This is the official implementation of “Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation” accepted in NeurIPS 2024 Paper Link(Arxiv)
🔥 October, 2024: We have added feature for single audio inference on our SepReformer-B for WSJ0-2MIX in models/SepReformer_Base_WSJ0. You can directly inference by your own samples!
🔥 October, 2024: We have uploaded the pre-trained models of our SepReformer-B for WSJ0-2MIX in models/SepReformer_Base_WSJ0/log/scratch_weight folder! You can directly test the model using the inference command below.
🔥 September 2024, Paper accepted at NeurIPS 2024 🎉.
We are planning to release the other cases especially for partially or fully overlapped, noisy-reverberant mixture with 16k of sampling rates for practical application within this year.

We propose SepReformer, a novel approach to speech separation using an asymmetric encoder-decoder network.
Demo Pages: Sample Results of speech separation by SepReformer
- python 3.10
- torch 2.1.2
- torchaudio 2.1.2
- pyyaml 6.0.1
- ptflops
- mir_eval
We offer a pretrained model for our SepReformer-B. (other models will be uploaded, soon)
This repository uses Git LFS (Large File Storage) to manage pretrained model files. If Git LFS is not installed, large files may not be downloaded properly. Please install Git LFS before cloning this repository.
- Installing and Setting Up Git LFS
-
Install Git LFS
Git LFS is an extension for Git that allows handling large files. You can install it, for example in Ubuntu, with the following commands:
sudo apt update sudo apt install git-lfs
-
Initialize Git LFS
Before cloning the repository, initialize Git LFS with the following command:
git lfs install
- For training or evaluation, you need dataset and scp file
- Prepare dataset for speech separation (eg. WSJ0-2mix)
- create scp file using data/create_scp/*.py
- If you want to train the network, you can simply trying by
-
set the scp file in ‘models/SepReformer_Base_WSJ0/configs.yaml’
-
run training as
python run.py --model SepReformer_Base_WSJ0 --engine-mode train
-
-
Simply Inference on a single audio with output wav files saved
python run.py --model SepReformer_Base_WSJ0 --engine-mode infer_sample --sample-file /to/your/sample/dir/
-
For example, you can directly test by using the included sample as
python run.py --model SepReformer_Base_WSJ0 --engine-mode infer_sample --sample-file ./sample_wav/sample.wav
-
Evaluating a model on dataset without saving output as audio files
python run.py --model SepReformer_Base_WSJ0 --engine-mode test -
Evaluating on dataset with output wav files saved
python run.py --model SepReformer_Base_WSJ0 --engine-mode test_wav --out_wav_dir '/your/save/directoy[optional]'
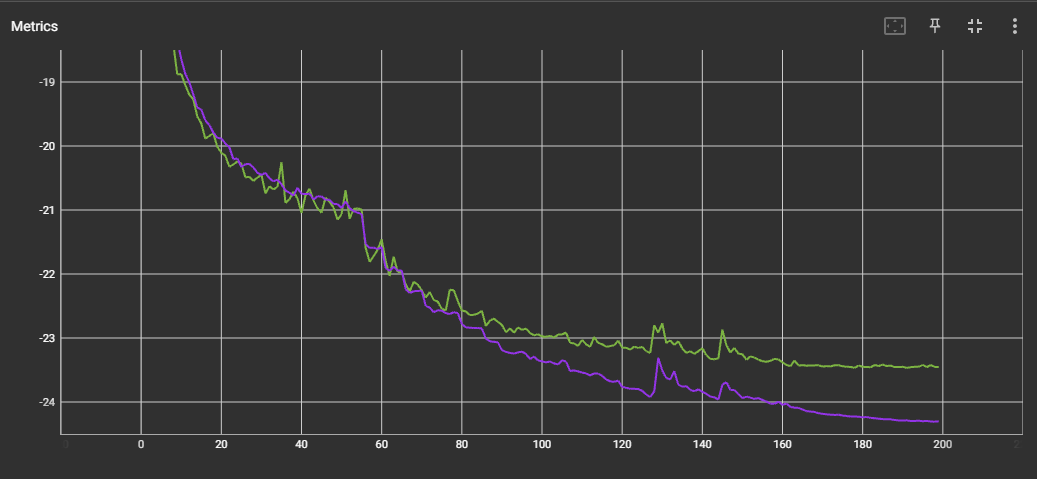
- For SepReformer-B with WSJ-2MIX, the training and validation curve is as follows:



If you find this repository helpful, please consider citing:
@inproceedings{
shin2024separate,
title={Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation},
author={Ui-Hyeop Shin and Sangyoun Lee and Taehan Kim and Hyung-Min Park},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=99y2EfLe3B}
}