![]()

Alibi is an open source Python library aimed at machine learning model inspection and interpretation. The focus of the library is to provide high-quality implementations of black-box, white-box, local and global explanation methods for classification and regression models.
If you're interested in outlier detection, concept drift or adversarial instance detection, check out our sister project alibi-detect.
|
Anchor explanations for images 
|
Integrated Gradients for text 
|
|
Counterfactual examples 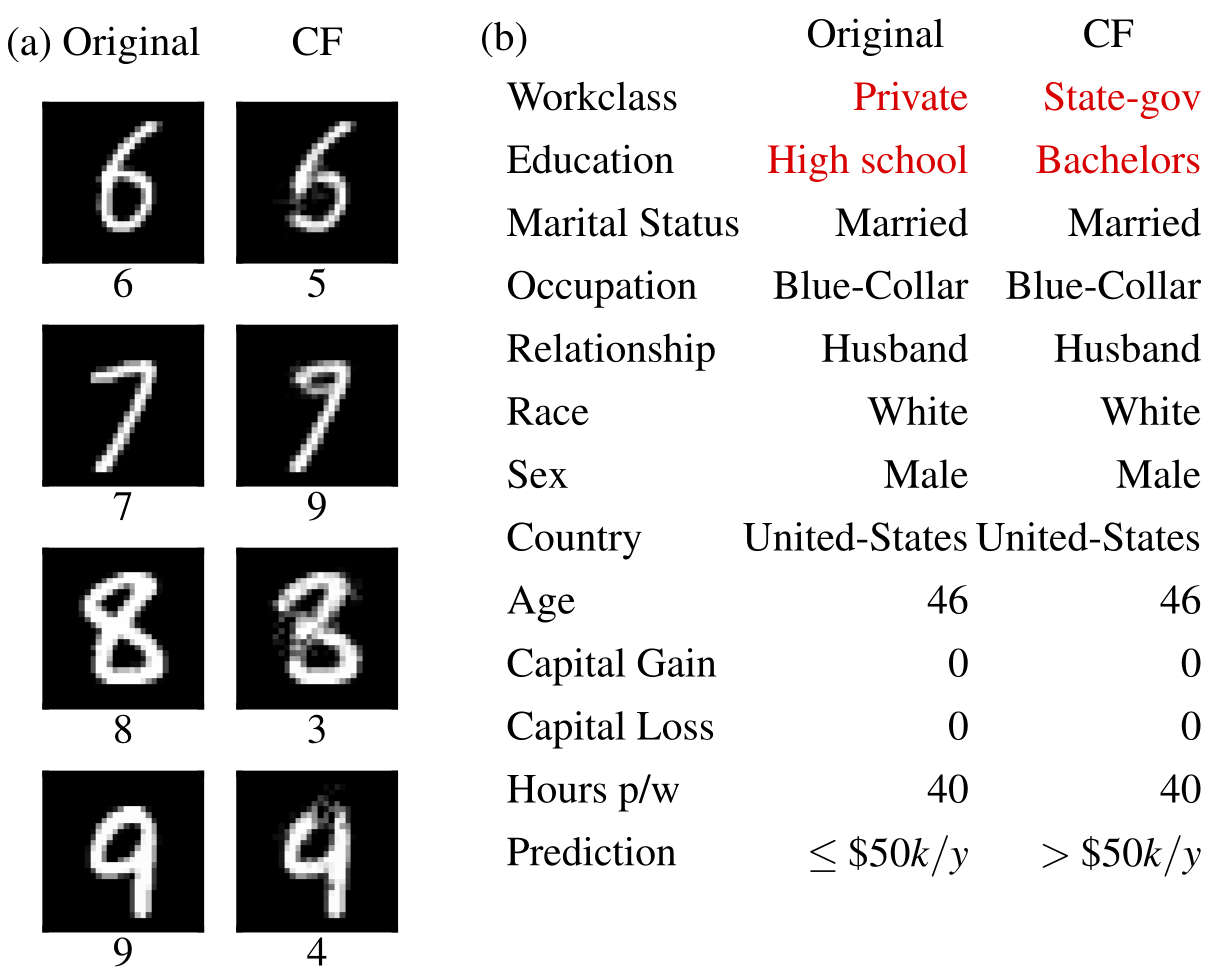
|
Accumulated Local Effects 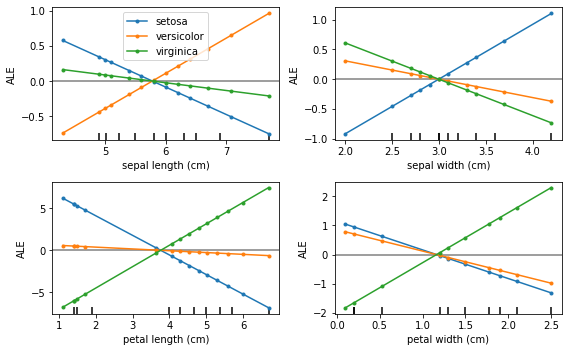
|
Alibi can be installed from PyPI:
pip install alibiAlternatively, the development version can be installed:
pip install git+https://github.com/SeldonIO/alibi.git To take advantage of distributed computation of explanations, install alibi with ray:
pip install alibi[ray]For SHAP support, install alibi as follows:
pip install alibi && pip install alibi[shap]The alibi explanation API takes inspiration from scikit-learn, consisting of distinct initialize,
fit and explain steps. We will use the AnchorTabular
explainer to illustrate the API:
from alibi.explainers import AnchorTabular
# initialize and fit explainer by passing a prediction function and any other required arguments
explainer = AnchorTabular(predict_fn, feature_names=feature_names, category_map=category_map)
explainer.fit(X_train)
# explain an instance
explanation = explainer.explain(x)The explanation returned is an Explanation object with attributes meta and data. meta is a dictionary
containing the explainer metadata and any hyperparameters and data is a dictionary containing everything
related to the computed explanation. For example, for the Anchor algorithm the explanation can be accessed
via explanation.data['anchor'] (or explanation.anchor). The exact details of available fields varies
from method to method so we encourage the reader to become familiar with the
types of methods supported.
The following tables summarize the possible use cases for each method.
| Method | Models | Explanations | Classification | Regression | Tabular | Text | Images | Categorical features | Train set required | Distributed |
|---|---|---|---|---|---|---|---|---|---|---|
| ALE | BB | global | ✔ | ✔ | ✔ | ✔ | ||||
| Anchors | BB | local | ✔ | ✔ | ✔ | ✔ | ✔ | For Tabular | ||
| CEM | BB* TF/Keras | local | ✔ | ✔ | ✔ | Optional | ||||
| Counterfactuals | BB* TF/Keras | local | ✔ | ✔ | ✔ | No | ||||
| Prototype Counterfactuals | BB* TF/Keras | local | ✔ | ✔ | ✔ | ✔ | Optional | |||
| Integrated Gradients | TF/Keras | local | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | Optional | |
| Kernel SHAP | BB | local global |
✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| Tree SHAP | WB | local global |
✔ | ✔ | ✔ | ✔ | Optional |
These algorithms provide instance-specific scores measuring the model confidence for making a particular prediction.
| Method | Models | Classification | Regression | Tabular | Text | Images | Categorical Features | Train set required |
|---|---|---|---|---|---|---|---|---|
| Trust Scores | BB | ✔ | ✔ | ✔(1) | ✔(2) | Yes | ||
| Linearity Measure | BB | ✔ | ✔ | ✔ | ✔ | Optional |
Key:
- BB - black-box (only require a prediction function)
- BB* - black-box but assume model is differentiable
- WB - requires white-box model access. There may be limitations on models supported
- TF/Keras - TensorFlow models via the Keras API
- Local - instance specific explanation, why was this prediction made?
- Global - explains the model with respect to a set of instances
- (1) - depending on model
- (2) - may require dimensionality reduction
-
Accumulated Local Effects (ALE, Apley and Zhu, 2016)
- Documentation
- Examples: Boston housing dataset, Iris dataset
-
Anchor explanations (Ribeiro et al., 2018)
-
Contrastive Explanation Method (CEM, Dhurandhar et al., 2018)
- Documentation
- Examples: MNIST, Iris dataset
-
Counterfactual Explanations (extension of Wachter et al., 2017)
- Documentation
- Examples: MNIST
-
Counterfactual Explanations Guided by Prototypes (Van Looveren and Klaise, 2019)
-
Integrated Gradients (Sundararajan et al., 2017)
- Documentation,
- Examples: MNIST example, Imagenet example, IMDB example.
-
Kernel Shapley Additive Explanations (Lundberg et al., 2017)
-
Tree Shapley Additive Explanations (Lundberg et al., 2020)
-
Trust Scores (Jiang et al., 2018)
- Documentation
- Examples: MNIST, Iris dataset
-
Linearity Measure
- Documentation
- Examples: Iris dataset, fashion MNIST
If you use alibi in your research, please consider citing it.
BibTeX entry:
@software{alibi,
title = {Alibi: Algorithms for monitoring and explaining machine learning models},
author = {Klaise, Janis and Van Looveren, Arnaud and Vacanti, Giovanni and Coca, Alexandru},
url = {https://github.com/SeldonIO/alibi},
version = {0.5.8},
date = {2021-04-29},
year = {2019}
}