DevOps Project Spring 2018 NC State University
| Name | Unity ID |
|---|---|
| 1. Navjot Singh | nsingh9 |
| 2. Khelan Patel | kjpatel4 |
| 3. Khantil Choksi | khchoksi |
| 4. Pavithra Iyer | piyer3 |
- Kubernetes Clustor Monitoring Dashboard: Khantil & Navjot
- Jenkins Slackbot Integration: Khelan & Pavithra
- Screencast: Navjot, Khantil, Khelan, Pavithra
- In our DevOps pipeline, one Kubernetes cluster containing one master and three slave nodes (EC2 instances) are configured for Dockerized version of checkbox.io. We have three pods (nginx, mongodb and checkbox) and respective three services already running.
-
By using proper tools, we can have good visibility into our containerized infrastructure and its orchestration.
-
Heapster: Kubernetes’ own metrics collector:
- Heapster is for now the go-to source for basic resource utilization metrics and events from our Kubernetes cluster.
- On each node, cAdvisor collects data about running containers that Heapster then queries through the kubelet of the node. The following solution to collect Kubernetes metrics, will give you more details on how Heapster works and how to configure it for with Grafana and Kubernetes dashboard.
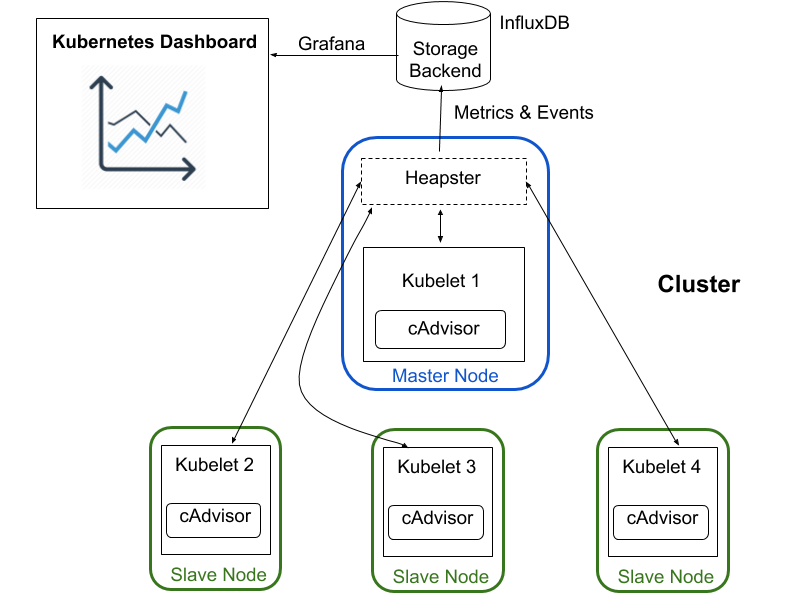


We have created new role setup_dashboard which will handle following tasks exaplained and you just have to follow steps 6,7, and 8 as instructed below in order to get the dashboard in your browser.
-
Kubernetes cluster is already setup or see instructions here.
-
Heapster, InfluxDB and Grafana Running:
Heapster has to be running in the cluster for the metrics and graphs to be available. For the integration of Heapster with backend DB InfluxDB and supporting graphs to be shown in Kubernetes Dashboard using Grafana, following yamls should be created to start and deploy services for influx, grafana and heapster.kubectl create -f https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/influxdb.yaml kubectl create -f https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/grafana.yaml kubectl create -f https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/heapster.yaml -
Create and Kubernetes Dasboard Service:
- To deploy Dashboard, execute following command:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
- To deploy Dashboard, execute following command:
-
Creating Sample User to access Kubernetes Dashboard:
- Creating Service Account with name
admin-userin namespacekube-systemfirst using service_account.yaml:
kubectl create -f ./monitoring/service-account/service_account.yaml
- Creating Service Account with name
-
Create Cluster Role Binding:
- After provisioning our cluster using
kubeadm,adminRole already exists in the cluster. We can use it and create onlyRoleBindingfor ourServiceAccountusing cluster_role_binding.yaml:
kubectl create -f ./monitoring/service-account/cluster_role_binding.yaml
- After provisioning our cluster using
-
Bearer Token:
- To find token to log in into Kubernetes Dashboard; execute following command:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
- To find token to log in into Kubernetes Dashboard; execute following command:
-
Start proxy to see Dasboard:
- To access Dashboard from local workstation; create a secure channel to Kubernetes cluster's master node. Run the following command:
kubectl proxy
- To access Dashboard from local workstation; create a secure channel to Kubernetes cluster's master node. Run the following command:
-
Accessing Dashboard:
- We can now access dashboard:
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/ - Here as of now, the deployment of Dashboard to public is not possbile due to their api concerns; so here I am using the SOCKS proxy to access the locally hosted Kubernetes Dashboard webpage inside the Kubernetes cluster's master node. To do this,
ssh -D 8080 -i "kube-ec2.pem" centos@ec2-18-237-77-230.us-west-2.compute.amazonaws.com.
- We can now access dashboard:




- Chaos Experiment: After running shell script by using command:
sh chaos_cpu.shto increase the CPU usage of one of our node, following CPU usage graph in real-time is obtained.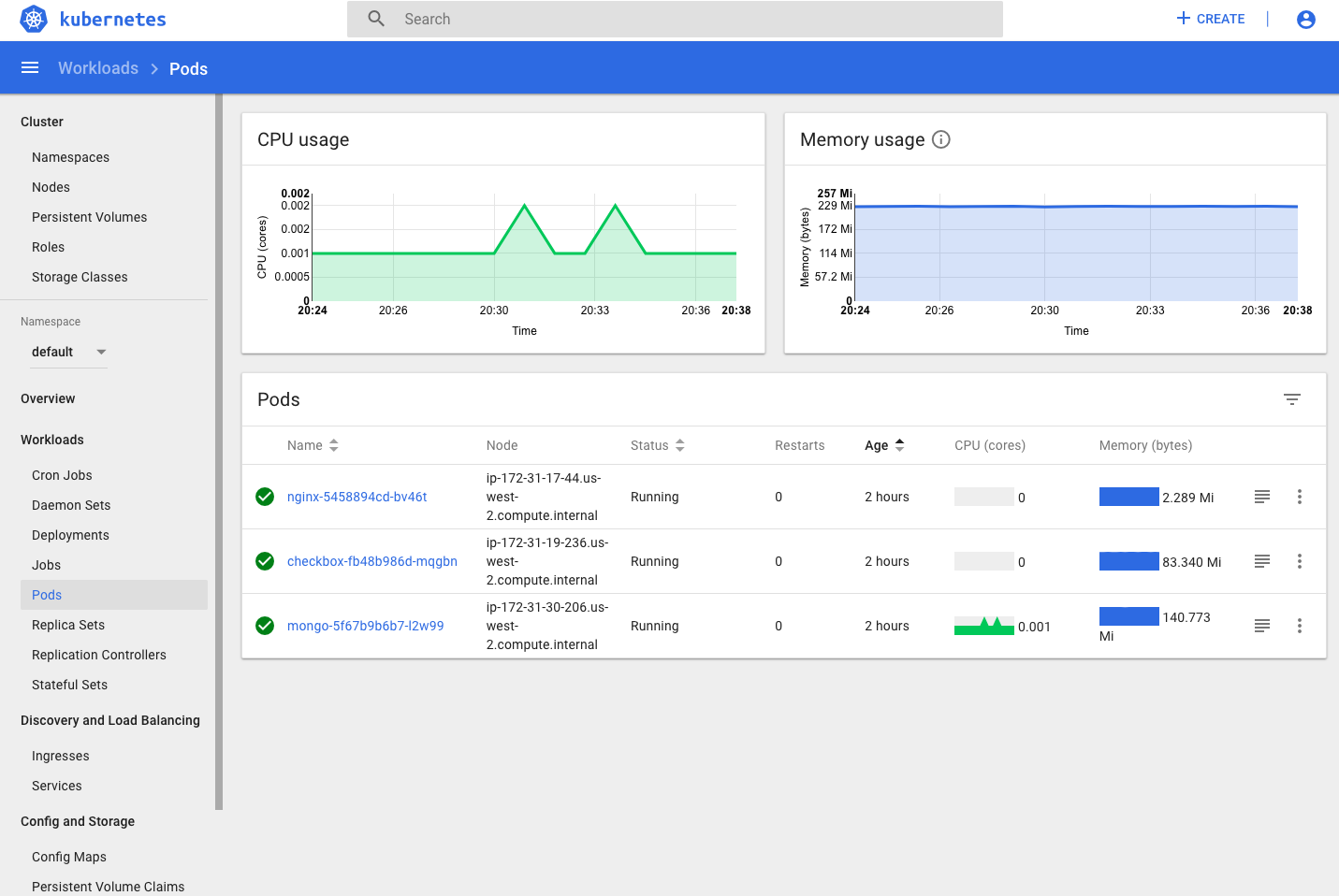

- Added Slack & jenkins integration which helps to Improve development team communication and workflow, which eventually results in higher team productivity.
- To monitor Jenkins job builds, we have integrated Jenkins Slack Bot into our slack team.
- This will help various teams to communicate easily while job builds are in-progress, successfully completed, and failed.
- Teams no more have to keep looking at Jenkins web interface, while log Jenkins jobs are taking long time.

- https://github.com/kubernetes/dashboard
- https://github.com/kubernetes/heapster
- https://github.com/kubernetes/dashboard/wiki/Accessing-Dashboard---1.7.X-and-above
- kubernetes/dashboard#1867
- https://github.com/CSC-DevOps/Chaos
- https://github.com/DataDog/the-monitor/blob/master/kubernetes/how-to-collect-and-graph-kubernetes-metrics.md
- https://www.datadoghq.com/blog/monitoring-kubernetes-performance-metrics/
- https://groups.google.com/forum/#!topic/kubernetes-dev/q8wdi6hJDkg
- https://askubuntu.com/questions/112177/how-do-i-tunnel-and-browse-the-server-webpage-on-my-laptop