, Hongming and Yan, Shuicheng},
booktitle={Proceedings of the 29th ACM International Conference on Multimedia},
pages={2037--2045},
year={2021}
}Our code is based on Compound Word Transformer.
src/video2npz/visbeat3 is a debugged version of haofanwang/visbeat3, which is a migration of visbeat from Python2 to Python3.