A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS. Any suggestions toward the best Non-AR TTS are welcome :)
- Fastformer: Additive Attention Can Be All You Need (Wu et al., 2021)
- Long-Short Transformer: Efficient Transformers for Language and Vision (Zhu et al., 2021)
- Conformer: Convolution-augmented Transformer for Speech Recognition (Gulati et al., 2020)
- Reformer: The Efficient Transformer (Kitaev et al., 2020)
- Attention Is All You Need (Vaswani et al., 2017)
- DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021 (Liu et al., 2021)
- Rich Prosody Diversity Modelling with Phone-level Mixture Density Network (Du et al., 2021)
- FastSpeech 2: Fast and High-Quality End-to-End Text to Speech (Ren et al., 2020)
-
One TTS Alignment To Rule Them All (Badlani et al., 2021): We are finally freed from external aligners such as MFA! Validation alignments for LJ014-0329 up to 70K are shown below as an example.

| Model | Memory Usage | Training Time (1K steps) |
|---|---|---|
| Fastformer (lucidrains') | 10531MiB / 24220MiB | 4m 25s |
| Fastformer (wuch15's) | 10515MiB / 24220MiB | 4m 45s |
| Long-Short Transformer | 10633MiB / 24220MiB | 5m 26s |
| Conformer | 18903MiB / 24220MiB | 7m 4s |
| Reformer | 10293MiB / 24220MiB | 10m 16s |
| Transformer | 7909MiB / 24220MiB | 4m 51s |
| Transformer_fs2 | 11571MiB / 24220MiB | 4m 53s |
Toggle the type of building blocks by
# In the model.yaml
block_type: "transformer_fs2" # ["transformer_fs2", "transformer", "fastformer", "lstransformer", "conformer", "reformer"]Toggle the type of prosody modelings by
# In the model.yaml
prosody_modeling:
model_type: "none" # ["none", "du2021", "liu2021"]Toggle the type of duration modelings by
# In the model.yaml
duration_modeling:
learn_alignment: True # True for unsupervised modeling, and False for supervised modelingDATASET refers to the names of datasets such as LJSpeech and VCTK in the following documents.
You can install the Python dependencies with
pip3 install -r requirements.txt
Also, Dockerfile is provided for Docker users.
You have to download the pretrained models and put them in output/ckpt/DATASET/. The models are trained under unsupervised duration modeling with "transformer_fs2" building block.
For a single-speaker TTS, run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
For a multi-speaker TTS, run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
The dictionary of learned speakers can be found at preprocessed_data/DATASET/speakers.json, and the generated utterances will be put in output/result/.
Batch inference is also supported, try
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
to synthesize all utterances in preprocessed_data/DATASET/val.txt.
The pitch/volume/speaking rate of the synthesized utterances can be controlled by specifying the desired pitch/energy/duration ratios. For example, one can increase the speaking rate by 20 % and decrease the volume by 20 % by
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Add --speaker_id SPEAKER_ID for a multi-speaker TTS.
The supported datasets are
- LJSpeech: a single-speaker English dataset consists of 13100 short audio clips of a female speaker reading passages from 7 non-fiction books, approximately 24 hours in total.
- VCTK: The CSTR VCTK Corpus includes speech data uttered by 110 English speakers (multi-speaker TTS) with various accents. Each speaker reads out about 400 sentences, which were selected from a newspaper, the rainbow passage and an elicitation paragraph used for the speech accent archive.
Any of both single-speaker TTS dataset (e.g., Blizzard Challenge 2013) and multi-speaker TTS dataset (e.g., LibriTTS) can be added following LJSpeech and VCTK, respectively. Moreover, your own language and dataset can be adapted following here.
-
For a multi-speaker TTS with external speaker embedder, download ResCNN Softmax+Triplet pretrained model of philipperemy's DeepSpeaker for the speaker embedding and locate it in
./deepspeaker/pretrained_models/. -
Run
python3 prepare_align.py --dataset DATASETfor some preparations.
For the forced alignment, Montreal Forced Aligner (MFA) is used to obtain the alignments between the utterances and the phoneme sequences. Pre-extracted alignments for the datasets are provided here. You have to unzip the files in
preprocessed_data/DATASET/TextGrid/. Alternately, you can run the aligner by yourself.After that, run the preprocessing script by
python3 preprocess.py --dataset DATASET
Train your model with
python3 train.py --dataset DATASET
Useful options:
- To use a Automatic Mixed Precision, append
--use_ampargument to the above command. - The trainer assumes single-node multi-GPU training. To use specific GPUs, specify
CUDA_VISIBLE_DEVICES=<GPU_IDs>at the beginning of the above command.
Use
tensorboard --logdir output/log
to serve TensorBoard on your localhost. The loss curves, synthesized mel-spectrograms, and audios are shown.







| ID | Model | Block Type | Pitch Conditioning |
|---|---|---|---|
| 1 | LJSpeech_transformer_fs2_cwt | transformer_fs2 |
continuous wavelet transform |
| 2 | LJSpeech_transformer_cwt | transformer |
continuous wavelet transform |
| 3 | LJSpeech_transformer_frame | transformer |
frame-level f0 |
| 4 | LJSpeech_transformer_ph | transformer |
phoneme-level f0 |
Observations from
- changing building block (ID 1~2): "transformer_fs2" seems to be more optimized in terms of memory usage and model size so that the training time and mel losses are decreased. However, the output quality is not improved dramatically, and sometimes the "transformer" block generates speech with an even more stable pitch contour than "transformer_fs2".
- changing pitch conditioning (ID 2~4): There is a trade-off between audio quality (pitch stability) and expressiveness.
- audio quality: "ph" >= "frame" > "cwt"
- expressiveness: "cwt" > "frame" > "ph"
- Both phoneme-level and frame-level variance are supported in both supervised and unsupervised duration modeling.
- Note that there are no pre-extracted phoneme-level variance features in unsupervised duration modeling.
- Unsupervised duration modeling in phoneme-level will take longer time than frame-level since the additional computation of phoneme-level variance is activated at runtime.
- Two options for embedding for the multi-speaker TTS setting: training speaker embedder from scratch or using a pre-trained philipperemy's DeepSpeaker model (as STYLER did). You can toggle it by setting the config (between
'none'and'DeepSpeaker'). - DeepSpeaker on VCTK dataset shows clear identification among speakers. The following figure shows the T-SNE plot of extracted speaker embedding.

- For vocoder, HiFi-GAN and MelGAN are supported.
-
Mar.05, 2022 (v0.2.1): Fix and update codebase & pre-trained models with demo samples
- Fix variance adaptor to make it work with all combinations of building block and variance type/level
- Update pre-trained models with demo samples of LJSpeech and VCTK under "transformer_fs2" building block and "cwt" pitch conditioning
- Share the result of ablation studies of comparing "transformer" vs. "transformer_fs2" paired among three types of pitch conditioning ("frame", "ph", and "cwt")
-
Feb.18, 2022 (v0.2.0): Update data preprocessor and variance adaptor & losses following keonlee9420's DiffSinger / Add various prosody modeling methods
- Prepare two different types of data pipeline in preprocessor to maximize unsupervised/supervised duration modelings
- Adopt wavelet for pitch modeling & loss
- Add fine-trained duration loss
- Apply
var_start_stepsfor better model convergence, especially under unsupervised duration modeling - Remove dependency of energy modeling on pitch variance
- Add "transformer_fs2" building block, which is more close to the original FastSpeech2 paper
- Add two types of prosody modeling methods
- Loss camparison on validation set:
- LJSpeech - blue: v0.1.1 / green: v0.2.0
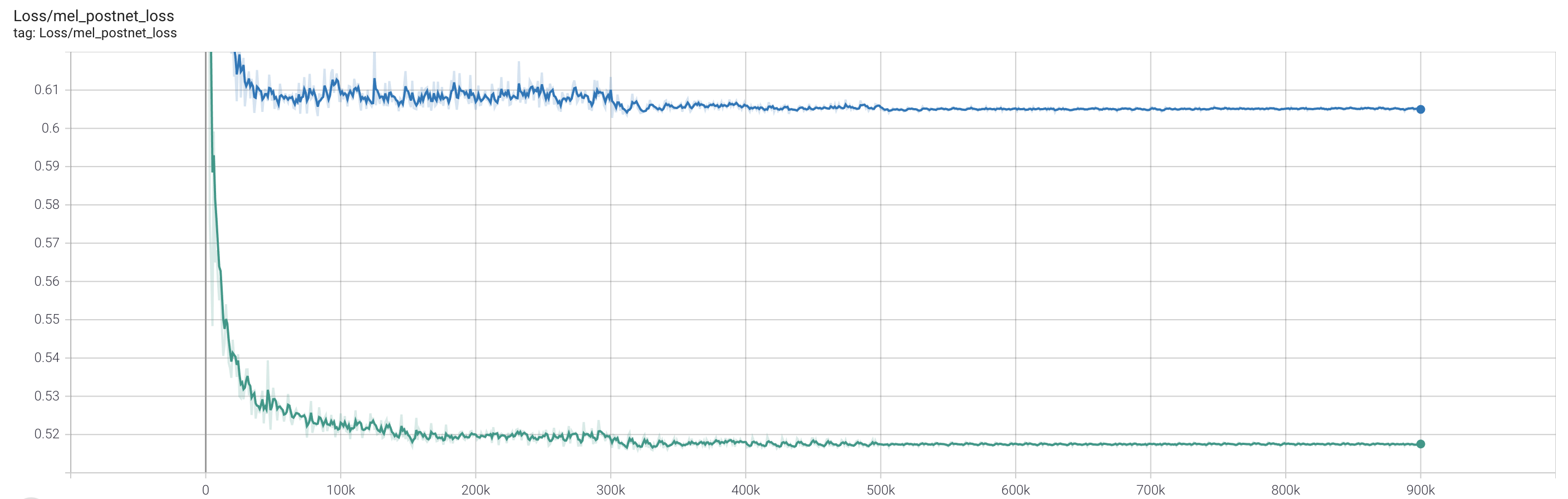
- VCTK - skyblue: v0.1.1 / orange: v0.2.0
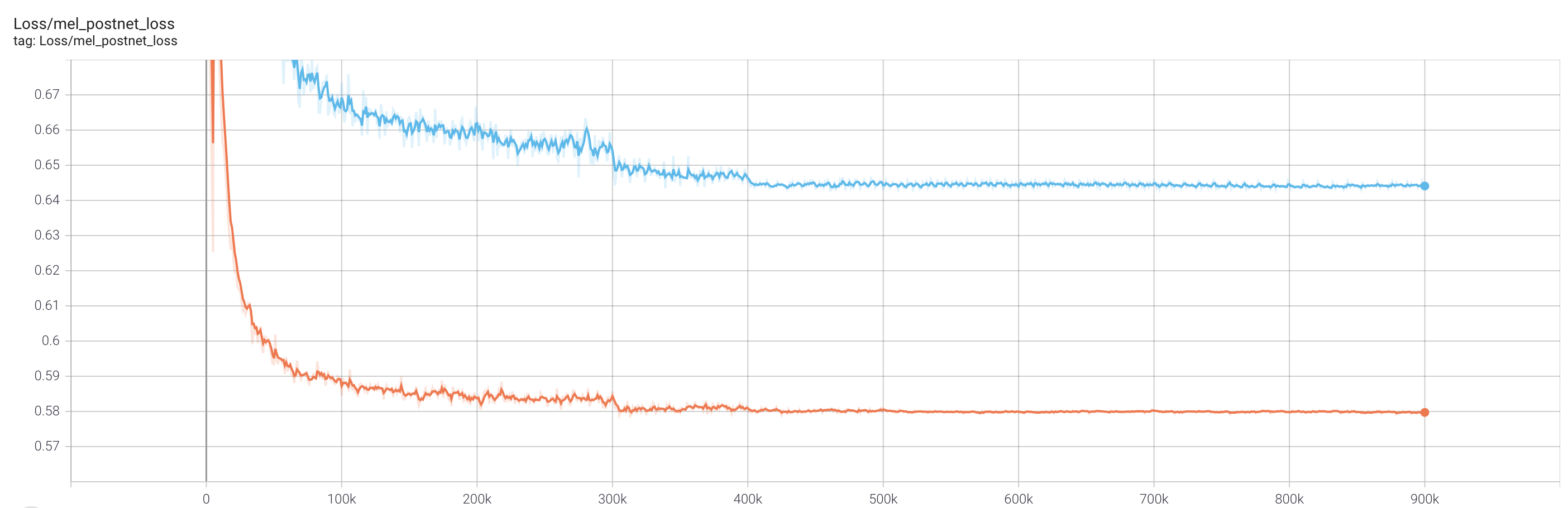
-
Sep.21, 2021 (v0.1.1): Initialize with ming024's FastSpeech2


Please cite this repository by the "Cite this repository" of About section (top right of the main page).
- ming024's FastSpeech2
- wuch15's Fastformer
- lucidrains' fast-transformer-pytorch
- lucidrains' long-short-transformer
- sooftware's conformer
- lucidrains' reformer-pytorch
- sagelywizard's pytorch-mdn
- keonlee9420's Robust_Fine_Grained_Prosody_Control
- keonlee9420's Cross-Speaker-Emotion-Transfer
- keonlee9420's DiffSinger
- NVIDIA's NeMo: Special thanks to Onur Babacan and Rafael Valle for unsupervised duration modeling.