


Argilla is an open-source platform for data-centric LLM development. Integrates human and model feedback loops for continuous LLM refinement and oversight.
With Argilla's Python SDK and adaptable UI, you can create human and model-in-the-loop workflows for:
- Supervised fine-tuning
- Preference tuning (RLHF, DPO, RLAIF, and more)
- Small, specialized NLP models
- Scalable evaluation.
There are different options to get started:
-
Take a look at our quickstart page 🚀
-
Start contributing by looking at our contributor guidelines 🤝
-
Skip some steps with our cheatsheet 🎼
This cheatsheet is a quick reference to the most common commands and workflows. For more detailed information, please refer to our documentation.
Deploy on Hugging Face Hub
HuggingFace Spaces now have persistent storage and this is supported from Argilla 1.11.0 onwards, but you will need to manually activate it via the HuggingFace Spaces settings. Otherwise, unless you're on a paid space upgrade, after 48 hours of inactivity the space will be shut off and you will lose all the data. To avoid losing data, we highly recommend using the persistent storage layer offered by HuggingFace.
After this, we can connect to our server.
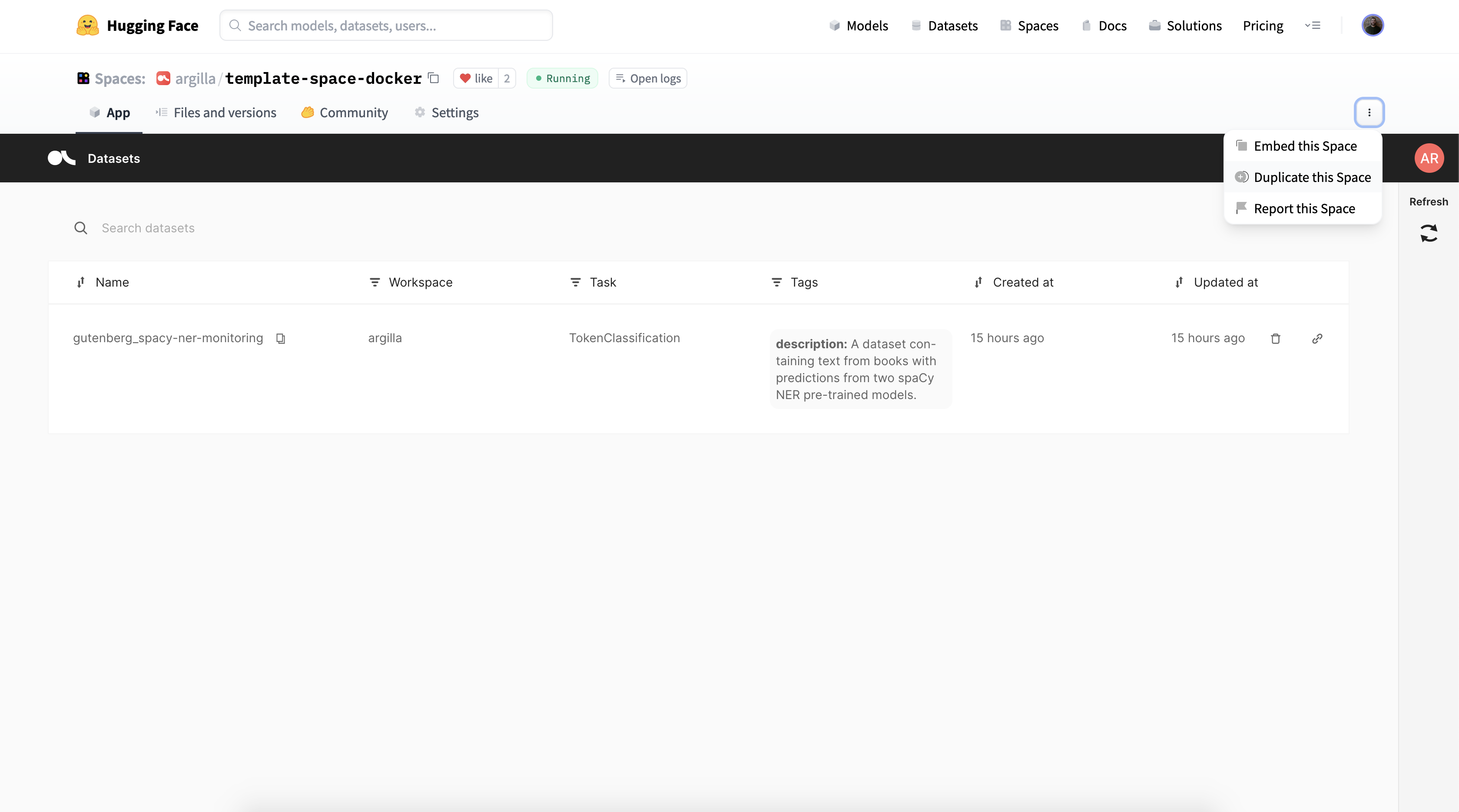
Connect to the Server
Once you have deployed Argilla, we will connect to the server.
import argilla as rg
rg.init(
api_url="argilla-api-url", # e.g. http://localhost:6900 or https://[your-owner-name]-[your_space_name].hf.space
api_key="argilla-api-key" # e.g. "owner.apikey"
workspace="argilla-workspace" # e.g. "admin"
)After this, you can start using Argilla, so you can create a dataset and add records to it. We use the FeedbackDataset as an example, but you can use any of the other datasets available in Argilla. You can find more information about the different datasets here.
Configure datasets
import argilla as rg
dataset = rg.FeedbackDataset(
guidelines="Please, read the question carefully and try to answer it as accurately as possible.",
fields=[
rg.TextField(name="question"),
rg.TextField(name="answer"),
],
questions=[
rg.RatingQuestion(
name="answer_quality",
description="How would you rate the quality of the answer?",
values=[1, 2, 3, 4, 5],
),
rg.TextQuestion(
name="answer_correction",
description="If you think the answer is not accurate, please, correct it.",
required=False,
),
]
)
remote_dataset = dataset.push_to_argilla(name="my-dataset", workspace="my-workspace")
Add records
import argilla as rg
record = rg.FeedbackRecord(
fields={
"question": "Why can camels survive long without water?",
"answer": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time."
},
metadata={"source": "encyclopedia"},
external_id='rec_1'
)
remote_dataset.add_records(record)And that's it, you now have your first dataset ready. You can begin annotating it or embark on other related tasks.
Query datasets
import argilla as rg
filtered_dataset = dataset.filter_by(response_status="submitted")
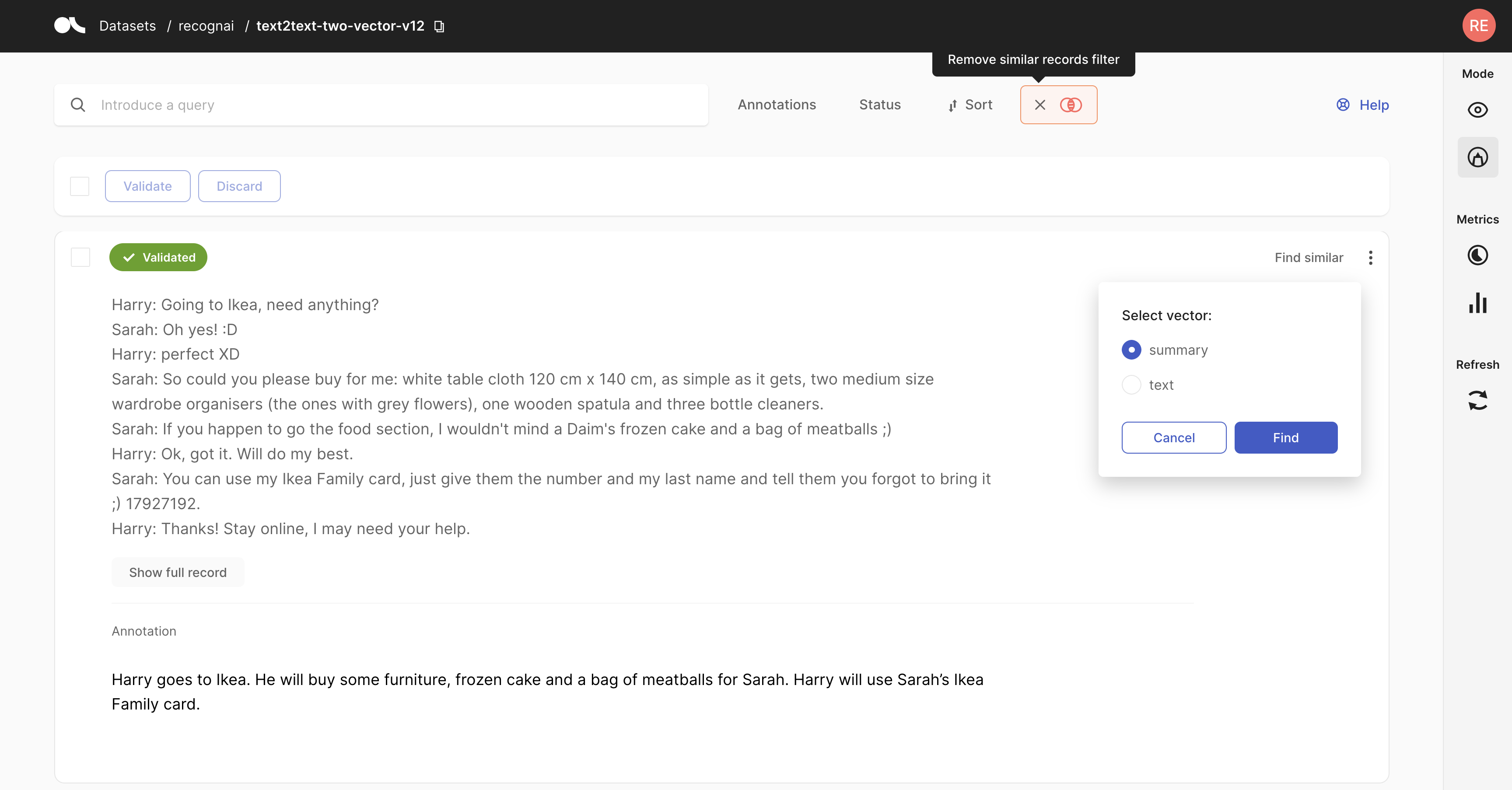
Semantic search
import argilla as rg
# using text embeddings
similar_records = ds.find_similar_records(
vector_name="my_vector",
value=embedder_model.embeddings("My text is here")
# value=embedder_model.embeddings("My text is here").tolist() # for numpy arrays
)
# using another record
similar_records = ds.find_similar_records(
vector_name="my_vector",
record=ds.records[0],
max_results=5
)
Weak supervision
from argilla.labeling.text_classification import add_rules, Rule
rule = Rule(query="positive impact", label="optimism")
add_rules(dataset="go_emotion", rules=[rule])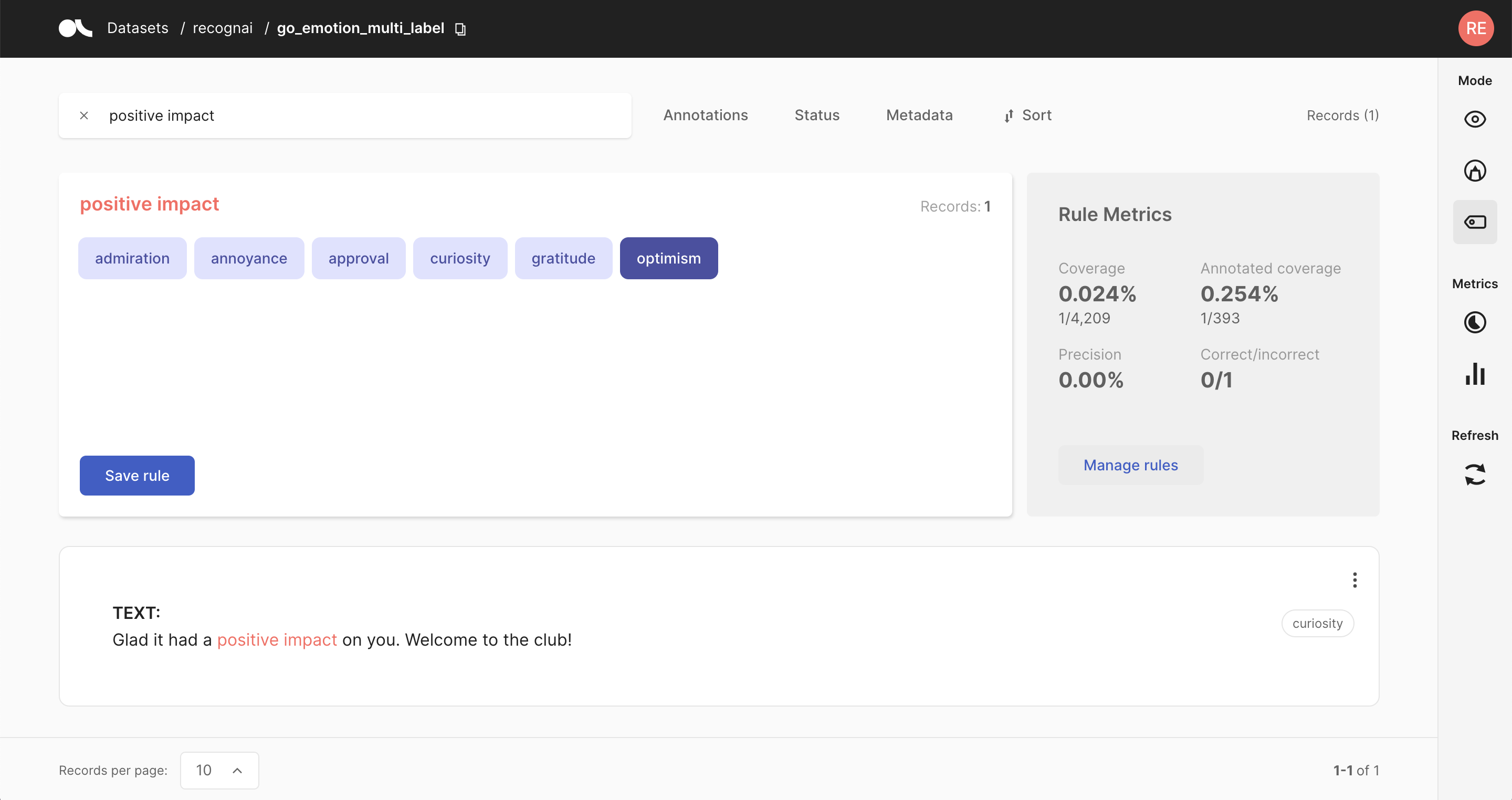
Train models
from argilla.training import ArgillaTrainer
trainer = ArgillaTrainer(
name="my_dataset",
workspace="my_workspace",
framework="my_framework",
model="my_framework_model",
train_size=0.8,
seed=42,
limit=10,
query="my-query"
)
trainer.update_config() # see usage below
trainer.train()
records = trainer.predict(["my-text"], as_argilla_records=True)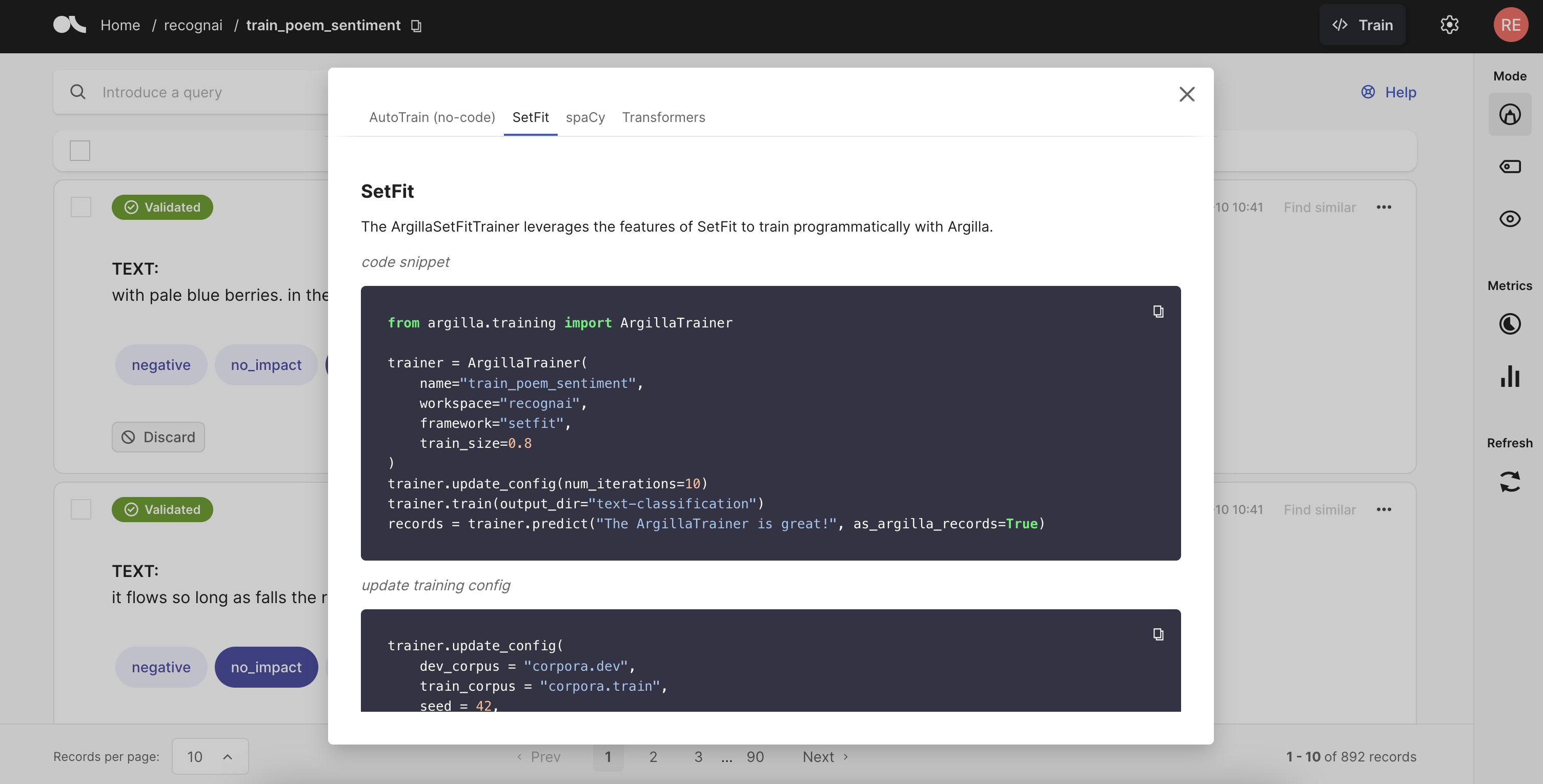
Argilla is built on 5 core components:
Python SDK
A Python SDK which is installable with pip install argilla. To interact with the Argilla Server and the Argilla UI. It provides an API to manage the data, configuration and annotation workflows.
FastAPI Server
The core of Argilla is a Python FastAPI server that manages the data, by pre-processing it and storing it in the vector database. Also, it stores application information in the relational database. It provides a REST API to interact with the data from the Python SDK and the Argilla UI. It also provides a web interface to visualize the data.
Relational Database
A relational database to store the metadata of the records and the annotations. SQLite is used as the default built-in option and is deployed separately with the Argilla Server but a separate PostgreSQL can be used too.
Vector Database
A vector database to store the records data and perform scalable vector similarity searches and basic document searches. We currently support ElasticSearch and AWS OpenSearch and they can be deployed as separate Docker images.
Vue.js UI
A web application to visualize and annotate your data, users and teams. It is built with Vue.js and is directly deployed alongside the Argilla Server within our Argilla Docker image.
Argilla is a tool that is in continuous development, with the aim of always offering better workflows and methods for various NLP tasks. To achieve this, it is based on several principles that define its functionality and scope.
Open
Argilla is free, open-source, and 100% compatible with major NLP libraries (Hugging Face transformers, spaCy, Stanford Stanza, Flair, etc.). In fact, you can use and combine your preferred libraries without implementing any specific interface.
End-to-end
Most annotation tools treat data collection as a one-off activity at the beginning of each project. In real-world projects, data collection is a key activity of the iterative process of ML model development. Once a model goes into production, you want to monitor and analyze its predictions and collect more data to improve your model over time. Argilla is designed to close this gap, enabling you to iterate as much as you need.
User and Developer Experience
The key to sustainable NLP solutions are to make it easier for everyone to contribute to projects. Domain experts should feel comfortable interpreting and annotating data. Data scientists should feel free to experiment and iterate. Engineers should feel in control of data pipelines. Argilla optimizes the experience for these core users to make your teams more productive.
Beyond hand-labeling
Classical hand-labeling workflows are costly and inefficient, but having humans in the loop is essential. Easily combine hand-labeling with active learning, bulk-labeling, zero-shot models, and weak supervision in novel data annotation workflows.
Below, you can find answers to some of the most common questions about Argilla. For more information, refer to our documentation.
What is Argilla?
Argilla is an open-source data curation platform, designed to enhance the development of both small and large language models (LLMs). Using Argilla, everyone can build robust language models through faster data curation using both human and machine feedback. We provide support for each step in the MLOps cycle, from data labeling to model monitoring. In fact, the inspiration behind the name "Argilla" comes from the word for "clay", in Latin, Italian and even in Catalan. And just as clay has been a fundamental medium for human creativity and tool-making throughout history, we view data as the essential material for sculpting and refining models.
Does Argilla train models?
Argilla does not train models but offers tools and integrations to help you do so. With Argilla, you can easily load data and train models straightforward using a feature we call the ArgillaTrainer. The ArgillaTrainer acts as a bridge to various popular NLP libraries. It simplifies the training process by offering an easy-to-understand interface for many NLP tasks using default pre-set settings without the need of converting data from Argilla's format. You can find more information about training models with Argilla here.
What is the difference between old datasets and the FeedbackDataset?
The FeedbackDataset stands out for its versatility and adaptability, designed to support a wider range of NLP tasks including those centered on large language models. In contrast, older datasets, while more feature-rich in specific areas, are tailored to singular NLP tasks. However, in Argilla 2.0, the intention is to phase out the older datasets in favor of the FeedbackDataset. For a more detailed explanation, please refer to this guide.
Can Argilla only be used for LLMs?
No, Argilla is a versatile tool suitable for a wide range of NLP tasks. However, we emphasize the integration with small and large language models (LLMs), reflecting confidence in the significant role that they will play in the future of NLP. In this page, you can find a list of supported tasks.
Does Argilla provide annotation workforces?
Currently, we already have partnerships with annotation providers that ensure ethical practices and secure work environments. Feel free to schedule a meeting here or contact us via email.
Does Argilla cost money?
No, Argilla is an open-source platform. And we plan to keep Argilla free forever. However, we do offer a commercial version of Argilla called Argilla Cloud.
What is the difference between Argilla open source and Argilla Cloud?
Argilla Cloud is the counterpart to our open-source platform, offering a Software as a Service (SaaS) model, and doesn't add extra features beyond what is available in the open-source version. The main difference is its cloud-hosting, which caters especially to large teams requiring features that aren't typically necessary for individual practitioners or small businesses. So, Argilla Cloud is a SAS plus virtual private cloud deployment, with added features specifically related to the cloud. For those interested in the different plans available under Argilla Cloud, you can find detailed information on our website.
How does Argilla differ from competitors like Snorkel, Prodigy and Scale?
Argilla distinguishes itself for its focus on specific use cases and human-in-the-loop approaches. While it does offer programmatic features, Argilla's core value lies in actively involving human experts in the tool-building process, setting it apart from other competitors.
Furthermore, Argilla places particular emphasis on smooth integration with other tools in the community, particularly within the realms of MLOps and NLP. So, its compatibility with popular frameworks like SpaCy and Hugging Face makes it exceptionally user-friendly and accessible.
Finally, platforms like Snorkel, Prodigy or Scale, while more comprehensive, often require a significant commitment. Argilla, on the other hand, works more as a component within the MLOps ecosystem, allowing users to begin with specific use cases and then scale up as needed. This flexibility is particularly beneficial for users and customers who prefer to start small and expand their applications over time, as opposed to committing to an all-encompassing platform from the outset.
What is Argilla currently working on?
We are continuously working on improving Argilla's features and usability, focusing now concentrating on a three-pronged vision: the development of Argilla Core (open-source), Distilabel, and Argilla JS/TS. You can find a list of our current projects here.
We love contributors and have launched a collaboration with JustDiggit to hand out our very own bunds and help the re-greening of sub-Saharan Africa. To help our community with the creation of contributions, we have created our developer and contributor docs. Additionally, you can always schedule a meeting with our Developer Advocacy team so they can get you up to speed.
🏘️ Attend our online bi-weekly community meetup.
🙋♀️ Join the Argilla community on Slack and get direct support from the community.
⭐ Argilla Github repo to stay updated about new releases and tutorials.
🎁 We've just printed stickers! Would you like some? Order stickers for free.
We continuously work on updating our plans and our roadmap and we love to discuss those with our community. Feel encouraged to participate.