Máy tính chỉ có thể học dữ liệu nếu lập trình viên mã hóa các dữ liệu đó thành các số, sau khi trải qua nhiều các bước thì tiếp tục giải mã. Quá trình đó gọi là Encoder và Decode. Vậy E và D là gì?
- Encoder: Chuyển input thành các features learning có khả năng học tập. Với các NN thì encoder này là các lớp ẩn, còn CNN thì là chuỗi các layers Conv + Maxpooling, RNN thì nó lại là các layers Embedding và Recurrent Neral Network.
- Decoder: Đầu ra của Encoder là đầu vào của Decoder, mục đích là tìm ra phân phối xác xuất từ các features learning ở Encoder để xác định nhãn. Kết quả nếu là các model phân loại là một nhãn, còn model seq2seq là một chuỗi các nhãn theo thứ tự.
Mô hình seq2seq khi chưa có lớp attention
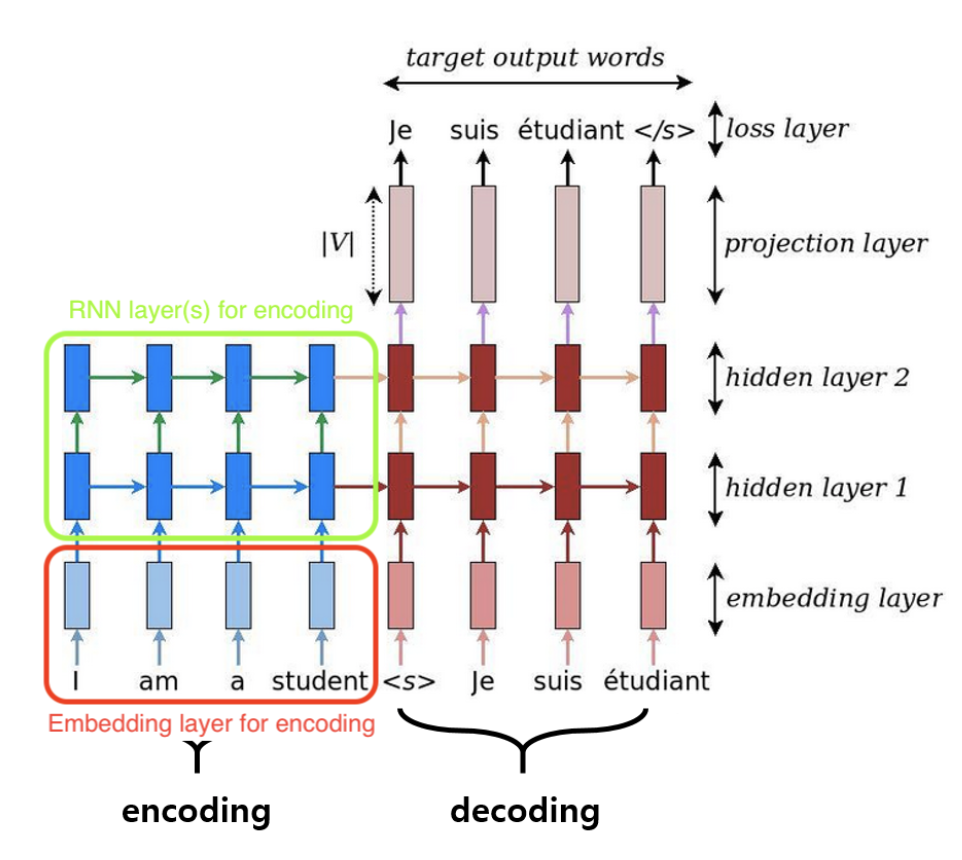
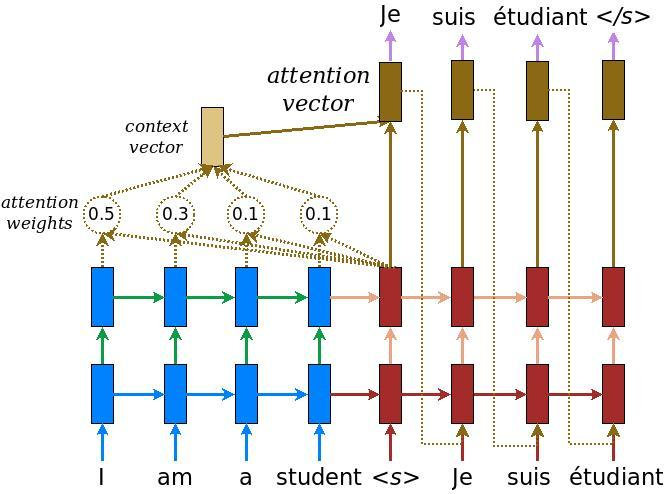
Có lớp Attention
Như trong hình có lớp Attention, từ 'I' trong tiếng Pháp là 'Je', đó đó lớp attention điều chỉnh một trọng số
Các bước thực hiện
1. Đầu tiên tại time step thứ
Ở đây dot product hoặc cosine similarity tùy vào lựa chọn.
2. Các scores sau bước 1 chưa được chuẩn hóa. Để tạo thành một phân phối xác xuất chúng ta đi qua hàm softmax khi đó ta sẽ thu được các trọng số attention weight.
3. Kết hợp vector phân phối xác xuất
4. Tính attention vector để decode ra từ tương ứng ở ngôn ngữ đích. Attention vector sẽ là kết hợp của context vector và các hidden state ở decoder. Theo cách này attention vector sẽ không chỉ được học từ chỉ hidden state ở unit cuối cùng như hình 1 mà còn được học từ toàn bộ các từ ở vị trí khác thông qua context vector. Công thức tính output cho hidden state cũng
tương tự như tính đầu ra cho input gate layer trong mạng RNN:
Kí hiệu
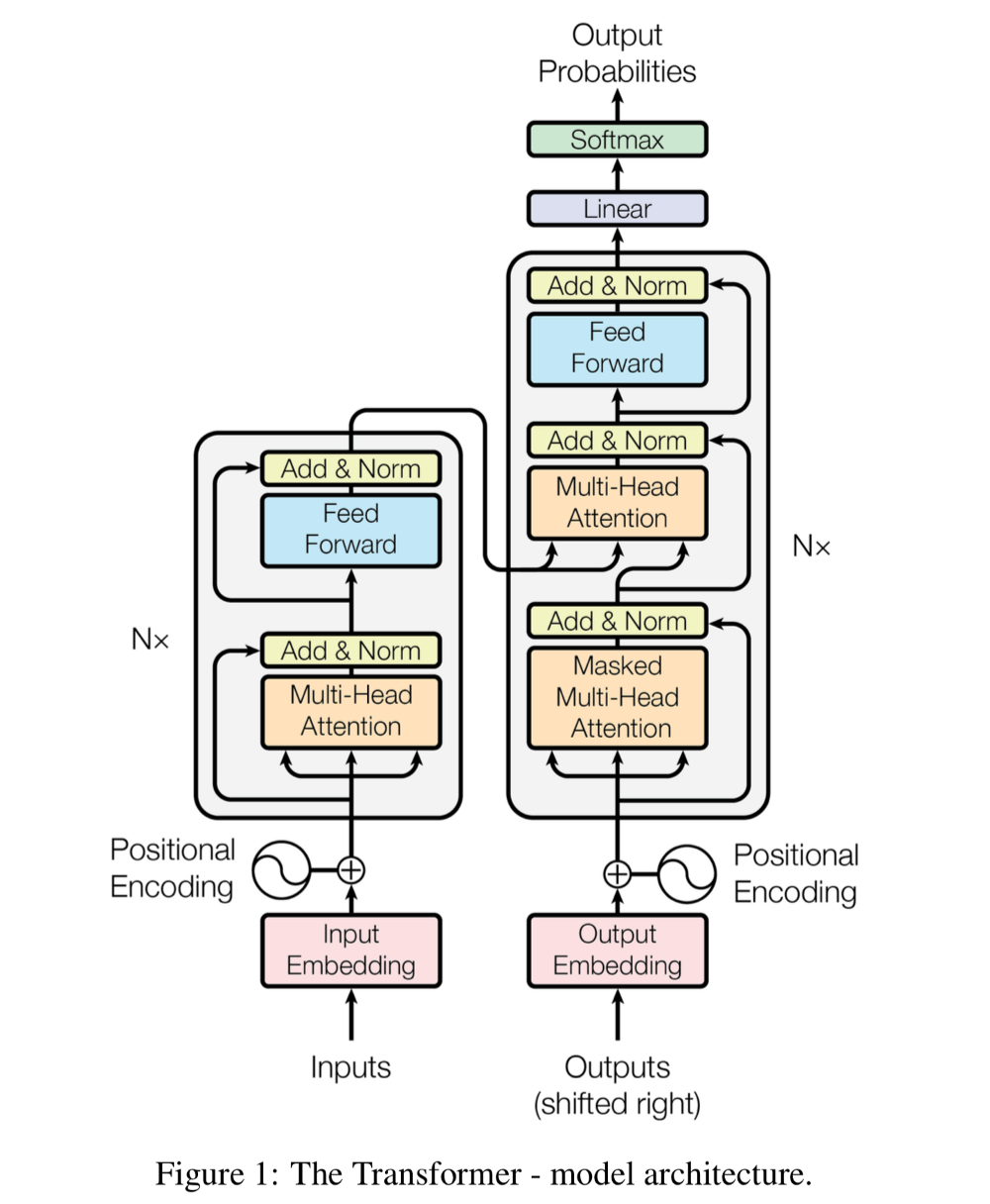
-
Encoder: Đầu ra của sub-layer là
$LayerNorm(x+Sublayer(x))$ có số chiều là 512 - Decoder: Có thêm 1 Masker ở sub-layer đầu tiên. Layer này không gì khác so với multi-head self-attention layer ngoại trừ được điều chỉnh để không đưa các từ trong tương lai vào attention.
Positional Encoding : đưa thêm yếu tố thời gian vào mô hình để làm tăng độ chuân xác. Nó là phép cộng vector mã hóa vị trí với vector biểu diễn từ. Mã hóa dưới dạng [0,1] hoặc sử dụng sin, cos.
Là một cơ chế self-attention: mỗi từ có thể điều chỉnh trọng số của từ khác trong câu sao cho từ ở vị trí càng gần nó nhất thì trọng số càng lớn và càng xa thì càng nhỏ. Sau khi đi qua lớp embedding ta có ma trận X là đầu vào của encoder và decoder.

Các Wq, Wk, Wv là hệ số mà model cần huấn luyện. Nhân với ma trận X thu đc ma trận Q, K, V.
Q, K tính toán phân phối score cho các cặp từ, V dựa trên phân phối score để tính vector phân phối xác suất. -> mỗi từ đc gán bởi 3 vector Q, K, V

Để tính score cho mỗi cặp từ ta cần tính dot-production giữa Q và K, phép tính này nhằm tìm ra mối liên hệ trọng số của các cặp từ. Sau đó chuẩn hóa bằng hàm Softmax, tiếp tục nhân Softmax với V để tìm ra attention vector.

Tính cho từ I

Tính attention cho toàn bộ câu
$Attention(\mathbf{Q, K, V}) = softmax(\frac{\mathbf{QK^T})}{\sqrt{d_k}}\mathbf{V} \tag{1}$