Github-SurpassHR/Youtube_SignatureCipher_Decryptor
Youtube上的视频抛开内容质量不谈画质确实可以说是顶级的,但下载却是存在一些不便,虽说通过下载利器IDM可以实现流媒体的嗅探下载,但IDM总是要从IE获取或手动设置代理服务器,其过程类似于抓包,实时监控着网络流量。我就琢磨有没有一种可以直接获取ytb直连的方法,所以我打算写一个小程序验证我的想法。
这篇文章大概会分为三个部分讲述这个小程序建立的过程,想到哪写到哪,比诺兰的电影时间线还乱
首先打开一个ytb视频播放页面,检查一下页面内容,因为是动态加载的页面我们不奢求直接在页面中找到真实链接,果不其然
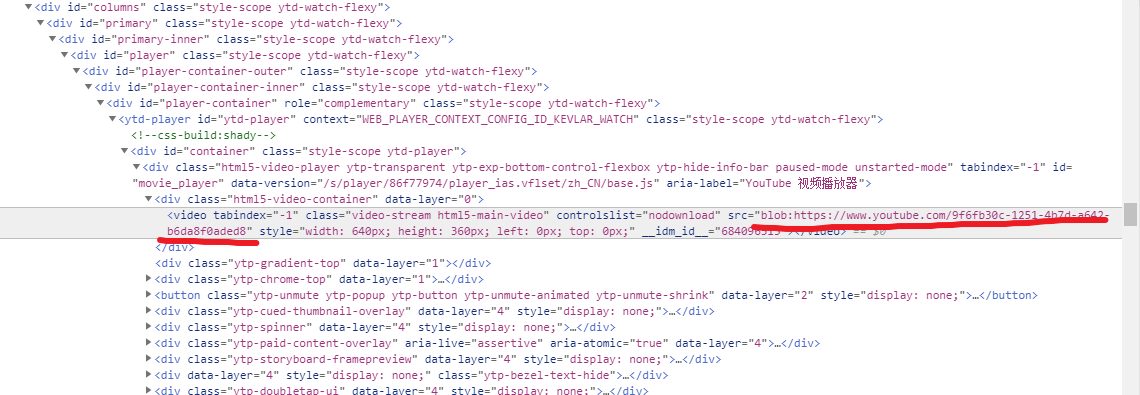
这blob:https看起来很像一种协议,经过一番百度发现:blob:https并不是一种协议,而是html5中blob对象在赋给video标签后生成的一串标记,blob对象对象包含的数据,浏览器内部会解析。**果然,在网页原文
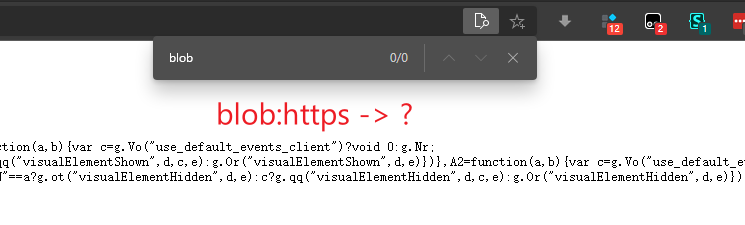
没有再能找到blob,说明blob通过调用某个js的某种方法将其变成了另一个链接,所以接下来有两种选择,一是冲着这个js方法使劲,二是凭感觉来找,根据我的经验在一个动态页面找一个隐藏在js中的视频链接不会太难,毕竟也就那几十条,而且一些通用的关键词playinfo、player-api等等都可以快速地检索到目标所在的标签,而与此同时使用base加密的js格式化后大概有5、6万行,但其实还有三,那就是直接抓包,但那样不就等于开挂了吗?我在写这篇总结时已经把成品做出来了,所以这一次我打算正面硬刚加密的js
我们猜想,当js处理完一个链接后会1.通过getElementsByxxx()的方法找到标签将原链接放回去,2.通过setAttribute()设置src属性内容等方法还原标签视频链接,因为能作为标签的选择器的只有class属性了,所以我兴致冲冲地在base.js中找到了与class中属性值相关的方法以及相关的调用,但万万没想到

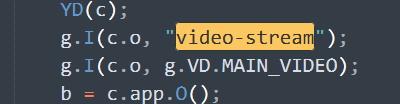
1.他阻止了视频流这个事件的传播

2.他把src属性给删了
不过好消息是我们可以发现出现频率很高的一个词ytp
再说他的链接,他应该还有一种选择就是把打包好的json信息,我们想要的视频链接也在json中,作为视频内容传给h5播放器,但既然是内容的传递那么这个方法八成不在加密算法文件base.js中,经过元素审查关键词ytp、player很容易找到了ytplayer这个js变量,youtube player起名字相当随便(第一次找链接就是这样找到的),无论是审查元素还是网络都能很好地验证
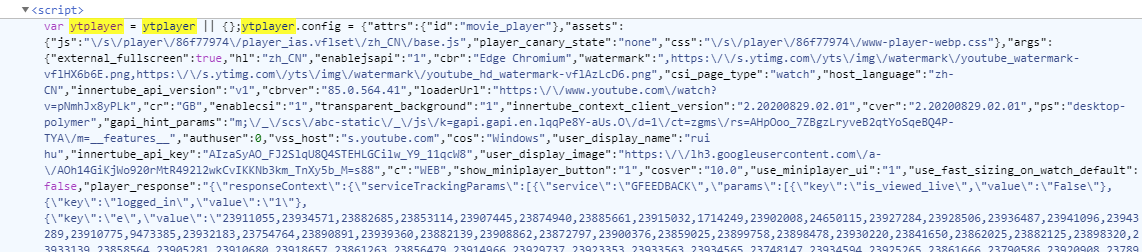
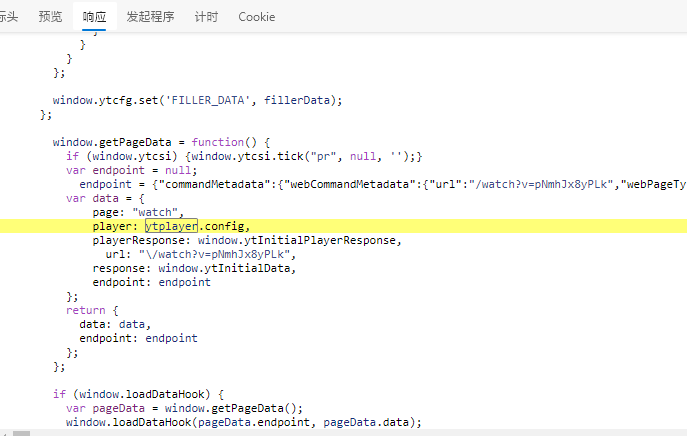
通过ytplayer.config这个属性储存了视频信息,其中包含了
ytplayer.config = {
"args": {
"innertube_api_version": "v1",
// ---------------重点保护----------------
"player_response": "...",
// --------------------------------------
"cbr": "Chrome",
"c": "WEB",
"csi_page_type": "watch",
"external_fullscreen": true,
"use_fast_sizing_on_watch_default": false,
"ps": "desktop-polymer",
"enablecsi": "1",
"host_language": "en",
"cr": "GB",
"cos": "Windows",
"enablejsapi": "1",
"watermark": ",https://s.ytimg.com/yts/img/watermark/youtube_watermark-vflHX6b6E.png,https://s.ytimg.com/yts/img/watermark/youtube_hd_watermark-vflAzLcD6.png",
"loaderUrl": "https://www.youtube.com/watch?v=pNmhJx8yPLk",
"cosver": "10.0",
"cbrver": "85.0.4183.76",
"cver": "2.20200829.02.01",
"use_miniplayer_ui": "1",
"vss_host": "s.youtube.com",
"gapi_hint_params": "m;/_/scs/abc-static/_/js/k=gapi.gapi.en.lqqPe8Y-aUs.O/d=1/ct=zgms/rs=AHpOoo_7ZBgzLryveB2qtYoSqeBQ4P-TYA/m=__features__",
"transparent_background": "1",
"innertube_api_key": "AIzaSyAO_FJ2SlqU8Q4STEHLGCilw_Y9_11qcW8",
"show_miniplayer_button": "1",
"hl": "en_US",
"innertube_context_client_version": "2.20200829.02.01"
},
"assets": {
"css": "/s/player/86f77974/www-player-webp.css",
"player_canary_state": "none",
"js": "/s/player/86f77974/player_ias.vflset/en_US/base.js"
},
"attrs": {"id": "movie_player"}
};
其中"player_response"包含各种质量的视频的来源以及信息,如果按照80字符一换行,里面大概有1000多行。其中视频与音频是分离的,从48k到320k,从144p到8k都有明确的提示信息,之后的流程就是多层套娃,player_response外面套ytplayer.config外面套data外面套pageData外面套window.getPageData外面套fillerData外面套setFiller,每套一层就额外增添一些判断条件或者信息,最后打包成为h5播放器可以识别的信息在播放器完成播放,套娃如下
然后再说说开挂的方法——抓包
俗话说:抓包抓好,牢饭吃饱。抓包在web开发中的重要性不言而喻
但我不怎么懂抓包,因为平常只是简单的分析一下就可以解决大部分的流媒体传输问题(b站是个例外,原视频链接没有藏掖,倒是在音视频请求、分段传输上下了很多套)
Fiddler首先配置要代理的浏览器,添加Fiddler的证书之后Fiddler就可以对流量进行分析和抓取
打开配置好的Fiddler后再打开ytb的视频页面,捕获页面中就会刷新出请求过的链接,无论是否响应
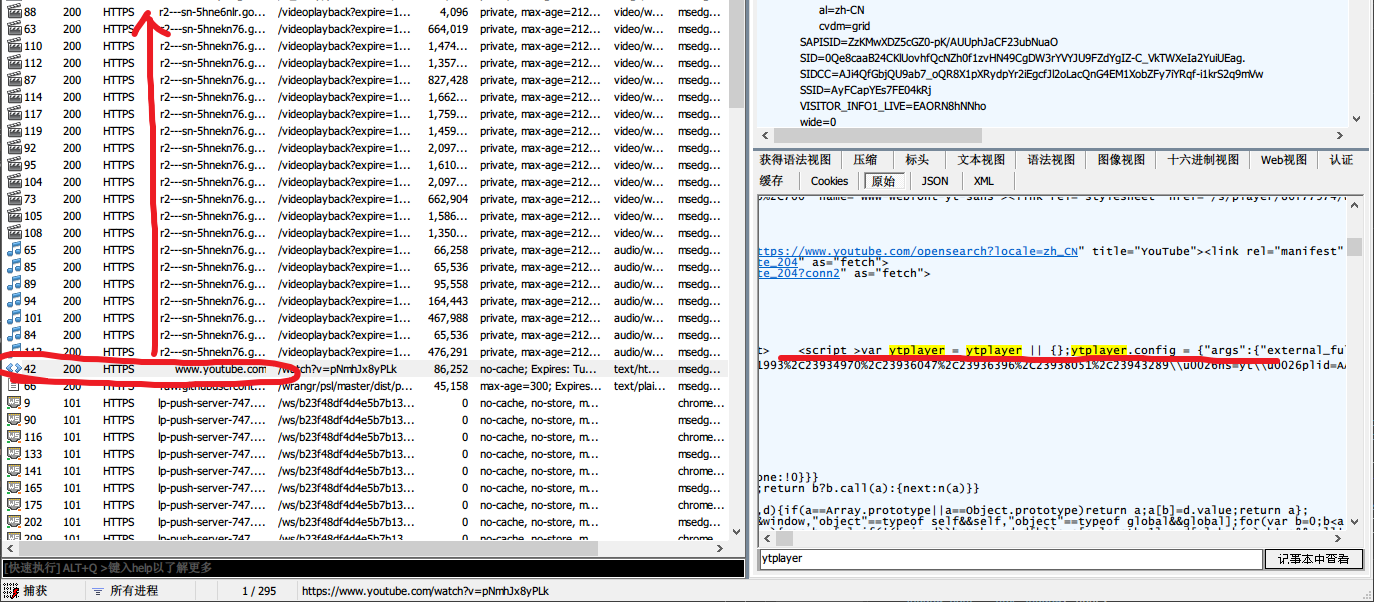
如图,Fiddler已经在图标方面对音视频链接进行了识别分类,突然搞得我前面的工作没有了意义,十分枯燥,同时在这里也可以验证我前面的猜测
不再赘述
总之寻找真实视频链接并没有描述中的难,html这种东西,总是感觉比逻辑要来的快一些,但上面还有没填好的坑,为接下来的程序编写带来了困难,元素审查本就不是走流程的一步,看过的页面做够多,总能找出些规律,总之多摸索
目标已经找出来了,接下来就是爬取了,我的目标是不适用第三方库解析网页来完成网页的解析和链接与信息的提取,首先把原始页面抓下来,把异常捕捉加上免得报红错影响心情
import urllib.request
import time
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.76 Safari/537.36",
"accept-language": "en,zh-CN;q=0.9,zh;q=0.8,ja;q=0.7,ar;q=0.6"
}
res = urllib.request.Request(url=url, headers=headers)
reqtime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
try:
req = urllib.request.urlopen(res, timeout=10)
html = req.read().decode('utf-8')
print('\n请求成功,请求时间是:{}\n'.format(reqtime))
except Exception as e:
print('\n请求失败,请求时间是:{}'.format(reqtime))
print('失败原因:{}请检查网络\n'.format(e))
main()测试通过后使用函数封装,添加文件写入,把当前步骤得到的结果做一个备份,之后的测试就通过读取文件内容来进行,既节省了等待响应的时间,又降低了封ip的风险,想必每个视频页面不会有太大的出入(事后证明出入还是有一点的)
爬到的页面通过utf-8decode之后,<body>部分正常,但<script>部分出现了unicode转义字符,不是出现了,本来就有,给正则式的构建造成了很大的困扰,下面是<script>部分出现的全部
# Unicode转义字符集
replace_dict = {
r'\\\"': r'',
r'\\u0026': r'&',
r'\u0026': r'&',
r'\\"': r"'",
r'\"': r"'",
r'\\': r'',
r'\/': r'/',
r'\u003c': r'<',
r'\u003e': r'>',
}因为ytb页面本身是有中文内容的,所以read()的时候使用utf-8可以避免一些显示上的问题,而像这样以文本形式储存在<script>中,并且多种形式像\\u0026和\u0026并存,我们本可以采取更加优雅一些的方法像json.loads()转换unicode转义字符的同时,将json文件以字典的形式保存于变量,但是它要求严格的json格式文件,最起码不能在IDE中报错,我本打算这样做,但是这样一来截取json格式片段的正则式则会变得臃肿,容错率变低,而且\"转义、\\" 反转义、\\\"反反转义并存json.loads()可能并不能做到完美,好在我们需要的片段是一段很类似媒体属性的json格式信息,不会出现汉字,那么工作量就少了很多,最终需要改动的地方如上所示,使用for循环完成对全文的替换,需要注意的的是字典的顺序很重要
for key in replace_dict:
html = html.replace(key, replace_dict[key])很暴力,但是很保险
urlFormat = re.compile(r'^https://www.youtube.com/watch\?v=.*|www.youtube.com/watch\?v=.*|youtube.com/watch\?v=.*')
mediaTitle = re.compile(r'<meta name="title" content="(.*?)">', re.S)
ytplayerCfg = re.compile(r'<script >var ytplayer.*?</script>', re.S)
streamingData = re.compile(r'"streamingData":{', re.S)
streamingdata1 = re.compile("'streamingData':{(.*)},'playbackTracking'", re.S)
streamingdata0 = re.compile("'streamingData':{(.*)},'playerAds'", re.S)
使用正则式完成从url检测到流媒体信息的提取,其中的一个坑就在键"streamingData",也就是上文所说的那一点出入,有的视频信息后面跟的是"playbackTracking",有的是"playerAds",都是小问题
从原html页面到格式化的json信息经历了
# 请求原页面,timeout=30(s)
def askURL(url):
global html
res = urllib.request.Request(url=url, headers=headers)
reqtime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
try:
req = urllib.request.urlopen(res, timeout=10)
html = req.read().decode('utf-8')
print('\n请求成功,请求时间是:{}\n'.format(reqtime))
except Exception as e:
print('\n请求失败,请求时间是:{}'.format(reqtime))
print('失败原因:{}请检查网络\n'.format(e))
main()
if logOn:
filename = 'oringin_video_page.html'
write(html, filename)
return html
# 替换掉unicode转义字符的页面
def prettify(html):
for item in replace_dict:
html = html.replace(item, replace_dict[item])
title = re.findall(mediaTitle, html)[0]
if logOn:
filename = 'pre_video_page.html'
write(html, filename)
return html, title
# 截取含有ytplayer播放器信息的js脚本
def process2Js(pre_html):
js_file = re.findall(ytplayerCfg, pre_html)[0]
if logOn:
filename = 'video_info_ytplayer_js.html'
write(js_file, filename)
return js_file
# 截取ytplayer中含有的流媒体信息
def process2Json(js_file):
if not re.findall(streamingdata0, js_file):
json_file = '{' + '"streamingData": {' + re.findall(streamingdata1, js_file)[0] + '}' + '}'
else:
json_file = '{' + '"streamingData": {' + re.findall(streamingdata0, js_file)[0] + '}' + '}'
json_file = json_file.replace("'", '"')
if logOn:
filename = 'video_page_json.json'
write(json_file, filename)
return json_file这样几步,为了方便记录我把一步拆成了几步,又把每一步封装,因为在这篇比较调理的代码之前的main.py.old写完我自己都看不懂,所以决定吸取教训
解析过程中用到了一次列表对列表的赋值,list(b) = list(a)将list(a)放入函数操作,打印list(b)发现b也变了,在java的时候就被这拷贝卡了一次,这次没长脑子,又被卡住了,写个循环赋值,或者直接调用copy库的deepcopy
本以为一切都结束了,因为测试了几个视频都可以只用浏览器直连下载,直到我测试了一个正义联盟的片段
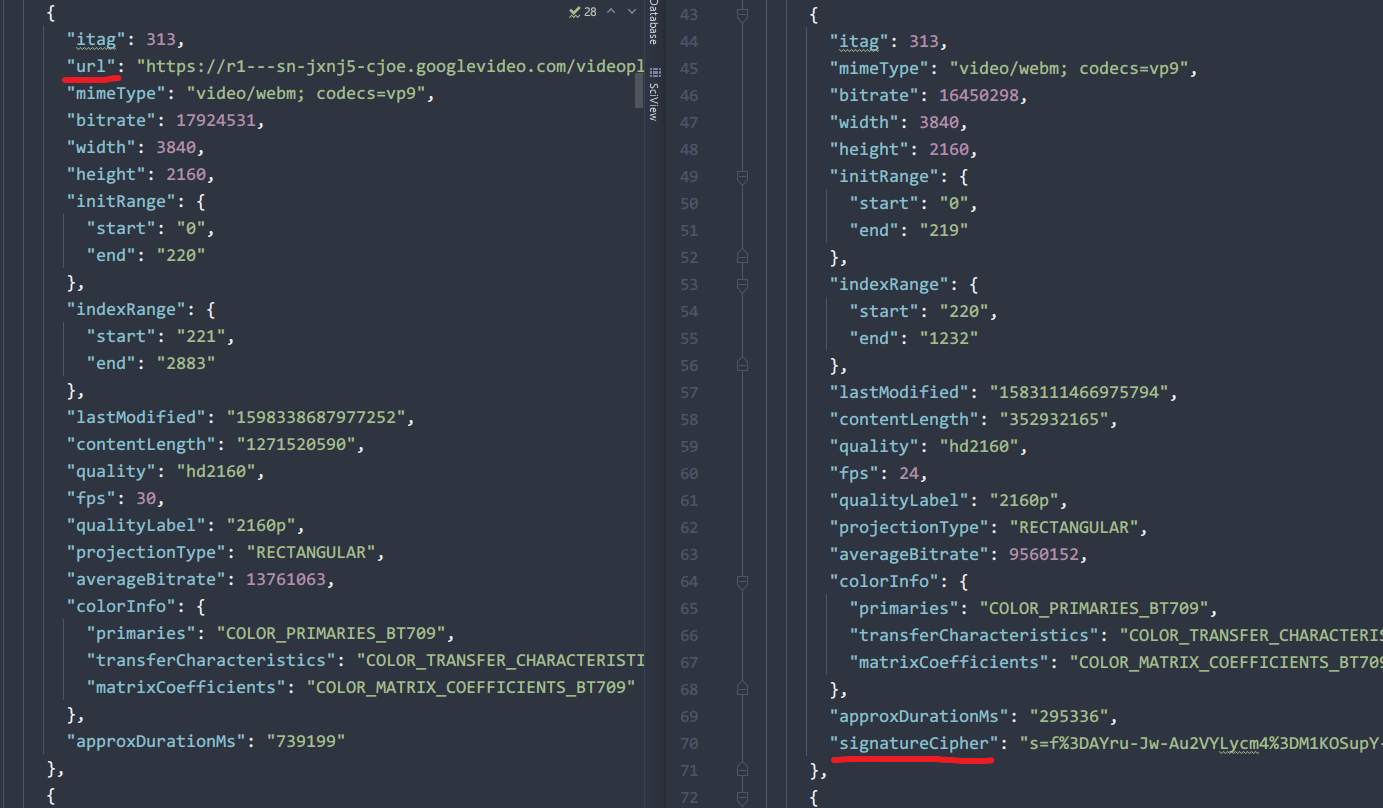
正常视频左,正义联盟右
不愧是正义联盟,正道的光,奥里给!
SignaturCipher中也是含有url的
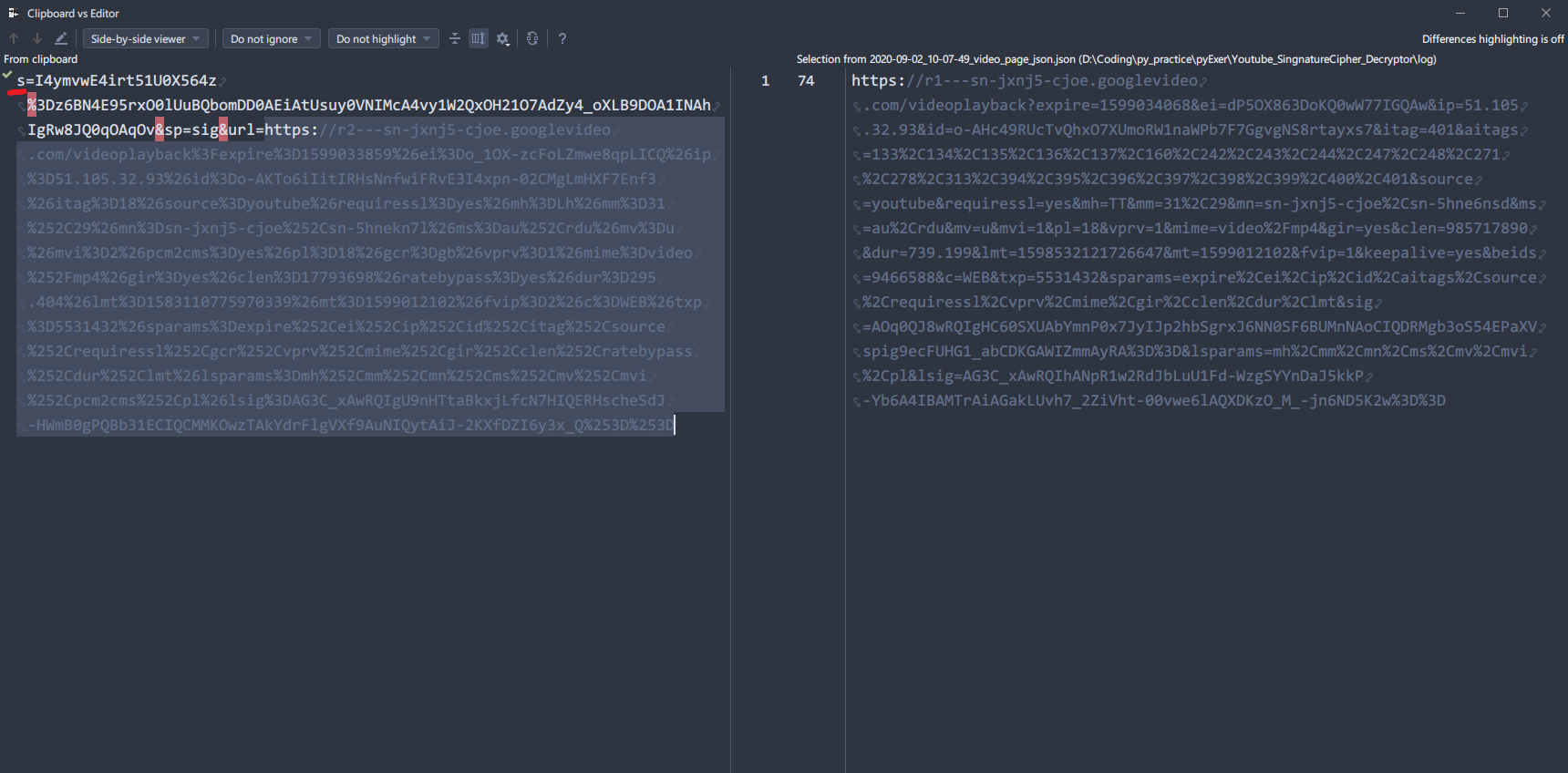
但经过对比可以发现,多了开头的s=...和&sp=sig这两段,而且链接中没有我们想要的&、?等分隔符,浏览器可以将百分号加密(Percentage-encoding也叫URL编码Url Encoding) 正常解析,但我们不行,而且googlevideo对于未解析的sig链接不予响应
这很影响对链接内容的分析,所以再次字典replace,转成我们方便分析的形式
# 百分号加密字符集
decode_dict = {
' ': '%20',
'"': '%22',
'#': '%23',
'%': '%25',
'&': '%26',
'(': '%28',
')': '%29',
'+': '%2B',
',': '%2C',
'/': '%2F',
':': '%3A',
';': '%3B',
'<': '%3C',
'=': '%3D',
'>': '%3E',
'?': '%3F',
'@': '%40',
'\\': '%5C',
'|': '%7C',
}
for value in decode_dict:
url = url.replace(decode_dict[key], key)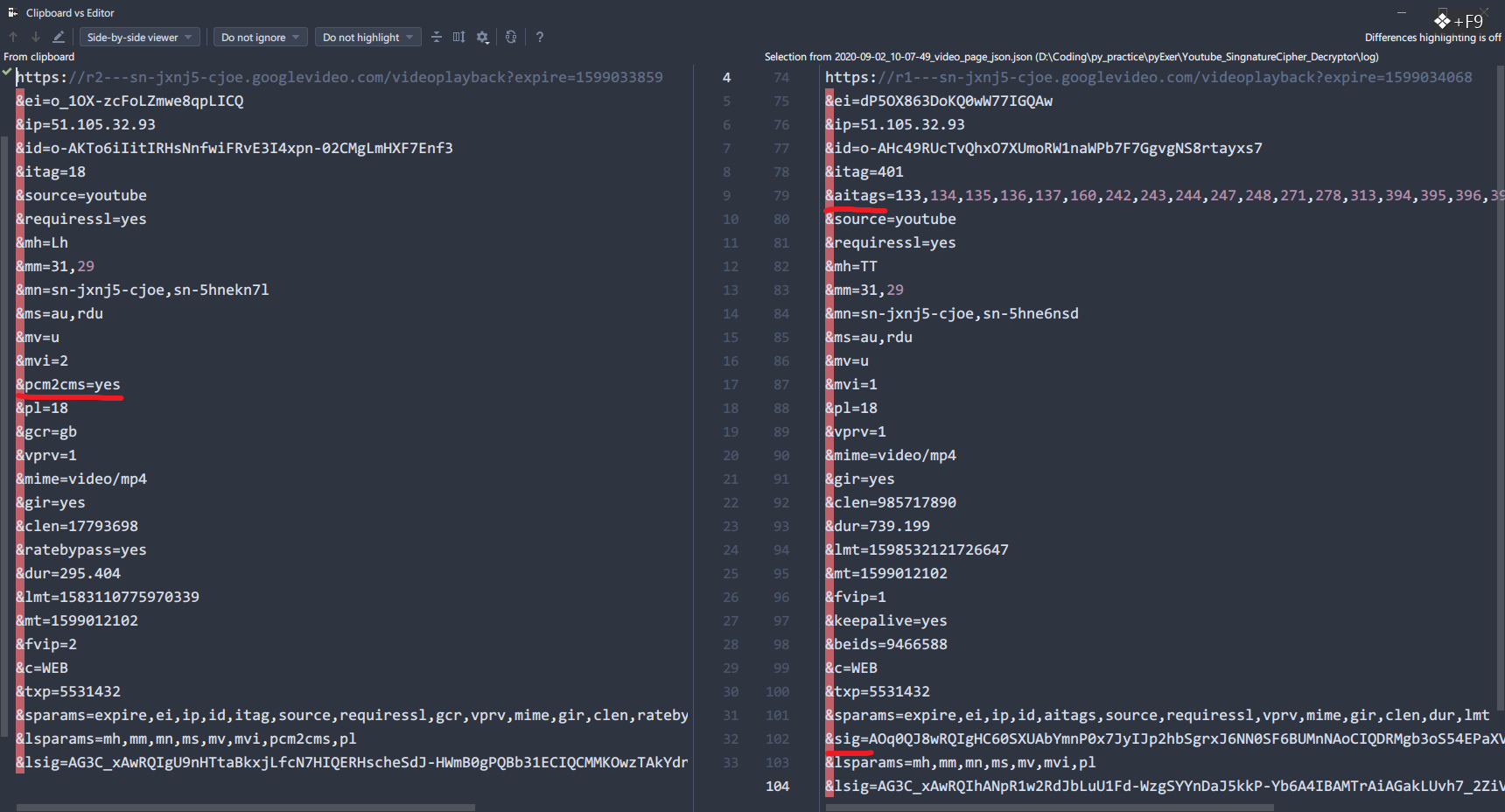
大概就是这样几个地方的不同,此时访问正义联盟的url
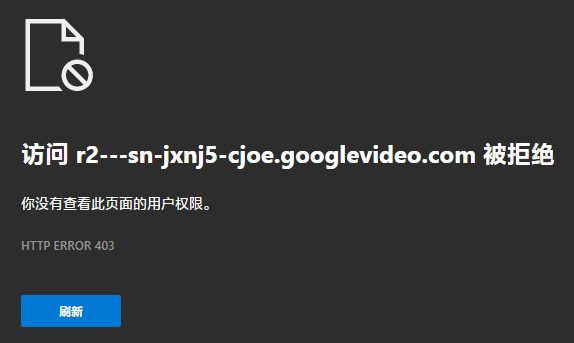
被阻止了,无权访问,但最起码服务器响应了,再根据前面已经写了这段链接是"SignatureCipher"的值,明显我们少的是那段sig也就是签名
我们新建一个sig并加入s=后面的签名信息,尝试访问一下,还是403
说明它被某种方法进行了加密,我对加密的理解就是一段字符串经过增删和置换形成一段新的字符串作为密钥,这放在明面的无论是未加密还是已加密,最后都要变成一段googlevideo服务器可以接受的密钥来获取视频,这个加密的方法几乎可以肯定就在base.js中
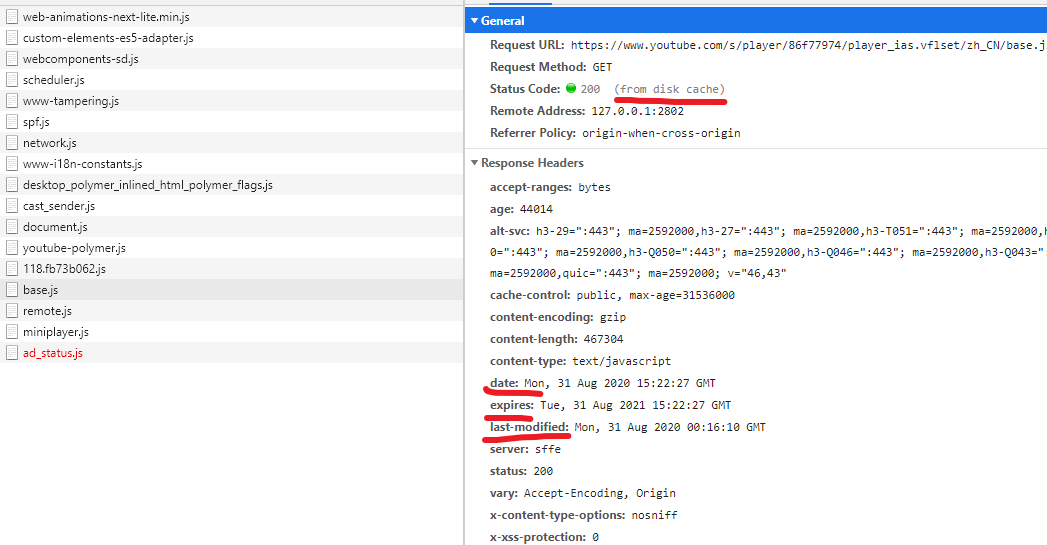
这只程序猿真是勤奋,12点了还在写东西,哦格林尼治时间啊,美国就是晚八点,那没事了,还没享受完福报。
然后我们从硬盘缓存和失效日期可以看出这玩意不是个会经常改变的东西,因为这里面有五万多行2m多,每次加载肯定是个大麻烦,而且cache-control的值是31536000这不就是一年整嘛,而且经过验证,msedge没有清除过缓存与Chrome的base.js修改日期是相同的,精确到秒
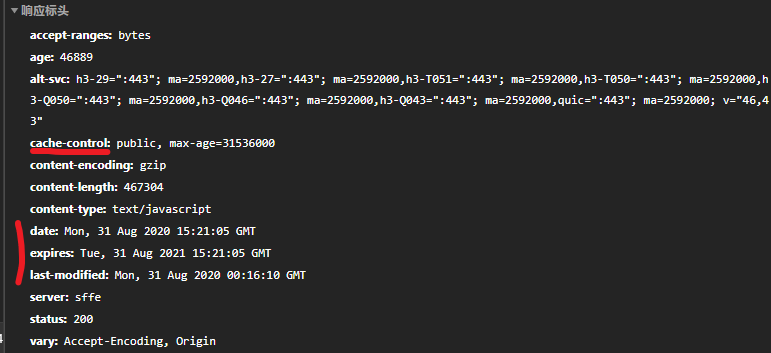
因此每次base.js内容发生变化就是从上传到失效一年整的时间,而我做这个解析的时间是北京时间8月31日十点多,换算成格林尼治时间刚好是8月31日下午两点多,也就是说我弄完睡了个觉起来就失效了wdnmd,这算是第三个坑放在第二个坑里一起埋了,所以写程序不能侥幸心理,只看个例
// 这是更新前的加密js
var Gv = {
HF: function (a) {
a.reverse()
},
A2: function (a, b) {
a.splice(0, b)
},
ch: function (a, b) {
var c = a[0];
a[0] = a[b % a.length];
a[b % a.length] = c
}
};
Hv = function (a) {
a = a.split("");
Gv.A2(a, 1);
Gv.ch(a, 39);
Gv.A2(a, 3);
return a.join("")
};
a = Hv(s);虽然这个base.js一年才需要看一次,但我还是写了段爬虫来抓它,这不是<link>的js文件,所以要在页面中自己拿
import urllib.request
from bs4 import BeautifulSoup
import re
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.76 Safari/537.36",
"accept-language": "en,zh-CN;q=0.9,zh;q=0.8,ja;q=0.7,ar;q=0.6"
}
domain = "https://www.youtube.com"
def askURL(url):
res = urllib.request.Request(url=url, headers=headers)
req = urllib.request.urlopen(res)
html = req.read().decode('utf-8')
return html
def parseHtml(html):
soup = BeautifulSoup(html, 'lxml')
basejs = soup.select('script[name="player_ias/base"]')
return basejs
def findBaseJs(basejs):
backdrop = re.findall('src="(.*?)"', str(basejs))[0]
url = domain + backdrop
jsfile = askURL(url)
return jsfile
def writeFile(jsfile, basepath):
with open(basepath, "w", encoding='utf-8') as f:
f.write(jsfile)
return
def main():
url = 'https://www.youtube.com/watch?v=LXb3EKWsInQ&t=3s'
basepath = 'base.js'
html = askURL(url)
basejs = parseHtml(html)
jsfile = findBaseJs(basejs)
writeFile(jsfile, basepath)
if __name__ == '__main__':
main()好家伙,一格式化我pycharm就裂开了,内存占用直逼6g,cpu100%
下面来分析,如果要对一个字符串进行有规律的增删替换,为了保证准确性,就要把每个字符拆解开来,并明确次序,js中的列表或数组可以满足需求,但字符串到列表或数组要先进行分割,split("")找一下

18个结果,不多,可以挨个看,也可以再加一点要求,得是xx = xx.split("")的

13个,已经很接近了
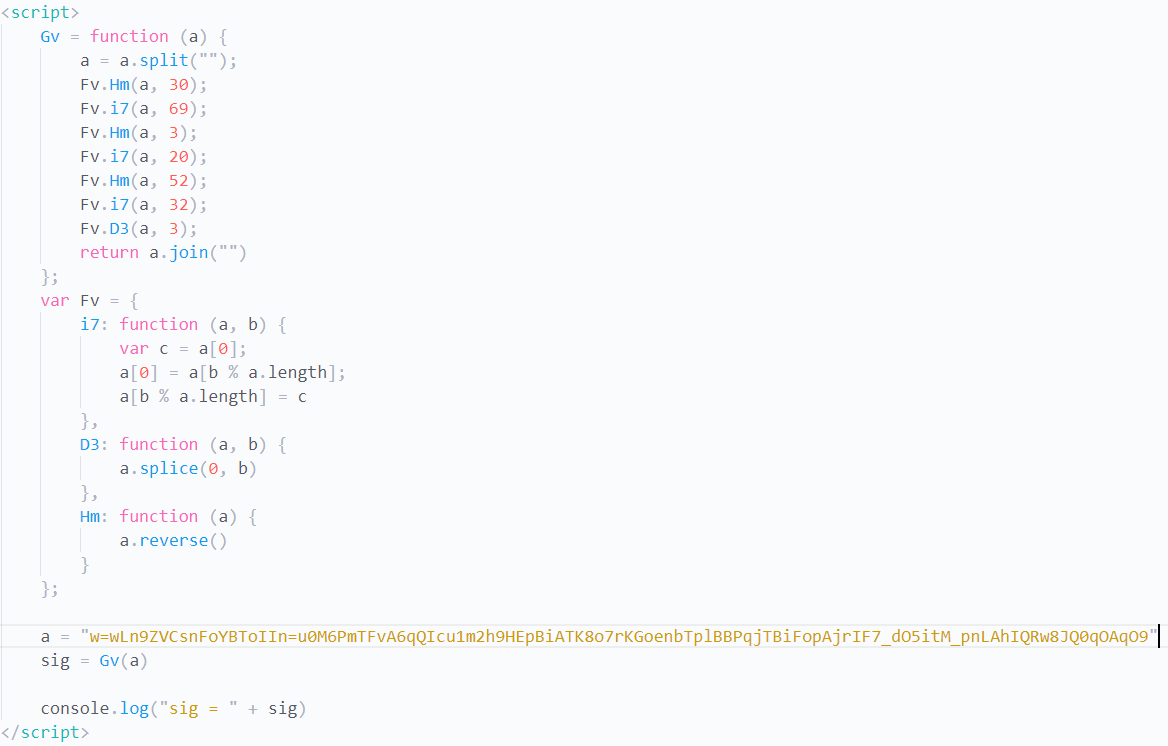
Gv = function (a) {
a = a.split("");
Fv.Hm(a, 30);
Fv.i7(a, 69);
Fv.Hm(a, 3);
Fv.i7(a, 20);
Fv.Hm(a, 52);
Fv.i7(a, 32);
Fv.D3(a, 3);
return a.join("")
};这是最终锁定在它的身上,其实带有一点蒙的成分,因为其他的都太复杂,几百行代码用来调试几十个字母的字符串就离谱
但这个函数中还调用了其他的方法,好在它们都属于同一个类的实例,其格式应该为
var Fv = {Hm、i7、D3方法}
搜索,区分大小写
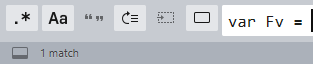
1个匹配,很好,这届的程序猿很给力
var Fv = {
i7: function (a, b) {
var c = a[0];
a[0] = a[b % a.length];
a[b % a.length] = c
},
D3: function (a, b) {
a.splice(0, b)
},
Hm: function (a) {
a.reverse()
}
};没有调用其他的函数
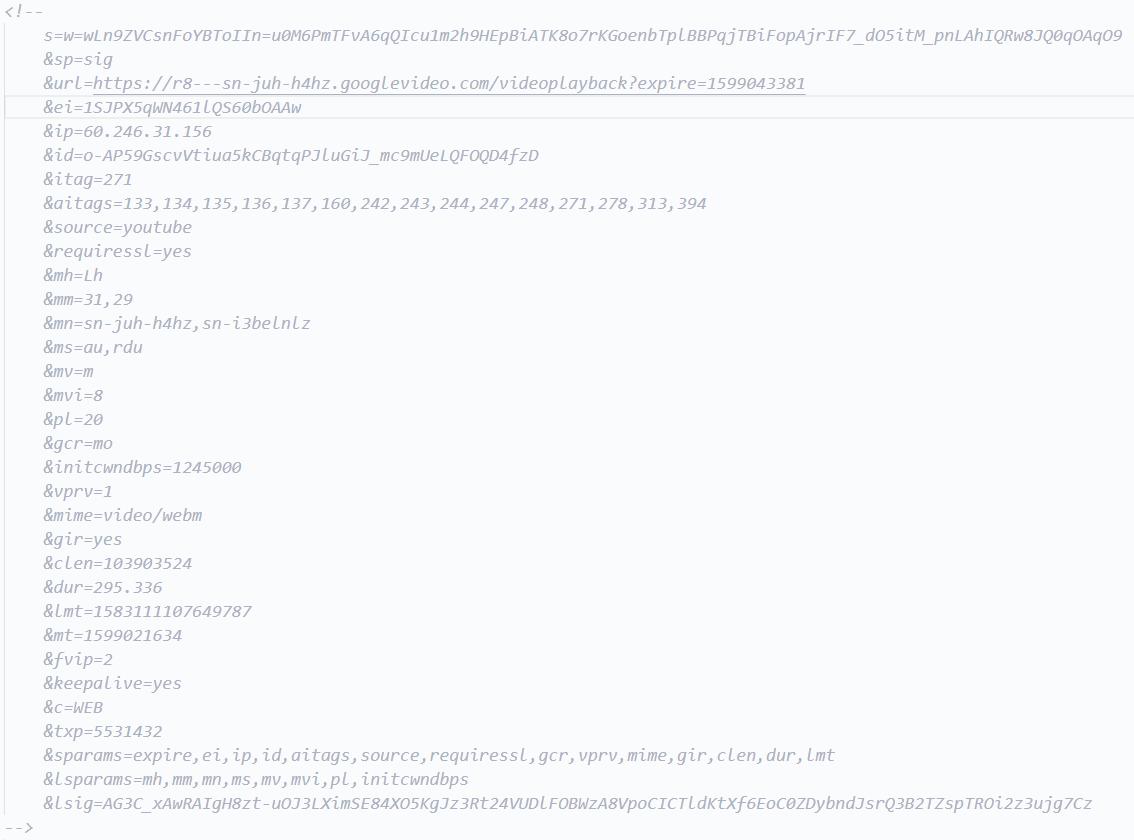
我们把它放到一个html,并测试正义联盟的加密签名,只取s=...到&sp=...之间的部分
在控制台输出一下转换结果
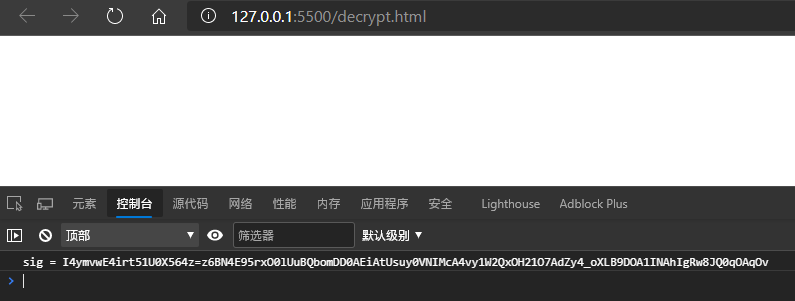
拼起来试试
https://r8---sn-juh-h4hz.googlevideo.com/videoplayback?expire=1599043381&ei=1SJPX5qWN461lQS60bOAAw&ip=60.246.31.156&id=o-AP59GscvVtiua5kCBqtqPJluGiJ_mc9mUeLQFOQD4fzD&itag=271&aitags=133,134,135,136,137,160,242,243,244,247,248,271,278,313,394&source=youtube&requiressl=yes&mh=Lh&mm=31,29&mn=sn-juh-h4hz,sn-i3belnlz&ms=au,rdu&mv=m&mvi=8&pl=20&gcr=mo&initcwndbps=1245000&vprv=1&mime=video/webm&gir=yes&clen=103903524&dur=295.336&lmt=1583111107649787&mt=1599021634&fvip=2&keepalive=yes&c=WEB&txp=5531432&sparams=expire,ei,ip,id,aitags,source,requiressl,gcr,vprv,mime,gir,clen,dur,lmt&lsparams=mh,mm,mn,ms,mv,mvi,pl,initcwndbps&lsig=AG3C_xAwRAIgH8zt-uOJ3LXimSE84XO5KgJz3Rt24VUDlFOBWzA8VpoCICTldKtXf6EoC0ZDybndJsrQ3B2TZspTROi2z3ujg7Cz
&sig=AOq0QJ8wRQIhALnp_Mti5Od_7FIrj1poFiBTjqPBBlpTbneoGKr7o8KTAiBpEH9h2m9ucIQq6AvFTmP6M0uwnIIoTBYoFnsCVZ9nLw==
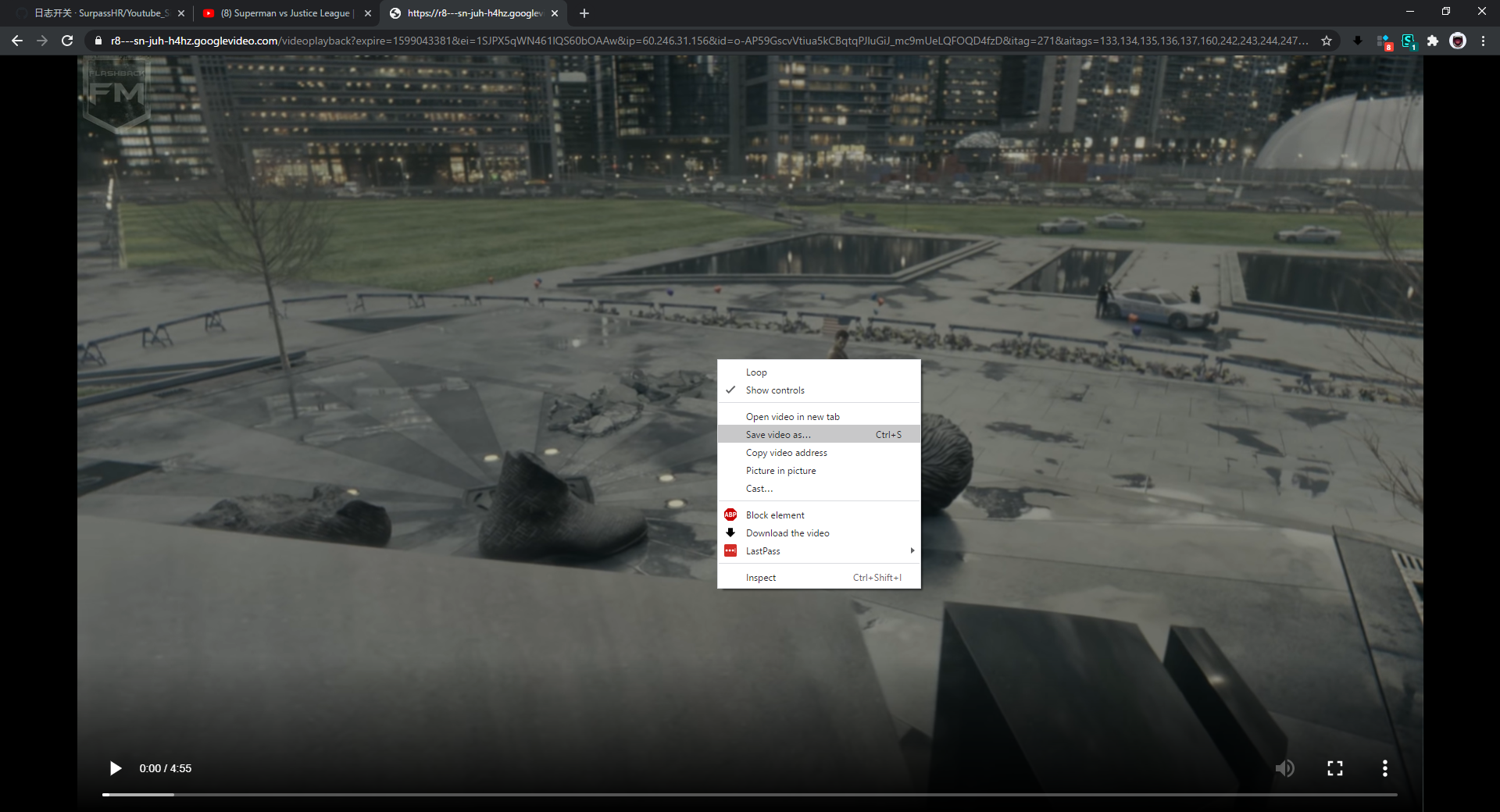
成功了
yysy比分析信息更难的是给变量和函数起名
我们只是用js解出了真实的签名,而python要调用js的函数方法有2:
- 1.借助第三方库pyexecjs,在python调用js函数
- 2.把js代码转写为python代码
第一种方法不在考虑范围内,因为我的目标是不借助第三方库完成主程序,所以只有方法2
而要实现两种语言的人工转换,首先要明确理解不同语言中实现相同作用的函数,或编写间接实现相同作用的自定义函数
先上代码,找出两种语言中作用不同的地方
var Fv = {
i7: function (a, b) {
var c = a[0];
a[0] = a[b % a.length]; //python中为len(a)
a[b % a.length] = c
},
D3: function (a, b) {
a.splice(0, b) //splice(index, howmany, item1,...,itemX)索引位置,个数,新添加,这里只用到了前两个参数,而python就需要自定义函数(可能有一样功能的,我不知道)
},
Hm: function (a) {
a.reverse() //相同
}
};
Gv = function (a) {
a = a.split(""); //python中split()函数不能用空字符(串)来分割,re.split()可以但要去掉首尾空字符
Fv.Hm(a, 30);
Fv.i7(a, 69);
Fv.Hm(a, 3);
Fv.i7(a, 20);
Fv.Hm(a, 52);
Fv.i7(a, 32);
Fv.D3(a, 3);
return a.join("") //python中join()的使用方法是"分割字符(串)".join(列表/元组)
};分析完毕,整理成python
decode_dict = {
' ': '%20',
'"': '%22',
'#': '%23',
'%': '%25',
'&': '%26',
'(': '%28',
')': '%29',
'+': '%2B',
',': '%2C',
'/': '%2F',
':': '%3A',
';': '%3B',
'<': '%3C',
'=': '%3D',
'>': '%3E',
'?': '%3F',
'@': '%40',
'\\': '%5C',
'|': '%7C',
}
# 百分号解码
def seperatorOff(a):
print('converting url...')
for key in decode_dict:
a = a.replace(decode_dict[key], key)
return a
# 自定义函数splice()
def splice(list, index, num):
for i in range(num):
list[index + i] = ''
while '' in list:
list.remove('')
return list
# ---------js函数原型-----------
class Fv:
def i7(a:list, b):
c = a[0]
a[0] = a[b % len(a)]
a[b % len(a)] = c
def D3(a:list, b):
splice(a, 0, b)
def Hm(a:list, num:int):
a.reverse()
def Gv(s):
a = []
for item in s:
a.append(item)
Fv.Hm(a, 30)
Fv.i7(a, 69)
Fv.Hm(a, 3)
Fv.i7(a, 20)
Fv.Hm(a, 52)
Fv.i7(a, 32)
Fv.D3(a, 3)
return ''.join(a)
# ----------js函数原型--------------
def decode(s):
return Gv(s)
if __name__ == '__main__':
sigcipher = ""
sigcipher = seperatorOff(sigcipher)
s = ""
s = decode(s)打个包作为自定义第三方库在main中引入
import os
def call(DownUrl, DownPath, FileName):
"""
:param DownUrl: 下载链接
:param DownPath: 保存位置
:param FileName: 文件名
:return:
"""
path = 'C:\\Program Files (x86)\\Internet Download Manager\\'
IDM = 'idman'
os.chdir(path)
FileName = '123.mp4'
command = ' '.join([IDM, '/d', DownUrl, '/p', DownPath, '/f', FileName, '/q'])
# autoDowncmd = ' '.join([IDM, '/s'])
os.system(command)
return True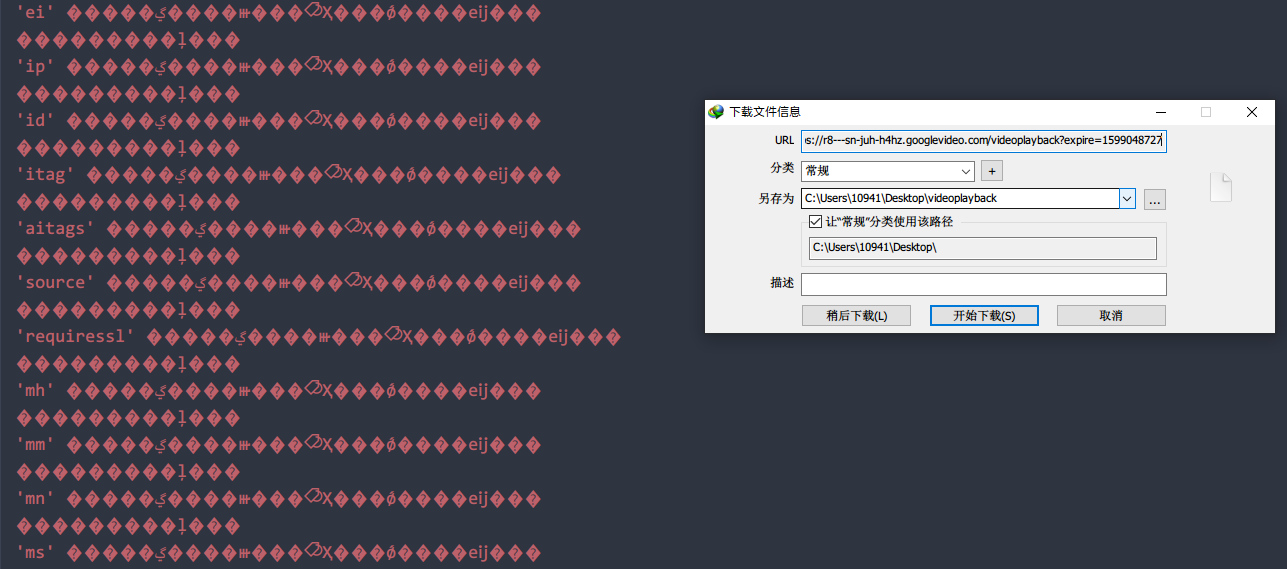
找到IDM路径,使用cmd命令传入参数启动IDM,但命令模式的IDM对链接长度似乎有限制,就此作罢。如图,expire属性之后的属性都没能传入,目前还没有头绪
前面说过,ytb通过googlevideo传输的媒体,音视频是分开的,所以,若要下载完整视频,就需要一个第三方库,ffmpeg,使用方法:使用FFmpeg合并音视频
也就是这两句批处理
# 合并
ffmpeg -i video.mp4 -i audio.wav -c:v copy -c:a aac -strict experimental output.mp4
# 替换音频
ffmpeg -i video.mp4 -i audio.wav -c:v copy -c:a aac -strict experimental -map 0:v:0 -map 1:a:0 output.mp4有点像当年把压缩文件copy到图片,来传输不可描述的资源 我个人来说分开下载音视频方便了剪辑和后期配音,锦上添花的玩意,不重要
在分析json文件时需要装载为字典,调用了json库,为了实现对字典键值对的查找,写了一个函数,可以无限递归遍历
rtnList = [] # 要返回的键/值列表
def get_dict_allkeys(key, dict_a): # 查询字典a中键/值,并将键/值放入rtnlist
"""
多维/嵌套字典数据无限遍历,获取json返回结果的所有key值集合
:param key:
:param dict_a:
:return:
"""
if isinstance(dict_a, dict): # 使用isinstance检测数据类型
for x in range(len(dict_a)):
temp_key = list(dict_a.keys())[x]
temp_value = dict_a[temp_key]
if temp_key == key:
rtnList.append(temp_key + ':' + temp_value)
get_dict_allkeys(key, rtnList) # 自我调用实现无限遍历
elif isinstance(dict_a, list):
for k in dict_a:
if isinstance(k, dict):
for x in range(len(k)):
temp_key = list(k.keys())[x]
temp_value = k[temp_key]
if temp_key == key:
rtnList.append(temp_value)
get_dict_allkeys(key, rtnList)成品是说,如果以学习的目的来看,程序的每一步都能达到我想要的目的,稳定、代码逻辑清晰
半成品是说,在用户使用的角度看,冗余的部分太多,像日志、不必要的分步、命名规范等
一个合格的程序要能完成对错误的自动处理,除非人为设置断点,不能因为冲突而退出
ytb下视频不用Premium🌶,爷青结
2020-09-02开学前夕