This is the Capstone project (last of the three projects) required for fulfillment of the Nanodegree Machine Learning Engineer with Microsoft Azure from Udacity. In this project, we use a dataset external to Azure ML ecosystem.
Azure Machine Learning Service and Jupyter Notebook is used to train models using both Hyperdrive and Auto ML and then the best of these models is deployed as an HTTP REST endpoint. The model endpoint is also tested to verify if it is working as intented by sending an HTTP POST request. Azure ML Studio graphical interface is not used in the entire exercise to encourage use of code which is better suited for automation and gives a data scientist more control over their experiment.
In this dataset, we predict divorce among couples by using the Divorce Predictors Scale (DPS) on the basis of Gottman couples therapy. The data was collected from seven different regions of Turkey, predominantly from the Black Sea region. Of the participants, 84 (49%) were divorced and 86 (51%) were married couples. Divorced participants answered the scale items by considering their marriages whereas, of the married participants, only those with happy marriages, without any thought of divorce, were included in the study.
The dataset consists of 170 rows/records/examples and 54 features/attributes/columns. Attribute columns are labeled as Atr1 to Atr54, Class column predicts the divorce, a value of 1 means couple would end up in divorce. You can read further about the dataset here
Download dataset from here
As we have to predict either of two states (Divorce/No Divorce), this problem is a Classification one. The 54 features that we will use for prediction are described below. Each feature can have a value form the list [0, 1, 2, 3, 4].
- If one of us apologizes when our discussion deteriorates, the discussion ends.
- I know we can ignore our differences, even if things get hard sometimes.
- When we need it, we can take our discussions with my spouse from the beginning and correct it.
- When I discuss with my spouse, to contact him will eventually work.
- The time I spent with my wife is special for us.
- We don't have time at home as partners.
- We are like two strangers who share the same environment at home rather than family.
- I enjoy our holidays with my wife.
- I enjoy traveling with my wife.
- Most of our goals are common to my spouse.
- I think that one day in the future, when I look back, I see that my spouse and I have been in harmony with each other.
- My spouse and I have similar values in terms of personal freedom.
- My spouse and I have similar sense of entertainment.
- Most of our goals for people (children, friends, etc.) are the same.
- Our dreams with my spouse are similar and harmonious.
- We're compatible with my spouse about what love should be.
- We share the same views about being happy in our life with my spouse
- My spouse and I have similar ideas about how marriage should be
- My spouse and I have similar ideas about how roles should be in marriage
- My spouse and I have similar values in trust.
- I know exactly what my wife likes.
- I know how my spouse wants to be taken care of when she/he sick.
- I know my spouse's favorite food.
- I can tell you what kind of stress my spouse is facing in her/his life.
- I have knowledge of my spouse's inner world.
- I know my spouse's basic anxieties.
- I know what my spouse's current sources of stress are.
- I know my spouse's hopes and wishes.
- I know my spouse very well.
- I know my spouse's friends and their social relationships.
- I feel aggressive when I argue with my spouse.
- When discussing with my spouse, I usually use expressions such as ‘you always’ or ‘you never’ .
- I can use negative statements about my spouse's personality during our discussions.
- I can use offensive expressions during our discussions.
- I can insult my spouse during our discussions.
- I can be humiliating when we discussions.
- My discussion with my spouse is not calm.
- I hate my spouse's way of open a subject.
- Our discussions often occur suddenly.
- We're just starting a discussion before I know what's going on.
- When I talk to my spouse about something, my calm suddenly breaks.
- When I argue with my spouse, ı only go out and I don't say a word.
- I mostly stay silent to calm the environment a little bit.
- Sometimes I think it's good for me to leave home for a while.
- I'd rather stay silent than discuss with my spouse.
- Even if I'm right in the discussion, I stay silent to hurt my spouse.
- When I discuss with my spouse, I stay silent because I am afraid of not being able to control my anger.
- I feel right in our discussions.
- I have nothing to do with what I've been accused of.
- I'm not actually the one who's guilty about what I'm accused of.
- I'm not the one who's wrong about problems at home.
- I wouldn't hesitate to tell my spouse about her/his inadequacy.
- When I discuss, I remind my spouse of her/his inadequacy.
- I'm not afraid to tell my spouse about her/his incompetence.
The dataset has been uploaded into this github repository and it can be accessed using the link as below:
We used method from_delimited_files('webURL') of the TabularDatasetFactory Class to retreive data from the csv file (link provided above).
Configuration and settings used for the Automated ML experiment are described in the table below:
| Configuration | Description | Value |
|---|---|---|
| experiment_timeout_minutes | This is used as an exit criteria, it defines how long, in minutes, your experiment should continue to run | 20 |
| max_concurrent_iterations | Represents the maximum number of iterations that would be executed in parallel | 5 |
| primary_metric | The metric that Automated Machine Learning will optimize for model selection | accuracy |
| task | The type of task to run. Values can be 'classification', 'regression', or 'forecasting' depending on the type of automated ML problem | classification |
| compute_target | The compute target to run the experiment on | trainCluster |
| training_data | Training data, contains both features and label columns | ds |
| label_column_name | The name of the label column | Class |
| n_cross_validations | No. of cross validations to perform | 5 |
In our experiment we found out SparseNormalizer GradientBoosting to be the best model based on the accuracy metric. The accuracy score for this models was 0.9882352941176471.
The parameters for the model SparseNormalizer GradientBoosting are described in the table below.
SparseNormalizer
| Parameters | Values |
|---|---|
| copy | True |
| norm | max |
GradientBoosting
| Parameters | Values |
|---|---|
| ccp_alpha | 0.0 |
| criterion | mse |
| init | None |
| learning_rate | 0.1 |
| loss | deviance |
| max_depth | 3 |
| max_features | sqrt |
| max_leaf_nodes | None |
| min_impurity_decrease | 0.0 |
| min_impurity_split | None |
| min_samples_leaf | 0.08736842105263157 |
| min_samples_split | 0.15052631578947367 |
| min_weight_fraction_leaf | 0.0 |
| n_estimators | 25 |
| n_iter_no_change | None |
| presort | deprecated |
| random_state | None |
| subsample | 0.8105263157894737 |
| tol | 0.0001 |
| validation_fraction | 0.1 |
| verbose | 0 |
| warm_start | False |
Improvements for autoML
- Change experiment timeout, this would allow for more model experimentation but the longer runs may cost you more.
- We could use different primary metric as sometimes accuracy alone doesn't represent true picture of the model performance.
- Incresing the number of cross validations may reduce the bias in the model.
Run Details Widget


Best Model

We use Logistric Regression algorithm from the SKLearn framework in conjuction with hyperDrive for hyperparameter tuning. There are two hyperparamters for this experiment, C and max_iter. C is the inverse regularization strength whereas max_iter is the maximum iteration to converge for the SKLearn Logistic Regression.
We have used random parameter sampling to sample over a discrete set of values. Random parameter sampling is great for discovery and getting hyperparameter combinations that you would not have guessed intuitively, although it often requires more time to execute.
The parameter search space used for C is [1,2,3,4,5] and for max_iter is [80,100,120,150,170,200]
The benchmark metric (accuracy) is evaluated using hyperDrive early stopping policy. Execution of the experiment is stopped if conditions specified by the policy are met.
We have used the BanditPolicy. This policy is based on slack factor/slack amount and evaluation interval. Bandit terminates runs where the primary metric is not within the specified slack factor/slack amount compared to the best performing run. This helps to improves computational efficiency.
For this experiment the configuratin used is; evaluation_interval=1, slack_factor=0.2, and delay_evaluation=5. This configration means that the policy would be applied to every 1*5 iteration of the pipeline and if 1.2*value of the benchmark metric for current iteration is smaller than the best metric value so far, the run will be cancelled.
The highest accuracy that our Logistic Regression Model acheived was 0.9803921568627451. The hyperparamteres that were used by this model are:
| Hyperparameter | Value |
|---|---|
| Regularization Strength (C) | 2.0 |
| Max Iterations (max_iter) | 150 |
Improvements for hyperDrive
- Use Bayesian Parameter Sampling instead of Random; Bayesian sampling tries to intelligently pick the next sample of hyperparameters, based on how the previous samples performed, such that the new sample improves the reported primary metric.
- We could use different primary metric as sometimes accuracy alone doesn't represent true picture of the model performance.
- Increasing max total runs to try a lot more combinations of hyperparameters, this would have an impact on cost too.
Run Details Widget



Best Model

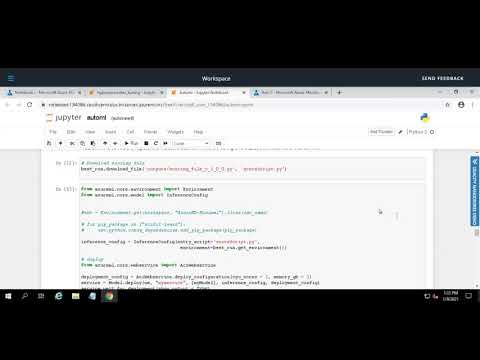
To deploy a Model using Azure Machine Learning Service, we need following:
- A trained Model
- Inference configuration; includes scoring script and environment
- Deploy configuration; includes choice of deployment (ACI, AKS or local) and cpu/gpu/memory allocation
Scoring script is generated when a model is created. It describes the input data that model will expect and passes it to the model for prediction and returns the results. Following command can be used to retreive the scoring script; best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'scoreScript.py').
We use the environment used by the best_run, the environment can be retreived by best_run.get_environment(). We can also download the yml file associated with the environment by using: best_run.download_file('outputs/conda_env_v_1_0_0.yml', 'envFile.yml')
For deployment we used Azure Container Instances with cpu_cores = 1 and memory_gb = 1
For Inference, the data passed to the model endpoint must be in JSON format. Following commands passes the data to the model as an HTTP POST request and records the response; response = requests.post(service.scoring_uri, test_sample, headers=headers)
Screenshots below show a demonstration of sample data response from the deployed model.
Demo

Deployed Model

The screencast shows the entire process of the working ML application, including a demonstration of:
- A working model
- Demo of the deployed model
- Demo of a sample request sent to the endpoint and its response
Yöntem, M , Adem, K , İlhan, T , Kılıçarslan, S. (2019). DIVORCE PREDICTION USING CORRELATION BASED FEATURE SELECTION AND ARTIFICIAL NEURAL NETWORKS. Nevşehir Hacı Bektaş Veli University SBE Dergisi, 9 (1), 259-273.