COYO-700M is a large-scale dataset that contains 747M image-text pairs as well as many other meta-attributes to increase the usability to train various models. Our dataset follows a similar strategy to previous vision-and-language datasets, collecting many informative pairs of alt-text and its associated image in HTML documents. We expect COYO to be used to train popular large-scale foundation models complementary to other similar datasets.
More details on the data acquisition process can be found in [our paper] (which will be updated soon).

- Nov 2022: Release COYO-Labeled-300M
- Aug 2022: Release COYO-700M Dataset
- We collected about 10 billion pairs of alt-text and image sources in HTML documents in CommonCrawl from Oct. 2020 to Aug. 2021. and eliminated uninformative pairs through the image and text level filtering process with minimal cost. The following figure outlines our data collection procedure.

- Included all image formats that Pillow library can decode. (JPEG, WEBP, PNG, BMP, ...)
- Removed images less than 5KB image size.
- Removed images with an aspect ratio greater than 3.0.
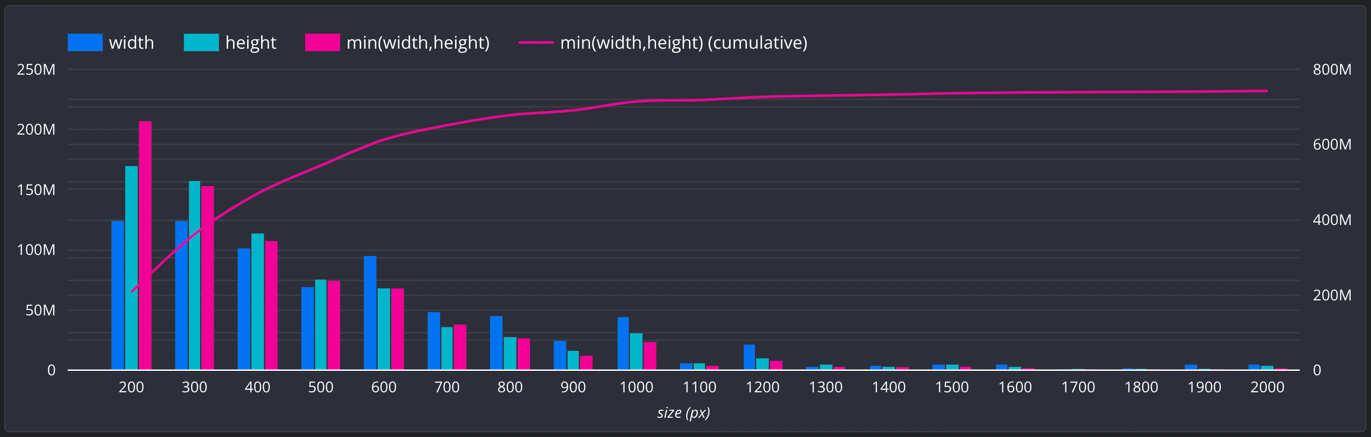
- Removed images with min(width, height) < 200.
- Removed images with a score of OpenNSFW2 or GantMan/NSFW higher than 0.5.
- Removed all duplicate images based on the image pHash value from external public datasets.
- ImageNet-1K/21K, Flickr-30K, MS-COCO, CC-3M, CC-12M
- Collected only English text using cld3.
- Replaced consecutive whitespace characters with a single whitespace and removed the whitespace before and after the sentence.
- e.g.
"\n \n Load image into Gallery viewer, valentine&#39;s day roses\n \n" → "Load image into Gallery viewer, valentine&#39;s day roses"
- e.g.
- Removed texts with a length of 5 or less.
- Removed texts that do not have a noun form.
- Removed texts with less than 3 words or more than 256 words and texts over 1000 in length.
- Removed texts appearing more than 10 times.
- e.g.
“thumbnail for”, “image for”, “picture of”
- e.g.
- Removed texts containing NSFW words collected from profanity_filter, better_profanity, and google_twunter_lol.
- Removed duplicated samples based on (image_phash, text).
- Different text may exist for the same image URL.
| id | url | text | width | height | image_phash | text_length | word_count | num_tokens_bert | num_tokens_gpt | num_faces | clip_similarity_vitb32 | clip_similarity_vitl14 | nsfw_score_opennsfw2 | nsfw_score_gantman | watermark_score | aesthetic_score_laion_v2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4896263451343 |  |
Fishing Fleet (Monterey), California art by Art Riley. HD giclee art prints for sale at CaliforniaWatercolor.com - original California paintings, & premium giclee prints for sale | 600 | 447 | bac58374982e0fc7 | 178 | 25 | 39 | 40 | 0 | 0.319336 | 0.248169 | 2.54512e-05 | 0.0293861 | 0.0406009 | 7.04812 |
| 1425929344479 |  |
The Gate by Pete2453 | 600 | 347 | 8374726575bc0f8a | 20 | 4 | 6 | 6 | 0 | 0.24939 | 0.203735 | 6.97374e-06 | 0.00823276 | 0.0721415 | 6.98521 |
| 7456063527931 |  |
Beautiful Pictures From the Shores of the Mythical Land (42 | 600 | 320 | 949d1fe559e2cc90 | 59 | 10 | 11 | 14 | 0 | 0.290771 | 0.179321 | 0.0130615 | 0.0178628 | 0.489642 | 6.94643 |
| 3221225511175 |  |
contemporary expensive lighting fixtures with minimum lighting | 800 | 499 | e5ea35075ab912c6 | 62 | 7 | 7 | 8 | 0 | 0.263916 | 0.217896 | 0.000990868 | 0.0137114 | 0.0960748 | 4.57594 |
| 5626407855002 |  |
Nintendo Co.'s Super Mario is displayed on coffee mugs for sale at the Nintendo World store in New York, U.S., on Friday, May 17, 2013. | 2000 | 1309 | 9311891e9437f4f3 | 135 | 27 | 37 | 35 | 0 | 0.400878 | 0.316650 | 0.00362968 | 0.0317519 | 0.0022693 | 6.324910 |
| 1125282207474 |  |
FILE PHOTO: A rainbow appears on the Auckland skyline featuring Sky Tower in New Zealand | 800 | 525 | 85b89c0166ee63be | 88 | 15 | 16 | 16 | 0 | 0.4453125 | 0.3505859 | 2.640485e-05 | 0.012074 | 0.0219129 | 5.294523 |
| 1434519186493 |  |
A man covers himself with algae as he poses for photographs on a beach in Qingdao, Shandong province on Tuesday, July 23, 2013. -- FILE PHOTO: REUTERS | 860 | 573 | f2c48dabbf93810a | 150 | 26 | 35 | 36 | 7 | 0.4165039 | 0.3427734 | 0.025009 | 0.01608 | 0.072775 | 6.833739 |
| count | ratio | |
|---|---|---|
| # of image-text pairs | 746,972,269 | 100.00% |
| # of unique urls | 656,114,783 | 87.84% |
| # of unique image_phash | 579,679,137 | 77.60% |
| # of unique text | 566,253,888 | 75.81% |
| name | type | description |
|---|---|---|
| id | long | Unique 64-bit integer ID generated by monotonically_increasing_id() |
| url | string | The image URL extracted from the src attribute of the <img> tag |
| text | string | The text extracted from the alt attribute of the <img> tag |
| width | integer | The width of the image |
| height | integer | The height of the image |
| image_phash | string | The perceptual hash(pHash) of the image |
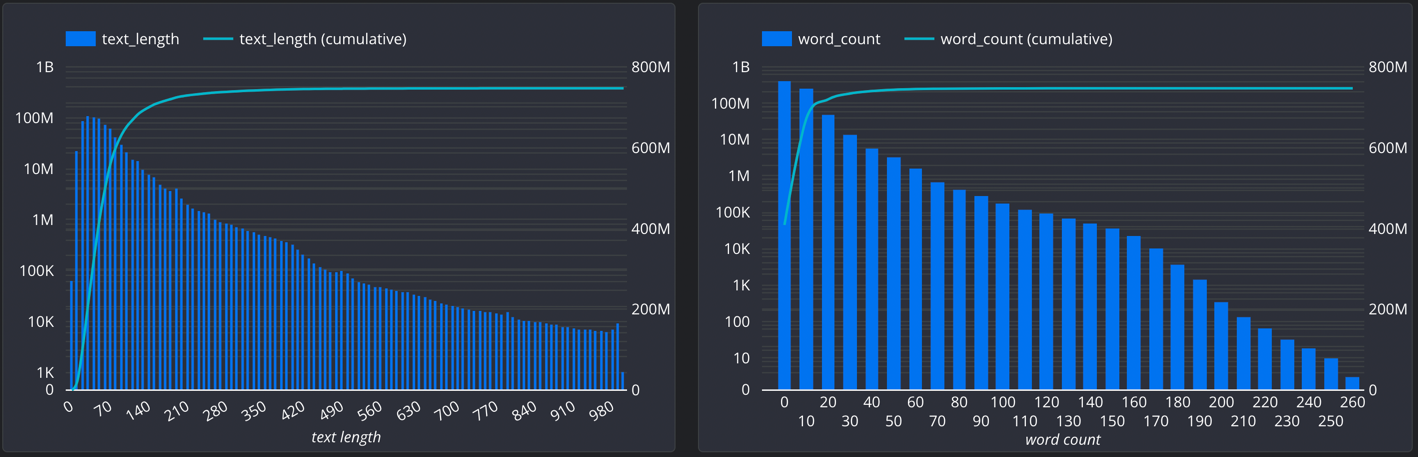
| text_length | integer | The length of the text |
| word_count | integer | The number of words separated by spaces. |
| num_tokens_bert | integer | The number of tokens using BertTokenizer |
| num_tokens_gpt | integer | The number of tokens using GPT2TokenizerFast |
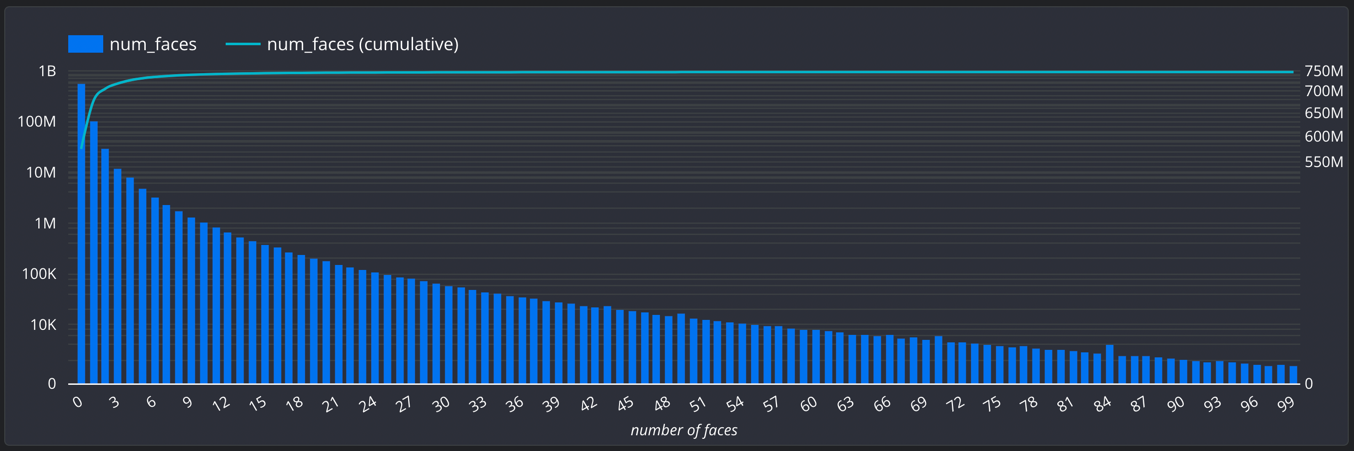
| num_faces | integer | The number of faces in the image detected by SCRFD |
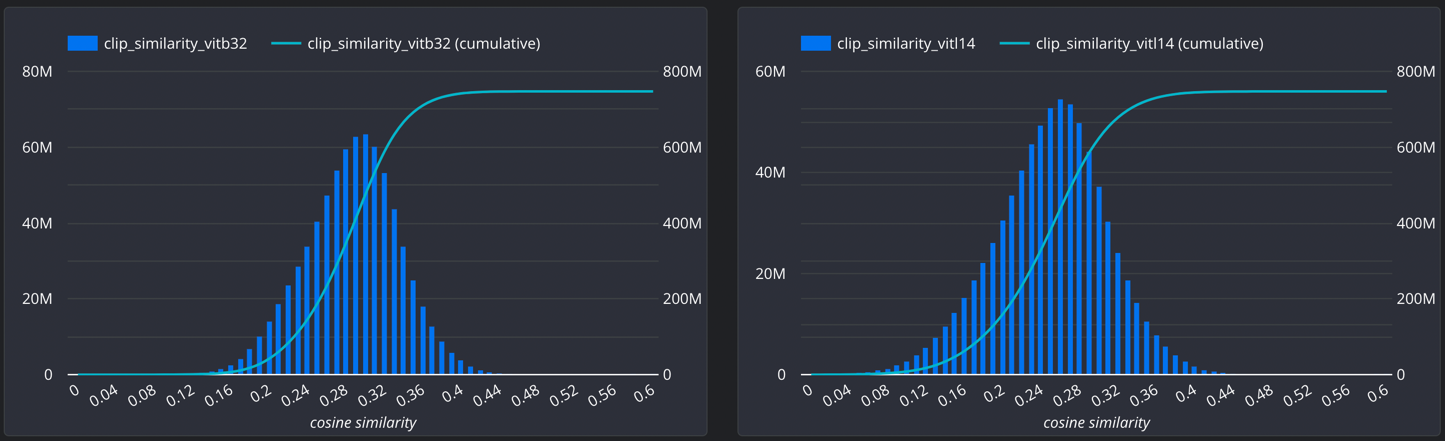
| clip_similarity_vitb32 | float | The cosine similarity between text and image(ViT-B/32) embeddings by OpenAI CLIP |
| clip_similarity_vitl14 | float | The cosine similarity between text and image(ViT-L/14) embeddings by OpenAI CLIP |
| nsfw_score_opennsfw2 | float | The NSFW score of the image by OpenNSFW2 |
| nsfw_score_gantman | float | The NSFW score of the image by GantMan/NSFW |
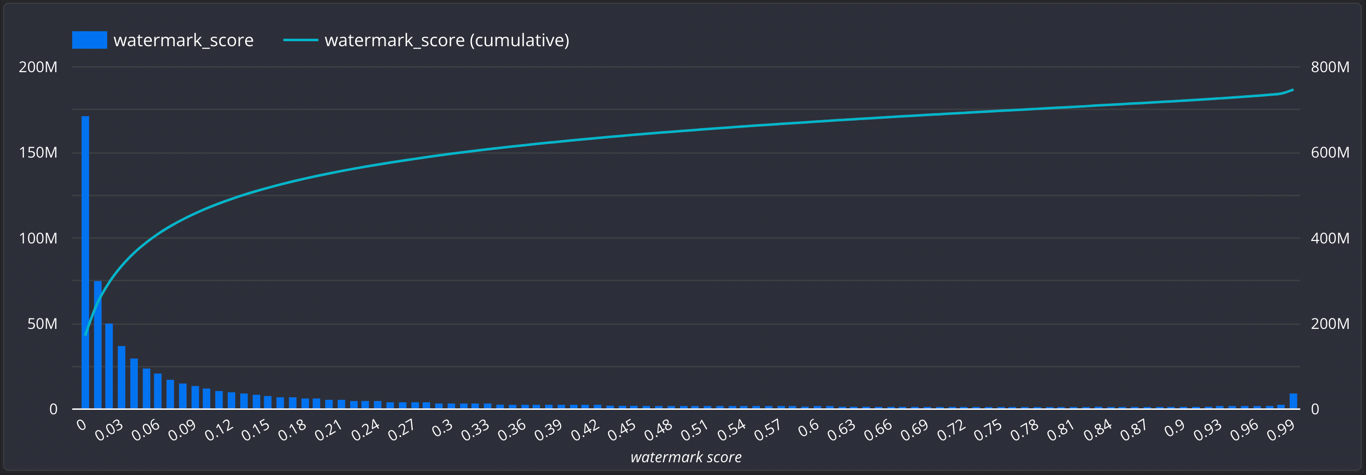
| watermark_score | float | The watermark probability of the image by our internal model |
| aesthetic_score_laion_v2 | float | The aesthetic score of the image by LAION-Aesthetics-Predictor-V2 |
- Statistics for numeric columns
| width | height | text_length | word_count | num_tokens_bert | num_tokens_gpt | num_faces | |
|---|---|---|---|---|---|---|---|
| mean | 621.78 | 540.99 | 68.53 | 11.13 | 15.75 | 17.24 | 0.60 |
| min | 200 | 200 | 6 | 3 | 1 | 3 | 0 |
| max | 21449 | 22507 | 1000 | 323 | 811 | 1523 | 736 |
| watermark_score | clip_similarity_vitb32 | clip_similarity_vitl14 | aesthetic_score_laion_v2 | nsfw_score_opennsfw2 | |
|---|---|---|---|---|---|
| mean | 0.178544 | 0.291266 | 0.254632 | 4.769132 | 0.012903 |
| min | 0.0 | -0.080871 | -0.176269 | 1.171712 | 0.0 |
| max | 1.0 | 0.591796 | 0.581542 | 8.082607 | 0.499755 |
- Image Size
- CLIP Similarity
- Text Length & Word Size
- Watermark score
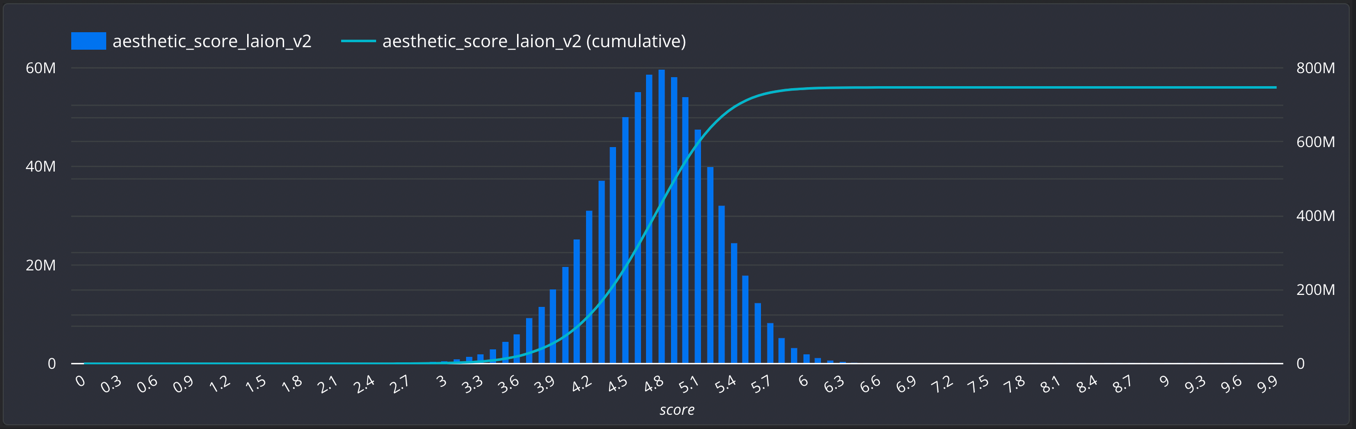
- Aesthetic score
- Number of faces
- For more detailed statistics on COYO-700M, please see the Data Studio report on COYO-700M.






- You can download the dataset from Huggingface Dataset.
- For more information on downloading the image dataset, please refer to download/README.md.
We empirically validated the quality of COYO dataset by re-implementing popular models such as ALIGN, unCLIP, and ViT. We trained these models on COYO-700M or its subsets from scratch, achieving competitive performance to the reported numbers or generated samples in the original papers. Since this observation supports the high quality of our dataset, we hope it to be continuously updated with open collaboration. Our pre-trained models and training codes will be released soon along with the technical report.
| Model | Data | ImageNet KNN | COCO I2T | COCO T2I |
|---|---|---|---|---|
| EfficientNet-B7 + BERT-base | ALIGN-1.8B | 69.300 | 55.400 | 41.700 |
| EfficientNet-B7 + BERT-base | COYO-700M | 68.618 | 59.000 | 42.419 |
- Our experiment setup followed ALIGN.
- We increased the batch size from 16K to 64K and reduced training steps by 1/4 for faster training.
unCLIP (OpenAI DALL·E 2)
 |
 |
|---|---|
| A high quality picture of a medieval knight with golden armor | A person with the head of a cat in the style of Andy Warhol |
 |
 |
|---|---|
| A pencil drawing of an astronaut riding a horse | Goryeo celadon in the shape of darth vader |
- We implemented the smaller version of unCLIP to validate the effectiveness of COYO for the text-conditional generation tasks.
- Specifically, we tried to reproduce three components of the original unCLIP: diffusion-based prior, decoder with some modifications, and super-resolution model for upscaling 64x64 into 256x256px.
- Detailed information on our modified version of unCLIP and quantitative analysis would be included in the upcoming technical report.
| Model | Data | ImageNet Validation Top-1 Acc |
|---|---|---|
| ViT-L/16 | JFT-300M | 87.76% |
| ViT-L/16 | COYO-Labeled-300M | 87.24% |
- We also provide COYO-Labeled-300M by adding machine-generated vision labels to a subset of COYO-700M for comparison with the JFT-300M.
- We first removed the duplicated images by
image_phash. - Then, we labeled 300M unique images into 21,841 classes by EfficientNetV2-XL trained with ImageNet-21K dataset.
- We first removed the duplicated images by
- Our experiment setup followed ViT.
- We also provide vit pre-training, fine-tuning code for reproducibility with weight files.
If you apply this dataset to any project and research, please cite our code:
@misc{kakaobrain2022coyo-700m,
title = {COYO-700M: Image-Text Pair Dataset},
author = {Byeon, Minwoo and Park, Beomhee and Kim, Haecheon and Lee, Sungjun and Baek, Woonhyuk and Kim, Saehoon},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/coyo-dataset}},
}
- Minwoo Byeon (@mwbyeon)
- Beomhee Park (@beomheepark)
- Haecheon Kim (@HaecheonKim)
- Sungjun Lee (@justhungryman)
- Woonhyuk Baek (@wbaek)
- Saehoon Kim (@saehoonkim)
- and Kakao Brain Large-Scale AI Studio
The COYO dataset is recommended to be used for research purposes. Kakao Brain tried to construct a "Safe" dataset when building the COYO dataset. (See Data Filtering Section) Kakao Brain is constantly making efforts to create more "Safe" datasets. However, despite these efforts, this large-scale dataset was not hand-picked by humans to avoid the risk due to its very large size (over 700M). Keep in mind that the unscreened nature of the dataset means that the collected images can lead to strongly discomforting and disturbing content for humans. The COYO dataset may contain some inappropriate data, and any problems resulting from such data are the full responsibility of the user who used it. Therefore, it is strongly recommended that this dataset be used only for research, keeping this in mind when using the dataset, and Kakao Brain does not recommend using this dataset as it is without special processing to clear inappropriate data to create commercial products.
The COYO dataset of Kakao Brain is licensed under CC-BY-4.0 License. The full license can be found in the LICENSE.cc-by-4.0 file. The dataset includes “Image URL” and “Text” collected from various sites by analyzing Common Crawl data, an open data web crawling project. The collected data (images and text) is subject to the license to which each content belongs.
While Open Source may be free to use, that does not mean it is free of obligation. To determine whether your intended use of the COYO dataset is suitable for the CC-BY-4.0 license, please consider the license guide. If you violate the license, you may be subject to legal action such as the prohibition of use or claim for damages depending on the use.
COYO dataset was released as an open source in the hope that it will be helpful to many research institutes and startups for research purposes. We look forward to contacting us from various places who wish to cooperate with us.