Demo 👉️ https://quest.ms.mff.cuni.cz/nlg/tabgenie
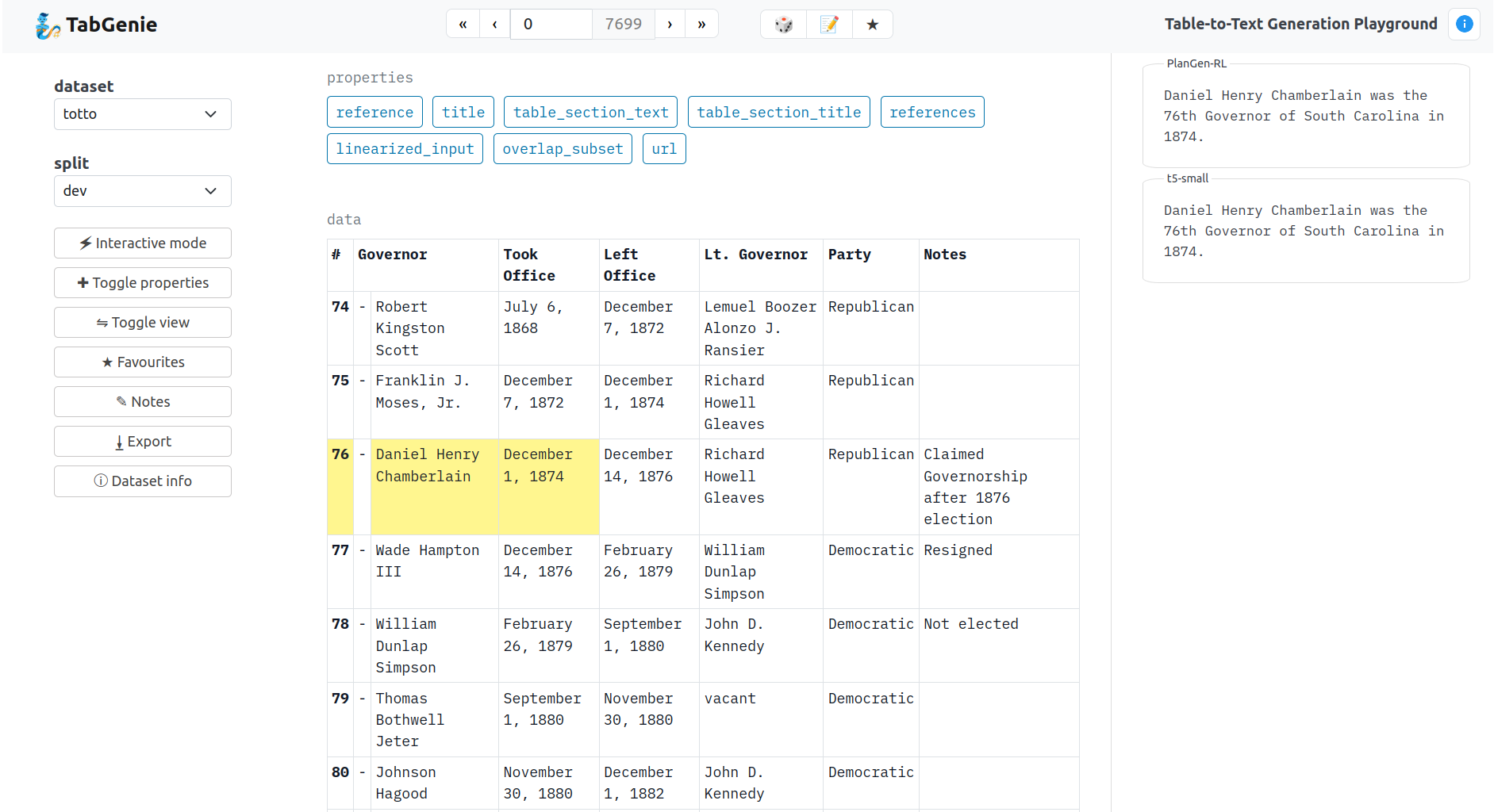
TabGenie provides tools for working with data-to-text generation datasets in a unified tabular format.
TabGenie allows you to:
- explore the content of the datasets
- interact with table-to-text generation models
- load and preprocess the datasets in a unified format
- prepare spreadsheets for error analysis
- export tables to various file formats
TabGenie is equipped with user-friendly web interface, Python bindings and command-line processing tools.
pip install tabgenie
tabgenie run --host=127.0.0.1 --port 8890
xdg-open http://127.0.0.1:8890
Or try the demo at:
👉️ https://quest.ms.mff.cuni.cz/nlg/tabgenie
The datasets are loaded from the HuggingFace datasets.
Input data in each dataset is preprocessed into a tabular format:
- each table contains M rows and N columns,
- cells may span multiple columns or rows,
- cells may be marked as headings (indicated by bold font),
- cells may be highlighted (indicated by yellow background).
Additionally, each example may contain metadata (such as title, url, etc.) which are displayed next to the main table as properties.
| Dataset | Source | Data type | # train | # dev | # test | License |
|---|---|---|---|---|---|---|
| CACAPO | van der Lee et al. (2020) | Key-value | 15,290 | 1,831 | 3,028 | CC BY |
| DART | Nan et al. (2021) | Graph | 62,659 | 2,768 | 5,097 | MIT |
| E2E | Dušek et al. (2019) | Key-value | 33,525 | 1,484 | 1,847 | CC BY-SA |
| EventNarrative | Colas et al. (2021) | Graph | 179,544 | 22,442 | 22,442 | CC BY |
| HiTab | Cheng et al. (2021) | Table | 7,417 | 1,671 | 1,584 | C-UDA |
| Chart-to-text | Kantharaj et al. (2022) | Chart | 24,368 | 5,221 | 5,222 | GNU GPL |
| Logic2Text | Chen et al. (2020b) | Table + Logic | 8,566 | 1,095 | 1,092 | MIT |
| LogicNLG | Chen et al. (2020a) | Table | 28,450 | 4,260 | 4,305 | MIT |
| NumericNLG | Suadaa et al. (2021) | Table | 1,084 | 136 | 135 | CC BY-SA |
| SciGen | Moosavi et al. (2021) | Table | 13,607 | 3,452 | 492 | CC BY-NC-SA |
| SportSett:Basketball | Thomson et al. (2020) | Table | 3,690 | 1,230 | 1,230 | MIT |
| ToTTo | Parikh et al. (2020) | Table | 121,153 | 7,700 | 7,700 | CC BY-SA |
| WebNLG | Ferreira et al. (2020) | Graph | 35,425 | 1,666 | 1,778 | CC BY-NC |
| WikiBio | Lebret et al. (2016) | Key-value | 582,659 | 72,831 | 72,831 | CC BY-SA |
| WikiSQL | Zhong et al. (2017) | Table + SQL | 56,355 | 8,421 | 15,878 | BSD |
| WikiTableText | Bao et al. (2018) | Key-value | 10,000 | 1,318 | 2,000 | CC BY |
See loaders/data.py for an up-to-date list of available datasets.
- Python 3
- Flask
- HuggingFace datasets
See setup.py for the full list of requirements.
- pip:
pip install tabgenie - development:
pip install -e .[dev] - deployment:
pip install -e .[deploy]
- local development:
tabgenie [app parameters] run [--port=PORT] [--host=HOSTNAME] - deployment:
gunicorn "tabgenie.cli:create_app([app parameters])"
Exports individual tables to file.
Usage:
tabgenie export \
--dataset DATASET_NAME \
--split SPLIT \
--out_dir OUT_DIR \
--export_format EXPORT_FORMAT
Supported formats: json, csv, xlsx, html, txt.
Generates a spreadsheet with system outputs and randomly selected examples for manual error analysis.
Usage:
tabgenie sheet \
--dataset DATASET \
--split SPLIT \
--in_file IN_FILE \
--out_file OUT_FILE \
--count EXAMPLE_COUNT
Displays information about the dataset in YAML format (or the list of available datasets if no argument is provided).
Usage:
tabgenie info [-d DATASET]
TabGenie can preprocess the datasets without dataset-specific preprocessing methods.
See the examples directory for a tutorial on using TabGenie for finetuning sequence-to-sequence models.
The datasets are stored to HF_DATASETS_CACHE directory which defaults to ~/.cache/huggingface/.
Set the HF_DATASETS_CACHE environment variable before launching tabgenie if you want to store the (potentially very large) datasets in a different directory.
The datasets are all loaded from HuggingFace datasets instead of their original repositories which allows to use preprocessed datasets and a single unified loader.
Note that preparing the datasets for the first time may take some time since the datasets have to be downloaded to cache and preprocessed. This process takes several minutes based on the dataset size. However, it only a one-time process (until the dataset is updated or the cache is deleted).
Also note that there may be some minor changes in the data w.r.t. to the original datasets due to unification, such as adding "subject", "predicate" and "object" headings to RDF triple-to-text datasets.
For adding a new dataset:
- prepare the dataset
- add the dataset to Huggingface Datasets
- OR download the dataset locally
- create the dataset loader in
loaders- a subclass of
HFTabularDatasetfor HF datasets - a subclass of
TabularDatasetfor local datasets
- a subclass of
- create a mapping between the dataset name and the class name in
loaders/__init__.py - add the dataset name to
tabgenie/config.yml.
Each dataset should contain the prepare_table(entry) method which instantiates a Table object from the original entry.
The Table object is automatically exported to HTML and other formats (the methods may be overridden).
If a dataset is an instance of HFTabularDataset (i.e. is loaded from Huggingface Datasets), it should contain a self.hf_id attribute. The attribute is used to automatically load the dataset via datasets package.
Pipelines are used for processing the tables and producing outputs.
See processing/processing.py for an up-to-date list of available pipelines.
Currently integrated:
- model_api - a pipeline which generates a textual description of a table by calling a table-to-text generation model through API,
- graph - a pipeline which creates a knowledge graph by extracting RDF triples from a table and visualizes the output using D3.js library,
For adding a new pipeline:
- create a file in
processing/pipelinescontaining the pipeline class, - create file(s) in
processing/processorswith processors needed for the pipeline, - add the mapping between pipeline name and class name to
get_pipeline_class_by_name()inprocessing/processing.py.
Each pipeline should define self.processors in the __init__() method, instantiating the processors needed for the pipeline.
The input to each pipeline is a content object containing several fields needed for table processing. This interface may be subject to change (see __init.py_:run_pipeline() for more details).
The processors serve as modules, i.e. existing processors can be combined to create new pipelines. The interface between the processors may vary, it is however expected that the last processor in the pipeline outputs HTML code which is displayed on the page.
This is an example pipeline configuration in tabgenie/config.yml:
rdf_triples:
pipeline: graph
interactive: true
datasets:
- webnlg
- dart
- e2e
The key rdf_triples is the name of the pipeline which will be displayed in the web interface. It should contain only letters of English alphabet, underscores _ or dashes -.
Required arguments:
pipeline:str- the name of the pipeline as defined inprocessing/processing.py, will be mapped to pipeline classinteractive:bool- whether the pipeline will be displayed in the interactive mode in the web interface
Optional arguments:
datasets:list- the list of datasets for which the pipeline will be active in the web interface (all datasets by default)- any other argument, will be passed to the pipeline in
pipeline_args
The global configuration is stored in the tabgenie/config.yml file.
datasets- datasets which will be available in the web interface,default_dataset- the dataset which is loaded by default,host_prefix- subdirectory on which the app is deployed (used for loading static files and sending POST requests),cache_dev_splits- whether to preload all available dev sets after startup,generated_outputs_dir- directory from which the generated outputs are loaded,pipelines- pipelines which will be available in the web interface (see the Interactive mode section for more info).
For citing our work, please use the following:
@inproceedings{kasner-etal-2023-tabgenie,
title = "{T}ab{G}enie: A Toolkit for Table-to-Text Generation",
author = "Kasner, Zden{\v{e}}k and
Garanina, Ekaterina and
Platek, Ondrej and
Dusek, Ondrej",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations)",
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-demo.42",
pages = "444--455",
}
- Link for the paper: https://aclanthology.org/2023.acl-demo.42/