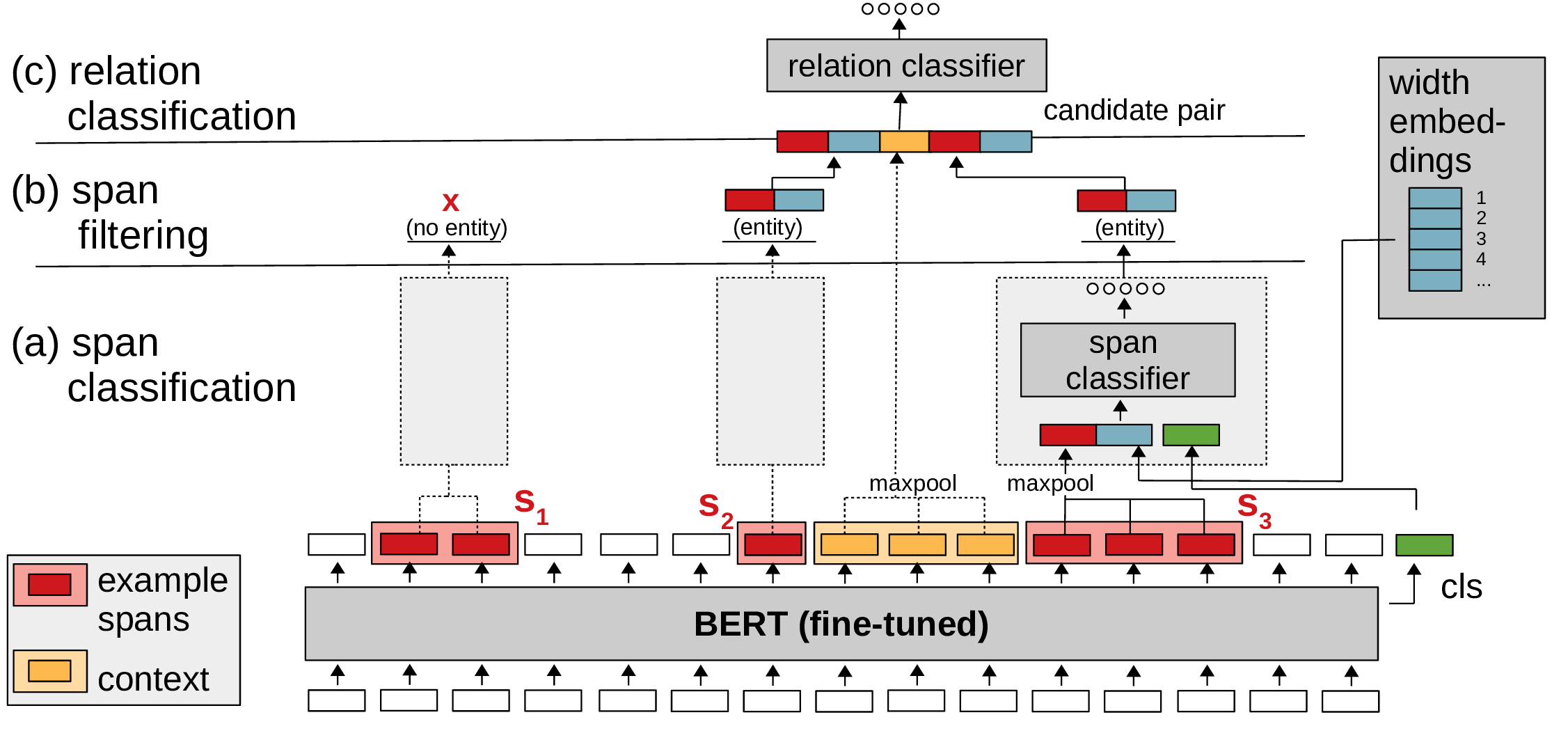
PyTorch code for SpERT: "Span-based Entity and Relation Transformer". For a description of the model and experiments, see our paper: https://arxiv.org/abs/1909.07755 (accepted at ECAI 2020).
- Required
- Python 3.5+
- PyTorch (tested with version 1.4.0)
- transformers (+sentencepiece, e.g. with 'pip install transformers[sentencepiece]', tested with version 4.1.1)
- scikit-learn (tested with version 0.24.0)
- tqdm (tested with version 4.55.1)
- numpy (tested with version 1.17.4)
- Optional
- jinja2 (tested with version 2.10.3) - if installed, used to export relation extraction examples
- tensorboardX (tested with version 1.6) - if installed, used to save training process to tensorboard
- spacy (tested with version 3.0.1) - if installed, used to tokenize sentences for prediction
Fetch converted (to specific JSON format) CoNLL04 [1] (we use the same split as [4]), SciERC [2] and ADE [3] datasets (see referenced papers for the original datasets):
bash ./scripts/fetch_datasets.sh
Fetch model checkpoints (best out of 5 runs for each dataset):
bash ./scripts/fetch_models.sh
The attached ADE model was trained on split "1" ("ade_split_1_train.json" / "ade_split_1_test.json") under "data/datasets/ade".
(1) Train CoNLL04 on train dataset, evaluate on dev dataset:
python ./spert.py train --config configs/example_train.conf
(2) Evaluate the CoNLL04 model on test dataset:
python ./spert.py eval --config configs/example_eval.conf
(3) Use the CoNLL04 model for prediction. See the file 'data/datasets/conll04/conll04_prediction_example.json' for supported data formats. You have three options to specify the input sentences, choose the one that suits your needs. If the dataset contains raw sentences, 'spacy' must be installed for tokenization. Download a spacy model via 'python -m spacy download model_label' and set it as spacy_model in the configuration file (see 'configs/example_predict.conf').
python ./spert.py predict --config configs/example_predict.conf
- To train SpERT with SciBERT [5] download SciBERT from https://github.com/allenai/scibert (under "PyTorch HuggingFace Models") and set "model_path" and "tokenizer_path" in the config file to point to the SciBERT directory.
- You can call "python ./spert.py train --help" / "python ./spert.py eval --help" "python ./spert.py predict --help" for a description of training/evaluation/prediction arguments.
- Please cite our paper when you use SpERT:
Markus Eberts, Adrian Ulges. Span-based Joint Entity and Relation Extraction with Transformer Pre-training. 24th European Conference on Artificial Intelligence, 2020.
[1] Dan Roth and Wen-tau Yih, ‘A Linear Programming Formulation forGlobal Inference in Natural Language Tasks’, in Proc. of CoNLL 2004 at HLT-NAACL 2004, pp. 1–8, Boston, Massachusetts, USA, (May 6 -May 7 2004). ACL.
[2] Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi, ‘Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction’, in Proc. of EMNLP 2018, pp. 3219–3232, Brussels, Belgium, (October-November 2018). ACL.
[3] Harsha Gurulingappa, Abdul Mateen Rajput, Angus Roberts, JulianeFluck, Martin Hofmann-Apitius, and Luca Toldo, ‘Development of a Benchmark Corpus to Support the Automatic Extraction of Drug-related Adverse Effects from Medical Case Reports’, J. of BiomedicalInformatics,45(5), 885–892, (October 2012).
[4] Pankaj Gupta, Hinrich Schütze, and Bernt Andrassy, ‘Table Filling Multi-Task Recurrent Neural Network for Joint Entity and Relation Extraction’, in Proc. of COLING 2016, pp. 2537–2547, Osaka, Japan, (December 2016). The COLING 2016 Organizing Committee.
[5] Iz Beltagy, Kyle Lo, and Arman Cohan, ‘SciBERT: A Pretrained Language Model for Scientific Text’, in EMNLP, (2019).