Reducing Burden
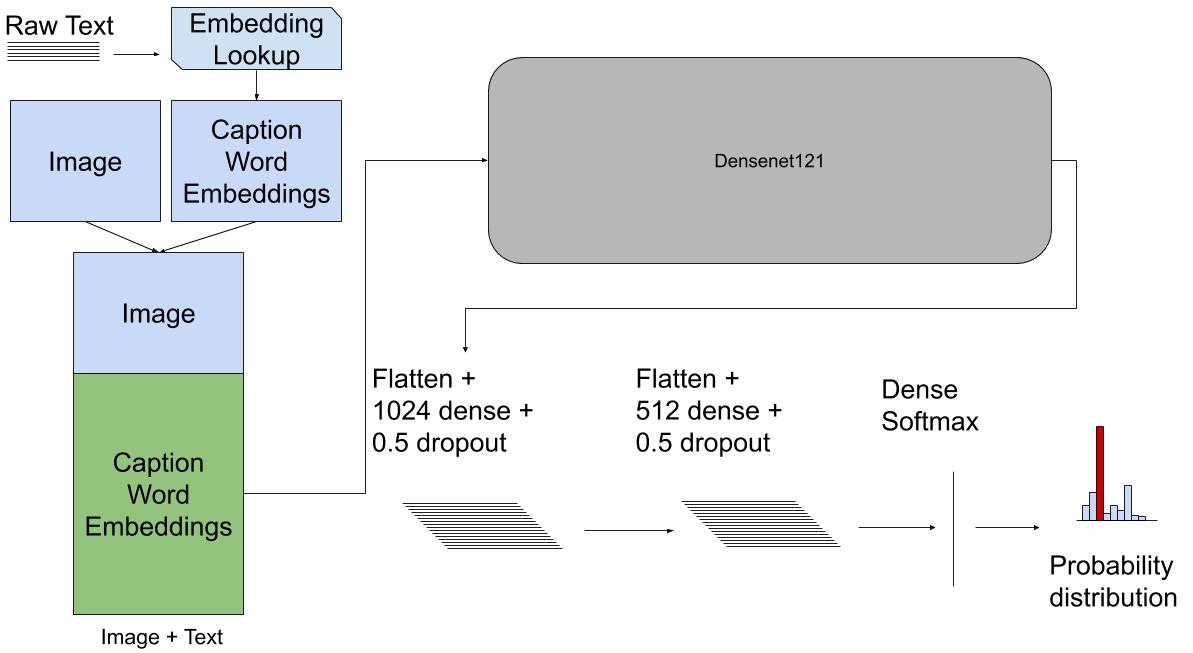 Data Fusion using machine learning is essential for integrating multimodal data. We explored different multimodal fusion methods including early, late, and model fusion to classify radiological images and associated text reports. We investigated the amount of labeled data needed for comparable performance by multimodal and unimodal models. We also gauged the performance of multimodal models vs unimodal models. Furthermore, we compared the performance between the different multimodal models: early, late, and model fusion. Our experiments showed the potential of multimodal fusion to produce competitive results using less training data when compared to their unimodal counterparts which was more noticeable with the early fusion method. Overall, our results suggest data fusion techniques may decrease the burden of annotation by physicians.
Data Fusion using machine learning is essential for integrating multimodal data. We explored different multimodal fusion methods including early, late, and model fusion to classify radiological images and associated text reports. We investigated the amount of labeled data needed for comparable performance by multimodal and unimodal models. We also gauged the performance of multimodal models vs unimodal models. Furthermore, we compared the performance between the different multimodal models: early, late, and model fusion. Our experiments showed the potential of multimodal fusion to produce competitive results using less training data when compared to their unimodal counterparts which was more noticeable with the early fusion method. Overall, our results suggest data fusion techniques may decrease the burden of annotation by physicians.
Preliminary Results:
| Model | N=1 | N=2 | N=4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Precision | Recall | AUC | F1 | Precision | Recall | AUC | F1 | Precision | Recall | AUC | |
| Early Fusion | 0.928 | 0.93 | 0.927 | 0.972 | 0.893 | 0.894 | 0.893 | 0.952 | 0.876 | 0.877 | 0.876 | 0.934 |
| Image Only | 0.637 | 0.64 | 0.636 | 0.674 | 0.617 | 0.619 | 0.617 | 0.629 | 0.616 | 0.622 | 0.615 | 0.639 |
| Late Fusion | 0.92 | 0.925 | 0.919 | 0.946 | 0.86 | 0.872 | 0.858 | 0.884 | 0.83 | 0.85 | 0.827 | 0.859 |
| Model Fusion | 0.88 | 0.905 | 0.878 | 0.982 | 0.86 | 0.882 | 0.858 | 0.961 | 0.844 | 0.869 | 0.841 | 0.938 |
| Text Only | 0.906 | 0.916 | 0.904 | 0.977 | 0.866 | 0.885 | 0.864 | 0.954 | 0.843 | 0.861 | 0.841 | 0.925 |