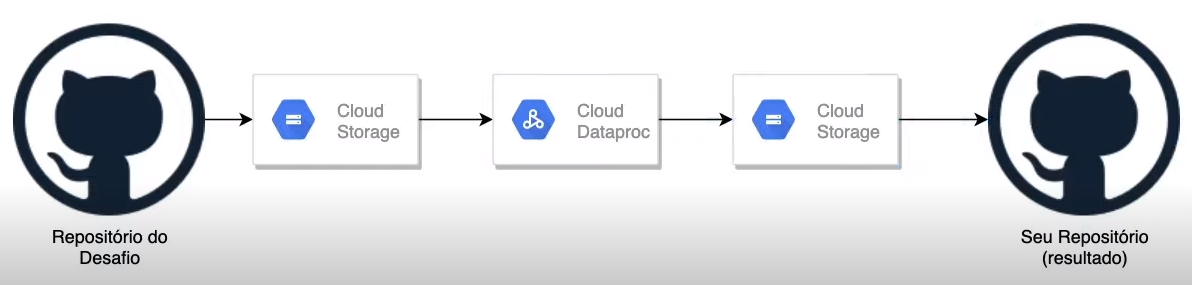
Este é um repositorio que armazena os resultados de um desafio da Digital Innovation One (DIO) em que consistiu na criação de um cluster de Hadoop no DataProc da Google Cloud e na execução de um workload de teste dentro deste cluster.
O projeto teve as seguintes etapas:
- Inicializar uma VM mediante Compute Engine API.
- Ativar o serviço de Cloud Dataproc e criar o cluster mediante SDK.
- Subir os arquivos dentro do
assetsao bucket criado para o Dataproc. - Iniciar um job no cluster que irá gerar um arquivo chamado
part-00000, que é produto de contar as palavras dentro dolivro.txt. Além disso, separar as 10 palavras mais usadas em um arquivo chamadoresultado.txt.
Repositório template: https://github.com/marcelomarques05/dio-desafio-dataproc