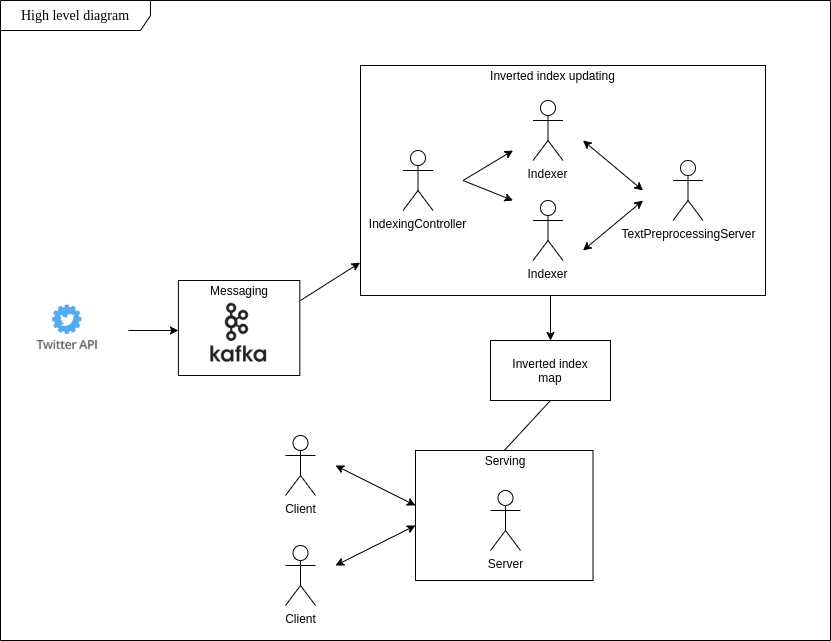
Searching for phrases people around say could be tough. What about dynamic updates of this dataset? Scalable storage and low latency? My main goal this project is to build a system that fulfills these requirements and allows to be up-to-date with trends present in tweets in a real-time fashion.
Following the idea of inverted index, I implemented the app that in real-time finds tweets with specific content, stores them in a local filesystem and allows to do word-based searching right after initializing client connection.
In order to run the app you need:
- Docker compose installation guide
- Clone the repo
git clone https://github.com/cyberpunk317/inverted_index.git
- Following this guide,
obtain Twitter API credentials and setup them in kafka/kafka_producer.py
TWITTER_APP_KEY = 'YOUR APP KEY' TWITTER_APP_SECRET = 'YOUR APP SECRET' TWITTER_KEY = 'YOUR KEY' TWITTER_SECRET = 'YOUR SECRET'
Create Dockerfiles for client and server:
./gradlew clean build createClientDockerfile createMainDockerfile
This will produce app_server.Dockerfile and app_client.Dockerfile in the root directory.
Start application:
docker-compose up
Launch a client session:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Start typing words of interest. Server will return location of tweets in the format 'dataset_v2//tweet_N.txt'. For example:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
See the open issues for a list of proposed features (and known issues).
Distributed under the MIT License. See LICENSE for more information.