It's a minimal setup for a cloud agnostic Data Lakehouse Architecture based on Apache Spark & Apache Hive + Postgres DB as Spark Metastore, MinIO as Storage Layer, Delta Lake as Storage Format, Apache Kyuubi as Serverless Spark SQL Gateway. This is to be used as a sandbox for running trying things on Spark or purely for didactic purposes.
The architecture of our Lakehouse sandbox is designed to replicate the essential components of a real-world Data Lakehouse, while being flexible and cloud-agnostic.

The main architectural elements and their corresponding technologies are as follows:
- Storage: We use MinIO, a high-performance, Kubernetes-native object storage solution. It's ideal for cloud-agnostic architectures due to its scalability and compatibility with Amazon S3 APIs, which will allow Spark & Hive to interact with it through Hadoop AWS.
- Data Format: Delta Lake, an open-source storage layer, provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing.
- Data Processing Engine: Apache Spark, a unified analytics engine, is used for large-scale data processing. It provides comprehensive APIs for efficient data handling and analysis.
- Data Catalog: Spark Catalog, integrated within Apache Spark, manages metadata of data and computations, facilitating data discovery and management.
- Metastore: Apache Hive, backed by PostgreSQL, serves as the Spark Metastore. It stores metadata for Spark SQL and enables more complex data operations and optimizations.
- SQL Gateway: Apache Kyuubi acts as a SQL gateway, enabling external applications to interact with the Spark Catalog through JDBC/ODBC interfaces.
| Image | Version |
|---|---|
| minio | RELEASE.2024-01-13T07-53-03Z |
| minio/mc | RELEASE.2024-01-13T08-44-48Z |
| postgres | 10-alpine |
| apache/hive | 3.1.3 |
| bitnami/spark | 3.4.2 |
| apache/kyuubi | 1.8.0-spark |
| Dependencies | MinIO | Hive | Spark | Kyuubi |
|---|---|---|---|---|
| Hadoop Common | - | 3.1.0 | 3.3.6 | 3.3.6 |
| Hadoop AWS | - | 3.1.0 | 3.3.6 | 3.3.6 |
| AWS SDK Bundle | - | 1.11.271 | 1.12.367 | 1.12.367 |
| Delta Lake | - | - | delta-core_2.12:2.4.0 | delta-core_2.12:2.4.0 |
| Apache Spark | - | - | 3.4.1 | 3.4.1 |
- Create folder hadoop-libs in the project root
- Download AWS Java SDK Bundle 1.11.271 and Hadoop AWS 3.1.0
- Place jars in hadoop-libs folder
Use Docker Compose:
docker compose upUse Docker Compose:
docker compose down -vThere is a sample python app that reads a CSV file from MinIO and creates a Delta Lake from it.
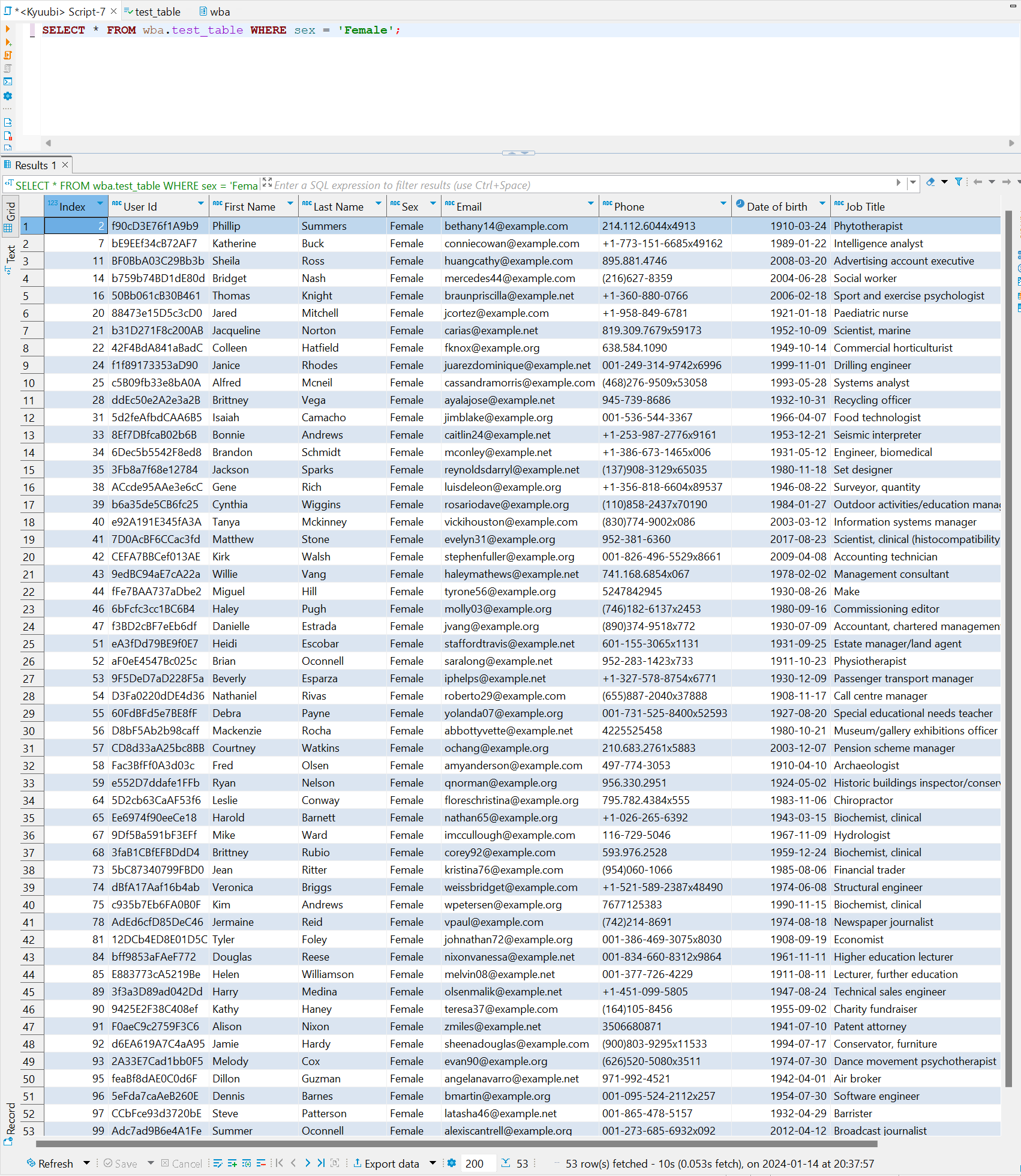
- Access MinIO UI and login
login: accesskeypassword: secretkey.
- Under
wbabucket createtest-datapath
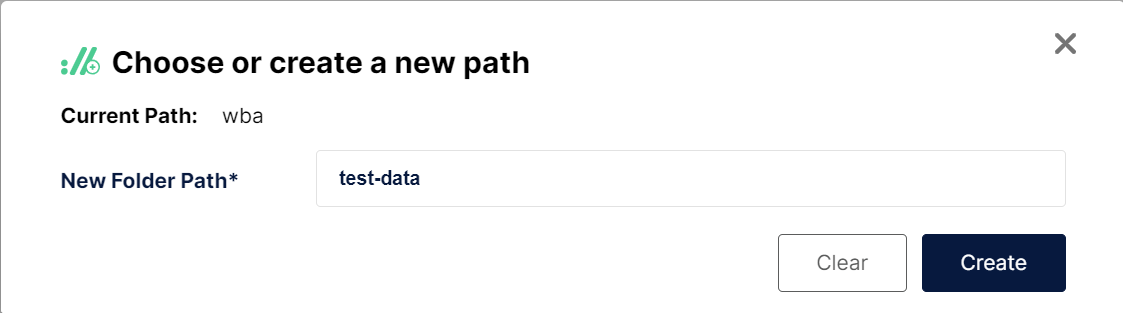
- Upload
./test-data/people-100.csvto new path




docker compose exec spark-master bash
spark-submit /opt/spark-apps/csv_to_delta.py- Setup an Apache Kyuubi connection
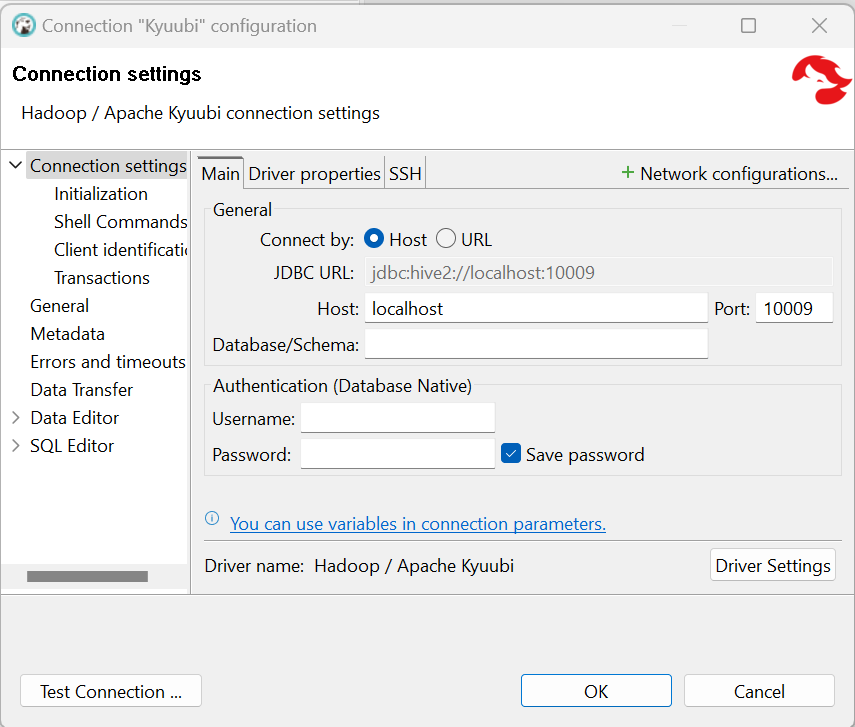
- Initial connection after sandbox started can take 1-3 min on average
- We can see the
wbadb created from Spark app and thetest_tablein Delta format, along with it's metadata.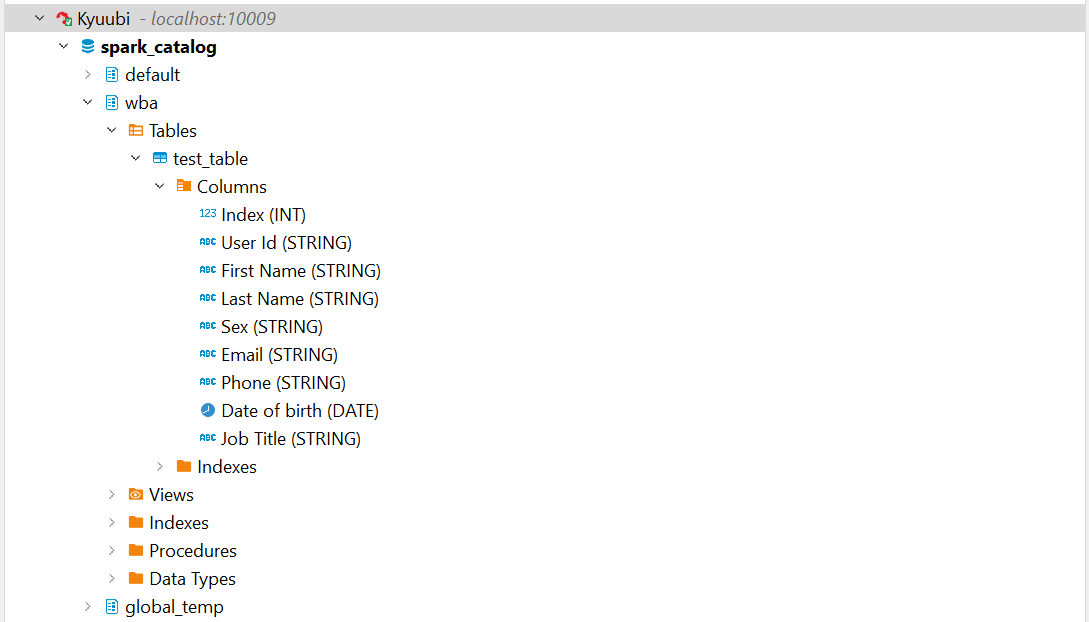
- We could also issue SQL statements directly from DBeaver