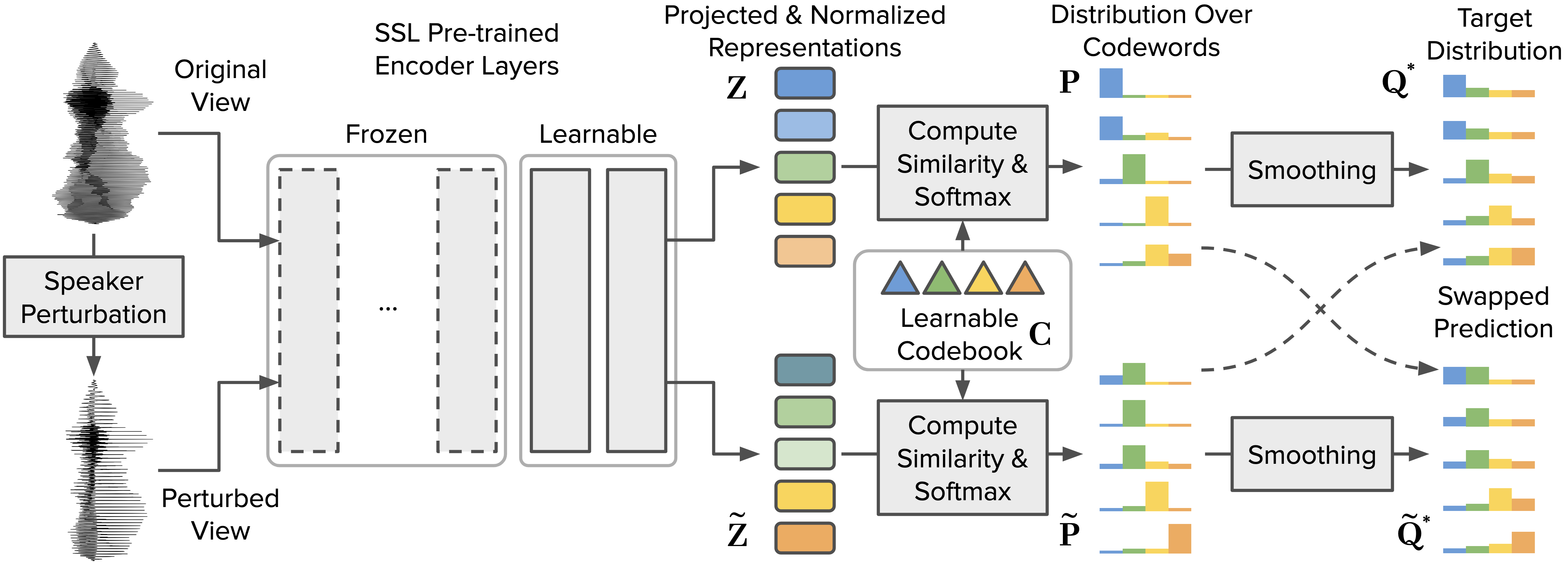
This repository is the official PyTorch implementation of the Speaker-invariant Clustering (Spin) proposed in the Interspeech 2023 paper Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering (Heng-Jui Chang, Alexander H. Liu, James Glass; MIT CSAIL).
Spin is a novel self-supervised learning method that clusters speech representations and performs swapped prediction between the original and speaker-perturbed utterances. Spin disentangles speaker information and preserves content representations with just 45 minutes of fine-tuning on a single GPU (HuBERT Base models). Spin improves pre-trained networks and outperforms prior methods in speech recognition and acoustic unit discovery.
Please cite our paper if you find this repository and/or the paper useful.
@inproceedings{chang2023spin,
author={Heng-Jui Chang and Alexander H. Liu and James Glass},
title={{Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering}},
year=2023,
booktitle={Proc. Interspeech}
}
Make sure sox is installed and your Python version is at least 3.6.
# Create virtual environment
conda create --name spin python=3.8
conda activate spin
# Install s3prl
git clone https://github.com/s3prl/s3prl.git
cd s3prl
pip install -e ".[all]"
cd ..
# Clone this repository and intall dependencies
git clone https://github.com/vectominist/spin.git
cd spin/
pip install -r requirements.txt
# Modify some s3prl files
cp s3prl_py/wav2vec2_model.py ../s3prl/s3prl/upstream/wav2vec2/wav2vec2_model.py
cp s3prl_py/WavLM.py ../s3prl/s3prl/upstream/wavlm/WavLM.pyDownload required data.
# Create a directory to save data (or any other path you like)
mkdir data
cd data
# LibriSpeech (skip if you already have this)
wget https://www.openslr.org/resources/12/train-clean-100.tar.gz
wget https://www.openslr.org/resources/12/dev-clean.tar.gz
wget https://www.openslr.org/resources/12/dev-other.tar.gz
# Decompress
tar zxvf train-clean-100.tar.gz
tar zxvf dev-clean.tar.gz
tar zxvf dev-clean.tar.gz
rm train-clean-100.tar.gz dev-clean.tar.gz dev-clean.tar.gz
# LibriSpeech Phoneme Alignments (for monitoring progress only)
wget https://huggingface.co/datasets/vectominist/spin_data/resolve/main/dev-clean.tsv
wget https://huggingface.co/datasets/vectominist/spin_data/resolve/main/dev-other.tsv
# Speaker Information
# Source: https://github.com/auspicious3000/contentvec
wget https://huggingface.co/datasets/vectominist/spin_data/resolve/main/spk2info.dictPrepare LibriSpeech dataset, see script/prepare.sh.
libri_dir: the directory of the LibriSpeech corpusjson_dir: the directory to save.jsonfiles generated fromprepare_data.py
bash script/prepare.sh ${libri_dir} ${json_dir}See config/spin.yaml.
- Modify
json_dir,spk2info, andphn_diraccording to the directories with the downloaded and preprocessed data. - Modify
loggerto switch to other loggers or simply setting it toFalseto disable logging.
data:
json_dir: /path/to/json_dir
spk2info: /path/to/spk2info.dict
val_data:
json_dir: /path/to/json_dir
phn_dir: /path/to/phoneme/alignments/dir
trainer:
logger: wandb # specify a pytorch-lightning logger you preferSee script/train.sh.
exp_dir: the directory to save checkpointsexp_name: experiment name- See
src/task/train_spin.pyfor details about available arguments like number of GPUs to be used.
bash script/train.sh ${exp_dir} ${exp_name}The trained model checkpoints can be found in ${exp_dir}/${exp_name}. Note that we use last.ckpt for evaluation and downstream tasks.
We use the s3prl toolkit for SUPERB downstream tasks.
- Modify line 26 of
s3prl_py/spin/expert.pyto the absolute path tospin/. - Copy the
s3prl_py/spindirectory tos3prlso that the toolkit can load the models.cp -R s3prl_py/spin ../s3prl/s3prl/upstream/spin
- Finally, add the following line to
../s3prl/s3prl/hub.py:from s3prl.upstream.spin.hubconf import *
All models are trained on a single NVIDIA A5000 GPU with 24GB VRAM. To reproduce similar or better performance, we suggest using GPUs larger than 24GB or specifying strategy: ddp under trainer in config/spin.yaml to enable multiple GPU training. Note that the following checkpoints are reproduced with the same recipe, so the results are slightly different from our paper. The training logs can be found in this link.
| Base Model | Clusters | PNMI | Checkpoint |
|---|---|---|---|
| HuBERT | 128 | 0.625 | link |
| HuBERT | 256 | 0.658 | link |
| HuBERT | 512 | 0.707 | link |
| HuBERT | 1024 | 0.745 | link |
| HuBERT | 2048 | 0.774 | link |
| WavLM | 128 | 0.604 | link |
| WavLM | 256 | 0.658 | link |
| WavLM | 512 | 0.714 | link |
| WavLM | 1024 | 0.748 | link |
| WavLM | 2048 | 0.775 | link |
If you have any questions, please open an issue or send me an email hengjui@mit.edu.