后缀树是一种数据结构,一个具有m个字符的字符串S的后缀树T,就是一个包含一个根节点的有向树,该树恰好带有m+1个叶子,这些叶子被赋予从0到m的标号。每一个内部节点,除了根节点以外,都至少有两个子节点,而且每条边都用S的一个子串来标识。出自同一节点的任意两条边的标识不会以相同的字符开始。后缀树的关键特征是:对于任何叶子i,从根节点到该叶子所经历的边的所有标识串连起来后恰好拼出S 的从i位置开始的后缀,即S[I,…,m]。(这里有一个规定,即字符串中不能有空格,且最后一个字符不能与前面任何一个字符相同)
为了方便理解概念,给出一个例子,下图是字符串"banana#"的后缀树。
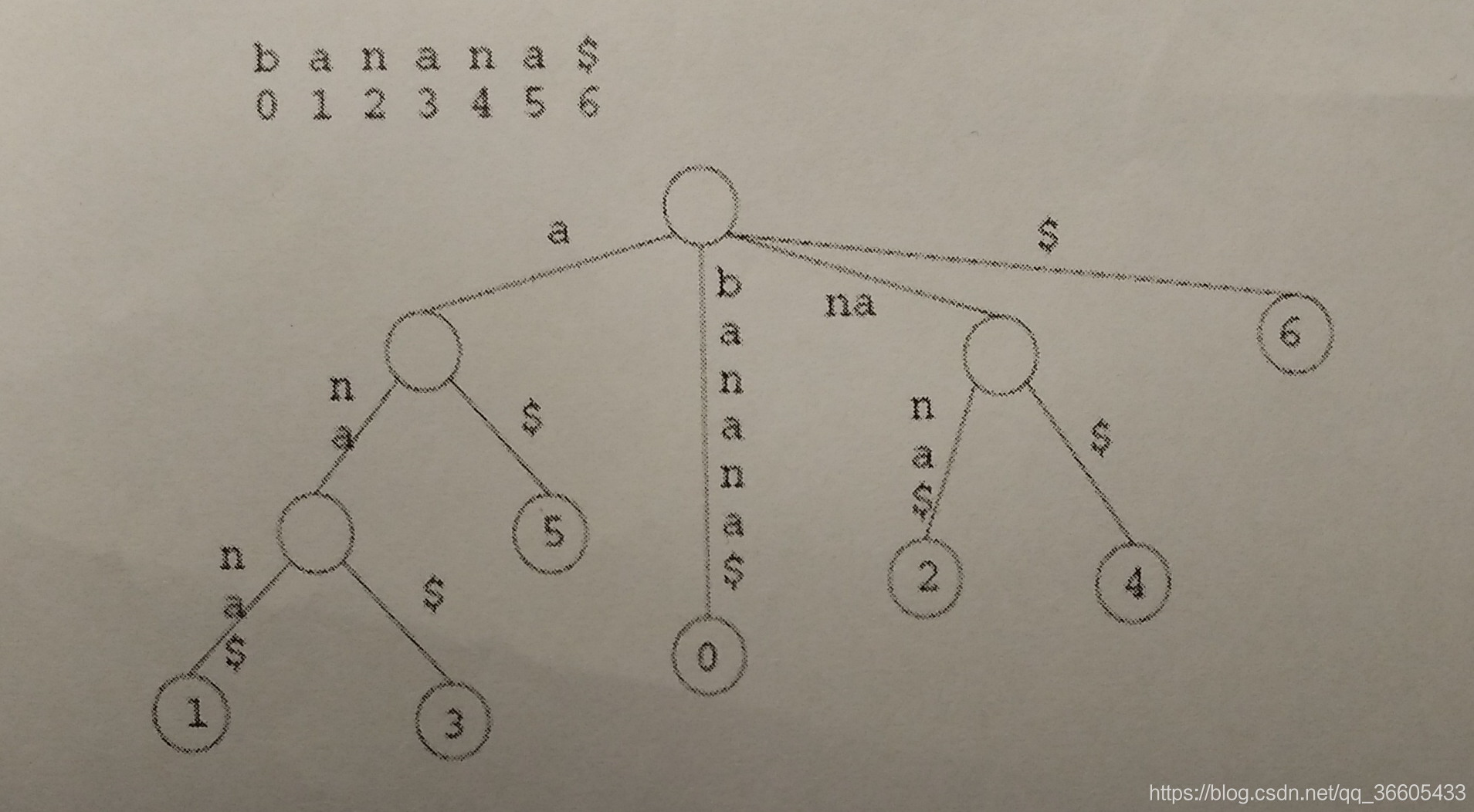
本文章利用的是Ukkonen算法构建后缀树,在 1995 年,Esko Ukkonen 发表了论文《On-line construction of suffix trees》,描述了在线性时间内构建后缀树的方法。 本文章参考数据结构系列——后缀树(附Java实现代码),理解之后做了适当的改进并用c++语言实现,代码在dev-cpp 5.11已测试。
首先解释一下将要用到的几个概念:活动点(包括活动节点,活动边,活动长度),剩余后缀数。活动点中的活动节点:是用于查找一个后缀是否已经存在这棵树里,即查找的时候从活动节点的子节点开始查找,同时当需要插入边的时候也是插入到该节点下;而活动边则是每次需要进行分割的边,即成为活动边就意味着需要被分割;而活动长度则是指明从活动边的哪个位置开始分割。剩余后缀数是我们需要插入的后缀的数量,说明程序员点就是缓存的数量,因为每次如果要插入的后缀存在,则缓存起来。另外还用到了后缀字符数组,表明将要处理的后缀字符。
对于指定的字符串,从前往后一次提取一个字符,将其加入后缀字符数组,然后剩余后缀数加一,在当前后缀树中(当然,刚开始树是空的)寻找是否存在当前字符的后缀,如果有,则继续进行循环读取下一个字符,如果没有,则进入后缀字符处理函数进行后缀处理,在后缀处理函数中,首先需要定位活动节点,然后在依据活动节点来进行不同的操作。
那么,先来了解一下几个规则:
规则一(活动节点为根节点时候的插入):
o插入叶子之后,活动节点依旧为根节点;
o活动边更新为我们接下来要更新的后缀的首字母;
o活动长度减1;
规则二(后缀链表):
o每个阶段,当我们建立新的内部节点并且不是该阶段第一次建立内部节点的时候, 我们需要用指针从当前内部节点指向本阶段最近一次建立的内部节点。
规则三(活动节点不为根节点时候的插入):
o如果当前活动节点不是根节点,那么我们每次从活动节点新建一个叶子之后,就要沿着后缀链表到达新的节点,并更新活动节点,如果不存在后缀链表,我们就转移到根节点,将活活动节点更新为根节点但活动长度以及活动边不变。
额外规则(活动点的晋升)
o如果活动边上的所有字符全部都被匹配完了(即活动边上的字符数==活动长度),则将活动边连接的下一个节点晋升为活动节点,同时重置活动长度为0。
也就是说更新活动点后,如果活动节点是根节点则按照规则一进行处理,如果活动节点不是根节点,则按照规则三进行处理,在处理过程中,还要时刻注意规则二和额外规则。当新建节点时,遵循以下规则,如果新建时,活动边存在,则分裂活动边,分割的位置由活动长度指定;如果活动边不存在,则就在活动节点下新建节点和边。
首先定义结构变量及类,包括Node结构体,Edge结构体,ActivePoint结构体,以及SuffixTree类。
Node结构体----后缀树中的节点
Node结构体----后缀树中的节点
struct Node
{
int flag;
int count;//链接的边的个数,用下边的边指针数组存储
Edge *child[max];
Edge *parent;
Node *next;//后缀链接标识
Node(){flag=-1;parent=NULL;count=0;next=NULL;}
Node(int f){flag=f;parent=NULL;count=0;next=NULL;}
};Edge结构体----后缀树中的边
struct Edge
{
string str;
Node *above,*below;//head-->above back--->below
Edge(){str="";above=NULL;below=NULL;}
Edge(Node *above,Node *below,string str)
{
this->str=str;
this->above=above;
this->below=below;
this->above->child[above->count++]=this;
this->below->parent=this;
}
Edge(Node *above,int i,Node *below,string str)
{
this->str=str;
this->above=above;
this->below=below;
this->above->child[i]=this;
this->below->parent=this;
}
};ActivePoint结构体----活动点
struct ActivePoint
{
Node *node;//活动节点
Edge *edge;//活动边
int length;//活动长度
ActivePoint(){node=NULL;edge=NULL;length=0;}
ActivePoint(Node*n,Edge*e,int len){node=n;edge=e;length=len;}
};SuffixTree类----后缀树类
class SuffixTree
{
public:
SuffixTree()
{
root=new Node();
activepoint=new ActivePoint(root,NULL,0);
reminder=0;
helpstr="";
suffixarray="";
active=NULL;
}
~SuffixTree(){delall(root);} //析构函数
void delall(Node *p);//实际释放空间函数,释放节点p的所有孩子 (从后往前)
int getlength(Node *p);//从p节点向上到根节点经历过的边的字符个数
string getstr(Node *node);//从根节点向下到p节点拼出字符串
string getallstr(){return helpstr;}//返回该树的字符串
bool search(Node *p,string str,Node *&cur);//从p节点向下寻找与字符串str匹配的,找到返回true
bool findstr(string str);//查找字符串是否存在
string findlongeststr();//寻找最长重复字符串
void finddeepestr(Node *a[],Node *p,int &cal);//寻找每个分支的最长重复字符串
int count(string str);//计算字符串str出现的次数
int countleaf(Node *p);//计算p节点下的叶节点个数
bool judgeleaf(Node *p);//判断p节点先是否全为叶节点
int find(char x);//查找指定的后缀是否存在
void build(string str);//构建后缀树
void deal(string str,int currentindex);//处理后缀函数
void showtree(){show(root,0,0);}//打印后缀树
void show(Node *p,int repeat,int len);//打印后缀树实际函数
void test()//测试用函数,展示当前活动点,后缀字符,剩余后缀数等信息
{
if(activepoint->edge!=NULL)
{
cout<<"\n apnode="<<getstr(activepoint->node)<<",apedge="<<activepoint->edge->str<<",aplen="<<activepoint->length;
cout<<",reminder="<<reminder<<",suffixarray="<<suffixarray<<"\n";
}
else
{
cout<<"\n apnode="<<getstr(activepoint->node)<<",apedge=NULL,aplen="<<activepoint->length;
cout<<",reminder="<<reminder<<",suffixarray="<<suffixarray<<"\n";
}
}
private:
Node *root;
ActivePoint *activepoint;
int reminder;
string suffixarray;
Node *active;
string helpstr;
};build(String word):在SuffixTree中定义一个build(String word)方法,是后缀树构建的入口函数。首先依次提取字符串的每个字符,并按照算法步骤逐个插入。find(char w)用于查找指定的后缀是否存在(这里所说的后缀其实就是单个字符,因为单个字符代表的就是以该字符开头的后缀)。如果当前后缀未找到,就进入后缀字符处理函数deal(),如果找到,就继续循环。
find():查找后缀是否存在是从活动边开始查找,如果活动边为NULL,则从活动节点的子节点挨个查找,查找是通过比较边上的指定位置(活动长度指定)与查找字符是否相等。这里有个地方需要注意:算法中提到,如果一个活动边已到达结尾(即活动长度==活动边的字符长度),则将活动边晋升为活动节点,并重置活动边和活动长度为NULL和0。
deal():该方法是用来处理后缀字符的,也是后缀树构建中的主要部分,主要就是依据上文提到的几个规则来进行。